

이 기사의 작성자:
타릭 베넷, 베이난 왕, 호프 왕
이 기사에서는 인공 지능(AI)의 데이터 액세스 문제에 대해 논의하고 "일반적으로 사용되는 NAS/NFS가 최선의 선택이 아닐 수 있음 "을 밝힙니다 .
1. 초기 인공지능/머신러닝 아키텍처
Gartner 조사에 따르면 LLM(대형 언어 모델)이 많은 관심을 받았음에도 불구하고 대부분의 조직은 아직 대규모 모델을 사용하는 초기 단계에 있으며 일부만이 생산 단계에 진입했습니다.
초기 단계에서 AI 플랫폼을 구축하는 데 중점을 두는 것은 프로젝트 파일럿과 개념 증명을 수행할 수 있도록 시스템을 실행하는 것입니다. 이러한 초기 아키텍처 또는 사전 프로덕션 아키텍처는 모델 교육 및 배포의 기본 요구 사항을 충족하도록 설계되었습니다. 현재 많은 조직에서는 이미 이러한 유형의 초기 AI 아키텍처를 프로덕션 환경에 사용하고 있습니다.
데이터와 모델이 증가함에 따라 이러한 초기 AI 아키텍처는 비효율적이 되는 경우가 많습니다. 기업은 클라우드에서 모델을 교육하고 프로젝트가 확장됨에 따라 데이터 및 클라우드 사용량이 12개월 이내에 크게 증가할 것으로 예상됩니다. 많은 조직은 현재 메모리 크기와 일치하는 데이터 볼륨으로 시작하지만 더 큰 로드에 대비해야 한다는 점을 인식하고 있습니다.
기업은 기존 기술 스택 또는 그린필드 배포를 사용하도록 선택할 수 있습니다. 이 기사에서는 기존 기술 스택을 사용하거나 추가 하드웨어를 구입하여 보다 확장 가능하고 민첩하며 성능이 뛰어난 기술 스택을 설계하는 방법에 중점을 둘 것입니다.
2. 데이터 접근의 어려움
AI/ML 아키텍처가 발전함에 따라 모델 훈련 데이터 세트의 크기가 계속해서 크게 증가하고 GPU의 컴퓨팅 성능과 규모도 빠르게 증가하고 있습니다. 컴퓨팅, 스토리지, 네트워크 외에도 데이터 액세스는 미래 지향적인 AI 플랫폼을 구축하는 데 있어 또 다른 핵심 요소라고 믿습니다 .

데이터 액세스는 컴퓨팅 엔진이 모델 교육 및 배포를 위한 데이터를 얻는 데 도움이 되는 데이터 서비스, 백업 스토리지(NFS, NAS) 및 고성능 캐시(예: Alluxio)와 같은 기술을 의미합니다.
데이터 액세스의 초점은 처리량과 데이터 로딩 효율성입니다. 이는 GPU 리소스가 부족한 AI/ML 아키텍처에서 점점 더 중요해지고 있습니다 . 데이터 로딩을 최적화하면 GPU 유휴 대기 시간을 크게 줄이고 GPU 활용률을 향상시킬 수 있습니다. 따라서 고성능 데이터 액세스는 아키텍처 배포의 주요 목표가 되어야 합니다.
기업이 초기 AI 아키텍처에 대한 모델 훈련 작업을 확장함에 따라 다음과 같은 몇 가지 일반적인 데이터 액세스 문제가 나타났습니다.
1
모델 훈련 효율성이 예상보다 낮습니다. 데이터 액세스 병목 현상으로 인해 훈련 시간이 컴퓨팅 리소스를 기준으로 예상한 것보다 깁니다. 처리량이 낮은 데이터 스트림은 GPU에 충분한 데이터를 제공하지 않습니다.
2
데이터 동기화와 관련된 병목 현상: 스토리지에서 로컬 GPU 서버로 데이터를 수동으로 복사하거나 동기화하면 준비할 데이터 대기열을 구축하는 데 지연이 발생합니다.
삼
동시성 및 메타데이터 문제: 대규모 작업이 병렬로 시작되면 공유 스토리지에서 경합이 발생할 수 있습니다. 백엔드 저장소의 메타데이터 작업이 느려지면 지연 시간이 늘어납니다.
4
느린 성능 또는 낮은 GPU 활용도: 고성능 GPU 인프라에는 막대한 투자가 필요하며, 데이터 액세스가 비효율적이면 GPU 리소스가 유휴 상태이거나 활용도가 낮습니다.
또한 이러한 과제는 데이터 팀이 관리해야 하는 수많은 다른 문제로 인해 더욱 복잡해집니다. 이러한 문제에는 고성능 GPU 클러스터의 요구 사항을 충족할 수 없는 느린 스토리지 I/O 속도가 포함됩니다. 수동 데이터 복사 및 동기화에 의존하면 데이터 팀이 데이터가 GPU 서버에 전달될 때까지 기다리는 동안 대기 시간이 늘어납니다. 데이터 액세스 문제는 하이브리드 인프라 또는 멀티 클라우드 환경에서 여러 데이터 사일로의 아키텍처 복잡성으로 인해 더욱 복잡해집니다.
이러한 문제는 궁극적으로 아키텍처의 엔드투엔드 효율성이 기대에 미치지 못하는 결과를 낳습니다.
데이터 액세스와 관련된 문제에는 두 가지 공통 솔루션이 있는 경우가 많습니다.
더 빠른 스토리지 구입: 많은 기업에서는 더 빠른 스토리지 옵션을 배포하여 느린 데이터 액세스 문제를 해결하려고 합니다. 클라우드 벤더는 고성능 스토리지를 제공하는 반면, 전문 하드웨어 벤더는 성능 향상을 위해 HPC 스토리지를 판매합니다.
객체 스토리지 위에 NAS/NFS 추가: 중앙 집중식 NAS 또는 NFS를 S3, MinIO 또는 Ceph와 같은 객체 스토리지에 백업으로 추가하는 것은 일반적인 관행이며 팀이 데이터를 공유 파일 시스템에 통합하여 사용자와 워크로드의 협업 및 공유를 단순화하는 데 도움이 됩니다. 또한, 성숙한 NAS 공급업체가 제공하는 데이터 일관성, 가용성, 백업 및 확장성과 같은 관련 데이터 관리 기능을 활용할 수도 있습니다.
그러나 위의 두 가지 일반적인 해결 방법은 실제로 문제를 해결하지 못할 수도 있습니다.
더 빠른 스토리지와 중앙 집중식 NFS/NAS는 점차적으로 일부 성능 향상을 달성할 수 있지만 단점도 있습니다.
1
더 빠른 스토리지는 데이터 마이그레이션을 의미하며, 이로 인해 데이터 안정성 문제가 쉽게 발생할 수 있습니다.
전용 스토리지가 제공하는 고성능을 활용하려면 데이터를 기존 스토리지에서 새로운 고성능 스토리지 계층으로 마이그레이션해야 합니다. 이로 인해 데이터가 백그라운드에서 마이그레이션됩니다. 대규모 데이터 세트를 마이그레이션하면 전송 시간이 길어지고 마이그레이션 중 데이터 손상이나 손실과 같은 데이터 신뢰성 문제가 발생할 수 있습니다. 팀이 데이터 동기화가 완료될 때까지 기다리는 동안 작업을 일시 중지하면 서비스가 중단되고 프로젝트 진행 속도가 느려질 수 있습니다.
2
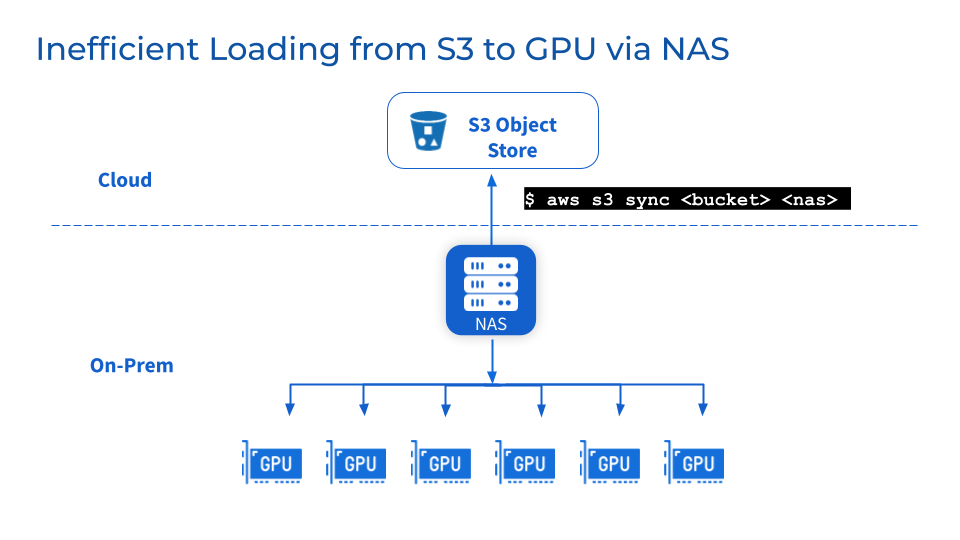
NFS/NAS: 유지 관리 및 병목 현상
추가 스토리지 계층으로서 NFS/NAS 유지 관리, 안정성 및 확장성 문제가 남아 있습니다. NFS/NAS에서 로컬 GPU 서버로 데이터를 수동으로 복사하면 반복된 백업으로 인해 대기 시간이 늘어나고 리소스가 낭비됩니다. 병렬 작업으로 인한 읽기 수요 급증으로 인해 NFS/NAS 서버 및 상호 연결된 서비스가 클러스터링될 수 있습니다. 또한 원격 NFS/NAS GPU 클러스터의 데이터 동기화 문제가 여전히 존재합니다.
삼
사업상의 이유로 공급업체를 변경해야 하는 경우 어떻게 해야 합니까?
기업은 비용 최적화 또는 계약상의 이유로 공급업체를 변경할 수 있습니다. 멀티 클라우드 환경의 유연성을 위해서는 벤더 종속 없이 대규모 데이터 세트를 쉽게 포팅할 수 있는 기능이 필요합니다. 그러나 페타바이트 규모의 데이터 스토리지를 이동하면 상당한 다운타임이 발생하고 모델 개발이 중단될 수 있습니다.
즉, 기존 솔루션은 단기적으로는 도움이 되지만 AI/ML의 기하급수적인 데이터 요구 사항 증가를 충족할 수 있는 확장 가능하고 최적화된 데이터 액세스 아키텍처를 제공할 수 없습니다.
3. Alluxio에서 제공하는 솔루션
Alluxio는 컴퓨팅과 데이터 소스 사이에 배포될 수 있습니다. AI/ML 아키텍처의 성능과 확장성을 향상하기 위해 데이터 추상화 및 분산 캐싱을 제공합니다.
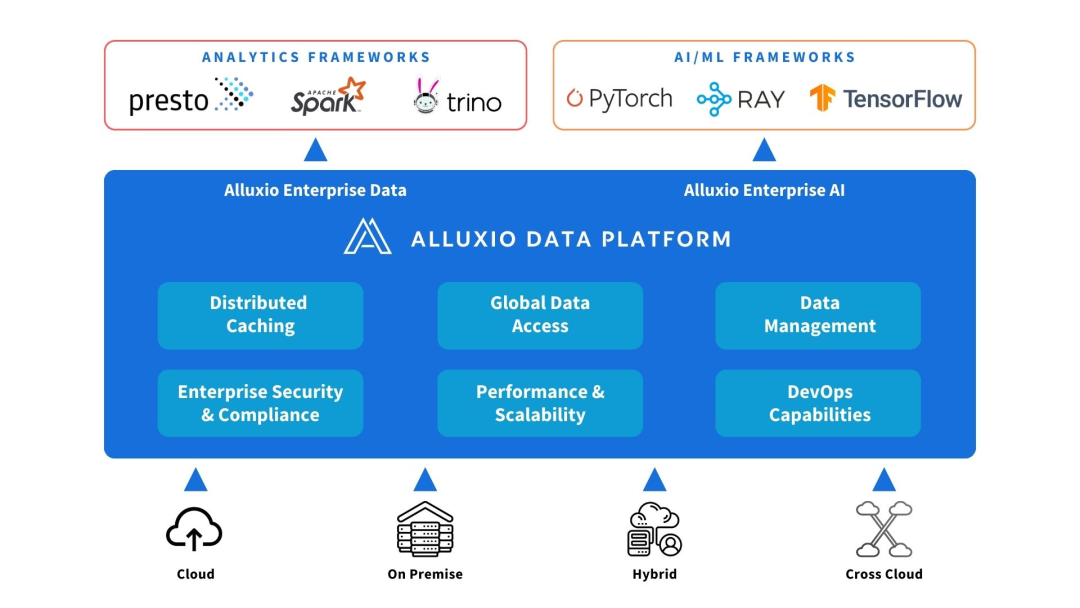
Alluxio는 데이터 양, 모델 복잡성 증가 및 GPU 클러스터 확장에 따라 확장성, 성능 및 데이터 관리 측면에서 초기 AI 아키텍처가 직면한 문제를 해결하는 데 도움을 줍니다.
1
용량을 늘리다
Alluxio는 클러스터 메모리나 로컬 SSD가 수용할 수 있는 것보다 더 큰 훈련 데이터 세트를 수용하기 위해 단일 노드의 한계 이상으로 확장됩니다. 다양한 스토리지 시스템을 연결하고 페타바이트 수준의 데이터 레이크를 탑재할 수 있는 통합 데이터 액세스 계층을 제공합니다. Alluxio는 자주 사용되는 파일과 메타데이터를 컴퓨팅에 가까운 메모리 및 SSD 계층에 지능적으로 캐시하므로 전체 데이터 세트를 복사할 필요가 없습니다.
2
데이터 관리 감소
Alluxio는 자동화된 분산 캐싱을 통해 GPU 클러스터 간의 데이터 이동 및 저장을 단순화합니다. 데이터 팀은 데이터를 로컬 준비 파일에 수동으로 복사하거나 동기화할 필요가 없습니다. Alluxio 클러스터는 복잡한 작업 흐름 작업을 거치지 않고도 핫 파일이나 개체를 컴퓨팅 노드에 가까운 위치로 자동으로 캡처할 수 있습니다. Alluxio는 노드당 5천만 개 이상의 개체가 있는 경우에도 워크플로를 단순화합니다.
삼
성능 향상
Alluxio는 워크로드를 가속화하도록 구축되어 GPU 처리량을 제한하는 기존 스토리지의 I/O 병목 현상을 제거합니다. 분산 캐싱은 데이터 액세스 속도를 몇 배나 향상시킵니다. 네트워크를 통해 원격 스토리지에 액세스하는 것과 비교하여 Alluxio는 메모리 및 SSD 수준에서 로컬 데이터 액세스를 제공하여 GPU 활용도를 향상시킵니다.
즉, Alluxio는 AI/ML 데이터 확장 시나리오에서 GPU 리소스 사용을 극대화할 수 있는 고성능 및 확장 가능한 데이터 액세스 레이어를 제공합니다.
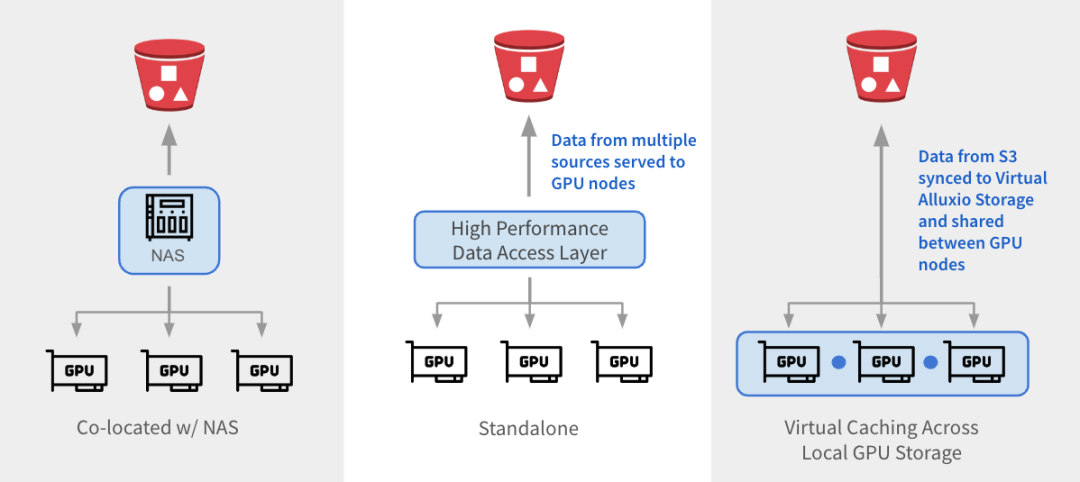
Alluxio는 세 가지 방법으로 기존 아키텍처와 통합될 수 있습니다.
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
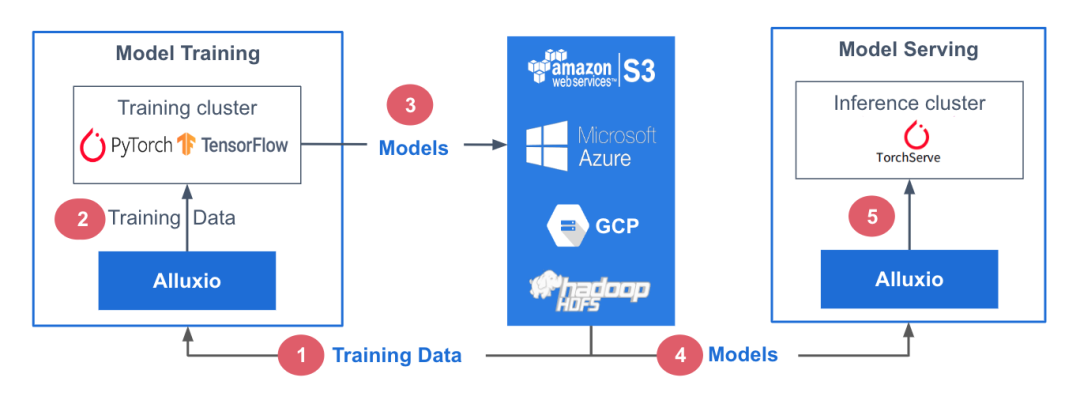
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
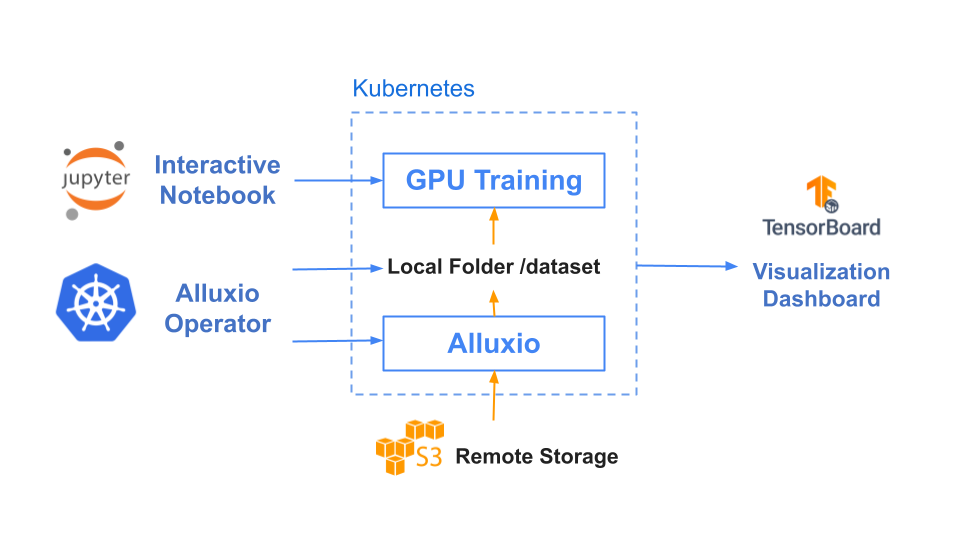
2
基准测试结果
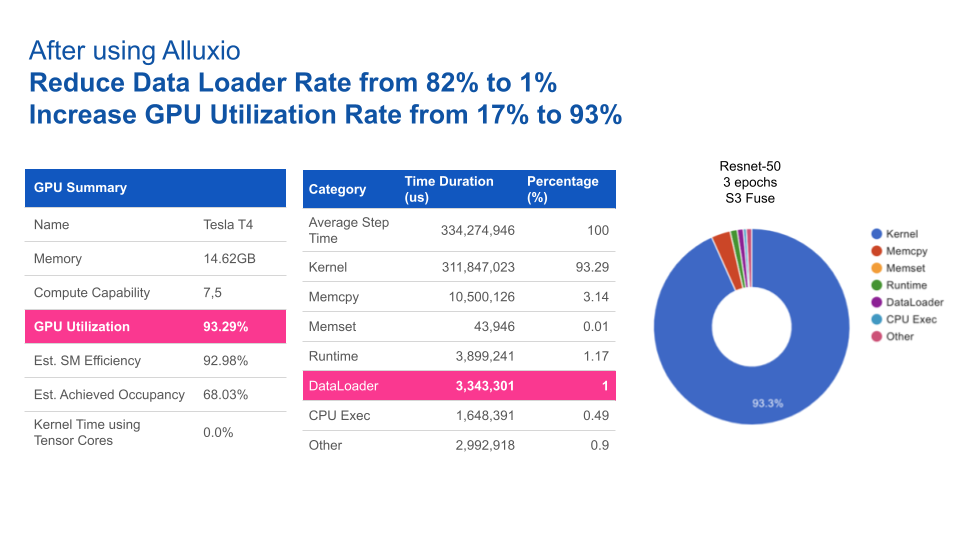
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
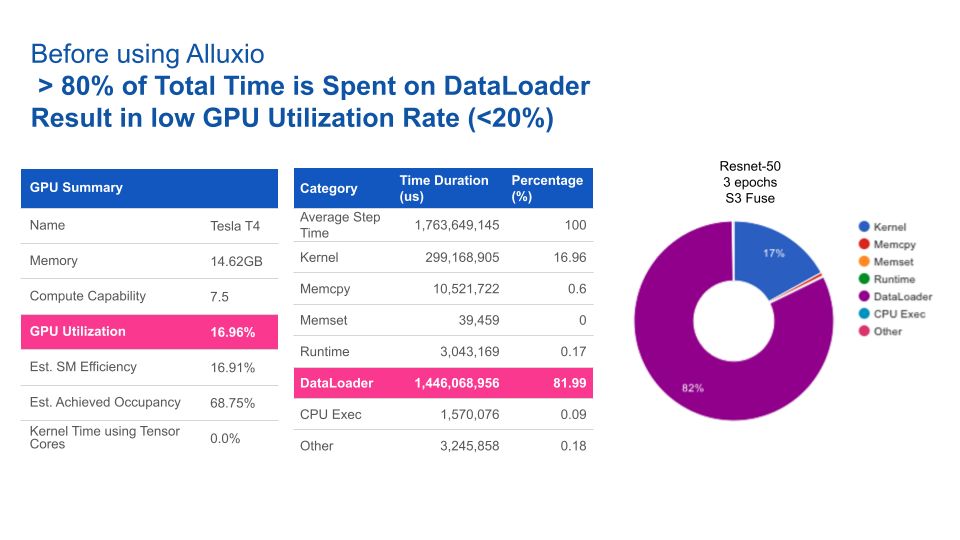
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。