
저자: 진쉐펑
배경
정적 그래프에서 대규모 언어 모델을 실행하면 다음과 같은 많은 이점이 있습니다.
-
연산자 융합 최적화/전체 그래프 실행으로 인한 성능 향상, Ascend인 경우 전체 그래프 싱킹 실행을 사용하여 성능을 더욱 향상시킬 수 있으며, 전체 그래프 싱킹 실행은 호스트 측의 데이터 처리 실행에 영향을 받지 않습니다. 그리고 성과는 안정되어 좋습니다;
-
정적 메모리 오케스트레이션은 메모리 활용도를 높이고 조각화를 방지하며 배치 크기를 늘려 훈련 성능을 향상시킵니다.
-
실행 순서를 자동으로 최적화하고 우수한 통신 및 계산 동시성을 달성합니다.
-
......
그러나 정적 이미지에서 대규모 언어 모델을 실행하는 데에도 어려움이 있습니다. 가장 눈에 띄는 것은 컴파일 성능입니다.
신경망 모델의 컴파일 프로세스는 실제로 Python으로 표현된 nn 코드를 데이터 흐름 계산 그래프로 변환합니다.
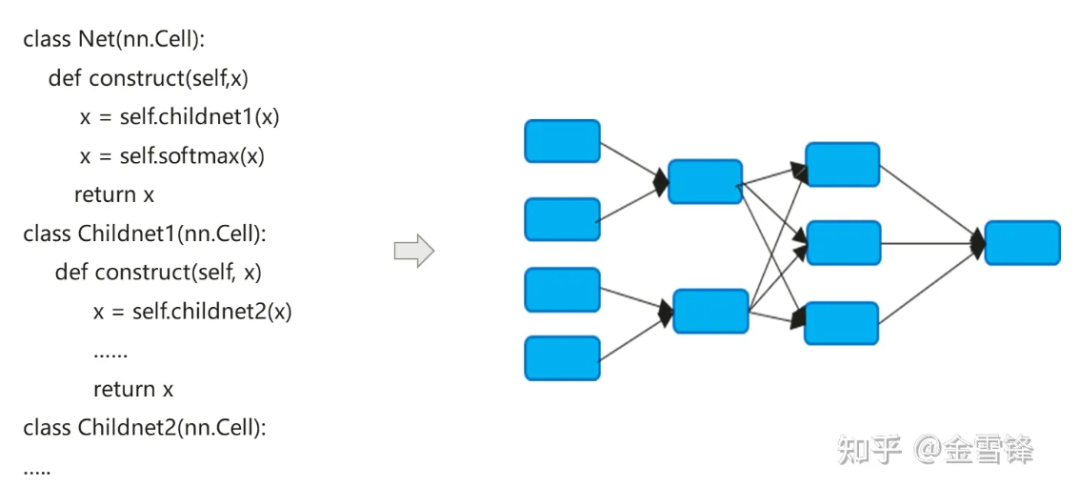
신경망 모델의 컴파일 프로세스는 기존 컴파일러와 약간 다릅니다. 기본 인라인 방법은 최종적으로 계층적 코드 표현을 평면 계산 그래프로 확장하는 데 종종 사용되며, 한편으로는 컴파일 최적화 기회를 극대화하려고 합니다. 반면에 자동 차별화 및 실행 논리를 단순화할 수도 있습니다.
기본적으로 인라인 이후에 형성된 계산 그래프에는 모든 계산 노드가 포함되며, 해당 노드에는 더 이상 하위 계산 그래프 파티션이 없으므로 상수 폴딩, 노드 융합, 병렬 분석 등 더 큰 규모로 프로세스 내 최적화를 수행할 수 있습니다. 등, 프로시저 간 호출 시 메모리 할당을 더 잘 실현하고 메모리 적용 및 성능 오버헤드를 줄일 수 있습니다. 반복적으로 호출되는 컴퓨팅 유닛의 경우에도 AI 분야의 컴파일러는 여전히 동일한 인라인 전략을 사용하며 프로그램 크기 확장 및 실행 가능한 코드 증가의 대가를 치르면서 컴파일 최적화 방법을 극대화하여 런타임 성능을 향상시킬 수 있습니다.
위의 설명에서 알 수 있듯이 인라인 최적화는 런타임 성능을 향상시키는 데 매우 도움이 되지만, 그에 따라 과도한 인라인은 컴파일 시간에도 부담을 줍니다. 하위 연산 그래프가 그래프 전체에 통합됨에 따라, 글로벌 관점에서 볼 때 컴파일러가 처리해야 하는 연산 그래프 노드의 수가 급격히 늘어나고 있습니다. 컴파일러는 일반적으로 Pass 메커니즘을 사용하여 최적화 방법을 구성하고 정렬합니다. 다양한 최적화 방법이 Pass 형식으로 직렬로 연결되고 처리 프로세스가 계산 그래프의 각 노드를 통과합니다. 처리 패스 수는 노드와 패스의 일치 및 변환 프로세스에 따라 달라집니다. 때로는 처리를 완료하는 데 여러 패스가 필요합니다. 일반적으로 패스 수가 M이고 계산 그래프 노드 수가 N인 경우 전체 컴파일 및 최적화 프로세스의 시간은 M * N 값과 직접적인 관련이 있습니다. 대규모 언어 모델 시대에 이 문제는 두 가지 주요한 이유가 있습니다. 첫째, 대규모 언어 모델의 모델 구조가 깊고 노드 수가 많습니다. 파이프라인 병렬 처리를 활성화하면 모델 규모와 노드 수가 더 늘어납니다. 원래 그래프 크기가 O이면 파이프라인 병렬 처리를 활성화하고 단일 노드 그래프의 크기는 (O/X)*Y가 됩니다. 여기서 X는 파이프라인의 단계 수이고 Y는 마이크로배치 수입니다. 실제로 구성 프로세스 중에 Y는 X보다 훨씬 큽니다. 예를 들어 X는 16이고 Y는 일반적으로 64-192로 설정됩니다. 이러한 방식으로 파이프라인 병렬화가 활성화되면 그래프 컴파일 규모가 원래 크기의 4~12배로 추가로 증가합니다.

수백억 개의 언어 모델로 구성된 특정 13B 네트워크를 예로 들면, 계산 그래프의 컴퓨팅 노드 수는 135,000개에 달하고 단일 컴파일 시간은 3시간에 가까울 수 있습니다.
**1.** 최적화 아이디어
우리는 딥 러닝의 신경망 구조가 여러 레이어로 구성되어 있음을 관찰했습니다. 대규모 모델 언어 모델에서 이러한 레이어는 특히 파이프라인 병렬 처리가 활성화된 경우 각 마이크로 배치의 레이어 레이어가 바로 그 레이어입니다. 같은. 따라서 Inline이나 Inline 없이 이러한 Layer 구조를 미리 유지하여 컴파일 성능을 기하급수적으로 향상시킬 수 있는지 궁금합니다. 예를 들어, 마이크로 배치를 경계로 따르고 마이크로 배치의 하위 그래프 구조를 유지한다면, 그러면 이론적으로 컴파일 시간은 원래 Y(Y는 마이크로 배치 수)의 1배가 됩니다.
모델에 작성된 코드에 따라 동일한 레이어를 재사용하는 방법은 일반적으로 루프 또는 반복 호출임을 알 수 있습니다. 레이어는 일반적으로 반복 프로세스의 순차적 구조 항목, 즉 하위 그래프에 해당합니다. 루프를 사용하거나 아래 코드에 표시된 것처럼 동일한 컴퓨팅 단위를 여러 번 호출하기 위해 반복하면 블록은 레이어 또는 마이크로 배치 하위 그래프에 해당합니다.
class Block(nn.Cell):
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block)
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
따라서 루프 본문을 자주 호출되는 하위 그래프로 간주하고 이를 Lazy Inline으로 표시하여 인라인 처리를 연기하도록 컴파일러에 지시하면 대부분의 컴파일 단계에서 성능 향상을 얻을 수 있습니다. 예를 들어 신경망이 동일한 하위 그래프 구조를 주기적으로 호출하는 경우 컴파일 단계에서 하위 그래프를 확장하지 않습니다. 그런 다음 컴파일이 끝나면 인라인 최적화가 트리거되어 필요한 최적화 및 변환 패스 처리를 수행합니다. 이런 식으로 컴파일러의 경우 인라인 확장된 코드가 아닌 더 작은 규모의 코드가 되는 경우가 대부분이므로 컴파일 성능이 크게 향상됩니다.
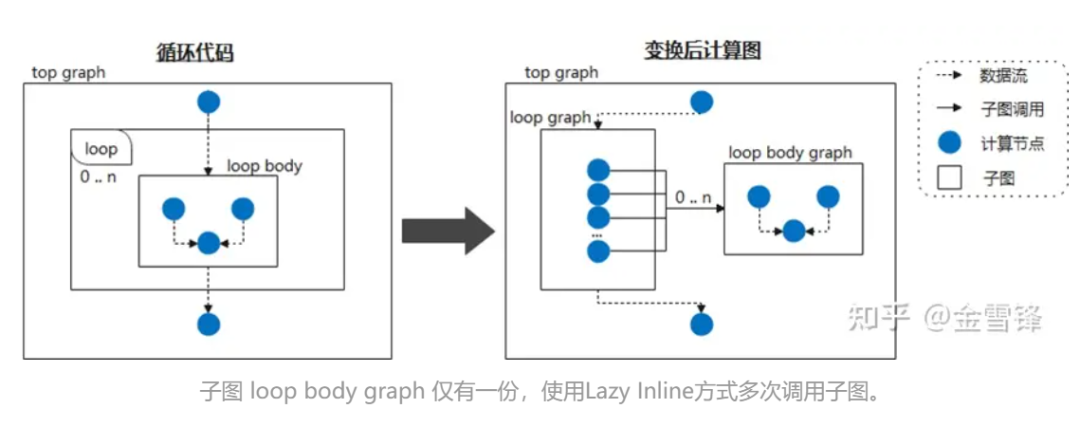
특정 구현 중에 관련 Layer 클래스에 @lazy-inline과 유사한 표시를 넣어 컴파일러에 메시지를 표시할 수 있습니다. 표시된 레이어가 루프 본문에서 호출되든 다른 방식으로 호출되든 인라인 확장 중에는 포함되지 않습니다. 실행 전까지는 수행되지 않습니다.
**2.** 마인드스포어 연습
Lazy Inline의 원리와 아이디어는 복잡하지 않은 것 같지만 기존 AI 그래프 컴파일 메커니즘은 일반적으로 완전한 컴파일 기능을 지원하는 종류의 컴파일러가 아니기 때문에 이 기능을 구현하는 것은 여전히 매우 어렵습니다.
다행스럽게도 MindSpore의 그래프 컴파일러는 하위 함수 호출, 클로저 및 기타 기능을 포함하여 IR을 설계할 때 다양성을 고려했습니다.
① Cell 인스턴스를 재사용 가능한 계산 그래프로 정리
Cell은 MindSpore 신경망의 기본 구성 요소이자 모든 신경망의 기본 클래스입니다. Cell은 conv2d, relu, bat_norm 등과 같은 단일 신경망 단위일 수도 있고, 다음을 구성하는 단위의 조합일 수도 있습니다. 회로망. GRAPH_MODE(정적 그래프 모드)에서는 Cell이 계산 그래프로 컴파일됩니다.
네트워크를 사용자 정의해야 하는 경우 Cell 클래스를 상속하고 __init__ 및 생성 메서드를 재정의해야 합니다. Cell 클래스는 __call__ 메서드를 재정의합니다. Cell 클래스 인스턴스가 호출되면 생성자 메서드가 실행됩니다. 구축 방법에서 네트워크 구조를 정의합니다.
다음 예에서는 컨볼루션 계산 기능을 구현하기 위해 간단한 네트워크를 구축했습니다. 네트워크의 연산자는 __init__에 정의되어 있으며 constructor 메소드에 사용됩니다. 해당 사례의 네트워크 구조는 Conv2d -> BiasAdd입니다.
구축 방법에서 x는 입력 데이터이고, 출력은 네트워크 구조를 계산한 결과이다.
import mindspore.nn as nn
import mindspore.ops as ops
from mindspore import Parameter
from mindspore.common.initializer import initializer
from mindspore._extends import lazy_inline
class MyNet(nn.Cell):
@lazy_inline
def __init__(self, in_channels=10, out_channels=20, kernel_size=3):
super(Net, self).__init__()
self.conv2d = ops.Conv2D(out_channels, kernel_size)
self.bias_add = ops.BiasAdd()
self.weight = Parameter(initializer('normal', [out_channels, in_channels, kernel_size, kernel_size]))
def construct(self, x):
output = self.conv2d(x, self.weight)
output = self.bias_add(output, self.bias)
return output
@Lazy_Inline은 Cell::__init__의 데코레이터입니다. 그 기능은 __init__의 모든 매개변수를 Cell의 cell_init_args 속성 값 self.cell_init_args = type(self).__name__ + str(arguments)로 생성하는 것입니다. cell_init_args 속성은 MindSpore 컴파일에서 Cell 인스턴스의 고유 식별자 역할을 합니다. 동일한 cell_init_args 값은 Cell 클래스 이름과 초기화 매개변수 값이 동일함을 나타냅니다.
constructor(self, x)는 Cell 클래스와 동일한 네트워크 구조를 정의합니다. 네트워크 구조는 입력 매개변수 self 및 x에 따라 달라집니다. Self에는 가중치와 같은 매개변수가 포함되어 있습니다. 이러한 가중치는 무작위로 초기화되거나 훈련 결과이므로 이러한 가중치는 Cell 인스턴스마다 다릅니다. 다른 자체 속성은 __init__ 매개변수에 의해 결정되며, __init__ 매개변수는 @lazy_inline에 의해 계산되어 셀 인스턴스 식별 cell_init_args를 얻습니다. 따라서 Cell 인스턴스 컴파일 계산 그래프 구문(self, x)은 구문(x, self.cell_init_args, self.trainable_parameters())으로 변환됩니다.
동일한 Cell 클래스이고 cell_init_args 매개변수가 동일한 경우 이러한 뉴런 인스턴스를 재사용 가능한 뉴런 인스턴스라고 하며, 이 뉴런 인스턴스에 해당하는 계산 그래프는 재사용 가능한 계산 그래프인 재사용_construct(X, self.trainable_parameters())로 명명됩니다. 각 Cell 인스턴스의 계산 그래프는 다음과 같이 변환될 수 있다고 추론할 수 있습니다.
def construct(self, x)
Reuse_construct(x, self.trainable_parameters())
재사용 가능한 컴퓨팅 그래프가 도입된 후에는 동일한 cell_init_args를 가진 뉴런 셀(재사용 가능한 컴퓨팅 그래프)을 한 번만 구성하고 컴파일하면 됩니다. 네트워크에 셀이 많을수록 성능이 향상될 수 있습니다. 그러나 모든 것에는 양면이 있습니다. 이러한 셀의 계산 그래프가 너무 작거나 너무 크면 연산자 융합, 메모리 다중화, 전체 그래프 싱킹 및 다중 그래프 호출 등과 같은 특정 기능의 컴파일 및 최적화가 제대로 이루어지지 않습니다. .
따라서 MindSpore 버전은 현재 재사용 가능한 계산 그래프를 생성하는 셀 컴파일 단계의 수동 식별만 지원합니다. 후속 버전에서는 Cell에 포함된 연산자 수, Cell이 사용된 횟수, 재사용 가능한 계산 그래프 생성 여부를 평가하고 최적화 제안을 제공하는 기타 요소 등 재사용 가능한 계산 그래프를 생성하기 위한 자동 전략을 계획합니다.
다음은 추상적이고 단순화된 설명을 위해 GPT 구조를 사용합니다.
class Block(nn.Cell):
@lazy_inline
def __init__(self, config):
.......
def construct(self, x, attention_mask, layer_past):
......
class GPT_Model(nn.Cell):
def __init__(self, config):
......
for i in range(config.num_layers):
self.blocks.append(Block(config, None))
......
self.num_layers = config.num_layers
def construct(self, input_ids, input_mask, layer_past):
......
present_layer = ()
for i in range(self.num_layers):
hidden_states, present = self.blocks[i](...)
present_layer = present_layer + (present,)
......
GPT는 여러 계층의 블록으로 구성됩니다. 이러한 블록의 초기화 매개변수는 모두 동일한 구성이므로 이러한 블록의 구조는 동일하며 컴파일러에 의해 내부적으로 다음 구조로 변환됩니다.
def Reuse_Block(x, attention_mask, layer_past,block_parameters) :
......
具体的Block 实例的计算图如下:
def construct(self, x, attention_mask, layer_past):
return Reuse_Block(x, attention_mask, layer_past,
self. trainable_parameters())
이 구조를 사용하면 컴파일 프로세스의 전반부에서 독립적인 계산 그래프가 되며 전체 계산 그래프에 인라인되지 않습니다. 최종 소량의 패스 최적화만 큰 계산 그래프에 인라인됩니다.
② L****azy Inline과 자동 미분/병렬/재계산 등의 기능 결합
Lazy Inline의 솔루션을 채택한 후에는 원래 프로세스에 어느 정도 영향을 미치며 관련 조정(주로 자동 차별화, 병렬성 및 재계산)이 필요합니다.
자동 차별화를 위해서는 호출 기능과 유사한 전달 노드가 나타나고 차별화 처리가 제공되어야 합니다.
병렬 프로세스의 경우 이전 파이프라인 절단은 전체 그림을 기반으로 했지만 이제는 공유 하위 그래프를 기반으로 절단해야 하기 때문에 파이프라인 병렬 패스 처리를 전체 그림이 아닌 시나리오에 적용해야 한다는 것이 가장 중요합니다. 구체적인 계획은 먼저 Stage에 따라 색상을 지정하고, Stage에 따라 공유 Cell의 노드를 분할하고, 현재 프로세스의 Stage에 해당하는 노드만 유지하고, Send/Recv 연산자를 삽입한 후 노드를 분할하는 것입니다. 공유 셀 외부에서는 현재 프로세스의 해당 노드를 유지합니다. 또한 스테이지 노드는 공유 셀의 Send/Recv 연산자를 공유 셀 밖으로 가져옵니다.
재계산 과정은 기존 재계산 과정에서 인라인 이후 전체 그래프에 대해 연산자를 처리하며, 재계산이 필요한 연산자와 재계산 매개변수는 사용자의 재계산 구성에 따라 결정됩니다. 계산된 연산자 실행이 종속되는 연산자입니다. Lazy Inline 이후에는 연속적인 재계산 연산자가 서로 다른 하위 그래프에 있을 수 있으며 정방향 노드와 역방향 노드 사이에 연결 관계를 찾을 수 없으므로 전체 그래프 연산자를 기반으로 한 원래 검색 전략은 실패합니다.
우리의 적응 계획은 자동 미분 후 다시 계산된 셀이나 연산자를 처리하는 것입니다. 자동 차별화 프로세스는 Cell에서 생성된 하위 그래프 또는 단일 연산자에 대한 클로저를 생성하여 순방향 출력 및 역전파 함수를 반환하고 각 클로저와 원래 순방향 부분 간의 관계도 매핑합니다. 이 정보를 통해 사용자의 재계산 구성을 기반으로 각 클로저를 기본 단위로 사용하고 Cell과 Operator를 균일하게 처리하며 원래의 Forward 부분을 원본 그래프에 다시 복사하여 종속 관계를 전달할 수 있습니다. 클로저의 클로저 역전파 함수 획득은 최종적으로 전체 그래프의 인라인에 의존하지 않는 재계산 방식을 달성할 수 있습니다.
③백엔드 처리 및 영향
프런트엔드에서 Lazy Inline을 켠 후 생성된 IR은 백엔드로 전송되며, 하위 그래프 싱킹을 통해 디바이스에서 실행되기 전에 백엔드에서 IR을 슬라이스해야 합니다. 그러나 Lazy Inline 후에도 메모리 재사용 및 스트림 할당을 위한 최적의 방법을 사용할 수 없거나, 컴파일 중 컴파일 가속을 위해 그래프의 내부 캐시를 사용할 수 없는 등 하위 그래프 싱킹 실행에 몇 가지 문제가 여전히 남아 있습니다. , 교차 그래프 처리를 수행할 수 없음(메모리 최적화, 통신 융합, 연산자 융합 등) 및 기타 문제.
최적의 성능을 얻기 위해서는 백엔드가 Lazy Inline의 IR을 백엔드 싱킹 실행에 적합한 형태로 처리해야 합니다. 가장 먼저 해야 할 일은 자동 미분에 의해 생성된 부분 연산자를 일반 하위 그래프 호출로 변환하고 변경하는 것입니다. 캡처된 변수를 일반 매개변수로 전달하면 전체 그래프가 가라앉고 전체 네트워크가 실행될 수 있습니다.
전체 그래프 싱킹 프로세스에서 이러한 호출에는 그래프의 인라인과 실행 시퀀스의 인라인이라는 두 가지 처리 방법이 있습니다. 그래프의 인라인으로 인해 그래프가 확장되고 후속 컴파일 속도가 느려집니다. 그러나 실행 시퀀스의 인라인으로 인해 메모리 재사용 중에 실행 시퀀스 인라인 부분의 메모리 수명 주기가 특히 길어집니다. 결국 메모리가 충분하지 않습니다.
결국 우리가 채택한 처리 방법은 최적화 단계, 연산자 선택, 연산자 컴파일 및 기타 프로세스에서 실행 시퀀스 인라인 프로세스를 재사용하여 그래프 크기를 최대한 작게 만들고 백엔드에 영향을 미치는 너무 많은 그래프 노드를 방지하는 것이었습니다. 그래프 시간을 정리합니다. 시퀀스 최적화, 스트림 할당, 메모리 재사용 및 기타 프로세스를 실행하기 전에 이러한 호출이 실제 노드 인라인으로 이루어져 최적의 메모리 재사용 효과를 얻습니다. 또한 일부 메모리 및 통신 최적화, 중복 계산 제거 및 그래프 인라인 이후의 기타 방법을 통해 메모리 및 성능이 저하되지 않는 것이 가능합니다.
현재 모든 교차 그래프 수준 최적화를 달성하는 것은 불가능합니다. 단일 지점 식별은 인라인 이후 단계에만 배치할 수 있으며 실행 순서 최적화, 스트림 할당 및 메모리 재사용에 대한 시간을 절약하는 것은 불가능합니다.
④ 효과 달성
대형 모델 컴파일 성능 최적화는 Lazy Inline 솔루션을 사용하여 컴파일 성능을 3~8배 향상시킵니다. 100억 개의 대형 모델의 13B 네트워크를 예로 들면 Lazy Inline 솔루션을 적용한 후 계산 그래프 컴파일 규모가 130,000+에서 감소했습니다. 노드를 20,000개 이상의 노드로 늘리면 컴파일 시간이 3시간에서 20분으로 단축되었으며 컴파일 결과 캐싱과 결합되어 전반적인 효율성이 크게 향상되었습니다.
⑤이용 제한사항 및 다음 단계
1. Cell Cell 인스턴스의 식별자는 Cell 클래스 이름과 __init__ 매개 변수 값을 기반으로 생성됩니다. 이는 init의 매개변수가 Cell의 모든 속성을 결정하며, 구성 구성 시작 시의 Cell 속성은 init 실행 후의 속성과 일치한다는 가정에 기초합니다. 따라서 구성과 관련된 Cell의 속성은 변경할 수 없습니다. init가 실행된 후.
2. 구성 함수 매개변수는 기본값을 가질 수 없습니다. 기존 MindSpore 버전에 구성 함수 매개변수에 대한 기본값이 있는 경우 이를 사용할 때마다 새로운 계산 그래프로 전문화되며 후속 버전에서는 원래 전문화 메커니즘을 최적화합니다.
3. Cell은 여러 개의 공유 Cell_X 인스턴스로 구성되며, 각 Cell_X는 여러 개의 공유 Cell_Y 인스턴스로 구성됩니다. Cell_X와 Cell_Y의 초기화가 모두 @lazy_inline으로 장식된 경우 가장 바깥쪽 Cell_X만 재사용된 계산 그래프로 컴파일될 수 있으며 내부 Cell_Y의 계산 그래프는 여전히 인라인입니다. 후속 버전에서는 이 다중 레벨 지연 인라인을 지원할 계획입니다. 기구.
고객이 높은 응집력과 낮은 결합도로 코드를 작성할 수 있도록 지원하는 방법도 MindSpore 프레임워크가 추구하는 목표 중 하나입니다. 예를 들어 사용 시 레이어 인덱스를 포함하는 Block:: __init__ 매개변수와 값이 있습니다. 다른 매개변수는 동일합니다. 레이어 인덱스는 각 레이어마다 다르기 때문에 미묘한 차이로 인해 블록을 재사용할 수 없습니다. 예를 들어 특정 GTP 버전 코드에는 다음 코드가 존재합니다.
class Block (nn.Cell):
"""
Self-Attention module for each layer
Args:
config(GPTConfig): the config of network
scale: scale factor for initialization
layer_idx: current layer index
"""
def __init__(self, config, scale=1.0, layer_idx=None):
......
if layer_idx is not None:
self.coeff = math.sqrt(layer_idx * math.sqrt(self.size_per_head))
self.coeff = Tensor(self.coeff)
......
def construct(self, x, attention_mask, layer_past=None):
......
블록을 재사용 가능하게 만들기 위해 이를 최적화하고 레이어 인덱스와 관련된 계산을 추출한 다음 이를 Construct의 매개변수로 사용하여 원래 구성에 입력함으로써 블록의 초기화 매개변수가 동일하도록 할 수 있습니다.
위 코드 세그먼트를 다음 코드 세그먼트로 수정하고 Init 및 Layer Index 관련 부분을 삭제한 후 coeff 매개변수를 추가하여 구성합니다.
class Block (nn.Cell):
def __init__(self, config, scale=1.0):
......
def construct(self, x, attention_mask, layer_past, coeff):
......
Shengsi MindSpore의 후속 버전에서는 이러한 미묘하게 다른 블록을 식별하고 최적화 및 개선을 위해 이러한 블록에 대한 최적화 제안을 제공할 계획입니다.
1990년대에 태어난 프로그래머가 비디오 포팅 소프트웨어를 개발하여 1년도 안 되어 700만 개 이상의 수익을 올렸습니다. 결말은 매우 처참했습니다! Google은 Flutter, Dart 및 Python 팀의 중국 코더의 "35세 저주"와 관련된 정리해고를 확인했습니다 . | Daily Windows 1.0용 Arc Browser가 3개월 만에 공식적으로 GA Windows 10 시장 점유율이 70%에 도달했으며 Windows 11 GitHub는 AI 기본 개발 도구 GitHub Copilot Workspace JAVA를 계속 해서 출시했습니다 . OLTP+OLAP을 처리할 수 있는 유일한 강력한 유형의 쿼리입니다. 우리는 너무 늦게 만났습니다 .