소개 : ArcGraph는 클라우드 네이티브 아키텍처와 통합 인벤토리 및 분석 기능을 갖춘 분산 그래프 데이터베이스입니다. 이 글에서는 제한된 메모리 하에서 ArcGraph가 어떻게 그래프 분석에 유연하게 대처할 수 있는지 자세히 설명합니다.
01 소개
이제 그래프 분석 기술이 널리 활용되면서 학계와 주요 그래프 데이터베이스 제조사들은 그래프 분석 기술의 고성능 지표를 개선하는데 열을 올리고 있습니다. 그러나 고성능 컴퓨팅을 추구하는 과정에서 계산 속도를 높이기 위해 메모리 사용량을 늘리는 '시간과 공간을 거래하는' 방식이 채택되는 경우가 많다. 그러나 외부 메모리 그래프 컴퓨팅은 이 단계에서 아직 성숙하지 않았으며 그래프 분석은 여전히 전체 메모리 컴퓨팅에 의존합니다. 이로 인해 고성능 그래프 컴퓨팅 엔진은 메모리가 부족할 때 그래프 분석 작업에 크게 의존하게 됩니다. 실행되지 않습니다.
과거 많은 고객 사례를 통해 고객이 그래프 분석에 투자하는 하드웨어 리소스는 일반적으로 고정적이고 제한되어 있으며 테스트 환경의 리소스는 프로덕션 환경보다 더 제한적이라는 것을 확인했습니다. 그래프 분석에 대한 고객의 적시성 요구 사항은 일반적으로 일반적인 오프라인 분석 요구 사항인 T+1입니다. 따라서 고객들은 그래프 컴퓨팅 엔진이 T+1만 충족된다면 높은 알고리즘 성능을 추구하기보다는 CPU, 메모리 등의 자원에 대한 수요를 줄여줄 것으로 기대하고 있습니다. 이는 대부분의 그래프 컴퓨팅 엔진에 있어 큰 과제입니다. CPU 요구 사항은 상대적으로 제어하기 쉬운 반면, 메모리 요구 사항은 짧은 개발 주기 내에서 크게 최적화하기 어렵습니다.
ArcGraph도 위의 과제에 직면해 있지만 고객 제공 방식의 지속적인 요약과 개선을 통해 우리의 그래프 컴퓨팅 엔진은 시간과 공간에서 처리 균형을 맞출 수 있는 유연성을 갖추고 있습니다. 현재 ArcGraph에 내장된 그래프 컴퓨팅 엔진은 그래프 분석 성능 지표 측면에서 업계를 선도하고 있으며 계속해서 최적화 및 개선되고 있습니다. 다음으로 제한된 메모리 하에서 그래프 분석에 대처하기 위해 ArcGraph가 시간과 공간을 교묘하게 교환하는 방법을 엔진의 기본 데이터 구조와 상위 알고리즘 호출 등 다양한 관점에서 설명하겠습니다.
02 포인트 ID 유형 선택
ArcGraph 그래프 계산 엔진은 string, int64 및 int32의 세 가지 포인트 ID 유형을 지원합니다. 문자열 포인트 유형에 대한 지원은 소스 데이터와의 호환성을 향상시킬 수 있지만 int64에 비해 문자열에서 int64 포인트 ID 매핑 테이블을 메모리에 유지해야 하기 때문에 메모리 사용량이 늘어납니다. 지정된 포인트 유형이 int64인 경우 ArcGraph는 소스 데이터의 문자열 유형 포인트 ID에서 int64 매핑 테이블을 생성하고 이를 외부 메모리에 배치합니다. 매핑된 int64 유형 포인트 가장자리 데이터만 메모리에 유지됩니다. 계산이 완료된 후 매핑 테이블이 메모리로 읽혀지고 문자열 ID가 복원됩니다. 따라서 int64 유형의 포인트 ID를 사용하면 외부 메모리와 메모리 간의 매핑 테이블을 교환하는 데 추가 시간이 소요되지만 원본의 길이와 포인트에 따라 절약되는 메모리 크기가 크게 줄어듭니다. ID. 데이터 볼륨.
또한 ArcGraph 그래프 계산 엔진은 int32도 지원합니다. 총 소스 데이터 포인트 수가 4천만 개 미만인 시나리오의 경우 int64에 비해 메모리 사용량을 약 30% 더 줄일 수 있습니다.
다음은 ArcGraph의 실행 그래프 알고리즘 API에서 그래프 로딩 포인트 ID 유형을 지정하는 예입니다.
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 Varint 인코딩 켜기
Varint 인코딩은 정수를 압축하고 인코딩하는 데 사용되며 가변 길이 인코딩 방법입니다. int32를 예로 들면, 정상적으로 값을 저장하려면 4바이트가 필요합니다. 기존 Varint 인코딩에서는 각 바이트의 마지막 7비트가 데이터를 나타내는 데 사용되며 가장 높은 비트는 플래그 비트입니다.


- 최상위 비트가 0이면 현재 바이트까지 마지막 7비트가 모두 데이터이고, 그 다음 바이트는 데이터와 관련이 없다는 뜻이다. 예를 들어 위 그림의 정수 1은 00000001을 나타내는 데 1바이트만 필요하며 후속 바이트는 정수 1의 데이터에 속하지 않습니다.
- 가장 높은 비트가 1이면 후속 바이트가 여전히 데이터의 일부임을 의미합니다. 예를 들어, 위 그림의 정수 511은 11111111 00000011을 나타내기 위해 2바이트가 필요하며, 후속 바이트는 131071의 데이터입니다.
이 아이디어를 사용하면 32비트 정수를 1~5바이트로 표현할 수 있습니다. 이에 따라 64비트 정수는 1~10바이트로 표시될 수 있습니다. 실제 사용 시나리오에서는 작은 숫자의 사용률이 큰 숫자의 사용률보다 훨씬 높으며, 특히 64비트 정수의 경우 더욱 그렇습니다. 따라서 Varint 인코딩은 일반적으로 상당한 압축 효과를 얻을 수 있습니다. Varint 인코딩에는 다양한 변형이 있으며 오픈 소스 구현도 많이 있습니다.
ArcGraph 그래프 계산 엔진은 메모리 내 에지 데이터 스토리지(주로 CSR/CSC)를 압축하기 위해 Varint 인코딩 사용을 지원합니다. Varint 인코딩을 켜면 에지 데이터가 차지하는 메모리가 실제 측정에서 최대 약 50%까지 크게 줄어들 수 있습니다. 동시에 인코딩 및 디코딩으로 인한 성능 손실도 약 20%에 달합니다. 따라서 전원을 켜기 전에 사용 시나리오와 고객 요구 사항을 명확하게 이해하여 메모리 절약으로 인한 성능 손실이 허용 가능한 범위 내에 있는지 확인해야 합니다.
다음은 ArcGraph의 그래프 로딩 API에서 그래프 계산을 활성화하는 Varint 코딩 예제입니다.
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 완벽한 해시맵 켜기
Perfect HashMap과 다른 HashMap의 차이점은 Perfect Hash Function(PHF)을 사용한다는 것입니다. 함수 H는 N개의 키 값을 M개의 정수로 매핑하며, 여기서 M>=N이고 H(key1)≠H(key2)∀key1, key2를 만족하면 이 함수는 완벽한 해시 함수입니다. M=N이면 H는 최소 완전 해시 함수(줄여서 MPHF)입니다. 이때 N개의 키 값은 N개의 연속된 정수로 매핑됩니다.
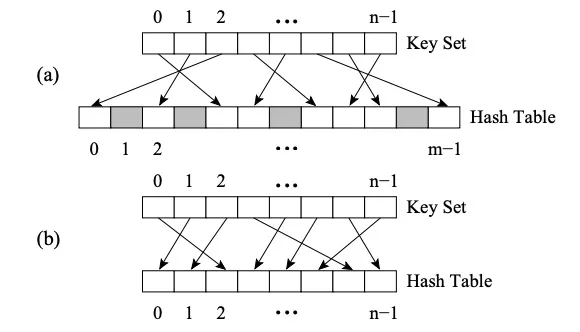 사진 (a)는 PHF, 사진 (b)는 MPHF입니다.
사진 (a)는 PHF, 사진 (b)는 MPHF입니다.
위 그림은 2단계 해싱의 FKS 전략입니다. 먼저 첫 번째 레벨 해시를 통해 데이터를 T 공간에 매핑한 후, 충돌하는 데이터를 무작위로 선택하여 새로운 해시 함수를 사용해 S 공간에 매핑하며, S 공간의 크기 m은 충돌하는 데이터의 제곱이 된다. (예를 들어 T2에 3개가 있는 경우 숫자가 충돌할 경우 m이 9인 S2 공간에 매핑됩니다.) 이때 충돌을 피하는 해시 함수를 쉽게 찾을 수 있습니다. 해시 함수를 적절하게 선택하면 단일 수준 해싱 중에 충돌이 줄어들므로 예상되는 저장 공간은 O(n)이 될 수 있습니다.
ArcGraph 그래프 계산 엔진은 원래 포인트 ID에서 메모리의 내부 포인트 ID로의 매핑을 유지합니다. 내부 포인트는 데이터 압축 및 벡터화 최적화에 편리한 연속적인 긴 정수 유형입니다. 매핑은 기본적으로 해시맵이지만 ArcGraph는 기본 구현 측면에서 두 가지 방법을 제공합니다.
- Flat HashMap - 구성 속도가 빠른 것이 장점이지만, 잦은 해시 충돌을 줄이기 위해 일반적으로 더 큰 메모리 공간이 필요하다는 단점이 있습니다.
- 완벽한 해시맵(Perfect HashMap) - 최악의 경우 O(1) 효율성의 쿼리를 보장하기 위해 더 적은 메모리를 사용할 수 있다는 장점이 있지만, 모든 키를 미리 알아야 하고 구성 시간이 길다는 단점이 있습니다.
따라서 Perfect HashMap을 켜면 시간을 공간으로 교환하는 목적도 달성할 수 있습니다. 테스트에 따르면 원래 지점에서 내부 지점 ID로 설정된 매핑의 경우 Perfect HashMap의 메모리 사용량은 일반적으로 Flat HashMap의 약 1/5에 불과하지만 이에 따라 구축 시간은 2~3배가 됩니다.
다음은 ArcGraph의 그래프 로딩 API에서 그래프 계산을 가능하게 하는 Perfect HashMap 예제입니다.
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 최적화 알고리즘 구현 및 결과 처리
알고리즘 구현 수준에서 메모리 사용량은 알고리즘의 특정 논리에 따라 달라지며, 시간을 공간으로 교환하는 목적을 달성할 수 있는 실습 내용을 다음과 같이 요약했습니다.
멀티스레딩과 알고리즘에서 ThreadLocal 개체의 사용을 적절하게 줄입니다. 알고리즘에는 임시 포인트 에지 컬렉션의 저장이 포함되는 경우가 많습니다. 이러한 저장소가 다중 스레드 논리에 나타나는 경우 스레드 수가 증가함에 따라 전체 메모리도 증가합니다. 동시 스레드 수를 적절하게 줄이거나 ThreadLocal 대형 개체의 사용을 줄이면 메모리를 줄이는 데 도움이 됩니다. 내부 메모리와 외부 메모리 간의 데이터 교환을 적절하게 늘립니다. 알고리즘의 특정 논리에 따라 일시적으로 사용되지 않는 대형 개체는 외부 메모리에 직렬화되고 개체가 사용될 때 스트리밍 방식으로 메모리로 읽어 들여 동시에 많은 양의 메모리를 차지하는 여러 대형 개체를 방지합니다. 시간.
다음은 위의 두 가지 사항을 구현한 알고리즘 구현 예입니다.
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
계산이 완료되면 결과가 외부 메모리에 기록되고 그래프 계산 엔진의 해당 메모리가 해제됩니다. 일부 시나리오에서는 결과 처리 프로그램이 그래프 컴퓨팅 클러스터 서버에서 실행되어 그래프 컴퓨팅 결과를 읽고 추가로 처리합니다. 그래프 계산 엔진의 메모리가 계산 결과를 공개하지 않은 경우 최악의 경우 현재 서버 메모리에 결과 데이터의 복사본이 두 개 남게 됩니다. 데이터 양이 많은 시나리오에서는 결과 데이터의 복사본이 매우 많은 양의 메모리를 차지합니다. 따라서 이러한 유형의 시나리오에서는 계산 결과를 외부 메모리에 쓰고 적시에 그래프 컴퓨팅 엔진의 메모리를 해제하는 것이 우선시되어야 합니다.
동시에 ArcGraph 팀은 고성능 및 낮은 리소스 사용이라는 "필요와 필요성"에 계속해서 도전하고 학계 및 업계 파트너와 협력하여 그래프 전달 메모리와 컴퓨팅 효율성을 더욱 연마하여 추가적인 기술 혁신을 달성할 것입니다.
Google: Rust로의 전환으로 Android 취약점이 크게 감소했습니다. Huawei는 공개 클래식 음악 플레이어인 Winamp가 2024.2.3에 공식적으로 오픈 소스로 출시되었다고 발표 했습니다 . 오라클 상표가 되었나요? Open Source Daily | PostgreSQL 17; 중국 AI 기업이 미국 칩 금지를 우회하는 방법; AI 개발자의 갈증을 해소할 수 있는 사람은 누구입니까? "Zhihuijun" 스타트업 회사는 현대 로봇 분야의 런타임 개발 프레임워크인 AimRT를 오픈 소스로 공개했으며, Tcl/Tk 9.0은 Meta를 출시하고 Llama 3.2 다중 모드 AI 모델을 출시했습니다.