
저자 소개: 시스템 최하위 계층/네트워크 최적화에 초점을 맞춘 Soutui/LLM 훈련 최적화에 종사하는 Zhang Ji.
배경
대규모 모델의 매개변수 수가 수십억에서 수조로 증가함에 따라 훈련 규모의 급속한 확장은 클러스터 비용의 상당한 증가를 유발할 뿐만 아니라 시스템 안정성에 문제를 야기하며, 특히 기계 고장이 자주 발생합니다. 무시할 수 없는 문제. 대규모 분산 교육 작업의 경우 관측 가능성 기능이 문제 해결 및 성능 최적화의 핵심이 되었습니다. 따라서 대규모 모델 훈련 분야에 종사하는 기술 인력은 필연적으로 다음과 같은 과제에 직면하게 됩니다.
- 훈련 과정 중에 네트워크 및 컴퓨팅 병목 현상과 같은 다양한 요인으로 인해 성능이 불안정하거나 변동하거나 심지어 저하될 수도 있습니다.
- 분산 훈련에는 여러 노드가 함께 작동하는 작업이 포함됩니다. 소프트웨어, 하드웨어, 네트워크 카드 또는 GPU 문제 등 노드에 장애가 발생하면 전체 훈련 프로세스가 일시 중단되어 훈련 효율성에 심각한 영향을 미치고 귀중한 GPU 리소스가 낭비됩니다.
그러나 실제 대규모 모델 학습 과정에서는 이러한 문제를 해결하기가 어렵습니다. 주된 이유는 다음과 같습니다.
- 훈련 프로세스는 동기식 작업이며 전반적인 성능 지표를 통해 현재 어떤 기계에 문제가 있는지 배제하기 어렵습니다. 기계가 느리면 전체 훈련 속도가 느려질 수 있습니다.
- 느린 훈련 성능은 훈련 로직/프레임워크의 문제가 아닌 경우가 많지만 일반적으로 훈련 관련 모니터링 데이터가 없으면 타임라인 인쇄가 실제로 효과가 없으며 타임라인 파일을 저장하기 위한 스토리지 요구 사항도 있습니다. 높은;
- 예를 들어, 훈련이 중단되면 토치 시간이 초과되기 전에 모든 스택의 인쇄를 완료한 다음 이를 분석해야 합니다. 대규모 작업에 직면하면 토치 시간 초과 내에 완료하기가 어렵습니다.
대규모 분산 훈련 운영에서 관찰 가능한 기능은 문제 해결 및 성능 개선에 특히 중요합니다. 대규모 훈련을 실행하면서 Ant는 AI 훈련의 관찰 가능성 요구 사항을 충족하기 위해 xpu_timer 라이브러리를 개발했습니다. 앞으로는 소스 xpu 타이머를 DLRover에 공개할 예정입니다. 누구나 협력하고 함께 구축할 수 있습니다. :) xpu_timer 라이브러리는 cublas/cudart 라이브러리를 가로채고 cudaEvent를 사용하여 행렬 곱셈/설정 통신 작업 시간을 측정하는 프로파일링 도구입니다. training, 타임라인 분석, 행 감지, 행 스택 분석 등의 기능도 갖추고 있으며 다양한 이기종 플랫폼을 지원하도록 설계되었습니다. 이 도구에는 다음과 같은 기능이 있습니다.
- 코드에 대한 침입이나 훈련 성능의 손실이 없으며 훈련 과정에 상주할 수 있습니다.
- 사용자에게 무관심하고 프레임워크와 관련이 없음
- 저손실/고정확도
- 데이터의 추가 처리 및 분석을 용이하게 하기 위해 지표 집계/전달을 수행할 수 있습니다.
- 정보 저장의 효율성이 높다
- 편리한 대화형 인터페이스: 다른 시스템과의 통합 및 직접적인 사용자 작업을 용이하게 하여 통찰력과 의사 결정 프로세스를 가속화할 수 있는 친숙한 외부 인터페이스를 제공합니다.
설계
먼저 훈련 중단/성능 저하 문제를 해결하기 위해 영구 커널 타이밍을 설계했습니다.
- 대부분의 시나리오에서 훈련 중단은 nccl 작업으로 인해 발생합니다. 일반적으로 행렬 곱셈을 기록하고 통신을 설정하기만 하면 됩니다.
- 단일 머신(ECC, MCE)에서의 성능 저하의 경우 행렬 곱셈만 기록하면 됩니다. 동시에 행렬 곱셈을 분석하면 사용자의 행렬 모양이 과학적인지 확인하고 각 프레임워크의 성능을 극대화할 수 있습니다. 행렬 곱셈을 구현할 때 cublas를 직접 사용합니다.
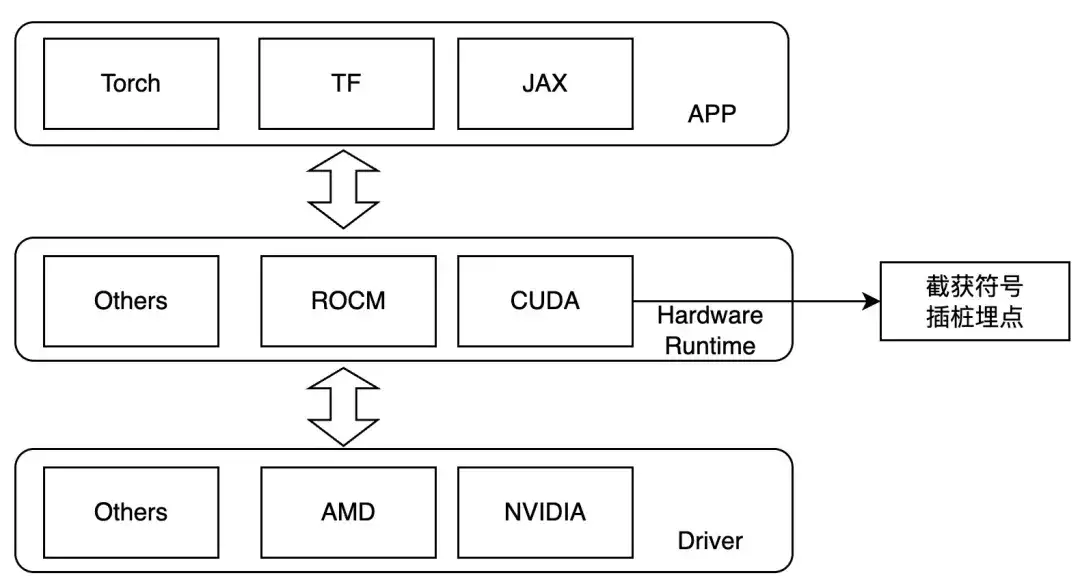
따라서 우리는 커널 실행 계층에서 가로채고 런타임 중에 LD_PRELOAD를 설정하여 관심 있는 작업을 추적하도록 설계했습니다. 이 방법은 동적 연결의 경우에만 사용할 수 있습니다. 현재 주류 교육 프레임워크는 동적 연결입니다. NVIDIA GPU의 경우 다음 기호에 주의할 수 있습니다.
- ibcuart.so
- cudaLaunch커널
- cudaLaunchKernelExC
- libcublas.so
- 큐블라젬엑스
- cublasGemmStridedBatchedEx
- cublasLtMatmul
- 큐블라Sgemm
- cublasSgemmStrided일괄 처리
다양한 하드웨어에 적응할 때 다양한 템플릿 클래스를 통해 다양한 추적 기능이 구현됩니다.
작업 흐름
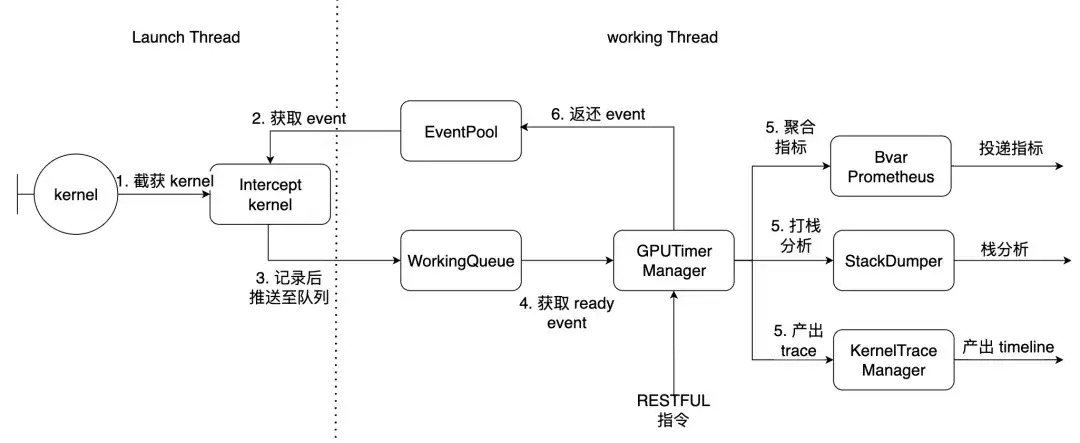
PyTorch를 예로 들면 Launch Thread는 토치의 기본 스레드이고 작업 스레드는 라이브러리 내부의 작업 스레드입니다. 위에서 설명한 7개의 커널이 여기서 차단됩니다.
사용방법 및 효과
전제조건
- NCCL은 libtorch_cuda.so에 정적으로 컴파일됩니다.
- 토치는 libcudart.so를 동적으로 링크합니다.
NCCL이 동적으로 링크된 경우 사용자 정의 함수 오프셋이 제공되고 런타임 시 동적으로 해결될 수 있습니다. Python 패키지를 설치하면 다음과 같은 명령줄 도구가 제공됩니다.
| xpu_timer_gen_syms | nccl을 동적으로 생성하고 구문 분석하기 위한 라이브러리 동적으로 주입된 함수 오프셋 |
| xpu_timer_gen_trace_timeline | 크롬 추적을 생성하는 데 사용됩니다. |
| xpu_timer_launch | 후크 패키지를 마운트하는 데 사용됩니다. |
| xpu_timer_stacktrace_viewer | 시간 초과 후 시각적 스택을 생성하는 데 사용됩니다. |
| xpu_timer_print_env | libevent.so 주소 인쇄 및 컴파일 정보 인쇄 |
| xpu_timer_dump_timeline | 타임라인 덤프를 트리거하는 데 사용됩니다. |
LD_PRELOAD 用法:XPU_TIMER_XXX=xxx LD_PRELOAD=`path to libevent_hook.so` python xxx
실시간 동적 캡처 타임라인
각 순위에는 동시에 모든 순위에 명령을 보내야 하는 포트 서비스가 있습니다. 시작 포트는 brpc입니다. 서비스 포트는 각 순위 추적에 대해 32B의 데이터 크기를 가지며 크기는 32K입니다. . 생성된 타임라인 json의 크기는 150K * 월드 크기로, 토치 타임라인의 기본 사용
usage: xpu_timer_dump_timeline [-h]
--host HOST 要 dump 的 host
--rank RANK 对应 host 的 rank
[--port PORT] dump 的端口,默认 18888,如果一个 node 用了所有的卡,这个不需要修改
[--dump-path DUMP_PATH] 需要 dump 的地址,写绝对路径,长度不要超过 1000
[--dump-count DUMP_COUNT] 需要 dump 的 trace 个数
[--delay DELAY] 启动这个命令后多少秒再开始 dump
[--dry-run] 打印参数
단일 기계 상황
xpu_timer_dump_timeline \
--host 127.0.0.1 \
--rank "" \
--delay 3 \
--dump-path /root/lizhi-test \
--dump-count 4000
多机情况# 如下图所示,如果你的作业有 master/worker 混合情况(master 也是参与训练的)
# 可以写 --host xxx-master --rank 0
# 如果还不确定,使用 --dry-run
xpu_timer_dump_timeline \
--host worker \
--rank 0-3 \
--delay 3 --dump-path /nas/xxx --dump-count 4000
xpu_timer_dump_timeline \
--host worker --rank 1-3 \
--host master --rank 0 --dry-run
dumping to /root/timeline, with count 1000
dump host ['worker-1:18888', 'worker-2:18888', 'worker-3:18888', 'master-0:18888']
other data {'dump_path': '/root/timeline', 'dump_time': 1715304873, 'dump_count': 1000, 'reset': False}
추후 해당 타임라인 폴더에 다음 파일들이 추가될 예정입니다.

그런 다음 이 파일에서 xpu_timer_gen_trace_timeline을 실행하세요.
xpu_timer_gen_trace_timeline 3개의 파일이 생성됩니다.
- merged_tracing_kernel_stack 보조 파일, Flame 그래프 원본 파일
- Trace.json 병합 타임라인
- tracing_kernel_stack.svg, 행렬 곱셈/nccl을 위한 호출 스택
Lama-recipes 32 카드 SF 분석 사례
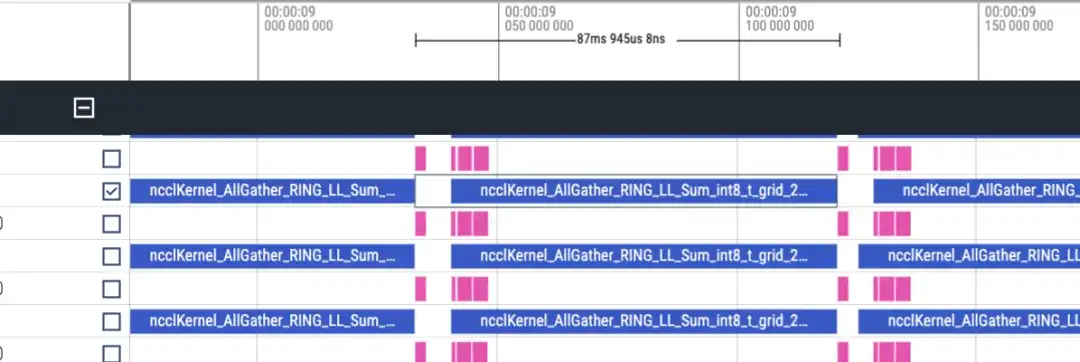
타임라인은 대략 다음과 같습니다. 각 순위에는 matmul/nccl 두 줄이 표시되며 모든 순위가 표시됩니다. 여기에는 정방향/역방향 정보가 없으므로 대략적으로 역방향이 정방향보다 2배 더 길다고 판단할 수 있습니다.

순방향 타임라인, 약 87ms
역방향 타임라인 약 173ms
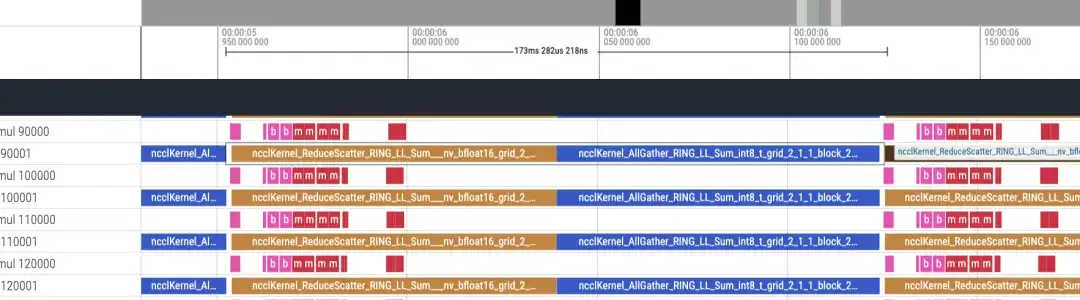
총 48개의 레이어가 있으며 총 시간 소모는 (173+87)*48 = 12480ms입니다. lmhead, embedding 및 기타 작업을 포함하면 전체 시간은 13초 정도 소요됩니다. 그리고 타임라인을 통해 계산시간보다 통신시간이 훨씬 길다는 것을 알 수 있으며, 통신으로 인해 병목 현상이 발생하는 것으로 판단할 수 있다.
행 스택 분석
pip를 사용하여 패키지를 설치한 후 명령줄 도구를 통해 분석할 수 있습니다. 기본적으로 커널은 300초 이상 후에 특정 스택 정보를 인쇄하여 pstack/py-spy를 사용합니다. 해당 스택을 인쇄하고 훈련 프로세스의 결과를 stderr로 인쇄합니다. conda를 통해 gdb를 설치하는 경우 gdb의 python api를 사용하여 lwp 이름을 얻을 수 있습니다. 기본 설치된 gdb8.2는 때때로 conda gdb의 기본 주소를 얻을 수 없습니다. gdb 다음은 NCCL 시간 초과를 시뮬레이션하기 위한 2카드 스택입니다.

다음은 단일 머신에서 8카드 llama7B sft 교육의 예입니다.
Python 패키지에서 제공하는 도구를 통해 집계 스택의 Flame 스택 그래프를 생성할 수 있습니다. 8카드 훈련 중 -STOP 랭크1을 종료하여 행이 시뮬레이션되므로 랭크 1이 랭크 1에 포함되기 때문입니다. 정지 상태.
xpu_timer_stacktrace_viewer --path /path/to/stack
运行后会在 path 中生成两个 svg,分别为 cpp_stack.svg, py_stack.svg
스택을 병합할 때 동일한 콜패스가 병합될 수 있다고 믿습니다. 즉, 스택 추적이 완전히 일관되므로 메인 스레드에 갇힌 대부분의 위치는 동일하지만 일부 루프와 활성 스레드가 있는 경우 인쇄됩니다. 스택 상단이 일치하지 않을 수 있지만 하단에서는 동일한 스택이 실행됩니다. 예를 들어 Python 스택의 스레드는 [email protected]에 고정됩니다. 또한 Flame 그래프의 샘플 수는 의미가 없습니다. 정지가 감지되면 모든 순위는 해당 스택 추적 파일을 생성하고(순위1은 일시 중단되었으므로 없음) 각 파일에는 Python/C++의 전체 스택이 포함됩니다.
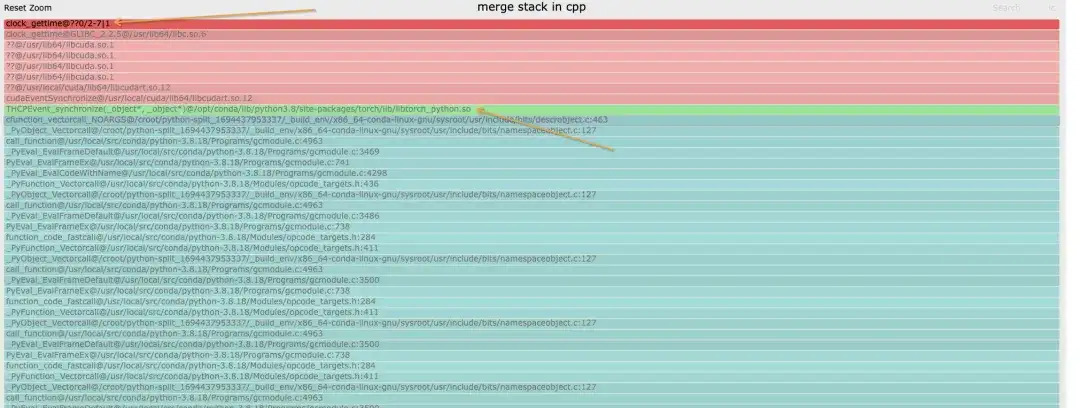
병합된 스택은 다음과 같이 스택의 범주를 구별하기 위해 사용됩니다. Python 스택에는 청록색과 녹색만 있을 수 있습니다.
- 청록색은 CPython/Python입니다.
- 빨간색은 C/기타 시스템과 관련된 것입니다.
- 녹색은 토치/NCCL입니다.
- 노란색은 C++입니다.

Python 스택은 다음과 같습니다. 파란색 블록 다이어그램은 특정 스택이며 명명 규칙은 func@source_path@stuck_rank|leak_rank입니다.
- func는 현재 함수 이름입니다. gdb가 이를 얻을 수 없으면 표시됩니까??
- source_path, 프로세스에서 이 기호의 so/source 주소
- stack_rank는 여기에 입력되는 순위 스택을 나타냅니다. 연속된 순위 번호는 순위 0,1,2,3 -> 0-3과 같이 시작-끝으로 접혀집니다.
- Leak_rank는 여기에 들어가지 않은 스택을 나타내며, 여기의 순위 번호도 접혀집니다.
그래서 그림에서 의미하는 바는 0랭크, 2~7랭크 모두 동기화 상태에서 멈춰 있고, 1랭크가 들어오지 않아 1랭크(실제로는 정지)에 문제가 있는 것으로 분석할 수 있습니다. 이 정보는 스택의 맨 위에만 추가됩니다.

이에 따라 cpp의 스택을 보면 메인 스레드가 동기화에 멈춘 것을 볼 수 있고, 결국 cuda.so에서도 획득 시간에 멈춘 것을 볼 수 있습니다. 이 스택이 없으면 랭크1만 있는 것으로 간주할 수 있습니다. __libc_start_main이 위치한 스택은 프로세스의 진입점을 나타냅니다.
일반적으로 스택에는 가장 깊은 링크가 하나만 있다고 간주할 수 있습니다. 분기가 발생하면 서로 다른 순위가 서로 다른 링크에 붙어 있음을 증명합니다.
커널 호출 스택 분석
토치 타임라인과 달리 타임라인에는 콜스택이 없습니다. 타임라인을 생성할 때 해당 스택 파일 이름은 tracing_kernel_stack.svg입니다. 이 파일을 크롬으로 드래그하여 관찰하세요.
- 녹색은 NCCL 작업입니다.
- 빨간색은 matmul 작업입니다.
- 청록색은 Python 스택입니다.

그라파나 시장 디스플레이
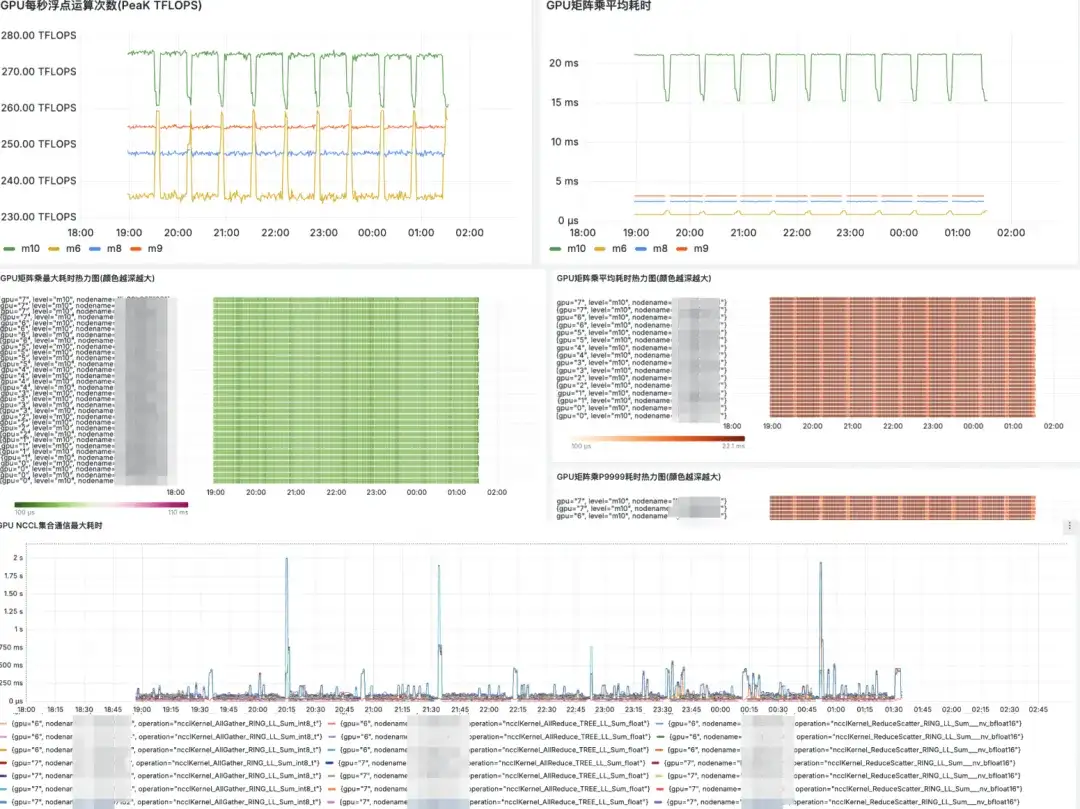
향후 계획
- NCCL/eBPF와 같은 더욱 세분화된 추적을 추가하여 훈련 중 정지 문제의 근본 원인을 보다 정확하게 분석하고 진단합니다.
- 다양한 국내 그래픽 카드를 포함하여 더 많은 하드웨어 플랫폼을 지원할 예정입니다.
DLRover 소개
DLRover(Distributed Deep Learning System)는 Ant Group AI Infra팀이 운영하는 오픈소스 커뮤니티로, 클라우드 네이티브 기술을 기반으로 한 지능형 분산 딥러닝 시스템입니다. DLRover를 사용하면 개발자는 하드웨어 가속 및 분산 작업과 같은 엔지니어링 세부 사항을 처리할 필요 없이 모델 아키텍처 설계에 집중할 수 있습니다. 또한 옵티마이저와 같이 딥 러닝 훈련과 관련된 알고리즘을 개발하여 훈련을 보다 효율적이고 지능적으로 만듭니다. 현재 DLRover는 딥 러닝 훈련 작업의 자동화된 운영 및 유지 관리를 위해 K8s 및 Ray의 사용을 지원합니다. 더 많은 AI Infra 기술을 알고 싶다면 DLRover 프로젝트를 주목해주세요.
DLRover DingTalk 기술 교류회 가입: 31525020959
DLR오버 스타:
https://github.com/intelligent-machine-learning/dlrover
기사 추천
AI 훈련 컴퓨팅 전력 효율성 향상: Ant DLRover 결함 자가 치유 기술의 혁신적 실천
AI 인프라 설계사를 만나다: 고속 대형 '레이싱카'를 타고 '바퀴를 바꾸는' 사람
[온라인 다시보기] NVIDIA GTC 2024 컨퍼런스 AI 엔지니어링 비용을 줄이는 방법은? 학습부터 추론까지 Ant의 풀스택 실습
