Log Segmentado
Divida arquivos grandes em vários arquivos menores que são mais fáceis de manusear.
Histórico do problema
Um único arquivo de log pode crescer para um tamanho grande e ser lido quando o programa é iniciado, tornando-se um gargalo de desempenho. Os logs antigos precisam ser limpos regularmente, mas limpar um arquivo grande é muito trabalhoso.
solução
Divida um único log em vários e, quando o log atingir um determinado tamanho, ele mudará para um novo arquivo para continuar a gravação.
//写入日志
public Long writeEntry(WALEntry entry) {
//判断是否需要另起新文件
maybeRoll();
//写入文件
return openSegment.writeEntry(entry);
}
private void maybeRoll() {
//如果当前文件大小超过最大日志文件大小
if (openSegment.
size() >= config.getMaxLogSize()) {
//强制刷盘
openSegment.flush();
//存入保存好的排序好的老日志文件列表
sortedSavedSegments.add(openSegment);
//获取文件最后一个日志id
long lastId = openSegment.getLastLogEntryId();
//根据日志id,另起一个新文件,打开
openSegment = WALSegment.open(lastId, config.getWalDir());
}
}Se o log for segmentado, será necessário um mecanismo para localizar rapidamente um arquivo com um local de log (ou número de sequência de log). Isso pode ser alcançado de duas maneiras:
- O nome de cada arquivo de divisão de log contém um início específico e deslocamento de posição de log (ou número de sequência de log)
- Cada número de sequência de log contém o nome do arquivo e o deslocamento da transação.
//创建文件名称
public static String createFileName(Long startIndex) {
//特定日志前缀_起始位置_日志后缀
return logPrefix + "_" + startIndex + "_" + logSuffix;
}
//从文件名称中提取日志偏移量
public static Long getBaseOffsetFromFileName(String fileName) {
String[] nameAndSuffix = fileName.split(logSuffix);
String[] prefixAndOffset = nameAndSuffix[0].split("_");
if (prefixAndOffset[0].equals(logPrefix))
return Long.parseLong(prefixAndOffset[1]);
return -1l;
}Depois que o nome do arquivo contém essas informações, a operação de leitura é dividida em duas etapas:
- Dado um deslocamento (ou id de transação), obtenha o arquivo onde o registro é maior do que este deslocamento
- Leia todos os logs maiores do que este deslocamento do arquivo
//给定偏移量,读取所有日志
public List<WALEntry> readFrom(Long startIndex) {
List<WALSegment> segments = getAllSegmentsContainingLogGreaterThan(startIndex);
return readWalEntriesFrom(startIndex, segments);
}
//给定偏移量,获取所有包含大于这个偏移量的日志文件
private List<WALSegment> getAllSegmentsContainingLogGreaterThan(Long startIndex) {
List<WALSegment> segments = new ArrayList<>();
//Start from the last segment to the first segment with starting offset less than startIndex
//This will get all the segments which have log entries more than the startIndex
for (int i = sortedSavedSegments.size() - 1; i >= 0; i--) {
WALSegment walSegment = sortedSavedSegments.get(i);
segments.add(walSegment);
if (walSegment.getBaseOffset() <= startIndex) {
break; // break for the first segment with baseoffset less than startIndex
}
}
if (openSegment.getBaseOffset() <= startIndex) {
segments.add(openSegment);
}
return segments;
}Por exemplo
Basicamente, todo o armazenamento MQ convencional, como RocketMQ, Kafka e o armazenamento subjacente BookKeeper do Pulsar, todos usam logs segmentados.
RocketMQ :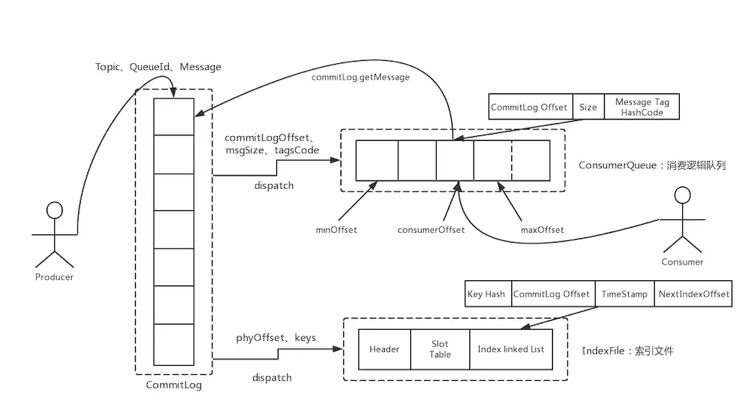
Kafka:
O armazenamento Pulsar implementa o BookKeeper: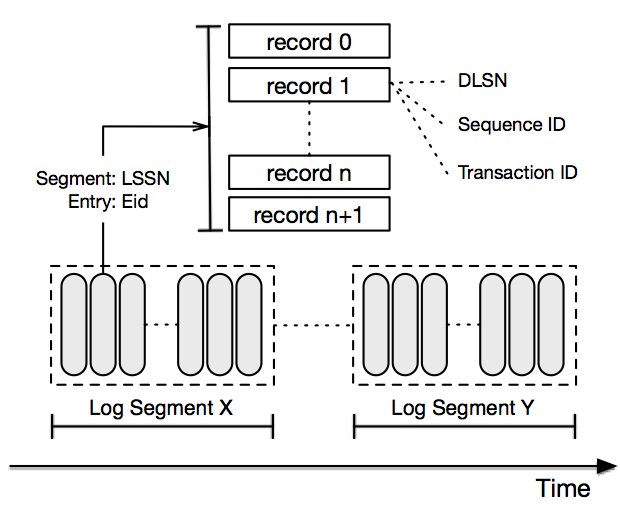
Além disso, o armazenamento com base no protocolo de consistência Paxos ou Raft geralmente usa logs segmentados, como Zookeeper e TiDB.
Um deslize todos os dias, você pode facilmente atualizar suas habilidades e obter várias ofertas:
