O CeresDB é um banco de dados de séries temporais distribuído, nativo da nuvem, de alto desempenho, escrito em Rust. Sua equipe de desenvolvimento anunciou recentemente que, após quase um ano de pesquisa e desenvolvimento de código aberto, o banco de dados de séries temporais CeresDB 1.0 foi lançado oficialmente, atingindo os padrões de disponibilidade de produção .
Documentação chinesa oficial do CeresDB 1.0: https://docs.ceresdb.io/cn/
Introdução aos principais recursos do CeresDB 1.0
mecanismo de armazenamento
-
Suporta armazenamento híbrido colunar
-
Filtro XOR eficiente
Nativo da nuvem distribuído
-
Realize a separação de computação e armazenamento (suporte OSS como armazenamento de dados, implementação WAL suporta OBKV, Kafka)
-
Suporta tabela de partições HASH
Implantação e O&M
-
Suporte à implantação autônoma
-
Suporte à implantação de cluster distribuído
-
Suporte Prometheus + Grafana para criar automonitoramento
protocolo de leitura e gravação
-
Suporte a consulta SQL e gravação
-
Implementou o protocolo integrado de leitura e gravação de alto desempenho do CeresDB e forneceu SDK multilíngue
-
Suporte Prometheus, pode ser usado como armazenamento remoto de Prometheus
SDK de leitura e escrita multilíngue
- SDKs de cliente implementados em quatro linguagens: Java, Python, Go, Rust
Introdução à arquitetura CeresDB
O CeresDB é um banco de dados de séries temporais. Comparado aos bancos de dados clássicos de séries temporais, o objetivo do CeresDB é ser capaz de processar dados em séries temporais e modos analíticos ao mesmo tempo e fornecer leitura e gravação eficientes.
Em um banco de dados clássico de séries temporais, Taga coluna ( InfluxDBcall Tag, Prometheuscall Label) geralmente gera um índice invertido para ela, mas no uso real, Taga cardinalidade da coluna é diferente em diferentes cenários——— em alguns No cenário, Taga cardinalidade é muito alto (os dados neste cenário são chamados de dados analíticos), e a leitura e escrita baseada no índice invertido pagará um preço alto por isso. Por outro lado, o método de varredura + remoção comumente usado em bancos de dados analíticos pode processar esses dados analíticos com mais eficiência.
Portanto, o conceito básico de design do CeresDB é adotar um formato de armazenamento híbrido e métodos de consulta correspondentes, de modo a processar eficientemente dados de séries temporais e dados analíticos ao mesmo tempo.
A figura abaixo mostra a arquitetura da versão autônoma do CeresDB
┌──────────────────────────────────────────┐
│ RPC Layer (HTTP/gRPC/MySQL) │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ SQL Layer │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Parser │ │ Planner │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌───────────────────┐ ┌───────────────────┐
│ Interpreter │ │ Catalog │
└───────────────────┘ └───────────────────┘
┌──────────────────────────────────────────┐
│ Query Engine │
│ ┌─────────────────┐ ┌─────────────────┐ │
│ │ Optimizer │ │ Executor │ │
│ └─────────────────┘ └─────────────────┘ │
└──────────────────────────────────────────┘
┌──────────────────────────────────────────┐
│ Pluggable Table Engine │
│ ┌────────────────────────────────────┐ │
│ │ Analytic │ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Wal ││ Memtable ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Flush ││ Compaction ││ │
│ │└────────────────┘└────────────────┘│ │
│ │┌────────────────┐┌────────────────┐│ │
│ ││ Manifest ││ Object Store ││ │
│ │└────────────────┘└────────────────┘│ │
│ └────────────────────────────────────┘ │
│ ┌ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
│ Another Table Engine │ │
│ └ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ ─ │
└──────────────────────────────────────────┘
Otimização de desempenho e resultados experimentais
O CeresDB usa uma combinação de armazenamento híbrido colunar, particionamento de dados, remoção e verificação eficiente para resolver o problema de baixo desempenho de consulta de gravação em linhas de tempo massivas (alta cardinalidade).
otimização de gravação
O CeresDB adota o modelo de escrita do tipo LSM (árvore de mesclagem estruturada em log), que não precisa processar índices invertidos complexos ao gravar, portanto, o desempenho da gravação é melhor.
otimização de consulta
Os seguintes meios técnicos são usados principalmente para melhorar o desempenho da consulta:
Poda:
-
poda min/max: o custo de construção é relativamente baixo e o desempenho é melhor em cenários específicos
-
Filtro XOR: melhora a precisão da filtragem do grupo de linhas no arquivo parquet
Escaneamento eficiente:
-
Simultaneidade entre vários SSTs: verifique vários arquivos SST ao mesmo tempo
-
Simultaneidade interna de um único SST: suporta a camada Parquet para extrair vários grupos de linhas em paralelo
-
Mesclar IO pequeno: para arquivos no OSS, mescle pequenas solicitações de IO para melhorar a eficiência do pull
-
Cache local: arquivos de cache extraídos por OSS, suporte a memória e cache de disco
resultados do teste de desempenho
Os testes de desempenho foram realizados usando TSBS. Os parâmetros de medição de pressão são os seguintes:
-
10 Marcas
-
10 campos
-
Linha do tempo (número de combinação de tags) nível 100w
Configuração da máquina de teste de pressão: 24c90g
Versão do InfluxDB: 1.8.5
Versão do CeresDB: 1.0.0
Comparação de desempenho de gravação
O desempenho de gravação do InfluxDB diminui mais com o tempo. Depois que a gravação do CeresDB é estável, a taxa de gravação tende a ser estável e o desempenho geral da gravação é mais de 1,5 vezes maior que o do InfluxDB (a lacuna pode ser superior a 2 vezes após um período de tempo)
Na figura abaixo, uma única linha contém 10 campos.
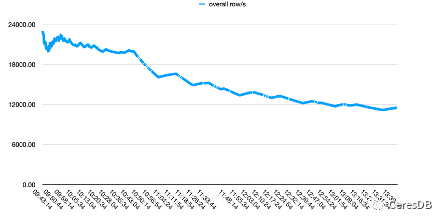
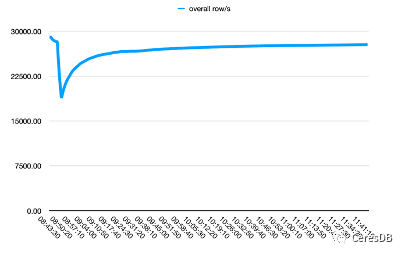
A imagem acima é Influxdb, e a imagem abaixo é CeresDB
Comparação de desempenho de consulta
Condição de triagem baixa (condição: os=Ubuntu15.10), CeresDB é 26 vezes mais rápido que InfluxDB, os dados específicos são os seguintes:
-
Tempo de consulta CeresDB: 15s
-
Tempo de consulta do InfluxDB: 6m43s
Condições de alta triagem (menos acertos de dados, condição: hostname=[8], neste momento o índice invertido tradicional será mais eficaz em teoria), este é um cenário onde o InfluxDB tem mais vantagens, e neste momento sob a condição de que o o aquecimento estiver concluído, o CeresDB é 5 vezes mais lento que o InfluxDB.
-
CeresDB: 85ms
-
InfluxDB: 15ms
roteiro 2023
A equipe de desenvolvimento disse que em 2023, após o lançamento do CeresDB 1.0, a maior parte de seu trabalho se concentrará em desempenho, distribuição e ecologia ao redor. Em particular, o suporte de encaixe da ecologia circundante espera facilitar o uso do CeresDB por vários usuários:
Ecologia circundante
-
Compatibilidade ecológica, incluindo compatibilidade com protocolos comuns de banco de dados de séries temporais, como PromQL, InfluxdbQL e OpenTSDB
-
Suporte a ferramentas de operação e manutenção, incluindo suporte a k8s, sistema de operação e manutenção CeresDB, automonitoramento, etc.
-
Ferramentas de desenvolvedor, incluindo importação e exportação de dados, etc.
desempenho
-
Explorar novos formatos de armazenamento
-
Aprimore diferentes tipos de índices para aprimorar o desempenho do CeresDB em diferentes cargas de trabalho
distribuído
-
balanceamento automático de carga
-
Melhorar a disponibilidade, confiabilidade