Resumo: Para avaliar a capacidade de generalização do modelo, ou seja, julgar se o modelo é bom ou ruim, precisamos usar um determinado índice para medi-lo. Com o índice de avaliação, podemos comparar os prós e contras de diferentes modelos, e usar esse índice para otimizar ainda mais o modelo.
Este artigo é compartilhado da comunidade de nuvem da Huawei " Explicação detalhada dos indicadores de avaliação e implementação de código do modelo de detecção de destino ", autor: Embedded Vision.
prefácio
Para entender a capacidade de generalização do modelo, ou seja, julgar se o modelo é bom ou ruim, precisamos usar um determinado índice para medi-lo. Com o índice de avaliação, podemos comparar os prós e contras de diferentes modelos e use esse índice para otimizar ainda mais o modelo. Para os dois tipos de modelos supervisionados, classificação e regressão, existem critérios de avaliação distintos .
Diferentes problemas e diferentes conjuntos de dados terão diferentes indicadores de avaliação de modelo, como problemas de classificação. No caso de categorias de conjuntos de dados balanceados, a precisão pode ser usada como um indicador de avaliação, mas, na realidade, quase todos os conjuntos de dados são categorias desbalanceadas. , o AP é usado como índice de avaliação da classificação, o AP de cada categoria é calculado separadamente e, em seguida, o mAP é calculado .
1. Precisão, recall e F1
1.1, taxa de precisão
Exatidão (precisão) – Exatidão , a porcentagem de resultados corretos previstos no total de amostras, definida da seguinte forma:
Precisão = ( TP + TN )/( TP + TN + FP + FN )
A taxa de erro e a precisão, embora comumente usadas, não atendem a todos os requisitos da tarefa. Tome o problema da melancia como exemplo. Supondo que o fazendeiro de melão traga um carrinho de melancias, usamos o modelo treinado para discriminar as melancias. Agora, a precisão pode apenas medir quantas melancias são consideradas da categoria correta (duas categorias: melões bons e melões ruins). Mas se estamos mais preocupados com "qual proporção das melancias colhidas são boas", ou "quantas proporções de todos os bons melões são colhidas", então os indicadores de precisão e taxa de erro obviamente não são suficientes.
Embora a taxa de precisão possa julgar a taxa correta geral, ela não pode ser usada como um bom indicador para medir o resultado quando a amostra está desbalanceada. Para dar um exemplo simples, por exemplo, em uma amostra total, as amostras positivas representam 90%, as amostras negativas representam 10% e as amostras estão seriamente desbalanceadas. Nesse caso, precisamos apenas prever todas as amostras como amostras positivas para obter uma alta taxa de precisão de 90%, mas na verdade não as classificamos com muito cuidado, apenas casualmente. Isso mostra que, devido ao problema de desequilíbrio da amostra, os resultados de alta precisão obtidos contêm muita água. Ou seja, se as amostras não forem balanceadas, a taxa de precisão será inválida.
1.2, taxa de precisão, taxa de recall
O cálculo da taxa de precisão (taxa de precisão) P e taxa de rechamada (taxa de rechamada) R envolve a definição da matriz de confusão. A tabela da matriz de confusão é a seguinte:
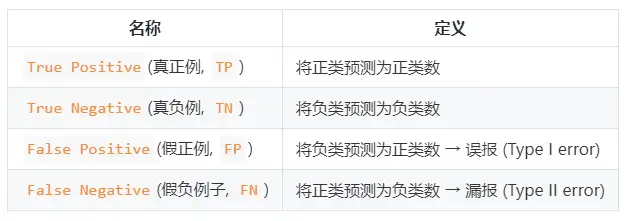
Fórmulas de precisão e recall:
- Taxa de precisão (taxa de precisão) P=TP/(TP+FP) P = TP /( TP + FP )
- Taxa de rechamada (taxa de rechamada) R=TP/(TP+FN) R = TP /( TP + FN )
A taxa de precisão e a taxa de precisão parecem um pouco semelhantes, mas são dois conceitos completamente diferentes. A taxa de precisão representa a precisão da previsão dos resultados da amostra positiva, e a taxa de precisão representa a precisão geral da previsão , incluindo amostras positivas e amostras negativas.
A taxa de precisão descreve o quão preciso é o modelo , ou seja, quantos dos exemplos positivos previstos são exemplos verdadeiros; a taxa de rechamada descreve o quão completo é o modelo , ou seja, quantas das amostras verdadeiras são previstas pelo nosso modelo é um exemplo positivo. A diferença entre a taxa de precisão e a taxa de recuperação está nos diferentes denominadores .Um denominador é o número de amostras previstas como positivas e o outro é o número de todas as amostras positivas na amostra original.
1.3, pontuação F1
Se quisermos encontrar um equilíbrio entre P e R , precisamos de um novo indicador: F 1 score. A pontuação F 1 leva em consideração a taxa de precisão e a taxa de rechamada, de modo que as duas possam atingir o mais alto ao mesmo tempo, e um equilíbrio é feito. A fórmula de cálculo de F 1 é a seguinte:
O cálculo de F 1 aqui é para o modelo de classificação binária, consulte o seguinte para o cálculo de F 1 para tarefas de classificação múltipla.
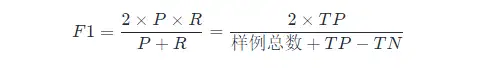
A forma geral da métrica F 1: Fβ , que nos permite expressar nosso viés para precisão/recall, Fβ é calculada da seguinte forma:
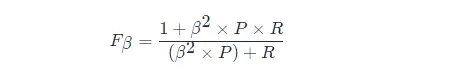
Dentre eles, β > 1 tem maior impacto na taxa de revocação, e β < 1 tem maior impacto na taxa de precisão.
Diferentes problemas de visão computacional têm preferências diferentes para os dois tipos de erros e geralmente tentam reduzir o outro tipo de erros quando um determinado tipo de erro não ultrapassa um determinado limite. Na detecção de alvos, o mAP (precisão média média) leva em consideração ambos os erros como um indicador unificado.
Muitas vezes, teremos múltiplas matrizes de confusão, como treinamento/teste múltiplo, cada vez que uma matriz de confusão pode ser obtida; ou treinamento/teste em vários conjuntos de dados, esperando estimar o desempenho "global" do algoritmo; e Ou executar tarefas de multiclassificação, cada combinação de duas categorias corresponde a uma matriz de confusão; ...Em geral, esperamos considerar de forma abrangente as taxas de precisão e revocação nas n n matrizes de confusão de duas categorias.
Uma abordagem direta é calcular primeiro as taxas de precisão e revocação em cada matriz de confusão, que são registradas como ( P 1, R 1), ( P 2, R 2),...,( Pn , Rn ) Em seguida, tire a média, para obter "Macro Precision (Macro-P)", "Macro Precision (Macro-R)" e o correspondente "Macro F1 F 1 (Macro-F1) " :
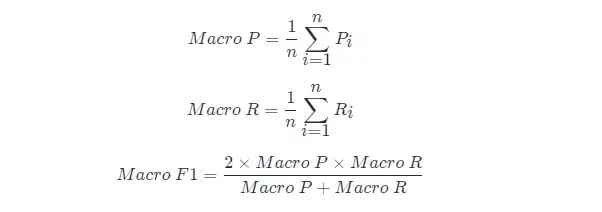
Outro método é calcular a média dos elementos correspondentes de cada matriz de confusão para obter os valores médios de TP, FP, TN, FN TP , FP , TN e FN e , em seguida, calcular a "taxa de microprecisão" (Micro-P ), "Micro Recall" (Micro-R) e "Micro F 1" (Mairo-F1)

1.4, curva PR
A relação entre a taxa de precisão e a taxa de rechamada pode ser mostrada por um gráfico PR. Tomando a taxa de precisão P como o eixo vertical e a taxa de rechamada R como o eixo horizontal, você pode obter a curva de taxa de taxa de rechamada de precisão, referida como a curva PR . A área sob a curva PR é definida como AP:
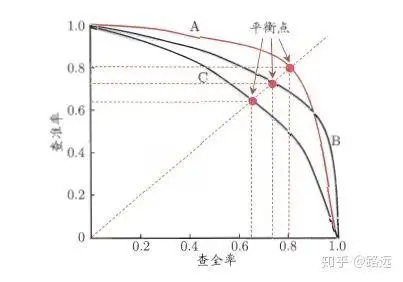
1.4.1, Como entender a curva PR
Pode ser entendido a partir de um modelo de classificação ou de um modelo de classificação. Tomando a regressão logística como exemplo, a saída da regressão logística é um número de probabilidade entre 0 e 1. Portanto, se quisermos julgar se um usuário é bom ou ruim de acordo com essa probabilidade, devemos definir um limite. De um modo geral, quanto maior a probabilidade de regressão logística, mais próxima ela fica de 1, o que significa que é mais provável que ele seja um mau usuário. Por exemplo, definimos um limite de 0,5, ou seja, consideramos todos os usuários com probabilidade menor que 0,5 como bons usuários e aqueles com probabilidade maior que 0,5 como maus usuários. Portanto, para o valor limite de 0,5, podemos obter o par correspondente de precisão e recuperação.
Mas o problema é: esse limite é definido arbitrariamente por nós e não sabemos se esse limite atende aos nossos requisitos. Portanto, para encontrar um limite mais adequado para atender aos nossos requisitos, devemos percorrer todos os limites entre 0 e 1, e cada limite corresponde a um par de precisão e revocação, obtendo assim a curva PR.
Finalmente, como encontrar o melhor ponto de limiar? Em primeiro lugar, precisamos explicar nossos requisitos para esses dois indicadores: esperamos que tanto a taxa de precisão quanto a taxa de rechamada sejam muito altas ao mesmo tempo. Mas, na verdade, esses dois indicadores são um par de contradições e é impossível atingir altas duplas. É óbvio pelo gráfico que se um deles é muito alto, o outro deve ser muito baixo. A seleção de um ponto limite apropriado depende das necessidades reais. Por exemplo, se quisermos uma alta taxa de recuperação, sacrificaremos alguma taxa de precisão. No caso de garantir a maior taxa de recuperação, a taxa de precisão não é tão baixa. .
1.5, curva ROC e área AUC
- A curva PR tem Recall como eixo horizontal e Precision como eixo vertical; enquanto a curva ROC tem FPR como eixo horizontal e TPR como eixo vertical**. Quanto mais próxima a curva PR estiver do canto superior direito, melhor será o desempenho . Ambas as métricas da curva PR se concentram em exemplos positivos
- A curva PR mostra a curva Precision vs Recall, e a curva ROC mostra a curva FPR (eixo x: taxa de falso positivo) vs TPR (taxa de verdadeiro positivo, TPR).
- [ ] Curva ROC
- [ ] área AUC
2. AP e mAP
2.1, Compreensão dos indicadores AP e mAP
O AP mede a qualidade do modelo treinado em cada categoria, e o mAP mede a qualidade do modelo em todas as categorias. Após a obtenção do AP, o cálculo do mAP torna-se muito simples, que é tirar a média de todos os APs. A fórmula de cálculo do AP é relativamente complicada (por isso é um capítulo separado), consulte o seguinte para obter detalhes.
O termo mAP tem diferentes definições. Essa métrica é comumente usada nas áreas de recuperação de informações, classificação de imagens e detecção de objetos. No entanto, os dois campos calculam o mAP de maneira diferente. Aqui falamos apenas sobre o método de cálculo do mAP na detecção de objetos.
O mAP é frequentemente usado como um índice de avaliação para algoritmos de detecção de alvo. Especificamente, para cada modelo de detecção de imagem produzirá vários quadros de previsão (excedendo em muito o número de quadros reais), usamos IoU (Intersection Over Union) para saber se a caixa de previsão do a previsão da marca é precisa. Após a conclusão da marcação, a taxa de rechamada R sempre aumentará com o aumento do quadro de previsão. A taxa de precisão P é calculada em diferentes níveis de taxa de rechamada R para obter AP e, finalmente, todas as categorias são calculadas em média de acordo com suas proporções. , isso ou seja, o índice mAP é obtido.
2.2, Cálculo aproximado de AP
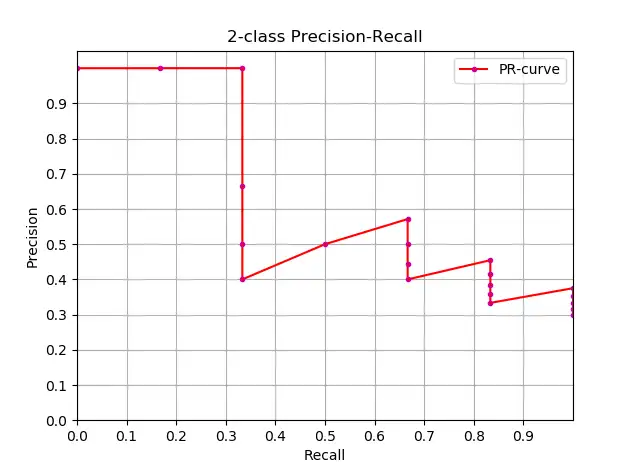
Conhecendo a definição de AP, o próximo passo é entender a realização do cálculo de AP. Teoricamente, AP pode ser calculado por integral. A fórmula é a seguinte:
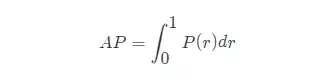
Mas geralmente, métodos aproximados ou de interpolação são usados para calcular AP .
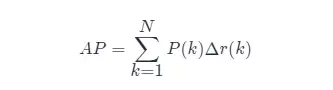
- Cálculo aproximado de AP (precisão média aproximada), este método de cálculo é de forma aproximada;
- Obviamente, pontos localizados em uma reta vertical não contribuem para o cálculo do AP ;
- Aqui N é a quantidade total de dados, k é o índice de cada ponto amostral, Δ r ( k )= r ( k )− r ( k −1).
O código para cálculo aproximado do AP e desenho da curva PR é o seguinte:
import numpy as np
import matplotlib.pyplot as plt
class_names = ["car", "pedestrians", "bicycle"]
def draw_PR_curve(predict_scores, eval_labels, name, cls_idx=1):
"""calculate AP and draw PR curve, there are 3 types
Parameters:
@all_scores: single test dataset predict scores array, (-1, 3)
@all_labels: single test dataset predict label array, (-1, 3)
@cls_idx: the serial number of the AP to be calculated, example: 0,1,2,3...
"""
# print('sklearn Macro-F1-Score:', f1_score(predict_scores, eval_labels, average='macro'))
global class_names
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(15, 10))
# Rank the predicted scores from large to small, extract their corresponding index(index number), and generate an array
idx = predict_scores[:, cls_idx].argsort()[::-1]
eval_labels_descend = eval_labels[idx]
pos_gt_num = np.sum(eval_labels == cls_idx) # number of all gt
predict_results = np.ones_like(eval_labels)
tp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend == cls_idx) # ndarray
fp_arr = np.logical_and(predict_results == cls_idx, eval_labels_descend != cls_idx)
tp_cum = np.cumsum(tp_arr).astype(float) # ndarray, Cumulative sum of array elements.
fp_cum = np.cumsum(fp_arr).astype(float)
precision_arr = tp_cum / (tp_cum + fp_cum) # ndarray
recall_arr = tp_cum / pos_gt_num
ap = 0.0
prev_recall = 0
for p, r in zip(precision_arr, recall_arr):
ap += p * (r - prev_recall)
# pdb.set_trace()
prev_recall = r
print("------%s, ap: %f-----" % (name, ap))
fig_label = '[%s, %s] ap=%f' % (name, class_names[cls_idx], ap)
ax.plot(recall_arr, precision_arr, label=fig_label)
ax.legend(loc="lower left")
ax.set_title("PR curve about class: %s" % (class_names[cls_idx]))
ax.set(xticks=np.arange(0., 1, 0.05), yticks=np.arange(0., 1, 0.05))
ax.set(xlabel="recall", ylabel="precision", xlim=[0, 1], ylim=[0, 1])
fig.savefig("./pr-curve-%s.png" % class_names[cls_idx])
plt.close(fig)2.3, cálculo de interpolação AP
O processo de evolução da fórmula de precisão média interpolada AP AP não será discutido aqui. Para detalhes, consulte este artigo. As fórmulas e diagramas aqui também são referidos neste artigo. O método de cálculo de interpolação de 11 pontos para calcular a fórmula AP AP é o seguinte:
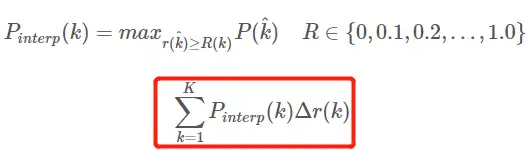
- Este é o AP no sentido usual de 11 pontos_Forma interpolada, selecione fixo 0,0.1,0.2,…,1.00,0.1,0.2,…,1.0 11 limites, isso é usado em PASCAL2007
- Aqui, porque há apenas 11 pontos envolvidos no cálculo, K = 11, chamado 11 points_Interpolated, e k é o índice de limite
- Pinterp ( k ) assume o valor máximo na amostra após o ponto de amostragem correspondente ao k-ésimo limite, exceto que o limite aqui é limitado ao intervalo de 0,0.1,0.2,…,1.00,0.1,0.2,…, 1.0 Dentro.
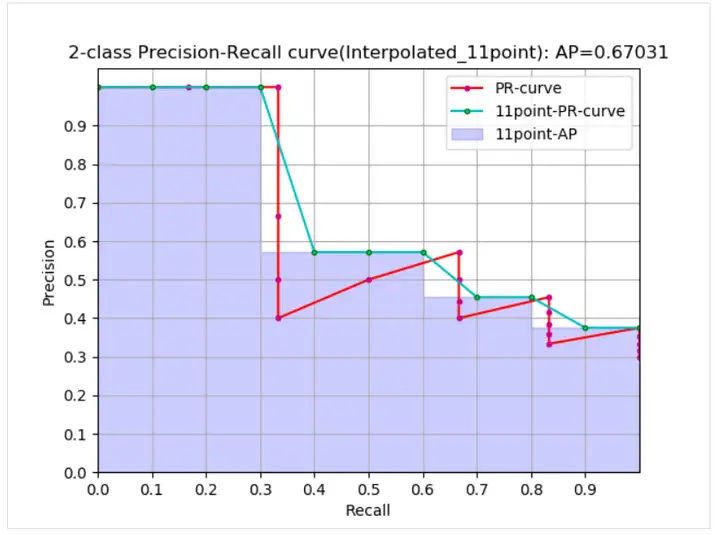
A partir da curva, o AP real < AP aproximado < AP interpolado, 11 pontos O AP interpolado pode ser grande ou pequeno e, quando a quantidade de dados é grande, estará próximo do AP interpolado. Ao contrário do AP interpolado, o AP é calculado em a fórmula anterior É a estimativa de área da curva PR A fórmula dada no papel PASCAL é mais simples e mais grosseira, calculando diretamente o valor médio da precisão em 11 patamares. A fórmula de 11 pontos para calcular AP fornecida no documento PASCAL é a seguinte.
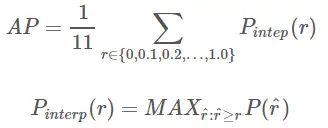
1. Calcule AP sob as condições dadas de recalque e precisão:
def voc_ap(rec, prec, use_07_metric=False):
"""
ap = voc_ap(rec, prec, [use_07_metric])
Compute VOC AP given precision and recall.
If use_07_metric is true, uses the
VOC 07 11 point method (default:False).
"""
if use_07_metric:
# 11 point metric
ap = 0.
for t in np.arange(0., 1.1, 0.1):
if np.sum(rec >= t) == 0:
p = 0
else:
p = np.max(prec[rec >= t])
ap = ap + p / 11.
else:
# correct AP calculation
# first append sentinel values at the end
mrec = np.concatenate(([0.], rec, [1.]))
mpre = np.concatenate(([0.], prec, [0.]))
# compute the precision envelope
for i in range(mpre.size - 1, 0, -1):
mpre[i - 1] = np.maximum(mpre[i - 1], mpre[i])
# to calculate area under PR curve, look for points
# where X axis (recall) changes value
i = np.where(mrec[1:] != mrec[:-1])[0]
# and sum (\Delta recall) * prec
ap = np.sum((mrec[i + 1] - mrec[i]) * mpre[i + 1])
return ap2. Calcule o AP dado o arquivo de resultado da detecção de alvo e o arquivo de rótulo do conjunto de teste xml:
def parse_rec(filename):
""" Parse a PASCAL VOC xml file
Return : list, element is dict.
"""
tree = ET.parse(filename)
objects = []
for obj in tree.findall('object'):
obj_struct = {}
obj_struct['name'] = obj.find('name').text
obj_struct['pose'] = obj.find('pose').text
obj_struct['truncated'] = int(obj.find('truncated').text)
obj_struct['difficult'] = int(obj.find('difficult').text)
bbox = obj.find('bndbox')
obj_struct['bbox'] = [int(bbox.find('xmin').text),
int(bbox.find('ymin').text),
int(bbox.find('xmax').text),
int(bbox.find('ymax').text)]
objects.append(obj_struct)
return objects
def voc_eval(detpath,
annopath,
imagesetfile,
classname,
cachedir,
ovthresh=0.5,
use_07_metric=False):
"""rec, prec, ap = voc_eval(detpath,
annopath,
imagesetfile,
classname,
[ovthresh],
[use_07_metric])
Top level function that does the PASCAL VOC evaluation.
detpath: Path to detections result file
detpath.format(classname) should produce the detection results file.
annopath: Path to annotations file
annopath.format(imagename) should be the xml annotations file.
imagesetfile: Text file containing the list of images, one image per line.
classname: Category name (duh)
cachedir: Directory for caching the annotations
[ovthresh]: Overlap threshold (default = 0.5)
[use_07_metric]: Whether to use VOC07's 11 point AP computation
(default False)
"""
# assumes detections are in detpath.format(classname)
# assumes annotations are in annopath.format(imagename)
# assumes imagesetfile is a text file with each line an image name
# cachedir caches the annotations in a pickle file
# first load gt
if not os.path.isdir(cachedir):
os.mkdir(cachedir)
cachefile = os.path.join(cachedir, '%s_annots.pkl' % imagesetfile)
# read list of images
with open(imagesetfile, 'r') as f:
lines = f.readlines()
imagenames = [x.strip() for x in lines]
if not os.path.isfile(cachefile):
# load annotations
recs = {}
for i, imagename in enumerate(imagenames):
recs[imagename] = parse_rec(annopath.format(imagename))
if i % 100 == 0:
print('Reading annotation for {:d}/{:d}'.format(
i + 1, len(imagenames)))
# save
print('Saving cached annotations to {:s}'.format(cachefile))
with open(cachefile, 'wb') as f:
pickle.dump(recs, f)
else:
# load
with open(cachefile, 'rb') as f:
try:
recs = pickle.load(f)
except:
recs = pickle.load(f, encoding='bytes')
# extract gt objects for this class
class_recs = {}
npos = 0
for imagename in imagenames:
R = [obj for obj in recs[imagename] if obj['name'] == classname]
bbox = np.array([x['bbox'] for x in R])
difficult = np.array([x['difficult'] for x in R]).astype(np.bool)
det = [False] * len(R)
npos = npos + sum(~difficult)
class_recs[imagename] = {'bbox': bbox,
'difficult': difficult,
'det': det}
# read dets
detfile = detpath.format(classname)
with open(detfile, 'r') as f:
lines = f.readlines()
splitlines = [x.strip().split(' ') for x in lines]
image_ids = [x[0] for x in splitlines]
confidence = np.array([float(x[1]) for x in splitlines])
BB = np.array([[float(z) for z in x[2:]] for x in splitlines])
nd = len(image_ids)
tp = np.zeros(nd)
fp = np.zeros(nd)
if BB.shape[0] > 0:
# sort by confidence
sorted_ind = np.argsort(-confidence)
sorted_scores = np.sort(-confidence)
BB = BB[sorted_ind, :]
image_ids = [image_ids[x] for x in sorted_ind]
# go down dets and mark TPs and FPs
for d in range(nd):
R = class_recs[image_ids[d]]
bb = BB[d, :].astype(float)
ovmax = -np.inf
BBGT = R['bbox'].astype(float)
if BBGT.size > 0:
# compute overlaps
# intersection
ixmin = np.maximum(BBGT[:, 0], bb[0])
iymin = np.maximum(BBGT[:, 1], bb[1])
ixmax = np.minimum(BBGT[:, 2], bb[2])
iymax = np.minimum(BBGT[:, 3], bb[3])
iw = np.maximum(ixmax - ixmin + 1., 0.)
ih = np.maximum(iymax - iymin + 1., 0.)
inters = iw * ih
# union
uni = ((bb[2] - bb[0] + 1.) * (bb[3] - bb[1] + 1.) +
(BBGT[:, 2] - BBGT[:, 0] + 1.) *
(BBGT[:, 3] - BBGT[:, 1] + 1.) - inters)
overlaps = inters / uni
ovmax = np.max(overlaps)
jmax = np.argmax(overlaps)
if ovmax > ovthresh:
if not R['difficult'][jmax]:
if not R['det'][jmax]:
tp[d] = 1.
R['det'][jmax] = 1
else:
fp[d] = 1.
else:
fp[d] = 1.
# compute precision recall
fp = np.cumsum(fp)
tp = np.cumsum(tp)
rec = tp / float(npos)
# avoid divide by zero in case the first detection matches a difficult
# ground truth
prec = tp / np.maximum(tp + fp, np.finfo(np.float64).eps)
ap = voc_ap(rec, prec, use_07_metric)
return rec, prec, ap2.4, método de cálculo do mAP
Como o cálculo do valor mAP é a média dos valores AP de todas as categorias no conjunto de dados , então queremos calcular o mAP , devemos primeiro saber como encontrar o valor AP de uma determinada categoria . Os métodos de cálculo de PA de uma determinada categoria de diferentes conjuntos de dados são semelhantes, principalmente divididos em três tipos:
(1) No VOC2007, você só precisa selecionar o valor máximo de Precisão quando Recall>=0,0.1,0.2,...,1 Recall >=0,0.1,0.2,...,1, um total de 11 pontos, e então AP AP é a média dessas 11 Precisões, e mAP mAP é a média de todos os valores de AP AP de todas as categorias. O código para calcular AP AP no conjunto de dados VOC (usando o método de cálculo de interpolação, o código vem do warehouse py-faster-rcnn )
(2) No VOC2010 e posterior, para cada valor de Recall diferente (incluindo 0 e 1), é necessário selecionar o valor máximo de Precisão quando for maior ou igual a esses valores de Recall e, em seguida, calcular a área sob o PR curva como o valor AP, mAP mAP é tudo A média dos valores AP da categoria.
(3) Para o conjunto de dados COCO, defina vários limites de IOU (0,5-0,95, 0,05 é o tamanho do passo), e há uma certa categoria de valor de AP sob cada limite de IOU e, em seguida, calcule a média de AP sob diferentes limites de IOU, ou seja, o valor AP final desejado de uma categoria.
3. Resumo das métricas de detecção de alvo
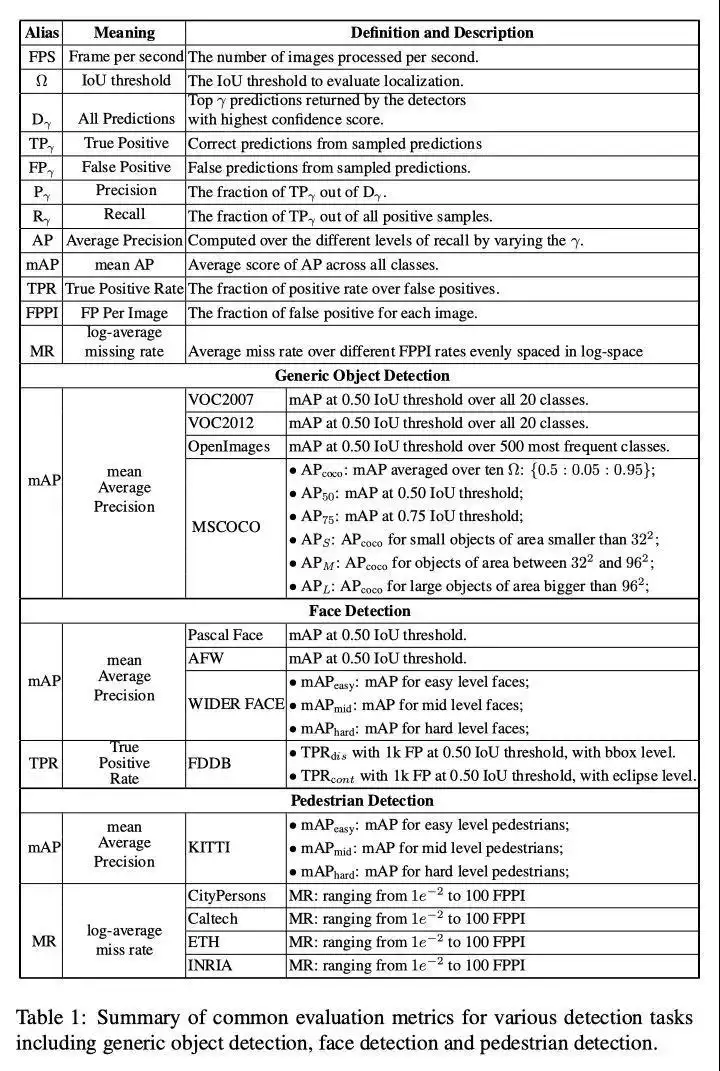
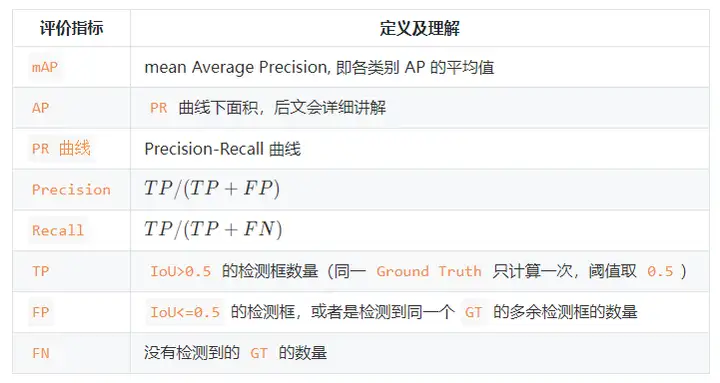
Em quarto lugar, materiais de referência
- Avaliação de detecção de alvo padrão-AP mAP
- Métricas de avaliação de desempenho para detecção de objetos
- Soft-NMS
- Avanços recentes em aprendizado profundo para detecção de objetos
- Uma implementação simples e rápida de R-CNN mais rápida
- Indicadores de avaliação do modelo de classificação - taxa de precisão, taxa de precisão, taxa de rechamada, F1, curva ROC, curva AUC
- Este artigo fornece uma compreensão completa da exatidão, precisão, recuperação, taxa verdadeira, taxa de falsos positivos, ROC/AUC
Clique para seguir e aprender sobre as novas tecnologias da Huawei Cloud pela primeira vez~