
누구나 GitHub에 별표를 표시할 수 있습니다.
분산형 풀링크 인과 학습 시스템 OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
대규모 모델 기반 지식 그래프 OpenSPG: https://github.com/OpenSPG/openspg
대규모 그래프 학습 시스템 OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
지난 4월 25일과 26일 양일간 상하이 하얏트 리젠시 글로벌 하버 호텔에서 글로벌 머신러닝 기술 컨퍼런스가 열렸습니다! Ant Group의 오픈소스 DLRover 책임자인 Wang Qinlong은 컨퍼런스에서 "DLRover 훈련 결함 자가 치유: 대규모 AI 훈련의 컴퓨팅 성능 효율성을 대폭 향상"이라는 주제로 기조연설을 하면서, 빠른 자가 치유 방법을 공유했습니다. 킬로칼로리 대규모 모델 훈련 작업 실패 Wang Qinlong은 DLRover의 기술 원리와 사용 사례뿐만 아니라 대규모 커뮤니티 모델에 대한 DLRover의 실제 효과도 소개했습니다.

오랫동안 Ant에서 AI 인프라 연구 및 개발에 참여한 Wang Qinlong은 Ant 분산 학습의 탄력적인 내결함성과 자동 확장 및 축소 프로젝트 구축을 주도했습니다. 그는 ElasticDL 및 DLRover와 같은 여러 오픈 소스 프로젝트에 참여했으며, 2023년 Open Atomic Foundation의 Vibrant Open Source Contributor, 2022년 Ant Group의 T-Star Outstanding Engineer로 선정되었습니다. 현재 그는 안정적이고 확장 가능하며 효율적인 대규모 분산 교육 시스템을 구축하는 데 중점을 두고 있는 Ant AI Infra 오픈 소스 프로젝트 DLRover의 설계자입니다.
대규모 모델 훈련 및 과제
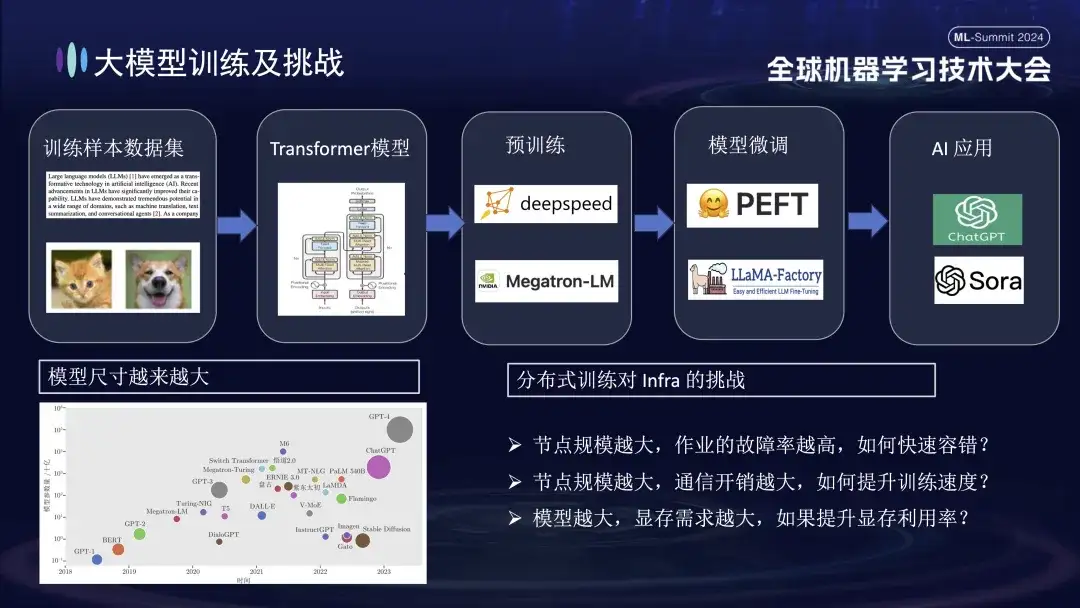
대규모 모델 훈련의 기본 프로세스는 위 그림에 나와 있습니다. 여기에는 훈련 샘플 데이터 세트 준비, Transformer 모델 구성, 사전 훈련, 모델 미세 조정 및 최종적으로 사용자 AI 애플리케이션 구축이 필요합니다. 대형 모델이 10억 개의 매개변수에서 1조개의 매개변수로 이동함에 따라 훈련 규모의 증가로 인해 클러스터 비용이 급증하고 시스템 안정성에도 영향을 미쳤습니다. 이러한 대규모 시스템으로 인해 발생하는 높은 운영 및 유지 관리 비용은 대형 모델 학습 중에 해결해야 할 시급한 문제가 되었습니다.
- 노드 크기가 클수록 작업 실패율이 높아집니다. 결함을 신속하게 허용하는 방법은 무엇입니까 ?
- 노드 크기가 클수록 통신 오버헤드가 커집니다. 훈련 속도를 향상시키는 방법은 무엇입니까 ?
- 노드 크기가 클수록 메모리 요구 사항도 커집니다. 메모리 활용도를 높이는 방법은 무엇입니까 ?
Ant AI 엔지니어링 기술 스택
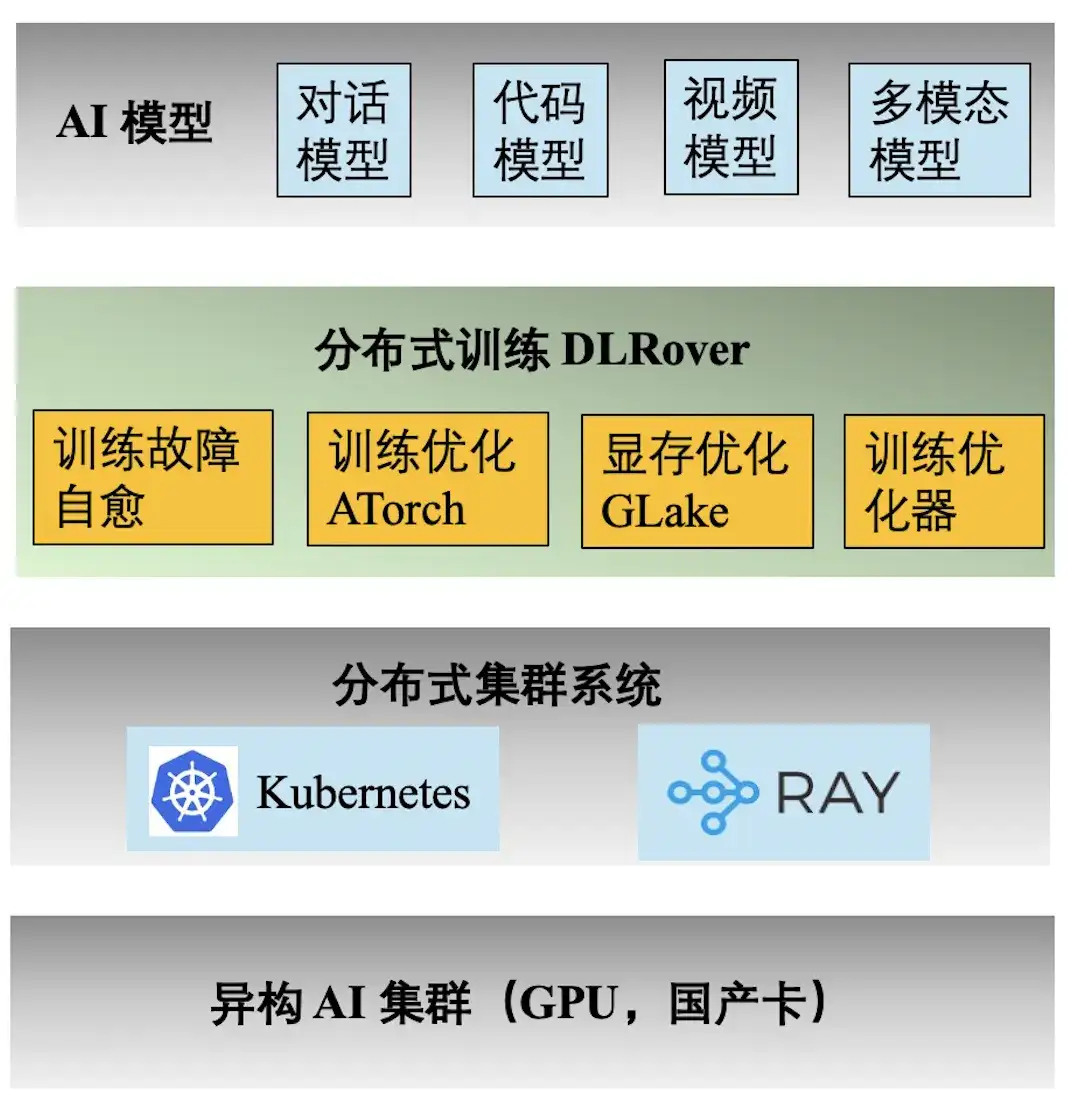
위 그림은 Ant AI 훈련의 엔지니어링 기술 스택을 보여줍니다. 분산 훈련 엔진 DLRover는 Ant의 대화, 코드, 비디오 및 다중 모드 모델에 대한 다양한 훈련 작업을 지원합니다. DLRover가 제공하는 주요 기능은 다음과 같습니다.
- **훈련 결함의 자가 치유:** 킬로칼로리 분산 훈련의 유효 시간을 97% 이상으로 늘려 대규모 훈련 결함의 컴퓨팅 전력 비용을 줄입니다.
- **훈련 최적화 ATorch:** 모델과 하드웨어를 기반으로 최적의 분산 훈련 전략을 자동으로 선택합니다. Kcal(A100) 클러스터 하드웨어의 컴퓨팅 전력 활용률을 60% 이상으로 늘립니다.
- **훈련 옵티마이저:** 옵티마이저는 모델 반복 탐색과 동일하며 최단 경로에서 목표를 달성하는 데 도움이 될 수 있습니다. 우리의 최적화 프로그램은 AdamW에 비해 수렴 가속을 1.5배 향상시킵니다. 관련 결과는 ECML PKDD '21, KDD'23, NeurIPS '23에 게재되었습니다.
- **비디오 메모리 및 전송 최적화 Glake: **대형 모델의 훈련 과정에서 많은 비디오 메모리 조각이 생성되어 비디오 메모리 리소스 활용도가 크게 감소합니다. 통합 메모리 + 전송 최적화 및 전역 메모리 최적화를 통해 훈련 메모리 요구 사항을 2~10배 줄입니다. 결과는 ASPLOS'24에 발표되었습니다.
실패가 컴퓨팅 성능 낭비로 이어지는 이유
Ant가 훈련 실패 문제에 특별한 관심을 기울이는 이유는 주로 훈련 과정에서 기계 오류가 발생하면 훈련 비용이 크게 증가하기 때문입니다. 예를 들어 Meta는 2022년에 대규모 모델 훈련을 위한 실제 데이터를 발표했습니다. OPT-175B 모델을 훈련할 때 992개의 80GB A100 GPU를 사용했으며, AWS GPU 가격에 따르면 총 124대의 8카드 머신이 사용되었습니다. 하루에. 실패로 인해 훈련 주기가 20일 이상 연장되어 컴퓨팅 성능 비용이 수천만 위안 증가했습니다.

아래 그림은 Alibaba Cloud 클러스터에서 대규모 모델을 교육할 때 발생하는 오류의 분포를 보여줍니다. 이러한 오류 중 일부는 다시 시작해도 해결될 수 있지만 다른 오류는 다시 시작해도 복구할 수 없습니다. 예를 들어, 다시 시작한 후에도 결함이 있는 카드가 여전히 손상되어 카드가 떨어지는 문제가 있습니다. 시스템을 다시 시작하고 복원하려면 먼저 손상된 시스템을 교체해야 합니다.
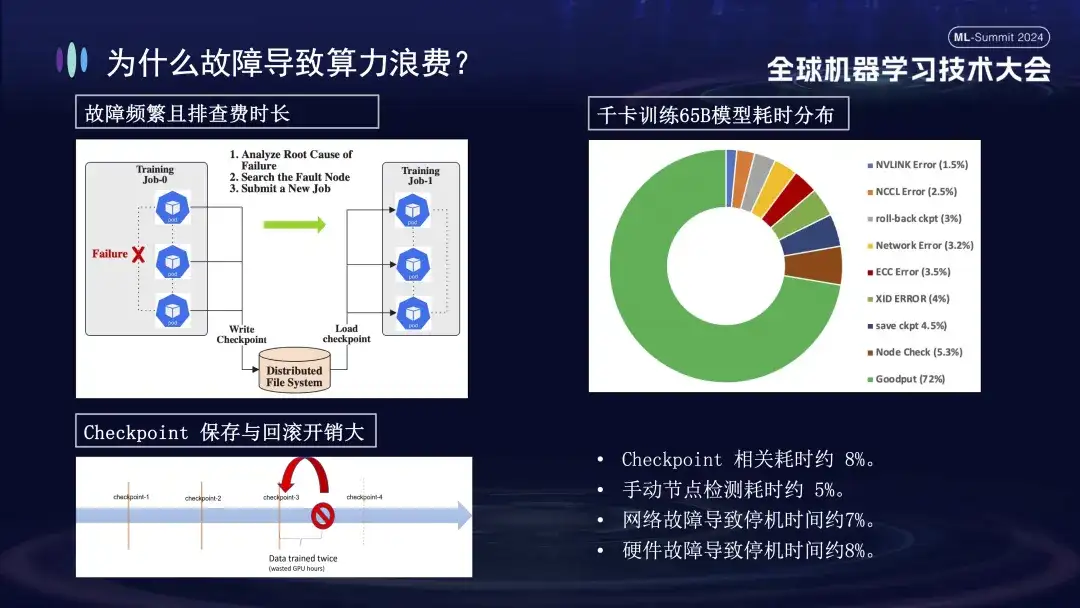
훈련 실패가 왜 그렇게 큰 영향을 미치나요? 우선, 분산 훈련을 위해서는 여러 노드가 함께 작동해야 합니다. 노드 하나라도 실패하면(소프트웨어, 하드웨어, 네트워크 카드 또는 GPU 문제 등) 전체 훈련 프로세스가 일시 중지되어야 합니다. 둘째, 훈련 실패가 발생한 후 문제를 해결하는 데 시간이 많이 걸리고 힘듭니다. 예를 들어, 일반적으로 사용되는 수동 검사 방법은 이제 한 번 확인하는 데 최소 1~2시간이 필요합니다. 마지막으로 훈련은 Stateful입니다. 훈련을 다시 시작하려면 계속하기 전에 이전 훈련 상태에서 복구해야 하며 일정 기간 후에 훈련 상태를 저장해야 합니다. 저장하는 데 시간이 오래 걸리고, 실패 롤백도 계산 낭비를 초래합니다. 위의 오른쪽 그림은 자가 치유를 수행하기 위해 온라인에 접속하기 전 훈련 시간의 분포를 보여줍니다. 체크포인트 관련 시간은 약 8%, 수동 노드 감지 시간은 약 5%이며 다운타임이 발생함을 알 수 있습니다. 네트워크 장애로 인한 비율은 약 7%, 하드웨어 장애로 인한 다운타임은 약 8%, 최종 유효 교육 시간은 약 72%에 불과합니다.
DLRover 훈련 결함 자가 복구 기능 개요

위 그림은 결함 자가 치유 기술에서 DLRover의 두 가지 핵심 기능을 보여줍니다. 우선, Flash Checkpoint는 학습 과정을 중단하지 않고 상태를 신속하게 저장하고 고주파 백업을 달성할 수 있습니다. 이는 장애 발생 시 시스템이 가장 최근의 체크포인트에서 즉시 복구할 수 있어 데이터 손실과 교육 시간이 단축된다는 의미입니다. 둘째, DLRover는 Kubernetes를 사용하여 지능적이고 탄력적인 스케줄링 메커니즘을 구현합니다. 이 메커니즘은 노드 오류에 자동으로 대응할 수 있습니다. 예를 들어, 100개의 시스템 클러스터에서 하나가 실패하면 시스템은 자동으로 99개의 시스템으로 조정되어 수동 개입 없이 훈련을 계속합니다. 또한 Kubeflow 및 PyTorchJob과 호환되며 노드 상태 모니터링 기능을 강화하여 모든 오류를 신속하게 식별하고 10분 이내에 대응하여 훈련 운영의 연속성과 안정성을 유지합니다.
DLRover 탄력적 내결함성 훈련
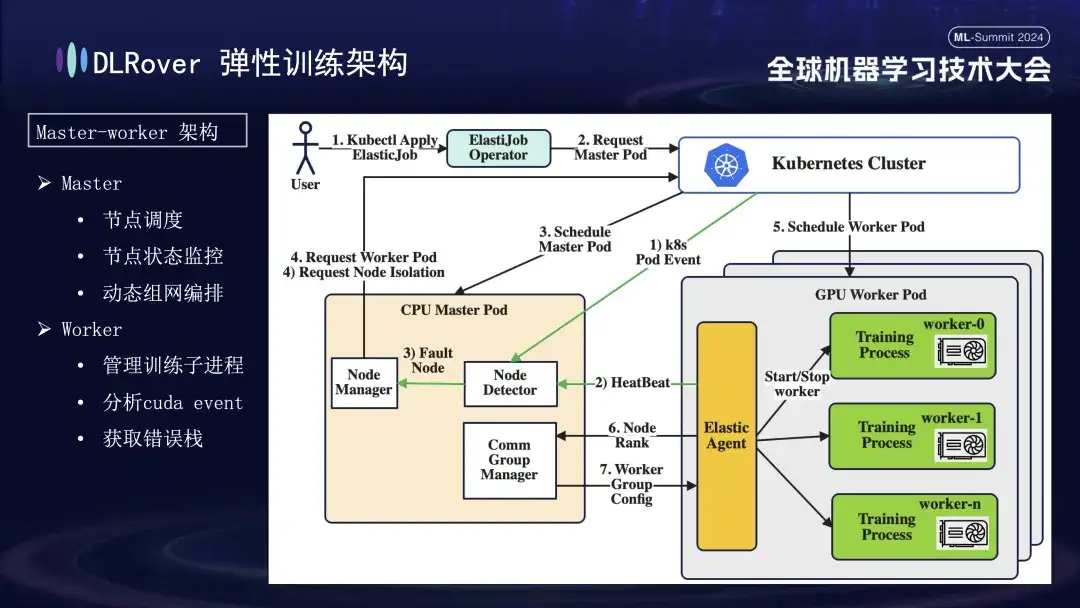
DLRover는 머신러닝 초기에는 흔하지 않았던 마스터-워커 아키텍처를 채택했습니다. 이 설계에서 마스터는 제어 센터 역할을 하며 훈련 코드를 실행하지 않고도 노드 스케줄링, 상태 모니터링, 네트워크 구성 관리, 오류 로그 분석과 같은 주요 작업을 담당합니다. 일반적으로 CPU 노드에 배포됩니다. 작업자는 실제 교육 부하를 부담하며 각 노드는 여러 하위 프로세스를 실행하여 노드의 여러 GPU를 활용하여 컴퓨팅 작업을 가속화합니다. 또한, 시스템의 견고성을 높이기 위해 작업자의 Elastic Agent를 맞춤화하고 강화하여 보다 효과적인 결함 감지 및 위치 파악이 가능하도록 하여 훈련 과정에서 안정성과 효율성을 보장합니다.
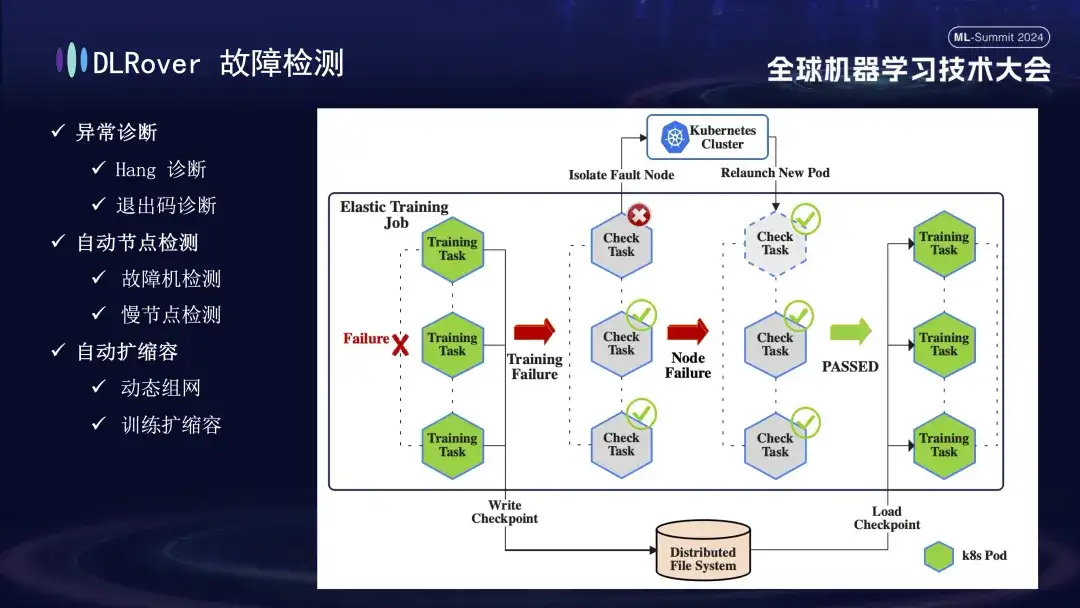
다음은 오류 감지 프로세스입니다. 훈련 과정에서 오류가 발생하여 작업이 중단되면 직관적인 성능은 훈련이 중단되는 것이지만 오류가 발생하면 관련된 모든 기계가 동시에 정지하기 때문에 오류의 구체적인 원인과 소스가 직접적으로 드러나지 않습니다. . 이 문제를 해결하기 위해 우리는 오류가 발생한 후 모든 컴퓨터에서 즉시 탐지 스크립트를 실행했습니다. 노드가 검사에 실패한 것으로 감지되면 Kubernetes 클러스터에 즉시 알림을 보내 실패한 노드를 제거하고 새 대체 노드를 재배포합니다. 새 노드는 기존 노드에 대한 추가 상태 확인을 완료하고 나면 훈련 작업이 자동으로 다시 시작됩니다. 결함이 있는 노드가 격리되어 리소스 부족이 발생하는 경우 감소 전략을 구현한다는 점은 주목할 가치가 있습니다(자세한 내용은 나중에 소개하겠습니다). 원래 결함이 있던 기계가 정상으로 돌아오면 시스템은 자동으로 용량 확장 작업을 수행하여 효율적이고 지속적인 교육을 보장합니다.
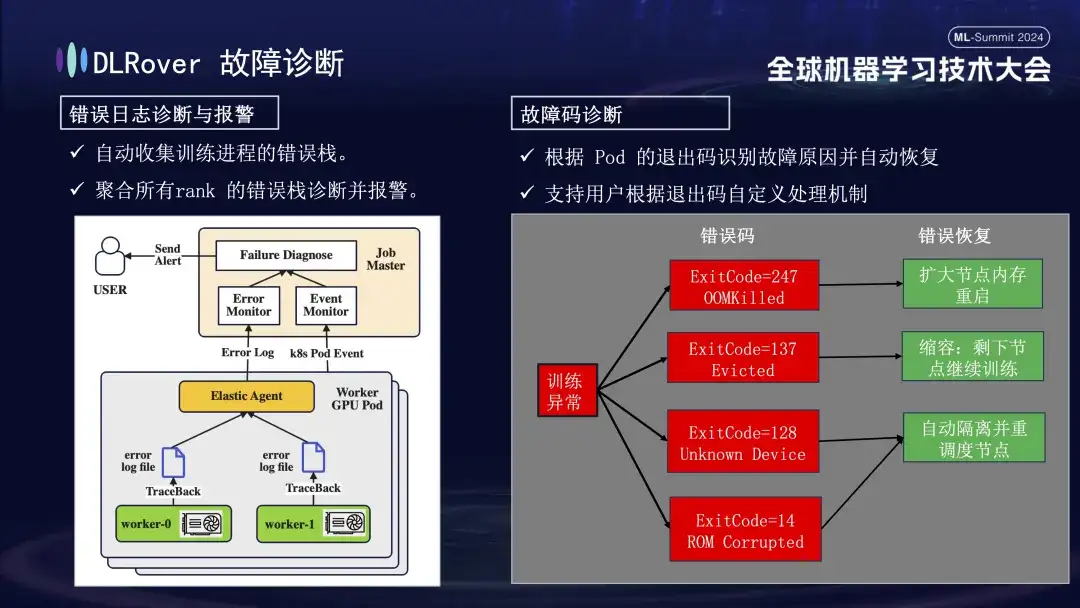
다음은 빠르고 정확한 오류 위치 및 처리를 달성하기 위해 다음과 같은 포괄적인 방법을 사용하는 오류 진단 프로세스입니다.
- 먼저 에이전트는 각 교육 프로세스에서 오류 정보를 수집하고 이러한 오류 스택을 마스터 노드에 요약합니다. 그런 다음 마스터 노드는 집계된 오류 데이터를 분석하여 문제가 있는 시스템을 찾아냅니다. 예를 들어 기계 로그에 ECC 오류가 표시되면 기계 결함을 직접 확인하고 제거합니다.
- 또한 Kubernetes의 종료 코드를 사용하여 진단을 지원할 수도 있습니다. 예를 들어 종료 코드 137은 일반적으로 감지된 문제로 인해 기본 컴퓨팅 플랫폼이 시스템을 종료했음을 나타내며, 종료 코드 128은 장치가 인식되지 않음을 의미합니다. GPU 드라이버에 결함이 있을 수 있습니다. 종료 코드를 통해 감지할 수 없는 오류도 많이 있습니다. 일반적인 오류로는 네트워크 지터 시간 초과가 있습니다.
- 네트워크 변동으로 인한 시간 초과 등 종료 코드만으로는 식별할 수 없는 오류도 많이 있습니다. 우리는 보다 일반적인 전략을 채택할 것입니다. 오류의 구체적인 성격에 관계없이 주요 목표는 오류가 있는 노드를 신속하게 식별하고 제거한 다음 마스터에 알리고 문제가 있는 위치를 구체적으로 감지하는 것입니다.
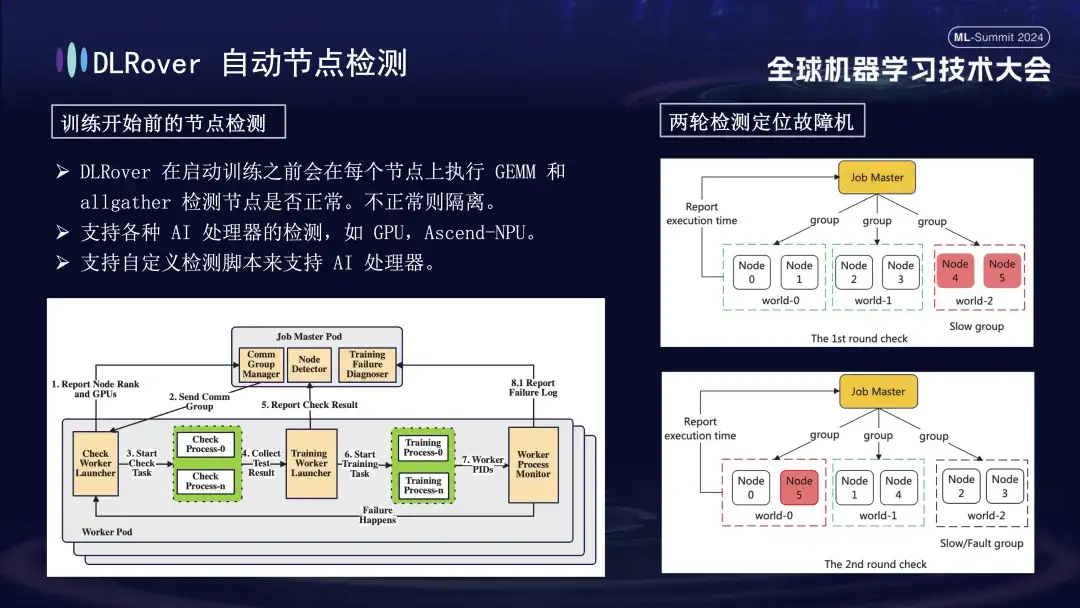
먼저, 모든 노드에 대해 행렬 곱셈을 수행합니다. 이어서 노드를 페어링하고 그룹화합니다. 예를 들어 6개의 노드가 있는 Pod에서는 노드를 (0,1), (2,3), (4,5)의 세 그룹으로 나누고 AllGather 통신 감지를 수행합니다. 수행. 4번과 5번 사이에서는 통신 장애가 발생했지만, 다른 그룹에서는 통신이 정상이라면, 4번이나 5번 노드에서 장애가 발생한 것으로 결론을 내릴 수 있다. 다음으로 결함이 있다고 의심되는 노드는 추가 테스트를 위해 알려진 정상 노드와 다시 쌍을 이룹니다. 예를 들어 감지를 위해 0과 5를 결합합니다. 결과를 비교함으로써 결함이 있는 노드를 정확하게 식별합니다. 이 자동화된 검사 프로세스는 10분 이내에 결함이 있는 기계를 정확하게 진단합니다.
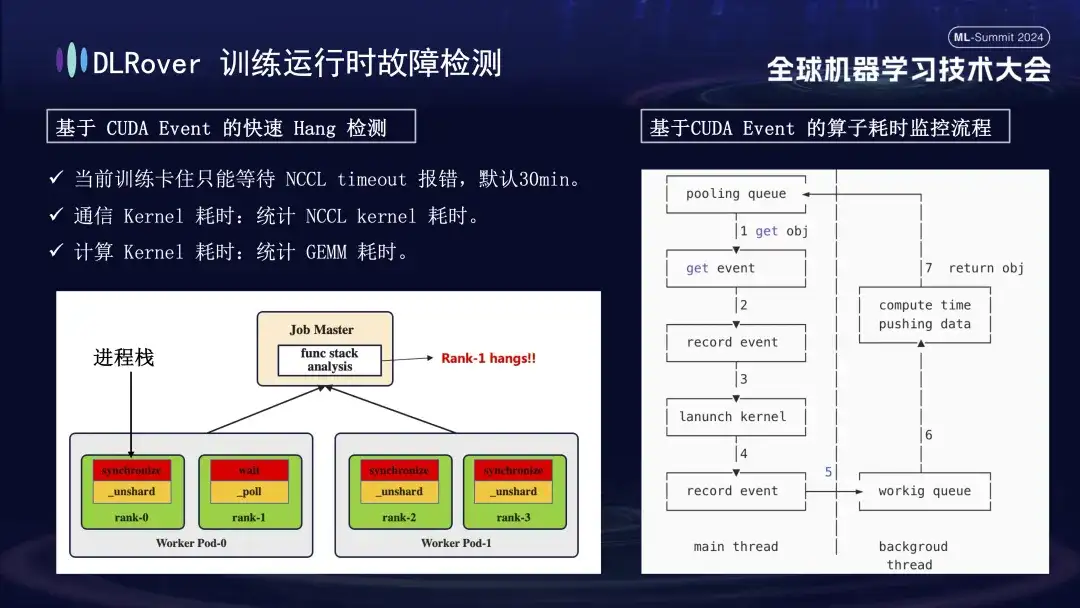
시스템 중단 및 오류 감지 상황은 이전에 논의되었지만 정지된 기계를 식별하는 문제는 해결되어야 합니다. NCCL에서 설정한 기본 시간 제한은 30분으로, 이는 오탐을 줄이기 위해 데이터 재전송을 허용합니다. 그러나 이로 인해 카드가 실제로 정지되었을 때 각 카드가 30분 동안 헛되이 기다리게 되어 막대한 누적 손실이 발생할 수 있습니다. 고착을 정확하게 진단하려면 세련된 프로파일링 도구를 사용하는 것이 좋습니다. 예를 들어 1분 이내에 프로그램 스택에 변화가 없는 등 프로그램이 일시 중지된 것으로 감지되면 각 카드의 스택 정보를 기록하고 그 차이를 비교 분석합니다. 예를 들어, 4개 랭크 중 3개 랭크가 Sync 작업을 수행하고 1개 랭크가 대기 작업을 수행하는 것으로 확인되면 해당 장치의 문제를 찾을 수 있습니다. 또한 핵심 CUDA 통신 커널과 컴퓨팅 커널을 하이재킹하고, 실행 전후에 이벤트 모니터링을 삽입하고, 이벤트 간격을 계산하여 동작이 정상적으로 실행되고 있는지 판단했습니다. 예를 들어 특정 작업이 예상 30초 이내에 완료되지 않으면 중단된 것으로 간주할 수 있으며 관련 로그 및 호출 스택이 자동으로 출력되어 비교를 위해 마스터에 제출되어 결함이 있는 시스템을 빠르게 찾을 수 있습니다.
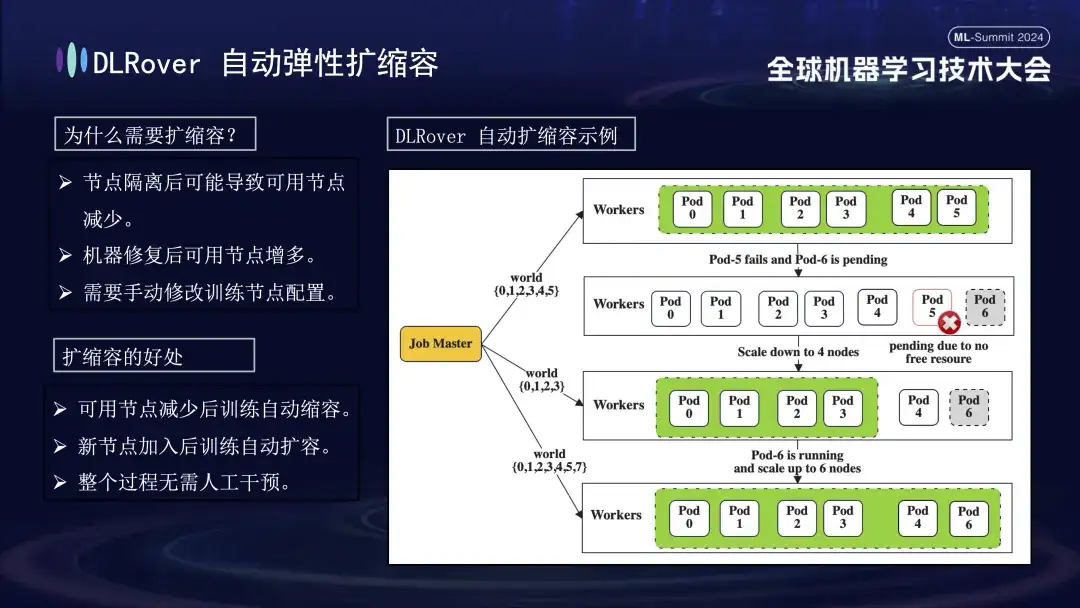
결함이 있는 기계가 식별된 후 비용과 효율성을 고려하여 이전 교육에는 백업 메커니즘이 있었지만 그 수는 제한되었습니다. 이때 탄력적인 팽창과 수축 전략을 도입하는 것이 특히 중요하다. 원래 클러스터에 100개의 노드가 있다고 가정하면, 노드 하나에 장애가 발생하면 나머지 99개 노드는 학습 작업을 계속할 수 있습니다. 장애가 발생한 노드가 복구된 후 시스템은 자동으로 100개 노드에 대한 작업을 재개할 수 있으며 이 프로세스에는 수동 개입이 필요하지 않습니다. 효율적이고 안정적인 교육 환경을 보장합니다.
DLRover 플래시 체크포인트
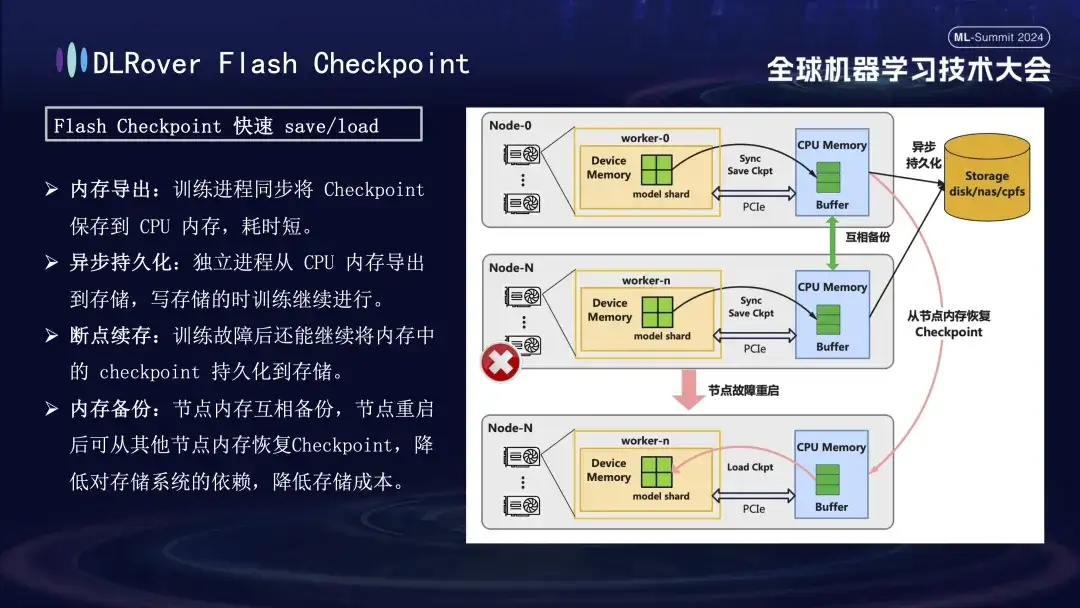
학습 실패 복구 과정에서 핵심은 모델 상태를 저장하고 복원하는 것입니다. 전통적인 체크포인트 방식은 오랜 시간 절약으로 인해 훈련 효율성이 떨어지는 경우가 많습니다. 이 문제를 해결하기 위해 DLRover는 학습 과정 중에 모델 상태를 GPU 메모리에서 메모리로 거의 실시간으로 내보낼 수 있는 Flash Checkpoint 솔루션을 혁신적으로 제안했습니다. 노드에 장애가 발생하면 백업 노드 메모리에서 훈련 상태를 신속하게 복원하여 장애 복구 시간을 크게 단축할 수 있습니다. 일반적으로 사용되는 Megatron-LM의 경우 Checkpoint 내보내기 프로세스에는 조정 및 완료를 위한 중앙 집중식 프로세스가 필요하므로 추가적인 통신 부담과 메모리 소비가 발생할 뿐만 아니라 시간 비용도 높아집니다. DLRover는 각 컴퓨팅 노드(순위)가 자체 체크포인트를 독립적으로 저장하고 로드할 수 있도록 분산 내보내기 전략을 사용하여 최적화 후 혁신적인 접근 방식을 채택하여 추가 통신 및 메모리 요구 사항을 효과적으로 방지하고 효율성을 크게 향상시켰습니다.
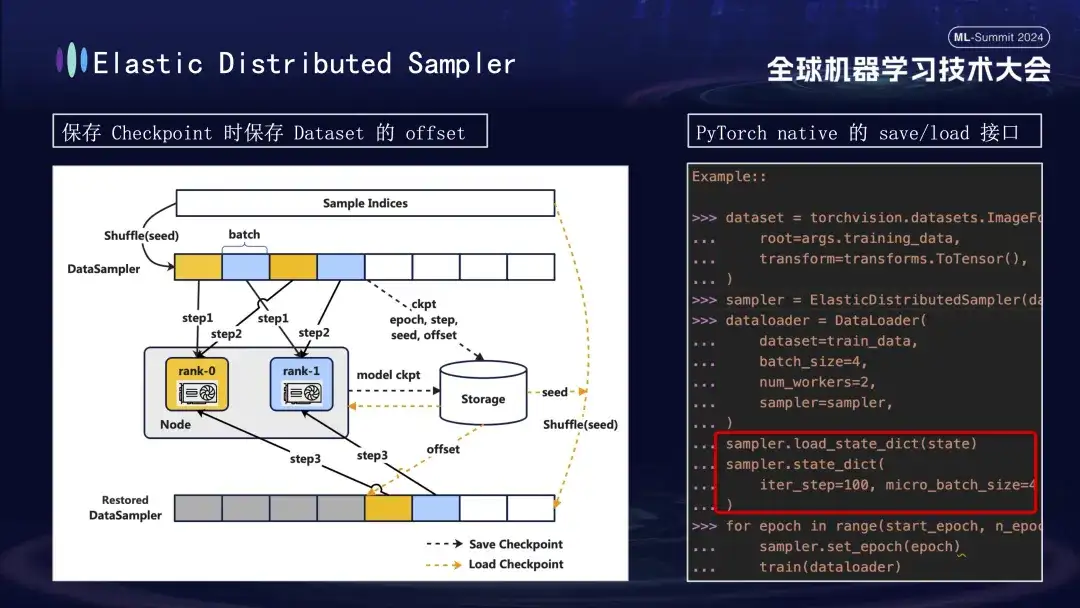
모델 체크포인트를 생성할 때 주목해야 할 또 다른 세부 사항이 있습니다. 모델 훈련은 훈련 프로세스의 1000단계에서 체크포인트를 저장한다는 가정 하에 데이터를 기반으로 합니다. 데이터 진행 상황을 고려하지 않고 나중에 훈련을 다시 시작하는 경우 데이터를 처음부터 직접 다시 사용하면 두 가지 문제가 발생합니다. 후속 새 데이터가 누락될 수 있고 이전 데이터가 재사용될 수 있습니다. 이 문제를 해결하기 위해 우리는 분산 샘플러 전략을 도입했습니다. 체크포인트를 저장할 때 이 전략은 모델 상태를 기록할 뿐만 아니라 읽은 데이터의 오프셋 위치도 저장합니다. 이런 방식으로 훈련을 재개하기 위해 체크포인트를 로드할 때 이전에 저장된 오프셋 지점부터 데이터 세트를 계속 로드한 후 훈련을 진행함으로써 모델 훈련 데이터의 연속성과 일관성을 보장하고 데이터 오류나 반복 처리를 방지합니다. .
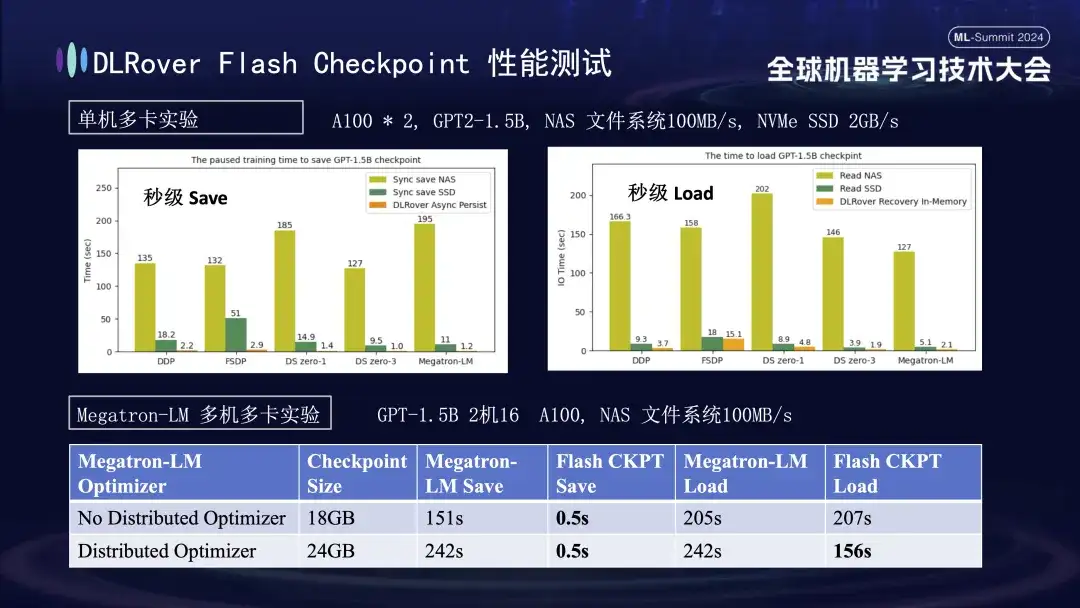
위 차트에서는 단일 머신 다중 GPU(A100) 환경에서의 실험 결과를 보여 주며, 학습 과정 중 체크포인트 저장으로 인한 차단 시간에 대한 다양한 스토리지 솔루션의 영향을 비교하는 것을 목표로 합니다. 실험에 따르면 스토리지 시스템의 성능이 효율성에 직접적인 영향을 미치는 것으로 나타났습니다. 덜 효율적인 스토리지 방법을 사용하여 체크포인트를 디스크에 직접 쓰는 경우 교육이 크게 차단되고 시간이 연장됩니다. 구체적으로 약 20GB 크기의 1.5B 모델 체크포인트의 경우 NAS 스토리지를 사용하면 쓰기 시간이 약 2~3분 정도 되는데, 최적화 전략을 채택하면 데이터를 메모리에 비동기적으로 임시 저장하는 방식을 채택하면 크게 단축될 수 있다. 이 과정은 평균 1초 정도 밖에 걸리지 않아 훈련의 연속성과 효율성이 크게 향상됩니다.

DLRover의 Flash Checkpoint 기능은 DDP, FSDP, DeepSpeed, Megatron-LM, Transformers.Trainer 및 Ascend-DDP를 포함한 주요 주류 대형 모델 교육 프레임워크와 광범위하게 호환됩니다. 각 프레임워크에 대한 맞춤형 API가 있어 사용자가 매우 쉽게 사용할 수 있습니다. 기존 학습 코드를 조정할 필요가 거의 없으며 즉시 사용할 수 있습니다. 특히 DeepSpeed 프레임워크 사용자는 Checkpoint를 실행할 때 DLRover의 저장 인터페이스만 호출하면 되는데, Megatron-LM의 통합은 훨씬 더 간단합니다. 기본 Checkpoint 가져오기 문을 DLRover에서 제공하는 가져오기 방법으로 바꾸기만 하면 됩니다. . 할 수 있다.
DLRover 분산 훈련 실습
우리는 시스템의 내결함성, 느린 노드 처리 능력, 확장 및 축소 유연성을 평가하기 위해 각 오류 시나리오에 대해 일련의 실험을 수행했습니다. 구체적인 실험은 다음과 같습니다.
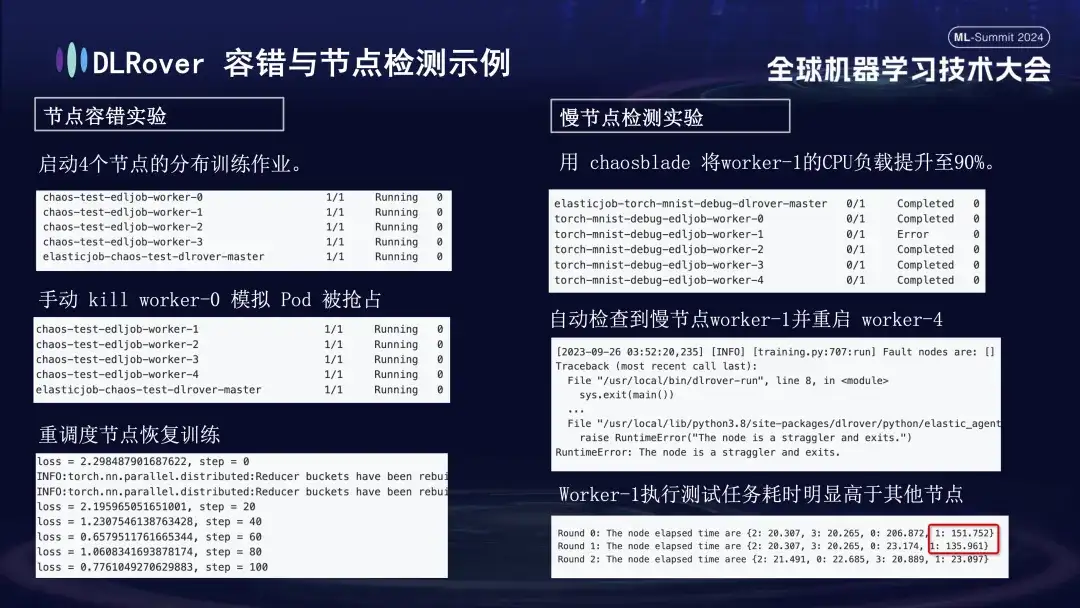
- 노드 내결함성 실험: 일부 노드를 수동으로 종료하여 클러스터가 빠르게 복구될 수 있는지 테스트합니다.
- 느린 노드 실험: 카오스블레이드 도구를 사용하여 노드의 CPU 로드를 90%로 늘려 시간이 많이 걸리는 느린 노드 상황을 시뮬레이션합니다.
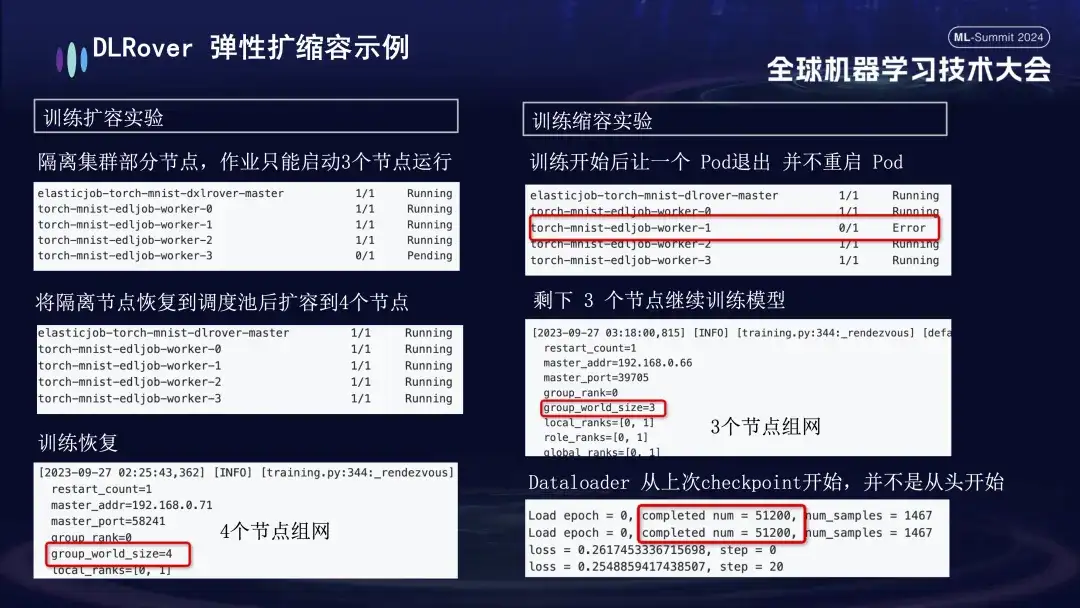
- 팽창 및 수축 실험: 기계 자원이 부족한 시나리오를 시뮬레이션합니다. 예를 들어 작업이 4개의 노드로 구성되었지만 실제로는 3개만 시작된 경우 이 3개의 노드는 여전히 정상적으로 학습될 수 있습니다. 일정 시간이 지난 후 노드 격리를 시뮬레이션했고 훈련에 사용할 수 있는 포드 수가 3개로 줄었습니다. 이 머신이 예약 대기열로 돌아오면 사용 가능한 Pod 수를 4개로 늘릴 수 있습니다. 이때 Dataloader는 다시 시작하는 대신 마지막 체크포인트부터 계속 학습합니다.
DLRover의 국내 카드 업무
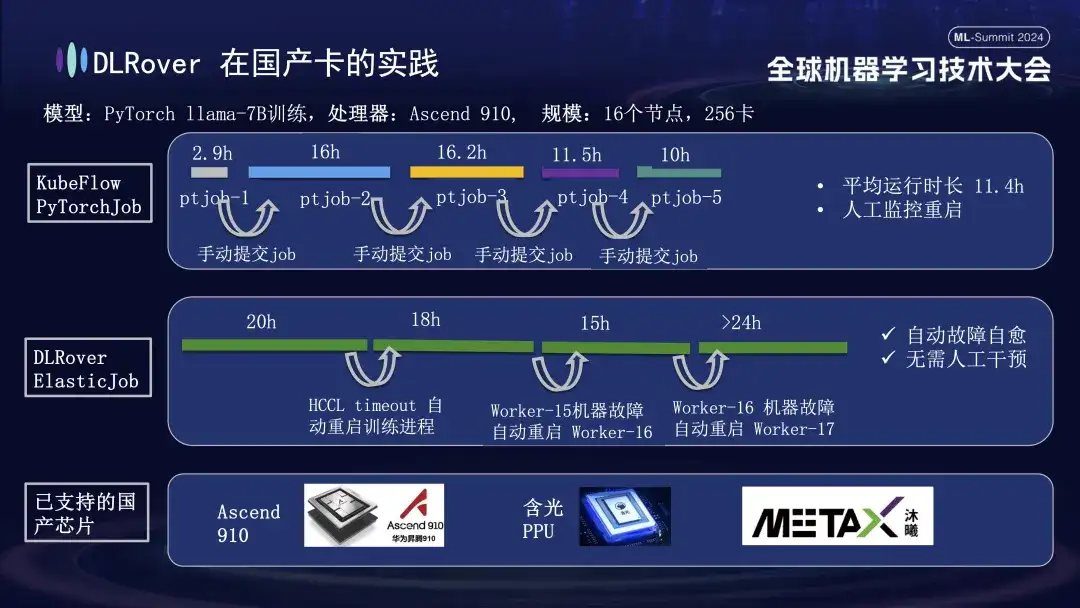
DLRover 결함 자가 치유는 GPU 지원 외에도 국내 가속기 카드의 분산 훈련도 지원합니다. 예를 들어 Huawei Ascend 910 플랫폼에서 LLama-7B 모델을 실행할 때 대규모 훈련에 256개의 카드를 사용했습니다. 처음에는 KubeFlow의 PyTorchJob을 사용했지만 이 도구에는 내결함성이 없었기 때문에 약 10시간 동안 지속된 후 훈련 프로세스가 자동으로 종료되고 나면 사용자는 작업을 수동으로 다시 제출해야 했습니다. 게으른. 두 번째 다이어그램은 훈련 결함 자가 치유가 활성화된 전체 훈련 프로세스를 보여줍니다. 20시간 동안 훈련을 진행했을 때 통신 시간 초과 오류가 발생하여 시스템이 자동으로 훈련 과정을 다시 시작하고 훈련을 재개했습니다. 약 40시간 후, 시스템 하드웨어 오류가 발생했습니다. 시스템은 결함이 있는 시스템을 신속하게 격리하고 훈련을 계속하기 위해 포드를 다시 시작했습니다. Huawei Ascend 910을 지원하는 것 외에도 Alibaba의 Hanguang PPU와도 호환되며 Muxi Technology와 협력하여 DLRover를 사용하여 자체 개발한 Qianka GPU에서 LLAMA2-65B 모델을 훈련합니다.
DLR1,000장 이상의 카드, 1,000억 개의 모델 훈련 실습
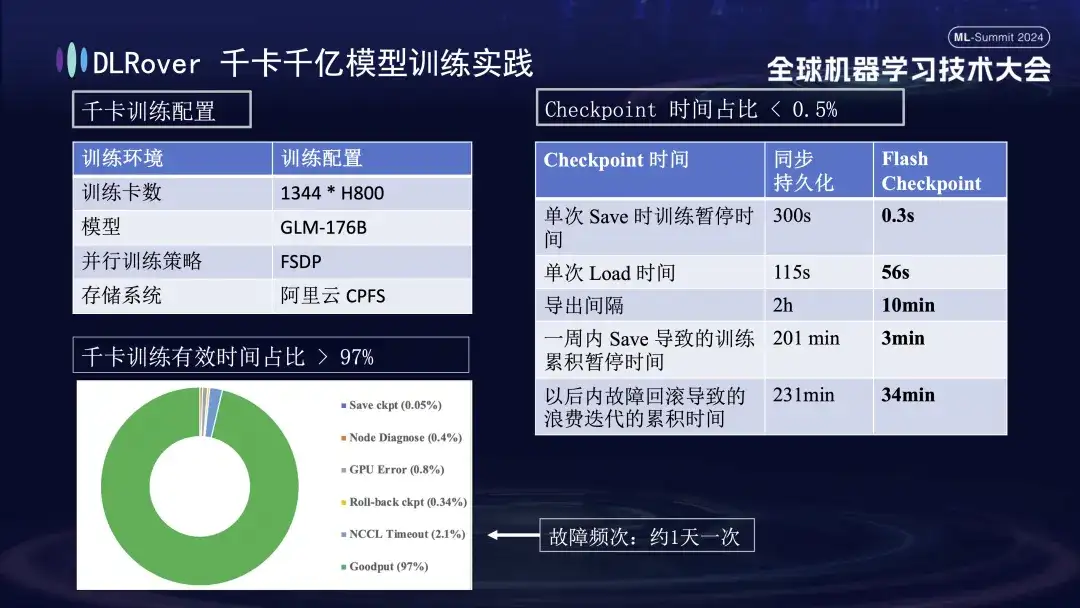
위 그림은 킬로 카드 훈련에 대한 DLRover 훈련 결함 자가 치유의 실질적인 효과를 보여줍니다. 1,000개 이상의 H800 카드가 대규모 모델 훈련을 실행하는 데 사용됩니다. 결함 빈도가 하루에 한 번인 경우 훈련 결함 자가 치유가 이루어집니다. 힐링 기능이 도입되어 효과적인 훈련 시간이 97% 이상을 차지합니다. 오른쪽 비교표는 Alibaba Cloud의 고성능 스토리지 FSDP를 사용할 때 단일 저장에 약 5분이 소요되는 반면, Flash Checkpoint 기술은 완료하는 데 0.3초밖에 걸리지 않음을 보여줍니다. 또한 최적화를 통해 노드 효율이 1분 가까이 향상되었습니다. 내보내기 간격은 원래 2시간마다 내보내기 작업이 수행되었으나 Flash Checkpoint 기능이 출시된 이후에는 10분마다 고주파 내보내기가 가능해졌습니다. 일주일 동안 저장 작업에 소비된 누적 시간은 거의 무시할 수 있습니다. 동시에 롤백 시간도 기존에 비해 약 5배 단축됐다.
DLR계획 및 커뮤니티 구축

DLRover는 현재 세 가지 주요 버전을 출시했습니다. 6월에 V0.4.0을 출시할 예정이며, CUDA 이벤트를 기반으로 하는 런타임 오류 감지 기능이 출시될 예정입니다.
- V0.1.0(2023/07): k8s/ray에서 TensorFlow PS의 탄력적 내결함성 및 자동 확장 및 축소;
- V0.2.0(2023/09): k8s의 PyTorch 동기 훈련을 위한 노드 감지 및 탄력적 내결함성;
- V0.3.5(2024/03): 플래시 체크포인트 및 국내 카드 오류 감지;
향후 계획 측면에서 DLRover는 노드 예약 및 관리, Lynx 편집 및 최적화, 훈련 최적화 프레임워크 AToch 및 국내 카드 훈련 측면에서 DLRover의 기능을 지속적으로 최적화하고 개선할 것입니다.
- **노드 스케줄링 및 관리: **통신 토폴로지 인식 스케줄링, 링 기반 AllReduce 통신 중 최상위 스위치의 통신 트래픽 감소;
- **컴파일 최적화 lynx: **계산 그래프 스케줄링 최적화, 최적의 통신 및 계산 중첩 달성, 통신 지연 숨기기;
- **훈련 최적화 프레임워크 ATorch: **RLHF 훈련 최적화, 분산 훈련의 초기화 가속 auto_accelerate;
- **국내 카드 트레이닝: **장애 자가 치유, 트레이닝 가속화 등의 기능을 국내 카드 트레이닝에 대한 모범 사례로 제공합니다.

기술 발전은 개방형 협업에서 시작됩니다. 누구나 GitHub의 오픈 소스 프로젝트를 팔로우하고 참여할 수 있습니다.
DLR오버:
https://github.com/intelligent-machine-learning/dlrover
글레이크:
https://github.com/intelligent-machine-learning/glake
WeChat 공개 계정인 'AI Infra'에서는 최신 연구 결과와 기술적 통찰력을 공유하는 것을 목표로 AI 인프라에 대한 최첨단 기술 기사를 정기적으로 게시할 예정입니다. 동시에, 더 많은 교류와 토론을 촉진하기 위해 DingTalk 그룹도 구성했습니다. 누구나 여기에 참여하여 질문하고 관련 기술 문제를 논의할 수 있습니다. 다들 감사 해요!
기사 추천
AI 훈련 컴퓨팅 전력 효율성 향상: Ant DLRover 결함 자가 치유 기술의 혁신적 실천
AI 인프라 설계사를 만나다: 고속 대형 '레이싱카'를 타고 '바퀴를 바꾸는' 사람
[온라인 다시보기] NVIDIA GTC 2024 컨퍼런스 AI 엔지니어링 비용을 줄이는 방법은? 학습부터 추론까지 Ant의 풀스택 실습
