Suponha que agora você tenha os dados e o orçamento, tudo esteja pronto e você esteja pronto para começar a treinar um modelo grande. Depois de mostrar suas habilidades, "ver todas as flores em Chang'an em um dia" parece ser algo próximo a esquina... Espere um minuto! O treinamento não é tão simples quanto a pronúncia dessas duas palavras. Pode ser útil ver o treinamento de BLOOM.
Nos últimos anos, tornou-se a norma que os modelos de linguagem fiquem cada vez maiores. As pessoas costumam criticar que as informações desses grandes modelos em si não são divulgadas para pesquisa, mas pouca atenção é dada ao conhecimento por trás da tecnologia de treinamento de grandes modelos. Este artigo tem como objetivo tomar o modelo de linguagem BLOOM com 176 bilhões de parâmetros como exemplo para esclarecer a engenharia de software e hardware e os pontos técnicos por trás do treinamento de tais modelos, de modo a promover a discussão da tecnologia de treinamento de modelos grandes.
Em primeiro lugar, gostaríamos de agradecer às empresas, indivíduos e grupos que permitiram ou patrocinaram a culminação de nosso grupo na incrível façanha de treinar um modelo de 176 bilhões de parâmetros.
Em seguida, começamos a discutir a configuração do hardware e os principais componentes técnicos.

Segue um breve resumo do projeto:
| hardware | 384 GPUs A100 de 80 GB |
| Programas | Megatron-DeepSpeed |
| arquitetura modelo | Baseado em GPT3 |
| conjunto de dados | 350 bilhões de palavras em 59 idiomas |
| tempo de treino | 3,5 meses |
Composição da equipe
O projeto foi idealizado por Thomas Wolf (Cofundador e CSO da Hugging Face), que ousou competir com as grandes empresas, propondo não só treinar um modelo que se destaca na maior floresta mundial de modelos multilíngues, mas também torná-lo disponível para todos O acesso público aos resultados do treinamento realiza os sonhos da maioria das pessoas.
Este artigo enfoca os aspectos de engenharia do treinamento de modelo. Algumas das partes mais importantes da tecnologia por trás do BLOOM são as pessoas e empresas que compartilham seus conhecimentos e nos ajudam a codificar e treinar.
Devemos agradecer principalmente a 6 grupos:
- A equipe BigScience da HuggingFace dedicou mais de seis funcionários em tempo integral à pesquisa e operação do treinamento, e eles também forneceram ou reembolsaram toda a infraestrutura, exceto o computador de Jean Zay.
- Os desenvolvedores da equipe do Microsoft DeepSpeed que desenvolveram o DeepSpeed e posteriormente o integraram ao Megatron-LM, passaram semanas pesquisando os requisitos do projeto e forneceram muitos conselhos práticos excelentes antes e durante o treinamento.
- A equipe NVIDIA Megatron-LM que desenvolveu o Megatron-LM ficou mais do que feliz em responder às nossas muitas perguntas e fornecer conselhos de uso de alto nível.
- A equipe IDRIS/GENCI, que gerencia o supercomputador Jean Zay, doou poder de computação significativo e forte suporte de administração de sistema para o projeto.
- A equipe do PyTorch criou uma estrutura poderosa na qual o restante do software se baseia e tem nos ajudado muito na preparação para o treinamento, corrigindo vários bugs e melhorando a usabilidade do treinamento dos componentes do PyTorch dos quais dependemos.
- Voluntário do Grupo de Trabalho de Engenharia da BigScience
É difícil nomear todas as pessoas brilhantes que contribuíram para o lado de engenharia do projeto, então vou citar apenas algumas pessoas importantes fora do Hugging Face que lançaram as bases de engenharia para o projeto nos últimos 14 meses:
Olatunji Ruwase, Deepak Narayanan, Jeff Rasley, Jared Casper, Samyam Rajbhandari e Rémi Lacroix
Agradecemos também a todas as empresas que permitiram que seus funcionários contribuíssem para este projeto.
visão geral
A arquitetura do modelo do BLOOM é muito semelhante ao GPT3 com algumas melhorias, que serão discutidas posteriormente neste artigo.
O modelo foi treinado em Jean Zay, um supercomputador financiado pelo governo francês gerenciado pela GENCI e instalado no IDRIS, o centro nacional de computação do Centro Nacional Francês de Pesquisa Científica (CNRS). O poder de computação necessário para o treinamento é generosamente doado a este projeto pelo GENCI (número de doação 2021-A0101012475).
Hardware de treinamento:
- GPU: 384 GPUs NVIDIA A100 de 80 GB (48 nós) + 32 GPUs sobressalentes
- 8 GPUs por nó, 4 interconexões entre placas NVLink, 4 links OmniPath
- Processador: processador AMD EPYC 7543 de 32 núcleos
- Memória da CPU: 512 GB por nó
- Memória GPU: 640 GB por nó
- Conexão entre nós: a placa de rede Omni-Path Architecture (OPA) é usada e a topologia de rede é uma árvore gorda sem bloqueio
- NCCL - Communications Network: uma sub-rede totalmente dedicada
- Disk IO network: GPFS compartilhado com outros nós e usuários
Pontos de verificação:
- principais pontos de verificação
- Cada ponto de verificação contém um estado do otimizador com precisão de fp32 e um peso com precisão de bf16+fp32 e ocupa um espaço de armazenamento de 2,3 TB. Se apenas o peso do bf16 for salvo, apenas 329 GB de espaço de armazenamento serão ocupados.
conjunto de dados:
- 1,5 TB de texto altamente desduplicado e limpo em 46 idiomas, convertido em tokens de 350 bilhões
- O vocabulário do modelo contém 250.680 tokens
- Para obter mais detalhes, consulte The BigScience Corpus A 1.6TB Composite Multilingual Dataset
O treinamento do modelo 176B BLOOM levou cerca de 3,5 meses para ser concluído, de março a julho de 2022 (cerca de 1 milhão de horas de computação).
Megatron-DeepSpeed
O modelo 176B BLOOM é treinado usando Megatron-DeepSpeed , que combina duas técnicas principais:
- Megatron-DeepSpeed :
- DeepSpeed é uma biblioteca de otimização de aprendizado profundo que torna o treinamento distribuído simples, eficiente e eficaz.
- O Megatron-LM é uma estrutura de modelo de transformador grande e poderosa desenvolvida pela equipe de pesquisa de aprendizagem profunda aplicada da NVIDIA.
A equipe do DeepSpeed desenvolveu um esquema 3D baseado em paralelo combinando ZeRO sharding e Pipeline Parallelism na biblioteca DeepSpeed com Tensor Parallelism no Megatron-LM. Consulte a tabela abaixo para obter mais detalhes sobre cada componente.
Observe que o Megatron-DeepSpeed da BigScience é baseado na base de código Megatron-DeepSpeed original e adicionamos alguns códigos a ele.
A tabela a seguir lista quais componentes de cada uma das duas estruturas que empregamos ao treinar o BLOOM:
| componentes | DeepSpeed | Megatron-LM |
|---|---|---|
| Dados ZeRO Paralelo | sim | |
| tensor paralelo | sim | |
| Pipeline Paralelo | sim | |
| otimizador BF16 | sim | |
| Função do kernel de fusão CUDA | sim | |
| carregador de dados | sim |
Observe que tanto o Megatron-LM quanto o DeepSpeed têm paralelismo pipeline e implementações do otimizador BF16, mas usamos a implementação do DeepSpeed porque eles são integrados ao ZeRO.
O Megatron-DeepSpeed atinge o paralelismo 3D para permitir que grandes modelos sejam treinados de maneira muito eficiente. Vamos discutir brevemente o que são componentes 3D.
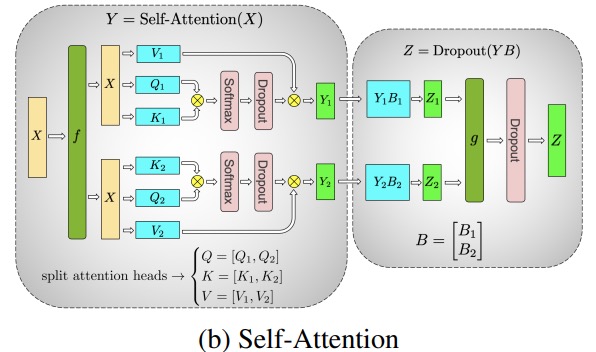
- Paralelismo de dados (DP) - A mesma configuração e modelo são replicados várias vezes, cada uma alimentada com uma cópia diferente dos dados a cada vez. O processamento é feito em paralelo, com todos os compartilhamentos sincronizados ao final de cada etapa de treinamento.
- Tensor Parallelism (TP) - Cada tensor é dividido em pedaços, de modo que cada fatia do tensor reside em sua GPU atribuída, em vez de ter todo o tensor residindo em uma única GPU. Durante o processamento, cada fragmento é processado separadamente e em paralelo em uma GPU diferente, e os resultados são sincronizados ao final da etapa. Isso é chamado de paralelismo horizontal, porque é feito horizontalmente.
- Pipeline Parallelism (PP) - O modelo é dividido verticalmente (ou seja, por camada) em várias GPUs para que apenas uma ou mais camadas de modelo sejam colocadas em uma única GPU. Cada GPU processa diferentes estágios do pipeline em paralelo e processa uma parte do lote.
- Otimizador de redundância zero (ZeRO) - também executa fragmentação de tensor semelhante ao TP, mas todo o tensor é reconstruído a tempo para computação direta ou reversa, portanto, nenhuma modificação do modelo é necessária. Ele também oferece suporte a várias técnicas de descarregamento para compensar a memória limitada da GPU.
paralelismo de dados
A maioria dos usuários com apenas algumas GPUs provavelmente está familiarizada com (DDP), que é a documentaçãoDistributedDataParallel correspondente do PyTorch . Nessa abordagem, os modelos são totalmente replicados para cada GPU e, em seguida, todos os modelos sincronizam seus estados entre si após cada iteração. Esse método pode acelerar o treinamento e resolver problemas investindo mais recursos de GPU. Mas tem a limitação de só funcionar se o modelo couber em uma única GPU.
Dados ZeRO Paralelo
O diagrama a seguir descreve bem o paralelismo de dados ZeRO ( desta postagem no blog ).
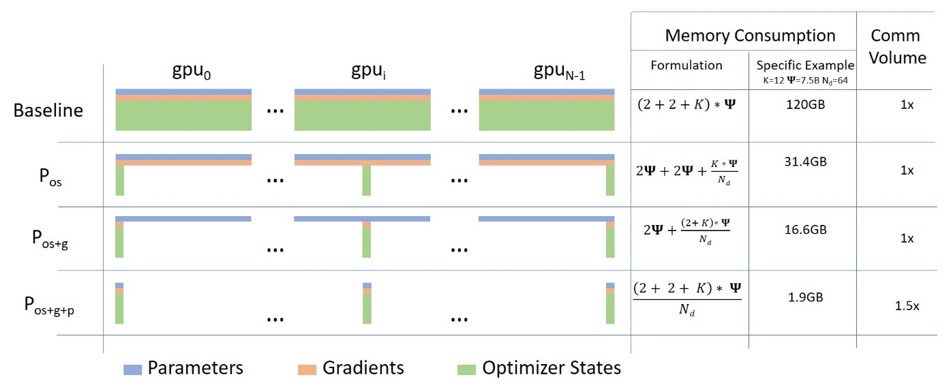
Parece ser relativamente alto, o que pode dificultar sua concentração no entendimento, mas, na verdade, o conceito é muito simples. Este é apenas o DDP usual, exceto que, em vez de cada GPU replicar todos os parâmetros do modelo, gradientes e estado do otimizador, cada GPU armazena apenas uma parte dele. Durante as execuções subsequentes, quando os parâmetros completos da camada para uma determinada camada são necessários, todas as GPUs sincronizam para fornecer umas às outras as peças que faltam - nada mais.
Este componente é implementado pelo DeepSpeed.
tensor paralelo
No Tensor Parallelism (TP), cada GPU processa apenas uma parte de um tensor e as operações de agregação são acionadas apenas quando determinados operadores exigem o tensor completo.
Nesta seção, usamos conceitos e diagramas do documento Megatron-LM Efficient Large-Scale Language Model Training on GPU Clusters .
Os principais módulos do modelo de classe Transformer são: uma camada totalmente conectada nn.Linearseguida por uma camada de ativação não linear GeLU.
Seguindo a notação do artigo da Megatron, podemos escrever a parte do produto escalar como Y = GeLU (XA), onde Xe Ysão os vetores de entrada e saída Ae é a matriz de peso.
É fácil ver como a multiplicação de matrizes pode ser dividida em várias GPUs se expressa em forma de matriz:
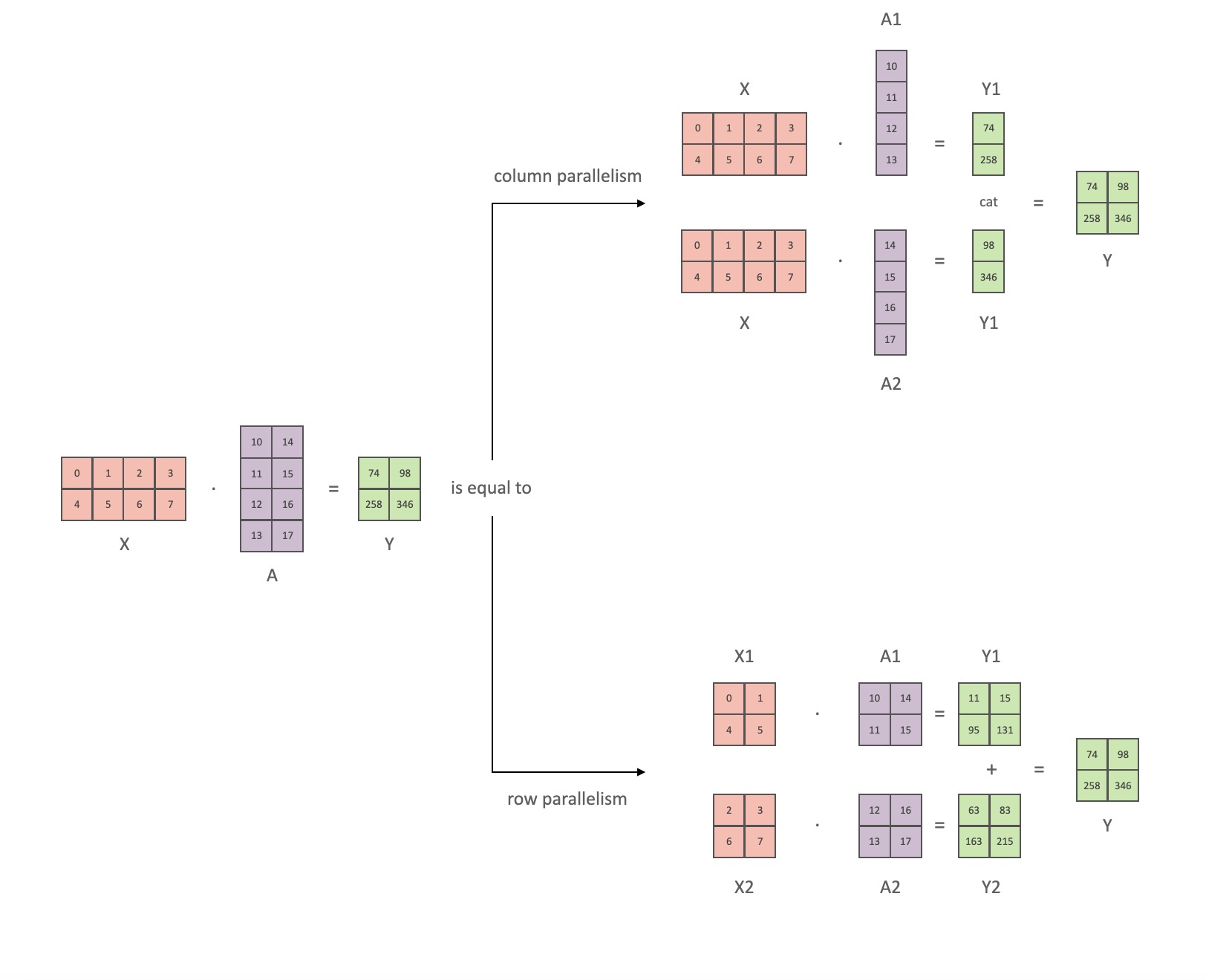
Se dividirmos as matrizes de peso Apor colunas Nem GPUs e, em seguida, realizarmos multiplicações de matrizes XA_1em XA_n, acabamos Ncom vetores de saída Y_1、Y_2、…… 、 Y_n, que podem ser alimentados independentemente GeLU:
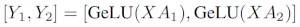
Observe que, como Ya matriz é dividida por coluna, podemos escolher o esquema de divisão por linha para o GEMM subsequente, de modo que ele possa obter diretamente a saída do GeLU da camada anterior sem nenhuma comunicação adicional.
Usando este princípio, podemos atualizar um MLP de profundidade arbitrária, simplesmente sincronizando a GPU após cada 拆列 - 拆行sequência . Os autores do artigo Megatron-LM fornecem uma boa ilustração para isso:
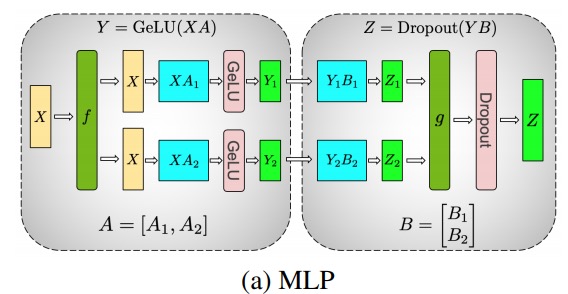
Aqui festá o operador de identidade na passagem para frente e todos reduzem na passagem para trás, e gsão todos reduzidos na passagem para frente e a identidade na passagem para trás.
Paralelizar as camadas de atenção de várias cabeças é ainda mais simples, pois elas são inerentemente paralelas devido a várias cabeças independentes!
Considerações especiais: como há duas reduções por camada nas passagens para frente e para trás, o TP requer interconexões muito rápidas entre os dispositivos. Portanto, a menos que você tenha uma rede muito rápida, não é recomendável fazer TP em vários nós. Em nossa configuração de hardware para treinamento do BLOOM, a velocidade entre os nós é muito mais lenta do que no PCIe. De fato, se o nó tiver 4 GPUs, um grau máximo de TP de 4 é melhor. Se você precisar de um grau TP de 8, precisará usar um nó com pelo menos 8 GPUs.
Este componente é implementado pelo Megatron-LM. Megatron-LM expandiu recentemente a capacidade de paralelo de tensor e adicionou a capacidade de paralelismo de sequência para operadores que são difíceis de usar o algoritmo de segmentação mencionado acima, como LayerNorm. O artigo Redução da recomputação da ativação em modelos de transformadores grandes fornece detalhes dessa técnica. O paralelismo de sequência foi desenvolvido após o treinamento do BLOOM, portanto o BLOOM foi treinado sem essa técnica.
Pipeline Paralelo
Paralelismo de pipeline ingênuo (PP ingênuo) é distribuir camadas de modelo em grupos em várias GPUs e simplesmente mover dados de GPU para GPU como se fosse uma grande GPU composta. O mecanismo é relativamente simples - você vincula a camada desejada ao dispositivo correspondente com .to()o método , e agora sempre que os dados entram ou saem dessas camadas, as camadas alternarão os dados para o mesmo dispositivo da camada e o restante permanecerá o mesmo.
Na verdade, isso é paralelismo de modelo vertical, porque se você se lembrar de como desenhamos a topologia da maioria dos modelos, na verdade dividimos as camadas do modelo verticalmente. Por exemplo, se a imagem abaixo mostra um modelo de 8 camadas:
=================== ===================
| 0 | 1 | 2 | 3 | | 4 | 5 | 6 | 7 |
=================== ===================
GPU0 GPU1
Cortamos verticalmente em 2 partes, colocando as camadas 0-3 na GPU0 e as camadas 4-7 na GPU1.
Agora, quando os dados são passados da camada 0 para a camada 1, da camada 1 para a camada 2 e da camada 2 para a camada 3, é como se fosse um avanço normal em uma única GPU. Mas quando os dados precisam passar da camada 3 para a camada 4, eles precisam ser transferidos da GPU0 para a GPU1, o que introduz sobrecarga de comunicação. Se as GPUs participantes estiverem no mesmo nó de computação (por exemplo, a mesma máquina física), a transferência é muito rápida, mas se as GPUs estiverem em diferentes nós de computação (por exemplo, várias máquinas), a sobrecarga de comunicação pode ser muito maior.
Em seguida, as camadas 4 a 5 a 6 a 7 são como modelos normais novamente e, quando a camada 7 é concluída, geralmente precisamos enviar os dados de volta à camada 0, onde estão os rótulos (ou enviar os rótulos para a última camada). Agora a perda pode ser calculada e o otimizador pode ser usado para atualizar os parâmetros.
pergunta:
- Por que esse método é chamado de paralelismo de pipeline ingênuo e quais são suas desvantagens? Principalmente porque o esquema tem apenas uma GPU ociosa em um determinado momento. Portanto, se você usar 4 GPUs, estará quase quadruplicando a quantidade de memória em uma única GPU, e outros recursos (como computação) serão praticamente inúteis. Adicione a sobrecarga de copiar dados entre dispositivos. Portanto, 4 cartões de 6 GB em paralelo usando pipeline ingênuo poderão manter o mesmo modelo de tamanho que 1 cartão de 24 GB, que treina mais rápido porque não tem sobrecarga de transferência de dados. Mas, por exemplo, se você tiver um cartão de 40 GB, mas precisar executar um modelo de 45 GB, poderá usar 4 cartões de 40 GB (o que é suficiente, porque também existem gradientes e estados do otimizador que exigem memória de vídeo).
- O compartilhamento de incorporações pode exigir cópias entre GPUs. O paralelismo de pipeline (PP) que usamos é quase o mesmo que o PP ingênuo acima, mas resolve o problema de ociosidade da GPU dividindo lotes de entrada em lotes de micros e criando artificialmente pipelines que permitem que diferentes GPUs participem do processo de computação simultaneamente.
A figura abaixo é do artigo do GPipe , a parte superior representa o esquema ingênuo de PP e a parte inferior é o método PP:

Da metade inferior da figura é fácil ver que o PP tem menos zona morta (o que significa que a GPU está ociosa), ou seja, menos "bolhas".
O grau de paralelismo dos dois esquemas da figura é 4, ou seja, o pipeline é composto por 4 GPUs. Portanto, existem quatro caminhos diretos de F0, F1, F2 e F3 e, em seguida, o caminho reverso de B3, B2, B1 e B0.
O PP introduz um novo hiperparâmetro para ajustar, chamado 块 (chunks). Ele define quantos blocos de dados são enviados sequencialmente pelo mesmo nível de pipe. Por exemplo, na metade inferior da figura, você pode ver chunks = 4. GPU0 executa o mesmo caminho de avanço nos pedaços 0, 1, 2 e 3 (F0,0, F0,1, F0,2, F0,3) e espera até que as outras GPUs terminem seu trabalho antes que GPU0 comece a funcionar novamente, execute o caminho de volta para os blocos 3, 2, 1 e 0 (B0,3, B0,2, B0,1, B0,0).
Observe que isso é conceitualmente o mesmo que etapas de acumulação de gradiente (GAS). PyTorch chama 块, e DeepSpeed chama GAS.
Pois 块, o PP introduz o conceito de microlotes (MBS). O DP divide o tamanho do lote global em tamanhos de lote pequenos, portanto, se o grau de DP for 4, o tamanho do lote global 1024 será dividido em 4 tamanhos de lote pequenos e cada tamanho de lote pequeno será 256 (1024/4). E se 块o número (ou GAS) for 32, acabamos com um tamanho de microlote de 8 (256/32). Cada estágio de tubo processa um microlote por vez.
A fórmula para calcular o tamanho global do lote para a configuração DP+PP é: mbs * chunks * dp_degree( 8 * 32 * 4 = 1024).
Vamos voltar e olhar para a foto novamente.
Usando PP ingênuo, chunks=1você acaba com PP ingênuo, que é muito ineficiente. E com 块números , você acaba com pequenos tamanhos de microlotes, que provavelmente também não são muito eficientes. Portanto, deve-se experimentar para encontrar 块o número .
O gráfico mostra que existem bolhas de tempo "mortas" que não podem ser paralelizadas porque o último forwardestágio precisa aguardar backwarda conclusão do pipeline. Então, o problema de encontrar o 块número para que todas as GPUs participantes possam atingir alta utilização simultânea é, na verdade, transformado em minimizar o número de bolhas.
Esse mecanismo de agendamento é chamado 全前全后. Algumas outras opções são Tandem e Tandem Intercalado .
Enquanto o Megatron-LM e o DeepSpeed têm suas próprias implementações do protocolo PP, o Megatron-DeepSpeed usa a implementação do DeepSpeed porque está integrado a outros recursos do DeepSpeed.
Outra questão importante aqui é o tamanho da matriz de incorporação de palavras. Embora geralmente as matrizes de incorporação de palavras exijam menos memória do que os blocos transformadores, no caso do BLOOM com um vocabulário de 250k, a camada de incorporação requer 7,2 GB para pesos bf16, em comparação com apenas 4,9 GB para o bloco transformador. Portanto, tivemos que fazer o Megatron-Deepspeed tratar a camada de incorporação como um bloco transformador. Assim temos um pipeline de 72 estágios, sendo 2 deles dedicados ao embedding (primeiro e último). Isso nos permite equilibrar o consumo de memória da GPU. Se não fizéssemos isso, teríamos o primeiro e o último estágio consumindo muita memória da GPU, e 95% do uso da memória da GPU seria muito pouco, então o treinamento seria muito ineficiente.
DP+PP
Há uma imagem no Tutorial DeepSpeed Pipeline Parallel que demonstra como combinar DP e PP, conforme mostrado abaixo.
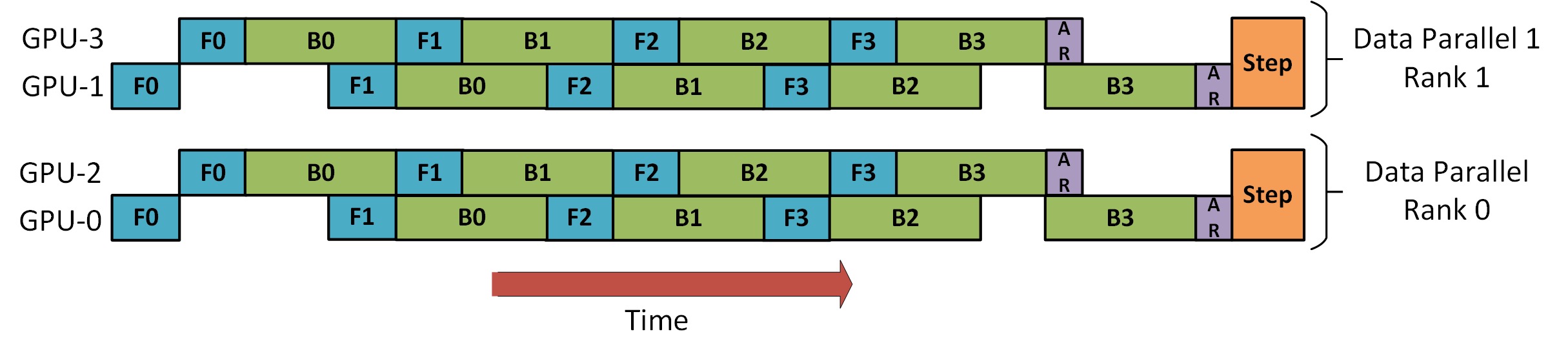
O importante a entender aqui é que o nível 0 do DP não pode ver o GPU2 e o nível 1 do DP não pode ver o GPU3. Para DP, existem apenas GPUs 0 e 1, e os dados são alimentados para eles. GPU0 usa PP para descarregar "secretamente" parte de sua carga para GPU2. Da mesma forma, o GPU1 também receberá ajuda do GPU3.
Como pelo menos 2 GPUs são necessárias para cada dimensão, pelo menos 4 GPUs são necessárias aqui.
DP+PP+TP
Para um treinamento mais eficiente, PP, TP e DP podem ser combinados, chamados de paralelismo 3D, conforme mostrado na figura abaixo.
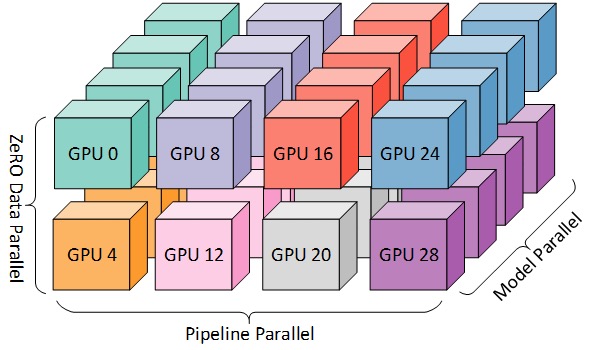
Esta figura é da postagem do blog 3D Parallelism: Scaling to Trillion Parameter Models ), que também é um bom artigo.
Como você precisa de pelo menos 2 GPUs por dimensão, aqui você precisa de pelo menos 8 GPUs para paralelismo 3D completo.
ZeRO DP+PP+TP
Uma das principais características do DeepSpeed é o ZeRO, que é uma versão aprimorada superescalável do DP, que discutimos na seção [ZeRO Data Parallel] (#ZeRO- Data Parallel). Normalmente é uma função independente e não requer PP ou TP. Mas também pode ser combinado com PP, TP.
Quando o ZeRO-DP é combinado com PP (e, portanto, TP), ele normalmente ativa apenas a fase 1 do ZeRO, que fragmenta apenas o estado do otimizador. O estágio 2 do ZeRO também fragmenta os gradientes e o estágio 3 também fragmenta os pesos do modelo.
Embora seja teoricamente possível usar o estágio 2 do ZeRO com paralelismo de pipeline, isso pode ter um impacto ruim no desempenho. Cada microlote requer uma comunicação adicional de redução de dispersão para agregar gradientes antes da fragmentação, o que adiciona uma sobrecarga de comunicação potencialmente significativa. De acordo com a natureza paralela do pipeline, usaremos pequenos microlotes e focaremos na compensação entre intensidade aritmética (tamanho do microlote) e minimização de bolhas no pipeline (número de microlotes). Portanto, o aumento da sobrecarga de comunicação prejudica o paralelismo do pipeline.
Além disso, devido ao PP, o número de camadas já é menor que o normal, portanto não economiza muita memória. O PP reduziu o tamanho do gradiente 1/PP, portanto, a fatia do gradiente nessa base não economiza muita memória em comparação com o DP puro.
O ZeRO stage 3 também pode ser utilizado para treinar modelos deste porte, porém, requer mais comunicação que o DeepSpeed 3D em paralelo. Há um ano, após uma avaliação cuidadosa de nosso ambiente, descobrimos que o paralelismo Megatron-DeepSpeed 3D teve o melhor desempenho. O desempenho do ZeRO Fase 3 melhorou significativamente desde então e, se o reavaliássemos hoje, talvez escolheríamos a Fase 3.
otimizador BF16
Treinar enormes modelos LLM com FP16 é um não-não.
Demonstramos isso por nós mesmos passando meses treinando o modelo 104B, que, como você pode ver no Tensorboard , falhou totalmente. No processo de luta contra a sempre divergente lm-loss, aprendemos muito:
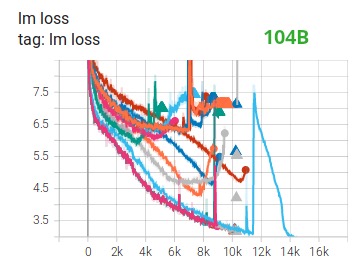
Também recebemos a mesma sugestão das equipes Megatron-LM e DeepSpeed após treinarem o modelo 530B . O recém-lançado OPT-175B também relatou que treinou muito duro no FP16.
Então, em janeiro, sabíamos que íamos treinar no A100, que suporta o formato BF16. Olatunji Ruwase desenvolveu um "BF16Optimizer" para treinar o BLOOM.
Se você não estiver familiarizado com esse formato de dados, verifique seu layout de bits . A chave para o formato BF16 é que ele tem o mesmo número de expoentes que o FP32, portanto não transborda, mas o FP16 frequentemente transborda! FP16 tem um intervalo de valor máximo de 64k, você só pode multiplicar números menores. Por exemplo, você pode fazer 250*250=62500, mas se tentar 255*255=65025, vai transbordar, que é a principal causa de problemas com o treinamento. Isso significa que seus pesos devem ser mantidos pequenos. Uma técnica chamada escala de perda ajuda a aliviar esse problema, mas o pequeno alcance do FP16 ainda pode ser um problema quando os modelos ficam muito grandes.
O BF16 não tem esse problema, você pode fazer facilmente 10_000*10_000=100_000_000, sem problema nenhum.
Obviamente, como o BF16 e o FP16 têm o mesmo tamanho, 2 bytes, não há almoço grátis, e a desvantagem ao usar o BF16 é que ele tem uma precisão muito baixa. No entanto, você deve se lembrar que o método de descida do gradiente estocástico e suas variantes que usamos no treinamento, esse método é um pouco como escalonamento, se você não encontrar a direção perfeita nesta etapa, tudo bem, você corrigirá na próxima passo próprio.
Seja usando BF16 ou FP16, há uma cópia dos pesos que está sempre em FP32 - é isso que é atualizado pelo otimizador. Portanto, o formato de 16 bits é usado apenas para cálculos, o otimizador atualiza os pesos FP32 com precisão total e os converte para o formato de 16 bits para a próxima iteração.
Todos os componentes do PyTorch foram atualizados para garantir que eles executem qualquer acúmulo no FP32, para que não ocorra perda de precisão.
Uma questão chave é a acumulação de gradiente, que é uma das principais características do paralelismo de pipeline, uma vez que os gradientes processados por cada microbatch são acumulados. A implementação do acúmulo de gradiente no FP32 para a precisão do treinamento é crítica, e foi exatamente isso BF16Optimizerque foi feito .
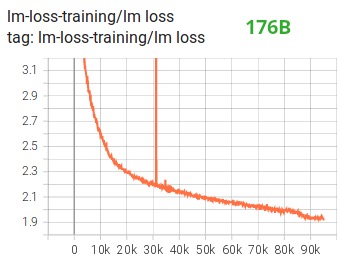
Entre outras melhorias, acreditamos que o uso do treinamento de precisão mista do BF16 transformou um possível pesadelo em um processo relativamente tranquilo, como pode ser visto no seguinte gráfico de perda de lm:
Função do kernel de fusão CUDA
A GPU faz principalmente duas coisas. Ele pode gravar dados e ler dados da memória de vídeo e realizar cálculos nesses dados. Quando a GPU está ocupada lendo e gravando dados, as unidades de computação da GPU ficam ociosas. Se quisermos utilizar a GPU com eficiência, queremos manter o tempo ocioso no mínimo.
Uma função do kernel é um conjunto de instruções que implementam uma operação específica do PyTorch. Por exemplo, torch.addquando , ele passa por um agendador PyTorch , que decide qual código deve ser executado com base nos valores dos tensores de entrada e outras variáveis e, por fim, o executa. Os kernels CUDA usam CUDA para implementar esses códigos e, portanto, são executados apenas em GPUs NVIDIA.
Agora, c = torch.add (a, b); e = torch.max ([c,d])ao , normalmente o que o PyTorch fará é lançar dois kernels separados, um que faz a adição ade be , ce o outro que leva o máximo de dambos . Nesse caso, a GPU abusca ba soma de sua memória de vídeo, realiza a adição e depois grava o resultado de volta na memória de vídeo. Em seguida, ele cexecuta a operaçãod e grava o resultado na memória de vídeo novamente.max
Se fôssemos fundir essas duas operações, ou seja, colocá-las em uma "função de kernel fundido" e, em seguida, iniciar esse kernel, em vez de cgravar o resultado intermediário na memória de vídeo, o manteríamos dfazer o cálculo definitivo. Isso economiza muita sobrecarga e evita que a GPU fique ociosa, tornando toda a operação muito mais eficiente.
A função do kernel de fusão faz exatamente isso. Eles substituem principalmente várias computações discretas e movimentação de dados de e para a memória de vídeo por computações fundidas com muito pouca movimentação de dados. Além disso, alguns núcleos de fusão transformam matematicamente as operações para que certas combinações de cálculos possam ser executadas mais rapidamente.
Para treinar o BLOOM de forma rápida e eficiente, é necessário usar várias funções customizadas de kernel fundido CUDA fornecidas pelo Megatron-LM. Em particular, há um kernel de fusão LayerNorm e kernels para várias combinações de escalonamento de fusão, mascaramento e operações softmax. O Bias Add também é integrado ao GeLU por meio da função JIT do PyTorch. Essas operações são todas limitadas à memória, por isso é importante fundi-las para maximizar a quantidade de computação após cada leitura de memória de vídeo. Assim, por exemplo, executar Bias Add durante a execução de uma operação GeLU cujo gargalo está na memória não aumentará o tempo de execução. Essas funções do kernel podem ser encontradas na biblioteca de códigos Megatron-LM .
conjunto de dados
Outra característica importante do Megatron-LM é o carregador de dados eficiente. Antes do início do primeiro treinamento, cada amostra em cada conjunto de dados é dividida em amostras de comprimento de sequência fixo (BLOOM é 2048) e um índice é criado para numerar cada amostra. Com base nos hiperparâmetros de treinamento, determinaremos o número de épocas que cada conjunto de dados precisa participar e, com base nisso, criaremos uma lista ordenada de índices de amostra e, em seguida, embaralharemos. Por exemplo, se um conjunto de dados tiver 10 amostras que devem ser treinadas para 2 épocas, o sistema primeiro classificará os índices de amostra em [0, ..., 9, 0, ..., 9]ordem embaralhará a ordem para criar a ordem global final para o conjunto de dados. Observe que isso significa que o treinamento não irá simplesmente iterar em todo o conjunto de dados e repetir, você pode ver a mesma amostra duas vezes antes de ver outra, mas no final do treinamento o modelo só verá cada amostra duas vezes. Isso ajuda a garantir uma curva de treinamento suave durante todo o treinamento. Esses índices, incluindo o deslocamento de cada amostra no conjunto de dados original, são salvos em um arquivo para evitar recalculá-los sempre que o treinamento é iniciado. Por fim, vários desses conjuntos de dados podem ser combinados com diferentes pesos nos dados finais usados para treinamento.
Embed LayerNorm
Em nossos esforços para evitar a divergência do modelo 104B, descobrimos que adicionar um LayerNorm adicional após a primeira camada de incorporação de palavras tornou o treinamento mais estável.
Esse insight vem de experimentos com bitsandbytes , que tem uma operação que é uma incorporação normal com uma LayerNorm inicializada com uma função xavier uniforme.StableEmbedding
Código de localização
Com base no artigo Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation , também substituímos as incorporações posicionais normais por AliBi, que permite a extrapolação de sequências de entrada mais longas do que as sequências de entrada usadas para treinar o modelo. Portanto, embora treinemos com sequências de comprimento 2048, o modelo pode lidar com sequências mais longas durante a inferência.
dificuldades no treinamento
Com a arquitetura, hardware e software prontos, pudemos iniciar os treinamentos no início de março de 2022. Desde então, no entanto, as coisas não foram tão tranquilas. Nesta seção, discutimos alguns dos principais obstáculos que encontramos.
Antes do início do treinamento, há muitas questões a serem resolvidas. Em particular, encontramos vários problemas que só apareceram depois que começamos o treinamento em 48 nós, não em pequenas escalas. Por exemplo, CUDA_LAUNCH_BLOCKING=1para evitar que o framework trave, precisamos dividir o grupo de otimizadores em grupos menores, caso contrário o framework travará novamente. Você pode ler mais sobre isso nas Crônicas Pré-Treinamento.
O principal tipo de problema encontrado durante o treinamento são falhas de hardware. Como este é um novo cluster com cerca de 400 GPUs, em média, enfrentamos 1-2 falhas de GPU por semana. Salvamos um ponto de verificação a cada 3 horas (100 iterações). Como resultado, perdemos uma média de 1,5 horas de treinamento por semana devido a falhas de hardware. O administrador do sistema Jean Zay substituirá a GPU com defeito e restaurará o nó. Enquanto isso, temos nós sobressalentes disponíveis.
Também tivemos vários outros problemas que resultaram em tempo de inatividade de 5 a 10 horas várias vezes, alguns relacionados a bugs de impasse no PyTorch, outros devido a espaço em disco insuficiente. Se você estiver interessado em detalhes, consulte as crônicas de treinamento .
Todo esse tempo de inatividade foi planejado na análise de viabilidade do treinamento desse modelo, e escolhemos o tamanho de modelo apropriado e a quantidade de dados que queríamos que o modelo consumisse de acordo. Então, mesmo com esses problemas de indisponibilidade, conseguimos concluir o treinamento dentro do tempo estimado. Como mencionado anteriormente, leva cerca de 1 milhão de horas de computação para ser concluído.
Outro problema é que o SLURM não foi projetado para ser usado por um grupo de pessoas. Os trabalhos SLURM pertencem a um único usuário e, se eles não estiverem por perto, outros membros do grupo não poderão fazer nada com o trabalho em execução. Temos um esquema de encerramento que permite que outros usuários do grupo finalizem o processo atual sem a presença do usuário que iniciou o processo. Isso funciona muito bem em 90% dos problemas. Se os designers SLURM lerem isso, adicione o conceito de um grupo Unix para que um trabalho SLURM possa pertencer a um grupo.
Como o treinamento funciona 24 horas por dia, 7 dias por semana, precisamos de alguém de plantão - mas como temos pessoas na Europa e na costa oeste do Canadá, não há necessidade de alguém carregar um pager e somos muito bons em apoiar uns aos outros. Claro, o treinamento de fim de semana deve ser observado. Nós automatizamos a maioria das coisas, incluindo a recuperação automática de falhas de hardware, mas às vezes a intervenção humana ainda é necessária.
para concluir
A parte mais difícil e estressante do treinamento são os 2 meses antes do início do treinamento. Estávamos sob muita pressão para começar a treinar o mais rápido possível e, devido ao pouco tempo alocado pelos recursos, não conseguimos acesso ao A100 até o último minuto. Então foi um momento muito difícil, considerando BF16Optimizerque foi escrito no último minuto, precisávamos depurá-lo e corrigir vários bugs. Conforme mencionado na seção anterior, encontramos novos problemas que só apareceram depois que começamos a treinar em 48 nós, e não em pequenas escalas.
Mas assim que resolvemos isso, o treinamento em si foi surpreendentemente tranquilo, sem grandes contratempos. Na maioria das vezes, há apenas um de nós assistindo e apenas algumas pessoas envolvidas na solução de problemas. Tivemos um grande apoio da direção de Jean Zay, que atendeu prontamente a maioria das necessidades que surgiram durante o treinamento.
No geral, foi uma experiência super intensa, mas gratificante.
O treinamento de grandes modelos de linguagem continua sendo uma tarefa desafiadora, mas esperamos que, ao construir e compartilhar essa técnica publicamente, outros possam aprender com nossa experiência.
recurso
links importantes
Documentos e Artigos
É impossível para nós explicar tudo em detalhes neste artigo, portanto, se as técnicas aqui apresentadas despertarem sua curiosidade e fizerem você querer aprender mais, leia os seguintes artigos:
Megatron-LM:
- Treinamento eficiente de modelos de linguagem em larga escala em clusters de GPU .
- Reduzindo a recomputação de ativação em modelos de transformadores grandes
Velocidade Profunda:
- ZeRO: otimizações de memória para treinar trilhões de modelos de parâmetros
- ZeRO-Offload: democratizando o treinamento de modelos em escala de bilhões
- ZeRO-Infinity: quebrando a parede de memória da GPU para aprendizado profundo em escala extrema
- DeepSpeed: Treinamento de modelo em escala extrema para todos
Megatron-LM e Deepspeedeed combinados:
Álibi:
- Treinar curto, testar longo: atenção com polarizações lineares permite a extrapolação do comprimento de entrada
- Qual modelo de linguagem treinar se você tiver um milhão de horas de GPU? - Lá você encontrará os experimentos que nos levaram a escolher o ALiBi.
BitsNBytes:
- Otimizadores de 8 bits via Quantização em bloco (usamos a incorporação do LaynerNorm neste artigo, mas outras partes do artigo e suas técnicas também são muito boas, a única razão pela qual não usamos otimizadores de 8 bits é que já usamos DeepSpeed-ZeRO para economizar memória do otimizador).
Obrigado pela postagem no blog
Muito obrigado às seguintes pessoas que fizeram boas perguntas e ajudaram a melhorar a legibilidade do artigo (em ordem alfabética):
- Britney Müller,
- Douwe Kiela,
- Jared Cásper,
- Jeff Rasley,
- Julien Launay,
- Leandro von Werra,
- Omar Sanseviero,
- Stefan Schweter e
- Thomas Wang.
Os gráficos neste artigo foram criados principalmente por Chunte Lee.
Texto original em inglês: https://hf.co/blog/bloom-megatron-deepspeed
Autor original: Stas Bekman
Tradutor: Matrix Yao (Yao Weifeng), um engenheiro de aprendizado profundo da Intel, trabalha na aplicação de modelos de família de transformadores em vários dados modais e no treinamento e raciocínio de modelos de grande escala.
Revisão e diagramação: zhongdongy (Adong)