
OpenAI가 ChatGPT-4o를 출시했습니다. 이는 인간과 컴퓨터의 상호 작용이 새로운 시대에 진입했음을 의미합니다. Chat-GPT4o는 동일한 신경망에서 처리되는 모든 입력과 출력을 사용하여 텍스트, 시각, 오디오 전반에 걸쳐 엔드투엔드 교육을 받은 새로운 모델입니다. 이는 또한 GenAI가 비정형 데이터를 연결하고 비정형 데이터 간의 교차 모드 상호 작용이 점점 더 쉬워지고 있음을 모든 사람에게 알려줍니다.
IDC 예측에 따르면 2025년까지 전체 글로벌 데이터의 80% 이상이 비정형 데이터가 될 것이며 벡터 데이터베이스는 비정형 데이터를 처리하는 중요한 구성 요소입니다. 벡터 데이터베이스의 역사를 되돌아보면, Zilliz는 2019년에 처음으로 Milvus를 출시하고 벡터 데이터베이스의 개념을 제안했습니다. 2023년 LLM(대형 언어 모델)의 폭발적인 증가로 인해 공식적으로 벡터 데이터베이스가 뒤에서 앞으로 밀려나고 급속한 개발 흐름을 따라잡게 되었습니다.
관련 기술인으로서 기술 발전 측면에서 벡터 데이터베이스의 발전 속도를 확실히 느낄 수 있으며, 단순한 ANNS에서 벡터 데이터베이스가 점차 진화하는 모습을 목격할 수 있습니다( https://zilliz.com.cn/glossary/%E8%BF% 91% E4%BC%BC%E6%9C%80%E8%BF%91%E9%82%BB%E6%90%9C%E7%B4%A2%EF%BC%88anns%EF%BC%89) Shell 더욱 다양해지고 복잡해졌습니다. 오늘은 기술적인 관점에서 벡터 데이터베이스의 발전 방향에 대해 논의해보고자 합니다.
기술의 발전 방향은 제품의 변화 추세에 따라야 하며, 후자는 수요에 따라 결정됩니다. 따라서 사용자 요구의 변화하는 맥락을 따라가는 것은 기술 변화의 방향과 목적을 찾는 데 도움이 될 수 있습니다. AI 기술이 성숙해짐에 따라 벡터 데이터베이스의 사용은 실험에서 생산으로, 보조 제품에서 주요 제품으로, 소규모 애플리케이션에서 대규모 배포로 점차 이동했습니다. 이로 인해 다양한 시나리오와 문제가 발생하고 이러한 문제를 해결하기 위한 해당 기술이 촉진됩니다. 아래에서는 비용과 비즈니스 요구라는 두 가지 측면에서 이를 논의합니다.
01. 비용
AIGC 시대의 온냉 저장 요구
비용은 벡터 데이터베이스의 광범위한 사용에 가장 큰 장애물 중 하나였습니다. 이 비용은 두 가지 점에서 발생합니다.
-
스토리지. 낮은 대기 시간을 보장하기 위해 대부분의 벡터 데이터베이스는 메모리나 로컬 디스크에 모든 데이터를 캐시해야 합니다. 흔히 수백억 대에 달하는 이 AI 시대에는 수십, 수백 테라바이트의 자원 소비를 의미한다.
-
컴퓨팅의 경우 대규모 데이터 세트에 대한 분산 지원에 대한 엔지니어링 요구 사항을 충족하려면 데이터를 여러 개의 작은 조각으로 나누어야 합니다. 각 샤드를 별도로 검색하고 우회해야 하므로 더 큰 쿼리 계산 증폭 문제가 발생합니다. 수백억 개의 데이터를 10G 샤드로 쪼개면 샤드가 1만개가 되는데, 계산이 1만배로 확대된다는 뜻이다.
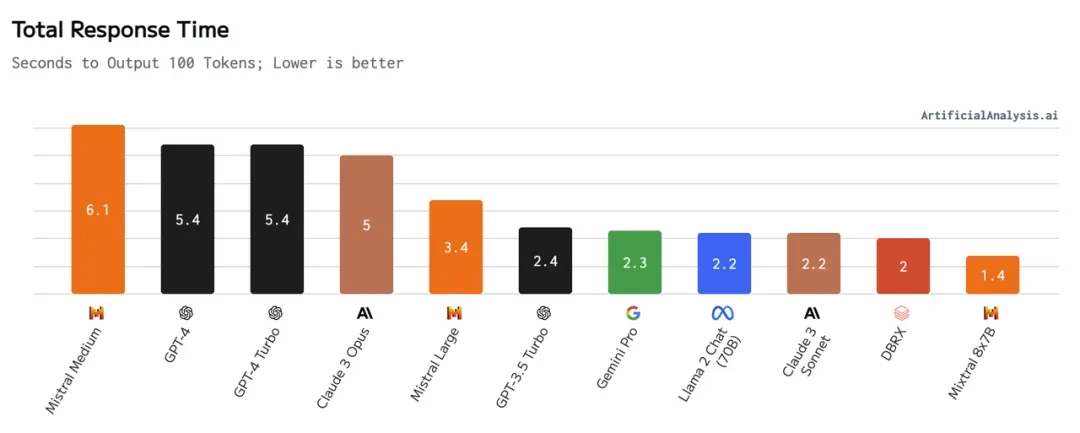 주류 LLM의 응답 시간, 출처: https://artificialanalytic.ai/models
주류 LLM의 응답 시간, 출처: https://artificialanalytic.ai/models
AIGC가 가져온 RAG 물결에서 단일 RAG 사용자(또는 ToC 플랫폼의 단일 테넌트)는 지연에 대한 민감도가 매우 낮습니다. 그 이유는 벡터 데이터베이스의 지연 시간이 수 밀리초에서 수백 밀리초에 달하는 것에 비해 링크의 핵심인 대형 모델의 지연 시간은 일반적으로 두 번째 수준을 초과하기 때문입니다. 또한 클라우드 개체 스토리지의 비용은 로컬 디스크 및 메모리의 비용보다 훨씬 저렴합니다.
-
스토리지 관점에서 볼 때, 데이터는 가장 저렴한 클라우드 객체에 콜드 스토리지로 배치되며, 필요할 경우 노드에 로드된 후 핫 스토리지로 변환되어 쿼리를 제공합니다.
-
전산적인 관점에서 각 쿼리에 필요한 데이터를 글로벌 데이터로 확장하지 않고 미리 압축하여 핫 스토리지가 침투하지 않도록 합니다.
이 기술은 사용자가 허용 가능한 지연 시간 내에서 비용을 크게 절감할 수 있도록 도와줍니다. 이는 현재 Zilliz Cloud(https://zilliz.com.cn/cloud)가 출시를 준비 중인 솔루션이기도 합니다.
하드웨어 반복이 가져온 기회
하드웨어는 모든 것의 기초이며, 하드웨어의 발전은 벡터 데이터베이스 기술의 발전 방향을 직접적으로 결정합니다. 다양한 시나리오에서 이러한 하드웨어를 어떻게 적응하고 활용하는가가 매우 중요한 개발 방향이 되었습니다.
- 비용 효율적인 GPU
벡터 검색은 컴퓨팅 집약적인 애플리케이션이며, 지난 2년 동안 컴퓨팅 가속을 위해 GPU를 사용하는 연구가 점점 더 많아졌습니다. 값비싼 고정관념과는 달리, 알고리즘 수준이 점진적으로 성숙해지고 벡터 검색 시나리오가 메모리 지연 시간이 낮은 저렴한 추론 카드에 적합하다는 사실로 인해 GPU 기반 벡터 검색은 뛰어난 비용 효율성을 보여줍니다.
 CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge 상위 100 리콜: 98% 데이터 세트: https://github.com/zilliztech/VectorDBBench
CPU: m6id.2xlarge T4: g4dn.2xlarge A10G: g5.2xlarge 상위 100 리콜: 98% 데이터 세트: https://github.com/zilliztech/VectorDBBench
테스트를 위해 GPU 인덱싱을 지원하는 Milvus를 사용했습니다. 단 2~3배의 비용으로 인덱스 구축과 벡터 검색 모두 수 배에서 수십 배의 성능 격차를 보였습니다. 처리량이 많은 시나리오를 지원하든 인덱스 구성 속도를 높이든 벡터 데이터베이스 사용 비용을 크게 줄일 수 있습니다.
- 끊임없이 변화하는 ARM
주요 클라우드 벤더들은 AWS의 Graviton, GCP의 Ampere 등 ARM 아키텍처 기반의 자체 CPU를 지속적으로 출시하고 있습니다. AWS Graviton3에서 관련 테스트를 수행한 결과 x86에 비해 더 저렴한 하드웨어를 제공하면서도 더 나은 성능을 제공할 수 있다는 사실을 확인했습니다. 더욱이 이러한 CPU는 매우 빠르게 발전하고 있습니다. 예를 들어 AWS는 2022년 Graviton3을 출시한 후 2023년에 컴퓨팅 성능이 30% 증가하고 메모리 대역폭이 70% 증가한 Graviton4를 출시했습니다 . com/2023/11/aws-차세대 aws 설계 칩 공개).
- 강력한 디스크
대부분의 데이터를 디스크에 저장하면 벡터 데이터베이스가 용량을 크게 늘리고 수백 밀리초의 대기 시간을 달성하는 데 도움이 될 수 있습니다. 이 수준은 대부분의 경우 충분하며 디스크 비용은 메모리의 수십 또는 심지어 1%입니다.
모델 측 양방향 돌진
모델은 벡터를 생성하고, 벡터 데이터베이스는 벡터 저장 및 쿼리를 지원합니다. 전체적으로는 벡터 데이터베이스 측의 비용 절감을 추구하는 것 외에도 모델 측에서도 벡터의 크기를 줄이려고 노력하고 있습니다.
예를 들어, 벡터 차원에서는 벡터에 도입된 전통적인 차원 축소 방식이 쿼리 정확도에 더 큰 영향을 미치며, OpenAI에서 출시한 ext-embedding-3-large( https://openai.com/index/ new -embedding-models-and-api-updates/) 모델은 매개변수를 통해 출력 벡터의 차원을 제어할 수 있지만 벡터 차원은 줄어들지만 다운스트림 작업 성능에는 거의 영향을 미치지 않습니다. 벡터 데이터 유형에 관해서는 Cohere 의 최근 블로그( https://cohere.com/blog/int8-binary-embeddings)에서 float, int8 및 바이너리 데이터 유형의 벡터를 동시에 출력하는 지원을 발표했습니다. 벡터 데이터베이스의 경우 이러한 변화에 어떻게 적응할 것인지도 적극적으로 모색해야 할 방향이다.
02.비즈니스 요구사항
벡터 검색 정확도 향상
검색의 정확성은 항상 중요한 주제였습니다. 광범위한 생산 애플리케이션으로 인해 또는 RAG 애플리케이션의 더 높은 관련성 요구 사항으로 인해 벡터 데이터베이스는 더 높은 검색 품질을 위해 노력하고 있습니다. 이 과정에서 너무 큰 덩어리로 인한 정보 손실 문제를 해결하는 ColBERT, 도메인 외부 정보 검색 문제를 해결하는 Sparse 등 새로운 기술이 끊임없이 등장하고 있습니다. 아래 그림은 BGE의 M3-Embedding 모델의 평가 결과를 보여주며, Sparse, Dense 및 ColBERT 벡터의 동시 출력을 지원할 수 있습니다. 아래 표는 이를 이용한 하이브리드 검색 결과를 보여줍니다.

벡터 데이터베이스의 경우 하이브리드 검색에 이러한 기술을 사용하여 검색 품질을 향상시키는 방법도 중요한 개발 방향입니다.
- 콜버트
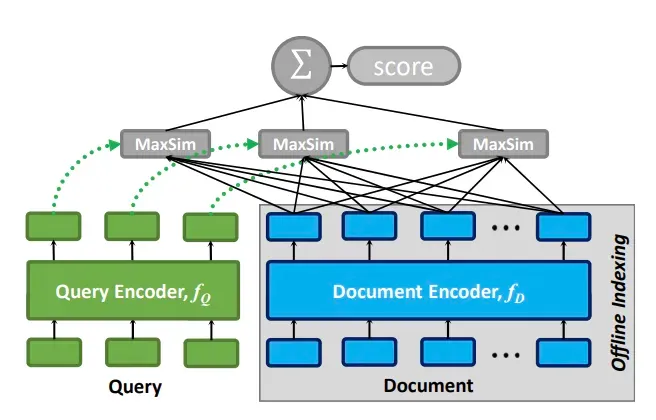
ColBERT는 전통적인 트윈 타워 모델에서 큰 덩어리로 인해 발생하는 정보 손실 문제를 해결하는 동시에 기존 검색 모델의 완전한 연결로 인해 발생하는 검색 효율성 문제를 피하기 위해 검색 모델을 제안했습니다. 토큰 벡터를 기반으로 하는 늦은 상호 작용 모드. 벡터 검색은 ColBERTv2에도 도입되어 최종 후기 상호 작용 모드의 속도를 높입니다.
- 부족한
기존의 Dense 벡터는 의미 정보를 포착하는 데는 좋지만 모델 훈련 중에 훈련 데이터에 있는 지식만 학습할 수 있기 때문에 Dense 벡터는 훈련 데이터에서 다루지 않는 새로운 어휘나 전문 용어에 대한 표현 능력이 제한됩니다. 그리고 이것은 실제 적용에서 매우 일반적입니다. 일반 모델의 미세 조정을 통해 이 문제를 어느 정도 해결할 수 있지만 비용이 많이 들고 실시간 성능에 어려움을 겪게 됩니다.
이때 전통적인 키워드 매칭을 기반으로 BM25에서 생성된 희소 벡터가 좋은 성능을 발휘합니다. 또한 SPLADE 및 BGE의 M3-Embedding과 같은 모델은 검색 품질을 더욱 향상시키기 위해 희소 벡터의 키워드 일치 기능을 유지하면서 더 많은 정보를 인코딩하려고 시도합니다.
실제로 업계에서는 오랫동안 키워드 검색과 벡터 검색을 기반으로 한 하이브리드 회상 시스템을 사용해 왔습니다. 벡터 데이터베이스에 차세대 희소 벡터를 통합하고 하이브리드 검색 기능을 지원하는 것이 점차 합의가 되었습니다. Milvus는 또한 버전 2.4에서 희소 벡터 검색 기능을 공식적으로 지원합니다.
오프라인 시나리오를 위해 벡터 데이터베이스를 더욱 최적화합니다.
현재 거의 모든 벡터 데이터베이스는 RAG( https://zilliz.com.cn/blog/ragbook-technology-development), 이미지 검색(https://zilliz.com.cn/use-cases) 을 포함한 온라인 시나리오에 중점을 두고 있습니다. /이미지-유사성-검색) 등
온라인 시나리오는 작은 볼륨, 높은 빈도, 높은 대기 시간 요구 사항이 특징입니다. 가장 비용에 민감하고 성능이 가장 중요하지 않은 시나리오에서도 종종 초 수준의 대기 시간이 필요합니다.
실제로 벡터 검색은 대규모 데이터 처리의 많은 오프라인 시나리오에서 중요한 역할을 합니다. 예를 들어 데이터 중복 제거 및 기능 마이닝과 같은 일괄 처리 작업이나 벡터 유사성을 재현 신호 중 하나로 사용하는 검색 및 추천 시스템은 일반적으로 벡터 검색을 오프라인 사전 계산 단계로 사용하고 기능 업데이트를 정기적으로 수행합니다. 이러한 오프라인 시나리오는 일괄 쿼리, 대량의 데이터 등이 특징이며 작업에 소요되는 시간 요구 사항은 몇 분 또는 몇 시간이 될 수 있습니다.
오프라인 시나리오를 지원하려면 벡터 데이터베이스가 많은 새로운 문제를 해결해야 합니다. 다음은 몇 가지 예입니다.
-
컴퓨팅 효율성: 많은 오프라인 시나리오에는 일부 검색 및 추천 시나리오의 오프라인 컴퓨팅 부분과 같이 대량의 데이터에 대한 효율적인 일괄 쿼리가 필요합니다. 이 시나리오에서는 개별 데이터의 지연이 필요하지 않지만 온라인 시나리오보다 전체적으로 더 높은 계산 효율성이 필요합니다. 이러한 유형의 문제를 더 잘 지원하려면 계산 밀도를 높이는 GPU 인덱싱과 같은 기능을 지원해야 합니다.
-
큰 수익: 데이터 마이닝은 종종 벡터 검색을 사용하여 모델이 특정 유형의 장면을 찾는 데 도움을 줍니다. 이를 위해서는 일반적으로 많은 양의 데이터를 반환해야 합니다. 이러한 반환된 결과로 인해 발생하는 대역폭 문제를 처리하는 방법과 대규모 topK 검색의 알고리즘 효율성이 이러한 시나리오를 지원하는 핵심입니다.
위의 문제가 해결될 수 있다면 벡터 데이터베이스는 온라인 애플리케이션뿐만 아니라 더 많은 시나리오에서 애플리케이션을 광범위하게 지원할 수 있습니다.
더 풍부한 벡터 데이터베이스 기능은 더 많은 산업 요구에 적응합니다.
벡터 데이터베이스가 생산에 점점 더 널리 사용됨에 따라 다양한 사용 방법이 등장했으며 다양한 산업에서도 사용됩니다. 산업 및 특정 시나리오와 관련성이 높은 이러한 요구 사항은 벡터 데이터베이스가 점점 더 많은 기능을 지원하도록 안내합니다.
-
바이오제약 산업: 검색을 위한 약물 분자식을 표현하는 데 일반적으로 바이너리 벡터가 사용됩니다.
-
위험 통제 산업: 가장 유사한 벡터가 아닌 가장 이상치 벡터를 찾아야 합니다.
-
범위 검색 기능: 사용자는 유사성 임계값을 설정하고 임계값보다 유사성이 높은 모든 결과를 반환할 수 있습니다. 결과 수를 추정할 수 없는 경우에도 반환된 결과의 관련성이 높다는 것을 확인할 수 있습니다.
-
Groupby 및 Aggregation 기능: 구조화되지 않은 대규모 데이터 쌍(영화, 기사)의 경우 일반적으로 프레임이나 텍스트 조각과 같은 세그먼트로 벡터를 생성합니다. 이러한 분할된 벡터를 통해 요구 사항을 충족하는 결과를 검색하려면 벡터 데이터베이스가 Groupby 및 결과 집계 기능을 지원해야 합니다.
-
다중 모드 모델 지원: 다중 모드 모델을 향한 모델 개발 추세로 인해 분포가 다른 벡터가 생성되므로 기존 알고리즘에서 검색 요구 사항을 충족하기가 어렵습니다.
위에서 언급한 다양한 산업 분야의 향상된 기능은 벡터 데이터베이스의 역동적인 개발 특성을 강조합니다. 벡터 데이터베이스는 다양한 산업 분야의 AI 애플리케이션의 복잡한 요구 사항을 충족하기 위해 더욱 풍부한 기능을 도입하기 위해 지속적으로 업그레이드되고 최적화될 것입니다.
03. 요약
벡터 데이터베이스는 지난 해 급속한 성숙 과정을 경험했으며, 사용 시나리오와 벡터 데이터베이스 자체의 기능 측면에서 큰 발전이 있었습니다. 점점 더 가시화되는 AI 시대에 이러한 추세는 더욱 가속화될 것입니다. 저는 이러한 개인적인 요약과 분석이 영감을 주고, 벡터 데이터베이스 개발을 위한 몇 가지 아이디어와 영감을 제공하며, 미래에 더욱 흥미로운 변화를 수용할 수 있기를 바랍니다.
알려지지 않은 오픈 소스 프로젝트가 얼마나 많은 수익을 가져올 수 있습니까? Microsoft의 중국 AI 팀은 수백 명의 사람들을 모아 미국으로갔습니다. Huawei는 Yu Chengdong의 직업 변경이 15년 동안 "FFmpeg Pillar of Shame"에 못 박혔다 고 공식 발표했습니다. 이전에는 그랬지만 오늘은 우리에게 감사해야 합니다.— Tencent QQ Video가 과거의 굴욕을 복수한다고요? Huazhong University of Science and Technology의 오픈 소스 미러 사이트가 외부 액세스 보고를 위해 공식적으로 공개되었습니다 . Django는 여전히 74%의 개발자가 선택한 제품입니다. Zed 편집자는 유명한 오픈 소스 회사의 전직 직원이었습니다 . 소식을 전했습니다: 기술 리더는 부하 직원의 도전을 받은 후 격노하고 무례하게 행동하여 해고되었으며 임신했습니다. 여직원 Alibaba Cloud가 공식적으로 Tongyi Qianwen 2.5를 출시했습니다. Microsoft는 Rust Foundation에 100만 달러를 기부했습니다.