Aula 08: Como dividir a aplicação exemplo em microsserviços
Após apresentar os conceitos básicos de Domain-Driven Design na Lição 07, esta lição apresentará como aplicar as ideias relacionadas ao Domain-Driven Design na divisão de microsserviços.
Divisão de microsserviços
No projeto e implementação de aplicativos de arquitetura de microsserviços, se você deseja descobrir a tarefa mais importante, deve ser a divisão de não microsserviços . O núcleo da arquitetura de microsserviços é um sistema distribuído composto por vários microsserviços cooperantes. Somente após a conclusão da divisão dos microsserviços, as responsabilidades de cada microsserviço podem ser esclarecidas e o modo de interação entre os microsserviços pode ser determinado e, em seguida, prosseguir com o design da API de cada microsserviço é a implementação final, teste e implantação de cada microsserviço.
Como pode ser visto no processo acima, a divisão de microsserviços é o primeiro elo em toda a cadeia de design e implementação de aplicativos. Mudanças em cada elo da cadeia impactarão nos elos subsequentes, sendo o primeiro elo da divisão de microsserviços, se houver alteração, ela afetará todos os elos subsequentes. A última coisa que você deseja é perceber que algumas funcionalidades devem ser migradas para outros microsserviços durante a implementação de microsserviços. Se isso acontecer, tanto a API quanto a implementação do microsserviço associado precisarão ser modificadas.
Obviamente, no desenvolvimento real, não é realista evitar completamente as mudanças na divisão de microsserviços. No estágio de divisão de microsserviços, se você gastar bastante energia em análise, os benefícios obtidos serão enormes.
Microsserviços e Contextos Delimitados
Na aula 07, introduzimos o conceito de contexto definido no design orientado a domínio. Se a ideia de design orientado a domínio for aplicada à arquitetura de microsserviços, podemos fazer uma correspondência um-para-um entre microsserviços e contexto definido . Cada contexto limitado corresponde diretamente a um microsserviço e, em seguida, usa o padrão de mapeamento de contexto para definir a forma de interação entre os microsserviços.
Dessa forma, o problema de divisão de microsserviços é transformado no problema de divisão do contexto definido no design dirigido por domínio. Se você já tem um conhecimento sólido de Domain Driven Design, isso será uma vantagem; caso contrário, o conteúdo da Lição 07 pode ajudá-lo a começar rapidamente.
Vamos usar o aplicativo de exemplo nesta coluna como exemplo para uma explicação específica.
Particionamento de microsserviço do aplicativo de amostra
A Lição 06 apresenta os cenários de usuário do aplicativo de exemplo, com base nesses cenários, o domínio do aplicativo pode ser determinado. No desenvolvimento de aplicativos reais, geralmente é necessária a participação de especialistas de domínio e pessoal de negócios.Através da comunicação com o pessoal de negócios, podemos ter uma compreensão mais clara do domínio. Quanto ao aplicativo de exemplo, uma vez que o domínio do aplicativo está relativamente próximo da vida e, para simplificar a introdução relacionada, conduziremos a análise de domínio por conta própria. No entanto, isso tem uma desvantagem, ou seja, a análise de domínio feita pelos desenvolvedores não reflete necessariamente o processo real do negócio. No entanto, para o aplicativo de amostra, isso é bom o suficiente.
O design orientado por domínio considera o domínio como o núcleo e o domínio é dividido em espaço de problema e espaço de solução .
O espaço do problema nos ajuda a pensar no nível de negócios e é a parte do domínio da qual depende o domínio principal, que inclui o domínio principal e outros subdomínios conforme necessário. O domínio core tem que ser criado do zero, pois é o core do sistema de software que iremos desenvolver; outros subdomínios podem já existir, ou também precisam ser criados do zero. A questão central do espaço do problema é como identificar e dividir subcampos.
O espaço de solução então consiste em um ou mais contextos limitados e os modelos dentro dos contextos. Idealmente, há uma correspondência um-para-um entre contextos e subdomínios definidos. Desta forma, a divisão pode ser iniciada a partir do nível de negócio, e então o mesmo método de divisão pode ser adotado no nível de implementação, de modo que a perfeita integração do espaço do problema e do espaço da solução possa ser realizada. Na prática real, é improvável que haja uma correspondência um-para-um entre contextos e subcampos definidos. Na implementação de um sistema de software, geralmente ele precisa ser integrado a sistemas legados existentes e sistemas externos, e esses sistemas têm seus próprios contextos definidos. Na prática, é mais realista que vários contextos limitados pertençam ao mesmo subcampo ou um contexto limitado corresponda a vários subcampos.
A ideia do Domain-Driven Design é começar pelo domínio, primeiro dividir o subdomínio e depois abstrair o contexto definido e o modelo no contexto do subdomínio. Cada contexto definido corresponde a um microsserviço.
áreas principais
O domínio principal é onde existe o valor do sistema de software e também é o ponto de partida do design. Antes de iniciar o sistema de software, você deve ter uma compreensão clara do valor central do sistema de software. Caso contrário, primeiro você precisa considerar os pontos de venda do sistema de software. Diferentes sistemas de software têm áreas principais diferentes. Como um aplicativo de táxi, sua área principal é como fazer com que os passageiros viajem com rapidez, conforto e segurança, que também é a área principal de aplicativos de táxi como Didi Taxi e Uber. Para o aplicativo happy travel como exemplo, essa área central é um pouco grande demais. O aplicativo happy travel simplifica a área central e se concentra apenas em como fazer os passageiros viajarem rapidamente.
Precisamos dar ao domínio principal um nome apropriado. A área central da viagem feliz é como combinar rapidamente entre os passageiros que precisam chamar um carro e os motoristas que fornecem serviços de viagem. Depois que o usuário cria o roteiro, o sistema distribui para os motoristas disponíveis, depois que o motorista recebe o roteiro, o sistema seleciona um motorista para distribuir o roteiro. A área central concentra-se no despacho de itinerários, daí o nome distribuição de itinerários .
conceitos na área
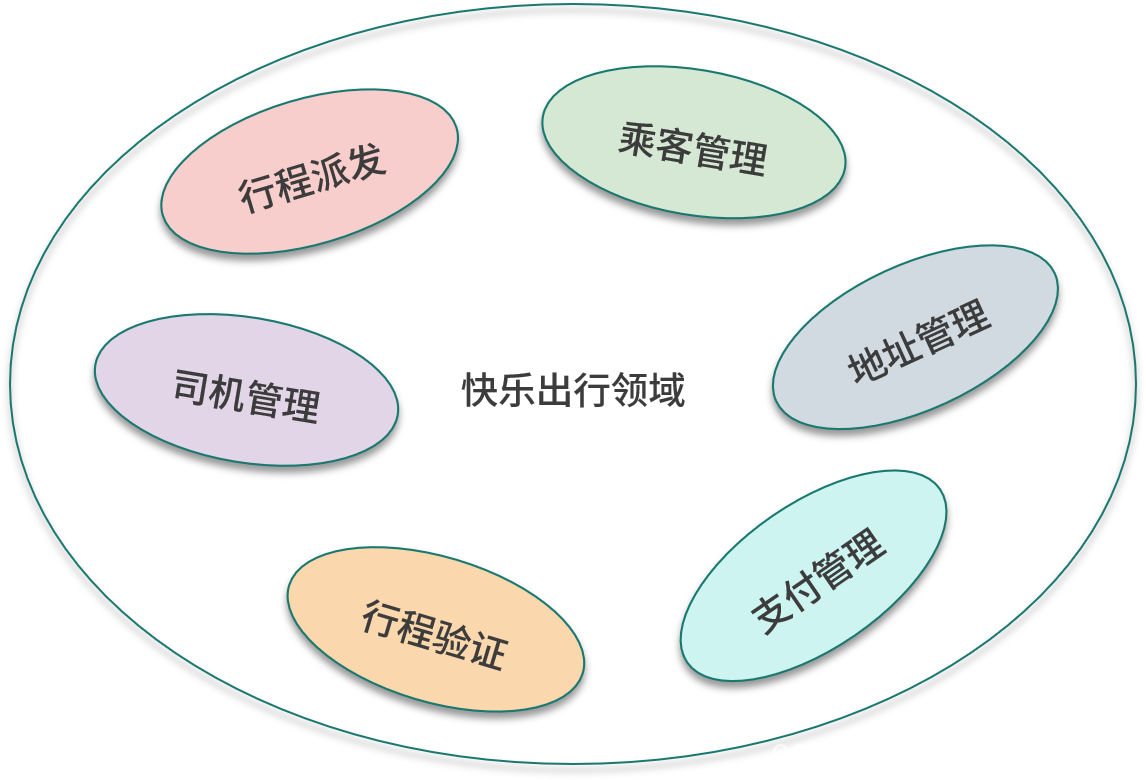
Em seguida, enumeramos os conceitos no domínio. Este é um processo de brainstorming que pode ser realizado em um quadro branco para listar todos os conceitos relacionados que vêm à mente, um por um. Conceitos são substantivos. O conceito mais antigo é itinerário, o que significa uma jornada de um determinado ponto de partida a um ponto de chegada. A partir do itinerário, pode-se derivar o conceito de passageiros e motoristas. O passageiro é o iniciador do itinerário e o motorista é o finalizador do itinerário. Cada itinerário tem um ponto de partida e um ponto de chegada, e o conceito correspondente é o endereço. Os motoristas usam veículos pessoais para completar as viagens, então os veículos são outro conceito.
Encontramos outros subcampos baseados em conceitos, e o conceito de viagem pertence ao campo central. Motoristas e passageiros devem pertencer a vários subdomínios independentes e, em seguida, ser gerenciados separadamente, o que resulta em dois subdomínios de gerenciamento de passageiros e gerenciamento de motoristas . O conceito de endereço pertence ao subcampo de gerenciamento de endereço ; o conceito de veículo pertence ao subcampo de gerenciamento de motorista.
Depois de dividir os subdomínios pelos conceitos do domínio, o próximo passo é continuar descobrindo novos subdomínios a partir das operações no domínio. No cenário do usuário, é mencionado que o itinerário precisa ser verificado, e esta operação tem seu subcampo correspondente verificação de itinerário . Após a conclusão da viagem, o passageiro precisa efetuar um pagamento, sendo que esta operação possui o subcampo gerenciamento de pagamentos correspondente .
A figura a seguir mostra os subdomínios no aplicativo de amostra.

contexto limitado
Depois de identificar o domínio principal e outros subdomínios, o próximo passo pode ser passar do espaço do problema para o espaço da solução. Primeiramente, os subdomínios são mapeados para o contexto delimitado, e o contexto delimitado tem o mesmo nome do subdomínio; então, o contexto delimitado é modelado, e a principal tarefa da modelagem é concretizar os conceitos relacionados.
Distribuição de itinerário
A entidade importante no modelo de despacho de itinerário é o itinerário, que também é a raiz do agregado no qual o itinerário reside. Uma viagem tem seus locais de início e fim, expressos como endereços de objeto de valor. O itinerário é iniciado pelo passageiro, então a entidade de itinerário precisa ter uma referência ao passageiro. Quando o sistema seleciona um motorista para aceitar o itinerário, a entidade de itinerário tem uma referência ao motorista. Durante todo o ciclo de vida, a viagem pode estar em diferentes estados, e existe um atributo e seu tipo de enumeração correspondente para descrever o estado da viagem.
A figura abaixo mostra as entidades e objetos de valor no modelo.
 

gestão de passageiros
A entidade importante no modelo de Gerenciamento de Passageiros é o Passageiro, que também é a raiz do Agregado no qual o Passageiro reside. Os atributos da entidade do passageiro incluem nome, endereço de e-mail, número de contato etc. A entidade do passageiro possui uma lista de endereços salvos associados a ela e o endereço é uma entidade.
A figura abaixo mostra as entidades no modelo.
 

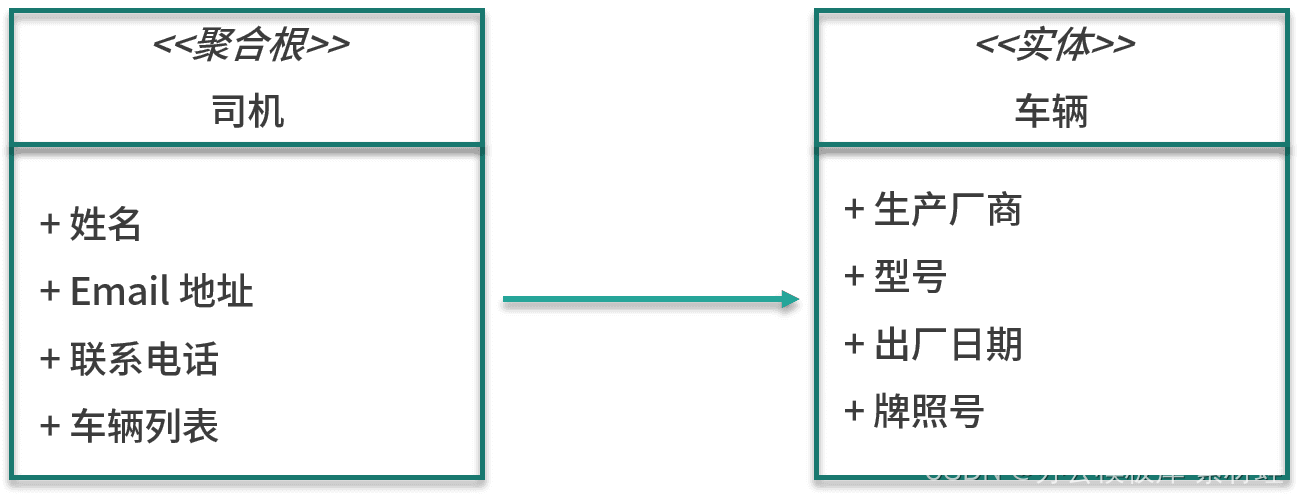
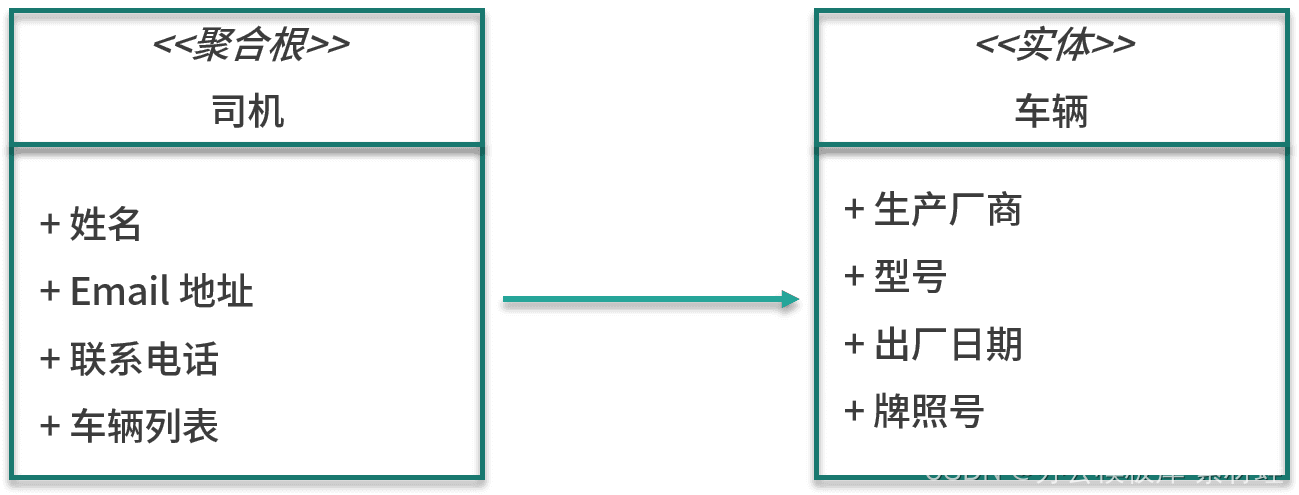
gerenciamento de motorista
A entidade importante no modelo de gerenciamento do driver é o driver, que também é a raiz do agregado no qual o driver reside. Os atributos da entidade do motorista incluem nome, endereço de e-mail, número de contato etc. Além da entidade do motorista, a agregação também inclui a entidade do veículo. Os atributos da entidade do veículo incluem fabricante, modelo, data de fabricação e licença número da placa.
A figura abaixo mostra as entidades no modelo.

gerenciamento de endereço
A entidade importante no modelo de gerenciamento de endereço é o endereço, que é hierárquico, variando de províncias, municípios e regiões autônomas a vilas e ruas. Além do endereço hierárquico, existe outra informação importante, ou seja, as coordenadas de localização geográfica, incluindo longitude e latitude.
verificação de itinerário
O modelo de verificação de itinerário não contém entidades específicas, mas serviços e implementações de algoritmos relacionados que verificam o itinerário.
gestão de pagamentos
Uma entidade importante no modelo de gerenciamento de pagamentos é o registro de pagamento, que contém informações como referências a itinerários e status de pagamento.
Interação entre contextos limitados
No modelo de nosso contexto definido, a entidade de itinerário do modelo de despacho de itinerário precisa se referir à entidade raiz do agregado "passageiro" no modelo de gerenciamento de passageiros e à entidade raiz do agregado "motorista" no modelo de gerenciamento de motorista . Na Lição 07, mencionamos que objetos externos só podem referenciar a entidade raiz do agregado, e ao referenciar, deve-se referenciar o identificador da entidade raiz do agregado, e não a entidade em si. Os identificadores da entidade Passenger e da entidade Driver são ambos tipos string, então a entidade Trip contém duas propriedades do tipo String para se referir à entidade Passenger e à entidade Driver respectivamente.
Quando o mesmo conceito aparece em modelos em diferentes contextos delimitados, o mapeamento é necessário, e podemos usar o modo de mapeamento de contexto mencionado na Lição 07 para mapeamento.
Nos contextos de gerenciamento de endereço e de envio de itinerário, existe a noção de endereço. A entidade de endereço no gerenciamento de endereço é uma estrutura complexa, incluindo nomes geográficos de diferentes níveis, que é para realizar a seleção de endereço de vários níveis e a consulta de endereço. No contexto de um despacho de itinerário, um endereço consiste simplesmente em um nome completo e coordenadas de localização geográfica. Para mapear entre os dois contextos, podemos adicionar uma camada anticorrosiva ao contexto de despacho de viagem para conversão de modelo.
Migração de aplicativos monolíticos existentes
O aplicativo de exemplo nesta coluna é um novo aplicativo criado do zero, portanto, não há nenhuma implementação existente para se referir ao dividir os microsserviços. Ao migrar um aplicativo monolítico existente para uma arquitetura de microsserviços, a divisão dos microsserviços será mais rastreável. A partir da implementação existente do aplicativo monolítico, você pode aprender sobre a interação real de cada parte do sistema, o que o ajudará a entender melhor é bom dividi-los de acordo com suas responsabilidades. Os microsserviços assim divididos estão mais próximos da situação real de operação.
Sam Newman, da ThoughtWorks, compartilhou sua experiência na divisão de microsserviços do produto SnapCI em seu livro "Building Microservices" Devido à experiência relevante do projeto de código aberto GoCD, a equipe SnapCI rapidamente dividiu os microsserviços do SnapCI. No entanto, existem algumas diferenças entre os cenários de usuário do GoCD e do SnapCI. Após um período de tempo, a equipe do SnapCI descobriu que a atual divisão de microsserviços trouxe muitos problemas. Eles geralmente precisam fazer algumas alterações em vários microsserviços, resultando em alta sobrecarga .
O que a equipe do SnapCI fez foi mesclar esses microsserviços em um único monólito, dando a eles mais tempo para entender como o sistema estava realmente funcionando. Um ano depois, a equipe do SnapCI redividiu esse sistema monolítico em microsserviços. Após essa divisão, os limites dos microsserviços se tornaram mais estáveis. Este exemplo do SnapCI ilustra que o conhecimento do domínio é crítico ao particionar microsserviços.
Resumir
O particionamento de microsserviços é crucial no desenvolvimento de aplicativos da arquitetura de microsserviços. Aplicando a ideia de domain-driven design, a divisão de microsserviços é transformada na divisão de subdomínios em domain-driven design, e então os conceitos no domínio são modelados através do contexto definido. As transformações do modelo podem ser executadas por meio de padrões de mapeamento entre contextos definidos.
Aula 09: Ambiente e Framework de Desenvolvimento de Implantação Rápida
Esta aula apresentará o conteúdo relacionado a "framework e ambiente de desenvolvimento de implantação rápida".
Nas aulas anteriores, introduzimos o conhecimento básico relacionado à arquitetura de microsserviços nativos da nuvem, e as próximas horas de aula entrarão no desenvolvimento real de microsserviços. Esta aula é a primeira aula relacionada ao desenvolvimento de microsserviços. Ela se concentrará em como preparar o ambiente de desenvolvimento local e apresentará o framework, bibliotecas de terceiros e ferramentas usadas no aplicativo de amostra.
Necessário para o desenvolvimento
Os pré-requisitos de desenvolvimento referem-se àqueles necessários para o ambiente de desenvolvimento.
Java
Os microsserviços do aplicativo de amostra são desenvolvidos com base no Java 8. Embora o Java 14 tenha sido lançado, o aplicativo de amostra ainda usa a versão mais antiga do Java 8, porque essa versão ainda é amplamente usada e os novos recursos incluídos após o Java 8 não são úteis para o aplicativo de amostra. Se o JDK 8 não estiver instalado, é recomendável acessar o site AdoptOpenJDK para baixar o instalador do OpenJDK 8. No MacOS e Linux, você pode usar o SDKMAN! para instalar o JDK 8 e gerenciar diferentes versões do JDK.
A seguir está a saída de java -version:
openjdk versão "1.8.0_242" OpenJDK Runtime Environment (AdoptOpenJDK)(build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (AdoptOpenJDK)(build 25.242-b08, modo misto)
Especialista
A ferramenta de compilação usada pelo aplicativo de amostra é o Apache Maven. Você pode instalar manualmente o Maven 3.6 ou usar o Maven integrado no IDE para criar o projeto. HomeBrew é recomendado para MacOS e Linux , e Chocolatey é recomendado para Windows .
Ambiente de desenvolvimento integrado
Um bom IDE pode melhorar muito a produtividade do desenvolvedor. Em termos de IDE, existem basicamente duas opções: IntelliJ IDEA e Eclipse; em termos de escolha de IDE, não há muita diferença entre os dois. Eu uso o IntelliJ IDEA Community Edition 2020.
Docker
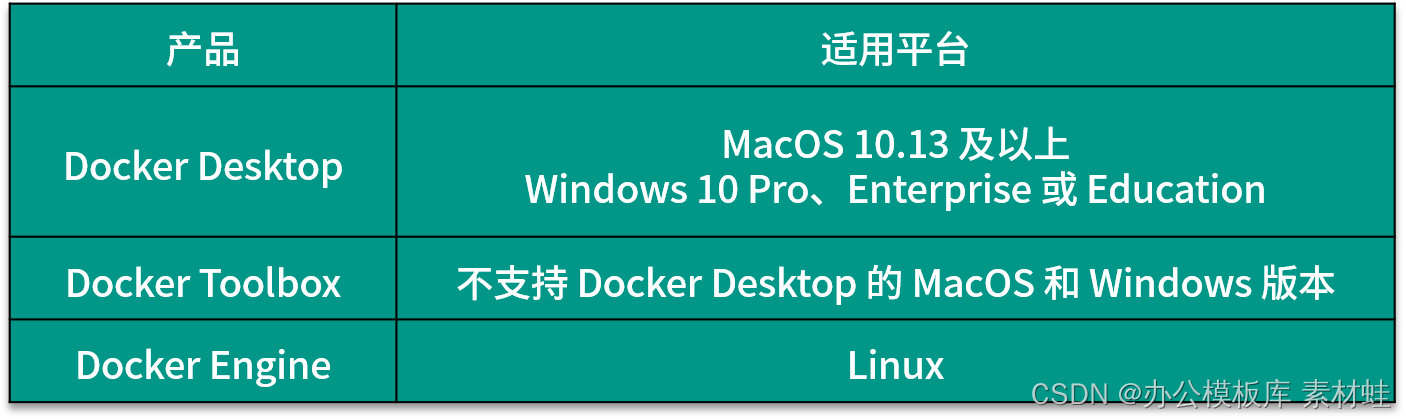
O ambiente de desenvolvimento local precisa usar o Docker para executar os serviços de suporte exigidos pelo aplicativo, incluindo banco de dados e middleware de mensagens. Através do Docker, resolve-se o problema de instalação de diferentes serviços de software, tornando muito simples a configuração do ambiente de desenvolvimento. Por outro lado, o ambiente de produção e execução do aplicativo é o Kubernetes, que também é implantado por conteinerização, o que garante a consistência entre o ambiente de desenvolvimento e o ambiente de produção. Para simplificar o processo de desenvolvimento local, o Docker Compose é usado no ambiente local para orquestração de contêineres.
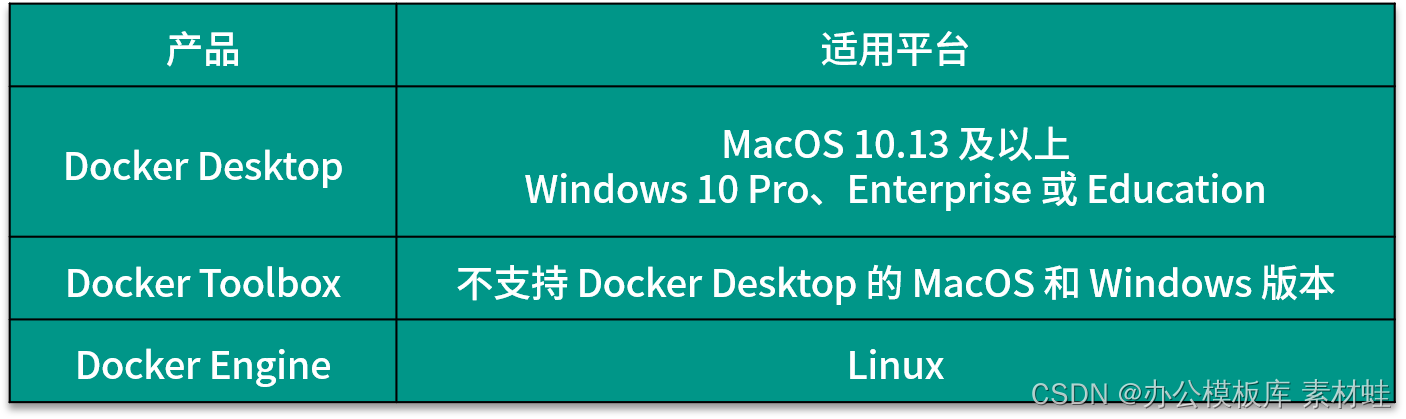
Dependendo do sistema operacional do ambiente de desenvolvimento, a forma de instalação do Docker é diferente. Existem 3 produtos Docker diferentes que podem ser usados para instalar o Docker, ou seja, Docker Desktop, Docker Toolbox e Docker Engine. A tabela a seguir mostra as plataformas aplicáveis desses 3 produtos. Para MacOS e Windows, se a versão for compatível, o Docker Desktop deve ser instalado primeiro e, em seguida, o Docker Toolbox deve ser considerado.

O produto Docker Desktop consiste em muitos componentes, incluindo Docker Engine, Docker Command Line Client, Docker Compose, Notary, Kubernetes e Credential Helper. A vantagem do Docker Desktop é que ele pode usar diretamente o suporte de virtualização fornecido pelo sistema operacional, o que pode proporcionar uma melhor integração.Além disso, o Docker Desktop também fornece uma interface gráfica de gerenciamento. Na maioria das vezes, operamos o Docker por meio da linha de comando docker. Se o comando docker -v puder exibir as informações de versão corretas, isso significa que o Docker Desktop foi instalado com sucesso.
A figura abaixo mostra as informações da versão do Docker Desktop.
 

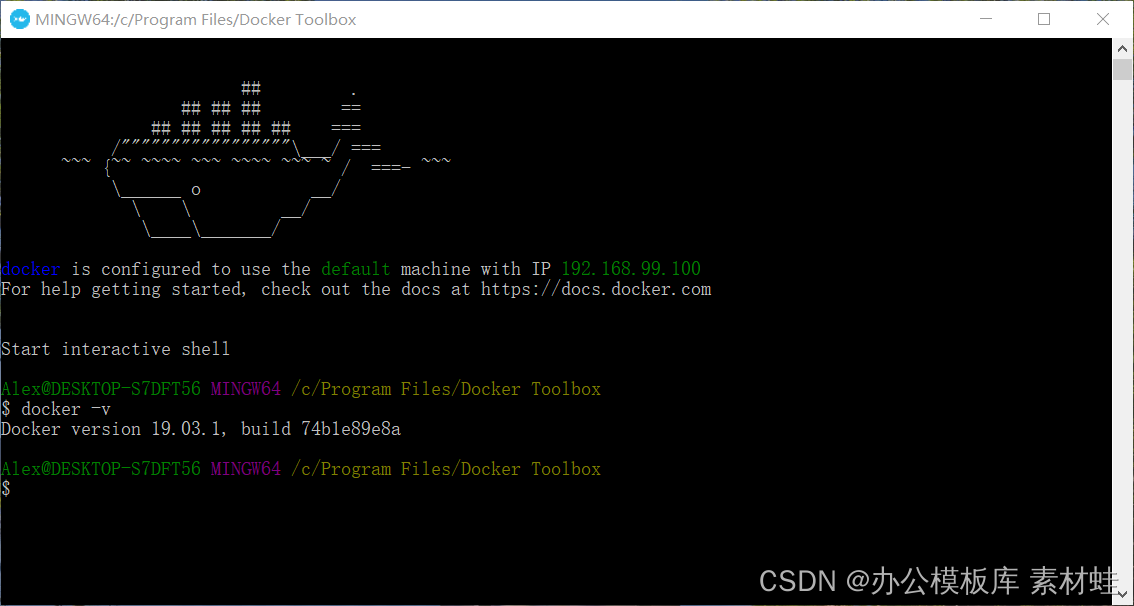
O Docker Toolbox é o antecessor do Docker Desktop. O Docker Toolbox usa o VirtualBox para virtualização, que possui requisitos de sistema baixos. Docker Toolbox consiste em Docker Machine, Docker Command Line Client, Docker Compose, Kitematic e Docker Quickstart Terminal. Após a conclusão da instalação, inicie um terminal por meio do Docker Quickstart para executar comandos docker.
A figura abaixo é o efeito de execução do terminal Docker Quickstart.

No Linux, só podemos instalar o Docker Engine diretamente e também precisamos instalar manualmente o Docker Compose.
Há uma diferença significativa no uso do Docker Desktop e do Docker Toolbox. O contêiner em execução no Docker Desktop pode usar a rede no host do ambiente de desenvolvimento atual e a porta exposta pelo contêiner pode ser acessada usando localhost; o contêiner em execução no Docker Toolbox na verdade é executado em uma máquina virtual do VirtualBox, que precisa ser acessada através do endereço IP da máquina virtual para acessar. Podemos obter o endereço IP por meio do comando docker-machine ip no terminal iniciado pelo Docker Quickstart, como 192.168.99.100. A porta exposta pelo container precisa ser acessada usando este endereço IP, que não é fixo. A prática recomendada é adicionar um nome de host chamado dockervm no arquivo hosts e apontar para esse endereço IP. Sempre use o nome de host dockervm ao acessar serviços em contêineres. Quando o endereço IP da máquina virtual muda, apenas o arquivo hosts precisa ser atualizado.
Kubernetes
Ao implantar aplicativos, precisamos de um cluster Kubernetes disponível. Geralmente, existem três maneiras de criar um cluster Kubernetes.
A primeira maneira é usar a plataforma de nuvem para criar arquivos . Muitas plataformas de nuvem fornecem suporte para Kubernetes. A plataforma de nuvem é responsável pela criação e gerenciamento de clusters Kubernetes. Você só precisa usar a interface da web ou ferramentas de linha de comando para criar clusters Kubernetes rapidamente. A vantagem de usar a plataforma em nuvem é que ela economiza tempo e esforço, mas é cara.
A segunda maneira é instalar um cluster Kubernetes em uma máquina virtual ou bare metal físico . A máquina virtual pode ser fornecida pela plataforma de nuvem, ou pode ser criada e gerenciada por ela mesma, e também é possível usar o cluster físico bare-metal mantido por ela. Existem muitas ferramentas de instalação do Kubernetes de código aberto disponíveis, como RKE , Kubespray , Kubicorn , etc. A vantagem desse método é que a sobrecarga é relativamente pequena, mas a desvantagem é que requer pré-instalação e pós-manutenção.
A terceira maneira é instalar o Kubernetes no ambiente de desenvolvimento local . O Docker Desktop já vem com o Kubernetes, você só precisa habilitá-lo. Além disso, você também pode instalar o Minikube . A vantagem dessa abordagem é que ela tem a menor sobrecarga e é altamente controlável, mas a desvantagem é que consumirá muitos recursos no ambiente de desenvolvimento local.
Entre os três métodos acima, o método de plataforma em nuvem é adequado para a implantação do ambiente de produção. Para o ambiente de teste e preparação de entrega (preparação), você pode escolher uma plataforma de nuvem ou pode optar por construir o ambiente por conta própria sob a perspectiva de custo. O Kubernetes no ambiente de desenvolvimento local também é necessário em muitos casos.
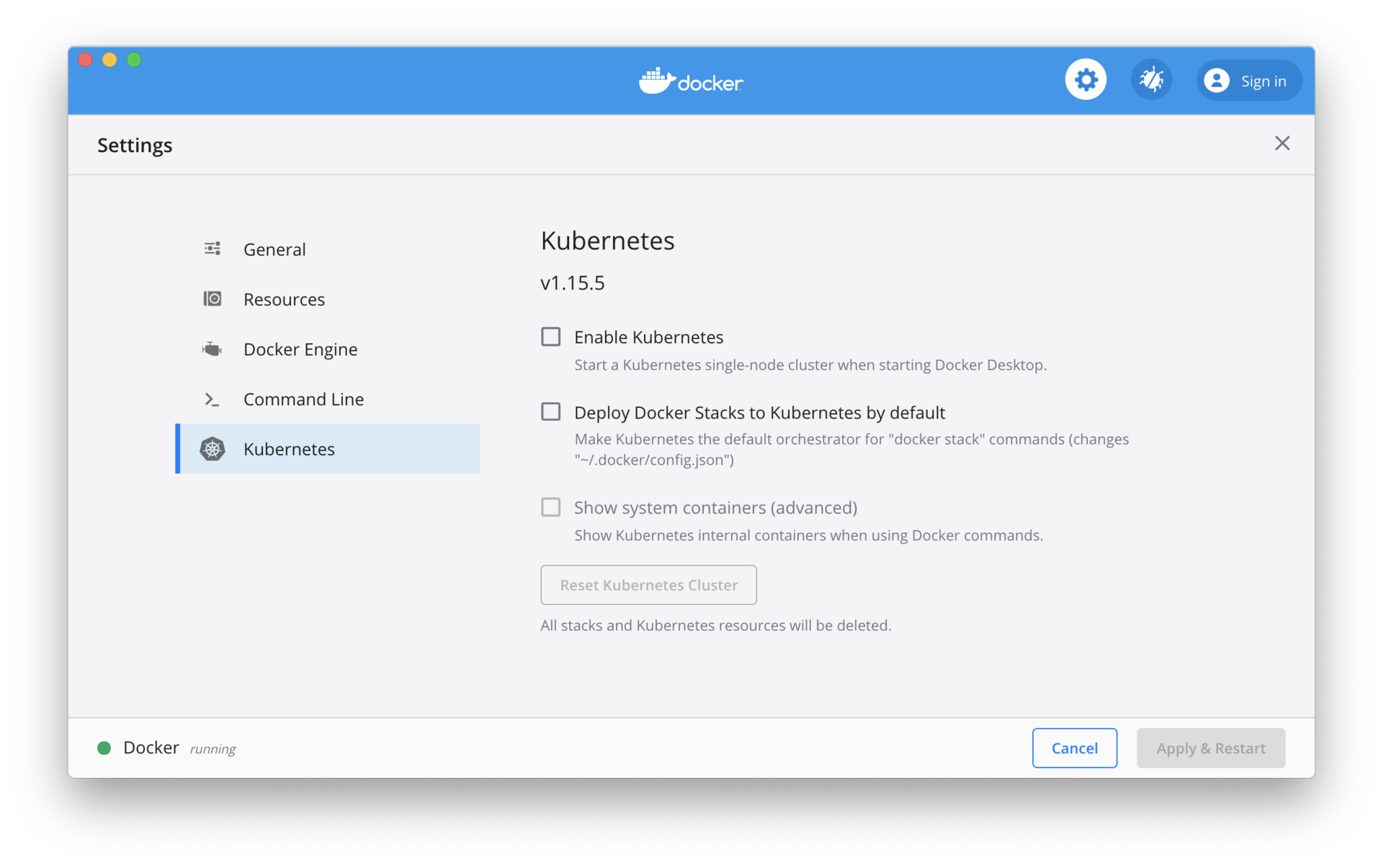
Em um ambiente de desenvolvimento local, o Kubernetes para Docker Desktop precisa ser ativado manualmente. Para Minikube, você pode consultar a documentação oficial para instalá-lo. A diferença entre os dois é que a versão do Kubernetes que vem com o Docker Desktop geralmente está algumas versões menores atrasadas. Conforme mostrado na figura abaixo, marque a opção "Enable Kubernetes" para iniciar o cluster Kubernetes. A versão do Kubernetes que vem com o Docker Desktop é 1.15.5, e a versão mais recente do Kubernetes é 1.18.

Frameworks e bibliotecas de terceiros
O aplicativo de exemplo usa algumas estruturas e bibliotecas de terceiros, que são brevemente apresentadas a seguir.
Spring Framework e Spring Boot
É difícil desenvolver aplicativos Java sem o framework Spring. O Spring Boot também é uma das escolhas populares para desenvolver microsserviços em Java no momento. A introdução do Spring e do Spring Boot está além do escopo desta coluna. Os microsserviços do aplicativo de amostra usarão alguns subprojetos na estrutura Spring, incluindo Spring Data JPA, Spring Data Redis e Spring Security.
Eventuate Tram
Eventuate Tram é uma estrutura de mensagem transacional usada pelo aplicativo de amostra. O modo de mensagem transacional desempenha um papel importante na manutenção da consistência dos dados. Eventuate Tram fornece suporte para padrões de mensagens transacionais e também inclui suporte para mensagens assíncronas. Eventuate Tram integra-se com PostgreSQL e Kafka.
Servidor e estrutura Axon
O aplicativo de amostra também usa o fornecimento de eventos e a tecnologia CQRS, e a implementação do fornecimento de eventos usa o servidor Axon e a estrutura Axon. O servidor Axon fornece armazenamento de eventos; A estrutura Axon se conecta ao servidor Axon e fornece suporte CQRS.
Serviços e ferramentas de suporte
Os serviços de suporte do aplicativo de amostra são necessários em tempo de execução e as ferramentas relacionadas podem ser usadas no desenvolvimento.
Apache Kafka e ZooKeeper
O aplicativo de exemplo usa mensagens assíncronas entre diferentes microsserviços para garantir a consistência final dos dados, portanto, o middleware de mensagem é necessário. O Apache Kafka é o middleware de mensagem usado no aplicativo de amostra e o ZooKeeper é necessário para executar o Kafka.
PostgreSQLName
Alguns dos microsserviços do aplicativo de exemplo usam um banco de dados relacional para armazenar dados. Entre muitos bancos de dados relacionais, o PostgreSQL é escolhido como banco de dados para alguns microsserviços no aplicativo de exemplo.
ferramenta de gerenciamento de banco de dados
No desenvolvimento, podemos precisar visualizar dados em um banco de dados relacional. Existem muitos clientes PostgreSQL disponíveis, incluindo DBeaver , pgAdmin 4 , OmniDB, etc. Você também pode usar plug-ins IDE, como o plug-in Database Navigator no IntelliJ IDEA.
Carteiro
Em desenvolvimento e teste, muitas vezes precisamos enviar solicitações HTTP para testar serviços REST.Existem muitas ferramentas relacionadas ao teste de serviços REST, como Postman , Insomnia e Advanced REST Client . Eu recomendo usar o Postman porque ele pode importar diretamente arquivos de especificação OpenAPI e gerar modelos de solicitação REST correspondentes. Como nossos microsserviços adotam uma abordagem de design API-first, cada API de microsserviço tem um arquivo de especificação OpenAPI correspondente. Durante o desenvolvimento, precisamos apenas importar o arquivo OpenAPI para o Postman, e então podemos começar a testar, economizando o trabalho de criar requisições manualmente.
Resumir
Antes de explicar o combate real, primeiro precisamos preparar o ambiente de desenvolvimento local. Esta classe primeiro apresenta como instalar e configurar Java, Maven, ambiente de desenvolvimento integrado, Docker e Kubernetes; em seguida, apresenta brevemente a estrutura e as bibliotecas de terceiros usadas no aplicativo de amostra; finalmente, apresenta os serviços de suporte usados pelo aplicativo de amostra e o ferramentas necessárias para o desenvolvimento.
Aula 10: API-first design com OpenAPI e Swagger
A partir desta aula, entraremos no desenvolvimento real de aplicativos de arquitetura de microsserviços nativos da nuvem.Antes de introduzir a implementação específica de microsserviços, a primeira tarefa é projetar e determinar a API aberta de cada microsserviço . A API aberta tornou-se amplamente popular nos últimos anos, e muitos serviços online e agências governamentais forneceram API aberta, que se tornou uma função padrão dos serviços online. Os desenvolvedores podem usar a API aberta para desenvolver vários aplicativos.
Embora exista uma certa relação entre a API aberta no aplicativo de microsserviço e a API aberta no serviço online, suas funções são diferentes. Na aplicação da arquitetura de microsserviços, os microsserviços só podem interagir por meio de comunicação entre processos, geralmente usando REST ou gRPC. Tal método de interação precisa ser corrigido de forma formalizada, formando uma API aberta. Uma API aberta de um microsserviço blinda os detalhes de implementação interna do serviço de usuários externos e também é a única forma de os usuários externos interagirem com ela ( claro, aqui se refere à integração entre microsserviços apenas por meio da API, se eventos assíncronos forem usados para integração, esses eventos também são interativos). A partir disso, podemos ver a importância da API de microsserviço. Do ponto de vista do público, os usuários de APIs de microsserviços são principalmente outros microsserviços, ou seja, principalmente usuários internos do aplicativo, o que é diferente da API de serviços online, que são principalmente voltados para usuários externos. Além de outros microsserviços, a interface web do aplicativo e os clientes móveis também precisam usar a API do microsserviço, mas geralmente usam a API do microsserviço por meio de um gateway de API.
Devido à importância da API do microsserviço, precisamos projetar a API muito cedo, ou seja, a estratégia API-first.
Uma estratégia API-first
Se você tiver experiência no desenvolvimento de APIs de serviços online, descobrirá que geralmente a implementação vem primeiro, seguida pela API pública, porque a API pública não foi considerada antes do projeto, mas foi adicionada posteriormente. O resultado dessa abordagem é que a API aberta reflete apenas a implementação real atual, não o que a API deveria ser. O método de design da API primeiro (API First) é colocar o design da API antes da implementação específica. A API first enfatiza que o design da API deve ser considerado mais da perspectiva dos usuários da API.
Antes de escrever a primeira linha do código de implementação, o provedor e o usuário da API devem ter uma discussão completa sobre a API, combinar as opiniões dos dois lados, finalmente determinar todos os detalhes da API e corrigi-la em um formato formal para se tornar uma especificação de API. Depois disso, o provedor da API garante que a implementação real atenda aos requisitos da especificação da API e o usuário grava a implementação do cliente de acordo com a especificação da API. A especificação da API é um contrato entre o provedor e o usuário, e a estratégia API-first foi aplicada no desenvolvimento de muitos serviços online. Depois que a API é projetada e implementada, a interface da web e o aplicativo móvel do próprio serviço online, assim como outros aplicativos de terceiros, são implementados usando a mesma API.
A estratégia API-first desempenha um papel mais importante na implementação de aplicativos da arquitetura de microsserviços. Aqui é necessário distinguir dois tipos de APIs: uma é a API fornecida para outros microsserviços e a outra é a API fornecida para a interface web e clientes móveis. Ao apresentar o design orientado a domínio na 07ª aula, mencionei o serviço de host aberto e a linguagem pública no modo de mapeamento do contexto limitado, e os microsserviços correspondem ao contexto limitado um a um. Se você combinar o serviço de host aberto com o idioma comum, obterá a API do microsserviço e o idioma comum será a especificação da API.
A partir daqui, podemos saber que o objetivo do primeiro tipo de API de microsserviço é o mapeamento de contexto, que é significativamente diferente da função do segundo tipo de API. Por exemplo, o microsserviço de gerenciamento de passageiros fornece funções para gerenciar passageiros, incluindo registro de passageiros, atualização de informações e consulta. Para o App do passageiro, essas funções requerem o suporte da API. Caso outros microsserviços precisem obter informações do passageiro, eles também devem chamar a API do microsserviço de gerenciamento de passageiros. Isso é para mapear o conceito de passageiros entre diferentes microsserviços.
implementação da API
Na implementação da API, um dos primeiros problemas é escolher o método de implementação da API. Em teoria, as APIs internas dos microsserviços não possuem altos requisitos de interoperabilidade e podem usar formatos privados. No entanto, para usar a grade de serviço, é recomendável usar um formato padrão comum. A tabela a seguir mostra o formato API comum. Geralmente escolha entre REST e gRPC, exceto usando menos SOAP. A diferença entre os dois é que o REST usa um formato de texto e o gRPC usa um formato binário; os dois diferem em popularidade, dificuldade de implementação e desempenho. Resumindo, REST é relativamente mais popular e menos difícil de implementar, mas seu desempenho não é tão bom quanto o gRPC.
 

A API para o aplicativo de exemplo nesta coluna é implementada usando REST, embora haja uma classe dedicada ao gRPC. O seguinte descreve a especificação OpenAPI relacionada à API REST.
Especificação OpenAPI
Para uma melhor comunicação entre provedores de API e usuários, precisamos de um formato padrão para descrever as APIs. Para APIs REST, esse formato padrão é definido pela especificação OpenAPI.
A OpenAPI Specification (OAS) é uma especificação de API aberta gerenciada pela OpenAPI Initiative (OAI) sob a Linux Foundation. O objetivo da OAI é criar, evoluir e promover um formato de descrição de API neutro para fornecedores. A especificação OpenAPI é baseada na especificação Swagger, doada pela SmartBear Corporation.
O documento OpenAPI descreve ou define a API, e o documento OpenAPI deve atender à especificação OpenAPI. A especificação OpenAPI define o formato do conteúdo de um documento OpenAPI, ou seja, os objetos e seus atributos que podem estar contidos nele. Um documento OpenAPI é um objeto JSON que pode ser representado no formato de arquivo JSON ou YAML. Veja a seguir uma introdução ao formato do documento OpenAPI. Todos os exemplos de código nesta lição usam o formato YAML.
Vários tipos básicos são definidos na especificação OpenAPI, como integer, number, string e boolean. Para cada tipo básico, o formato específico do tipo de dados pode ser especificado através do campo de formato, por exemplo, o formato do tipo string pode ser data, data-hora ou senha.
Os campos e suas descrições que podem aparecer no objeto raiz do documento OpenAPI são fornecidos na tabela abaixo. A versão mais recente da especificação OpenAPI é 3.0.3.
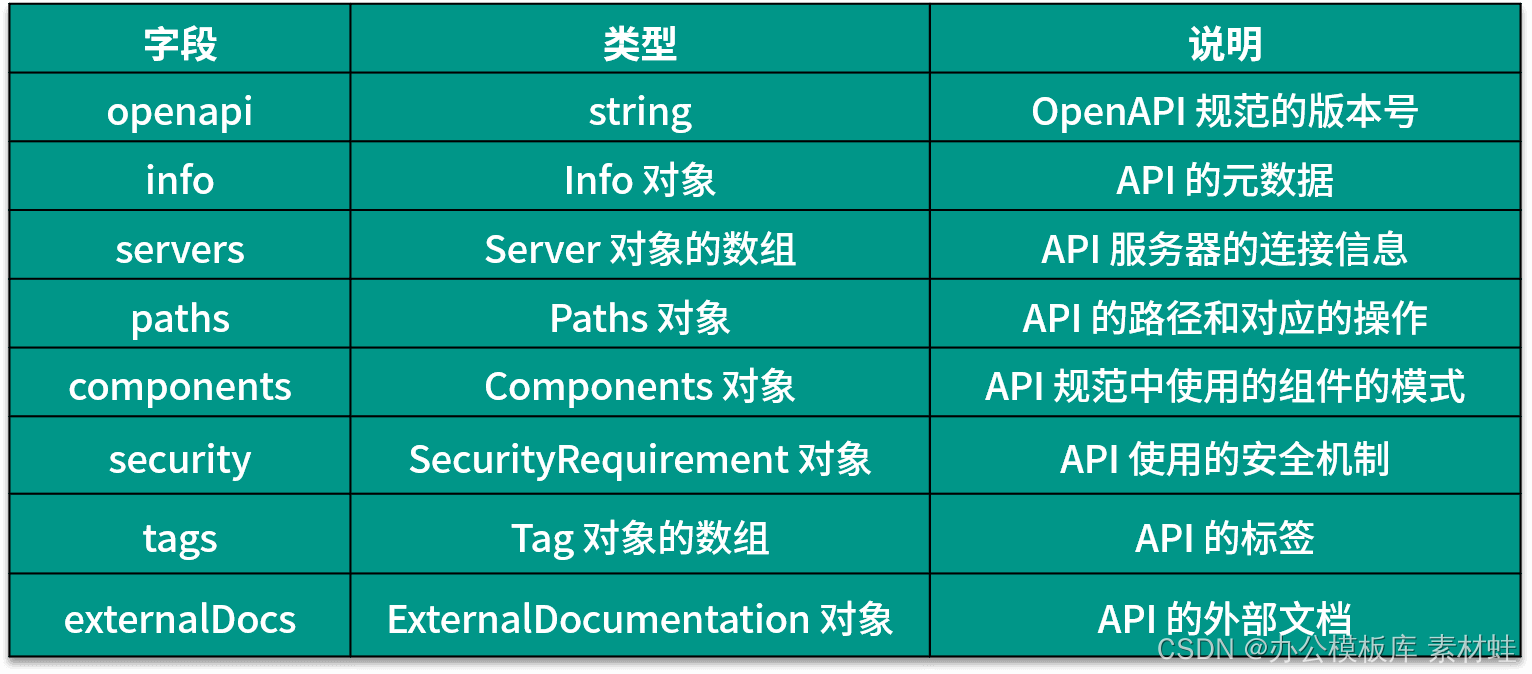 

objeto de informação
O objeto Info contém os metadados da API, que podem ajudar os usuários a entender melhor as informações relevantes da API. A tabela a seguir mostra os campos que podem ser incluídos no objeto Info e suas descrições.
 

O código a seguir é um exemplo de uso do objeto Info.
title : Descrição do serviço de teste : Este serviço é usado para testes simples licença: nome: Apache 2.0 url: https://www.apache.org/licenses/LICENSE-2.0.html versão: 2.1.0
objeto do servidor
O objeto Servidor representa o servidor da API.A tabela a seguir mostra os campos que podem ser incluídos no objeto Servidor e suas descrições.
 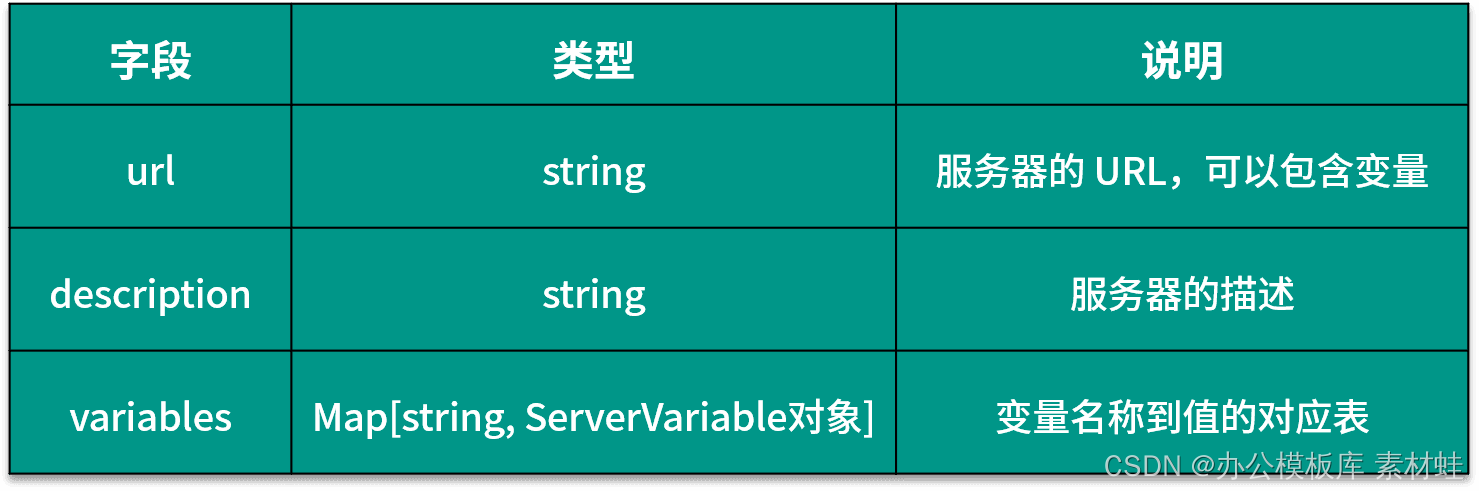

O código a seguir é um exemplo de uso do objeto Server, onde a URL do servidor contém dois parâmetros, port e basePath, port é um tipo de enumeração e os valores opcionais são 80 e 8080.
url: http://test.myapp.com:{port}/{basePath}
descrição:
Variáveis do servidor de teste:
porta:
enum:
- '80'
- '8080'
padrão: '80'
basePath:
padrão: v2
objeto Paths
Os campos no objeto Paths são dinâmicos. Cada campo representa um caminho, começando com "/", o caminho pode ser um modelo de string contendo variáveis. O valor do campo é um objeto PathItem, no qual você pode usar campos comuns, como resumo, descrição, servidores e parâmetros, e nomes de métodos HTTP, incluindo get, put, post, delete, opções, head, patch e trace , que O campo de nome do método define os métodos HTTP suportados pelo caminho correspondente.
Objeto de operação
No objeto Paths, o tipo de valor do campo correspondente ao método HTTP é um objeto Operation, representando uma operação HTTP. A tabela a seguir mostra os campos e suas descrições que podem ser incluídos no objeto Operação, sendo os campos parâmetros, requestBody e respostas os mais comumente utilizados.
 

Objeto de parâmetro
Um objeto Parameter representa os parâmetros de uma operação. A tabela a seguir mostra os campos que podem ser incluídos em um objeto Parâmetro e suas descrições.
 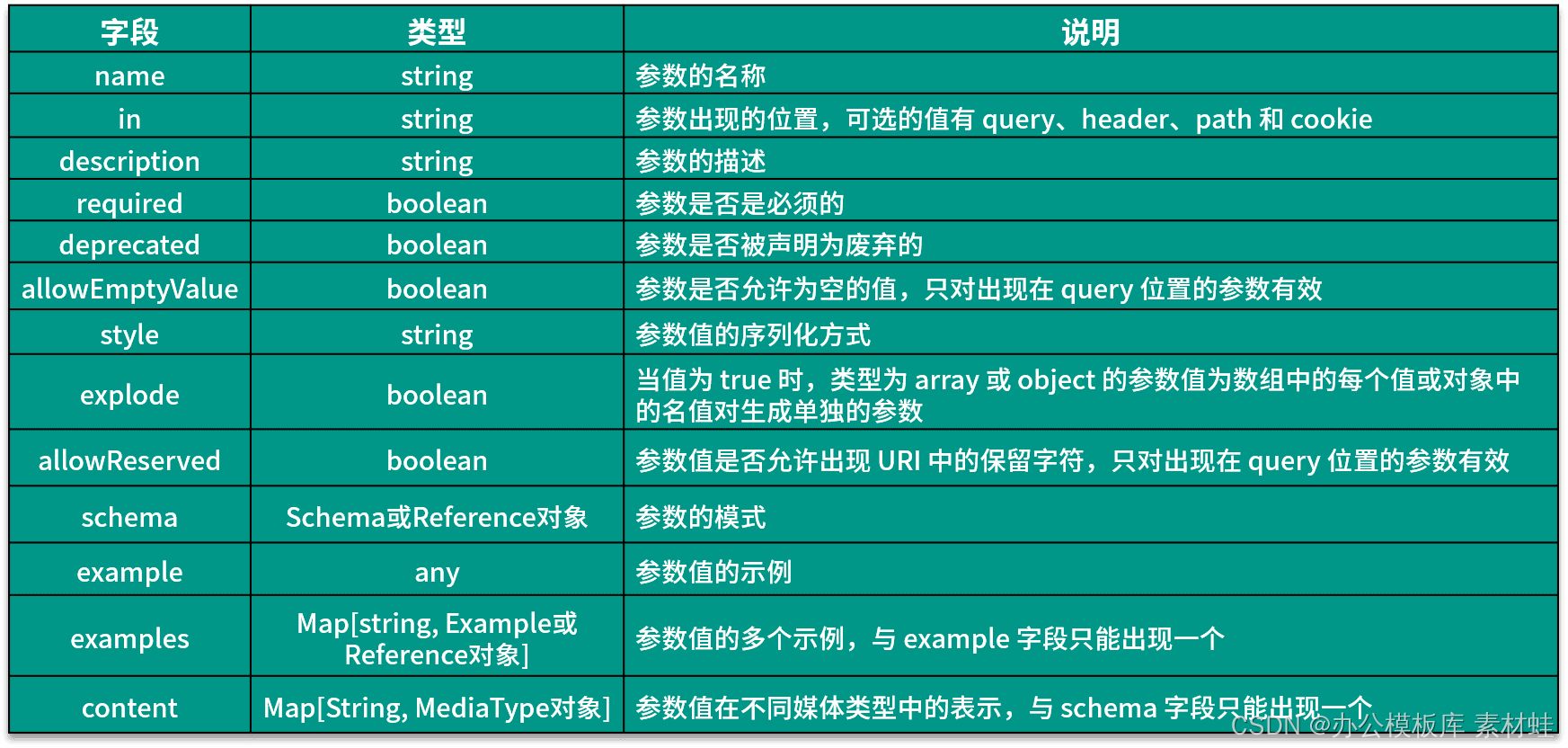

O código a seguir é um exemplo de uso do objeto Parameter: O id do parâmetro aparece no caminho e seu tipo é string.
nome: id em: descrição do caminho: 乘客ID necessário: verdadeiro esquema: tipo: string
objeto RequestBody
O objeto RequestBody representa o conteúdo da solicitação HTTP. A tabela a seguir mostra os campos que podem ser incluídos no objeto RequestBody e suas descrições.
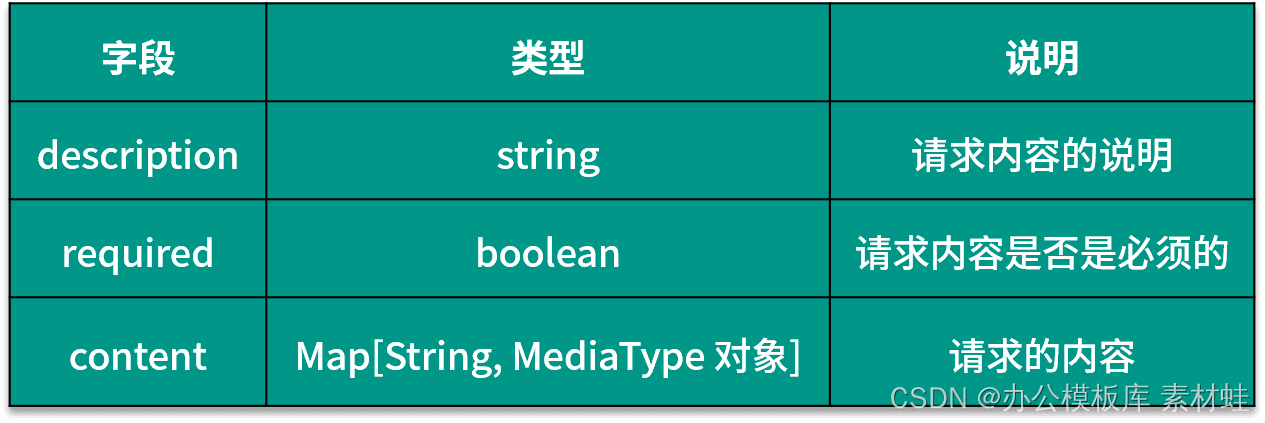 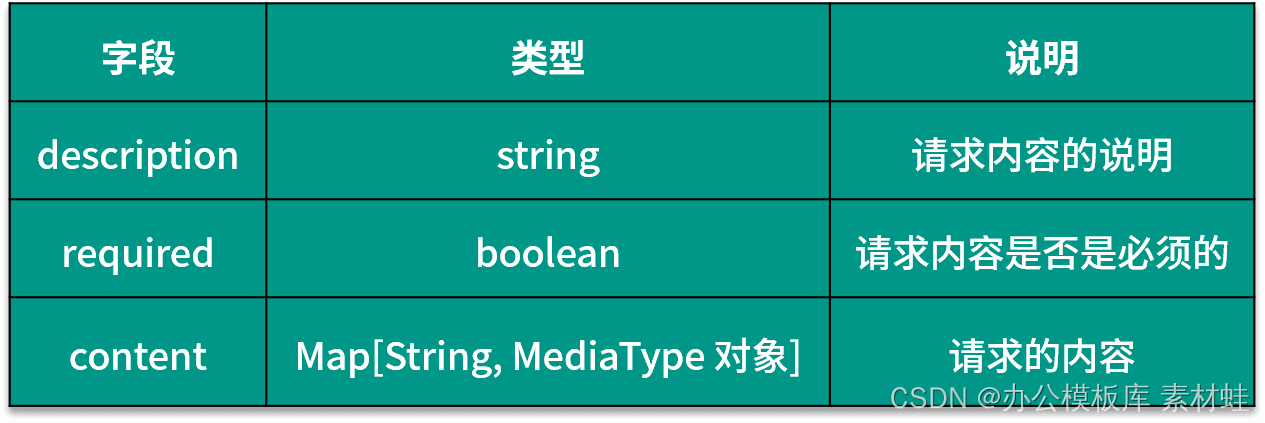

Objeto de respostas
O objeto Responses representa a resposta à solicitação HTTP e os campos desse objeto são dinâmicos. O nome do campo é o código de status da resposta HTTP e o tipo do valor correspondente é um objeto Response ou Reference. A tabela a seguir mostra os campos que podem ser incluídos no objeto Response e suas descrições.
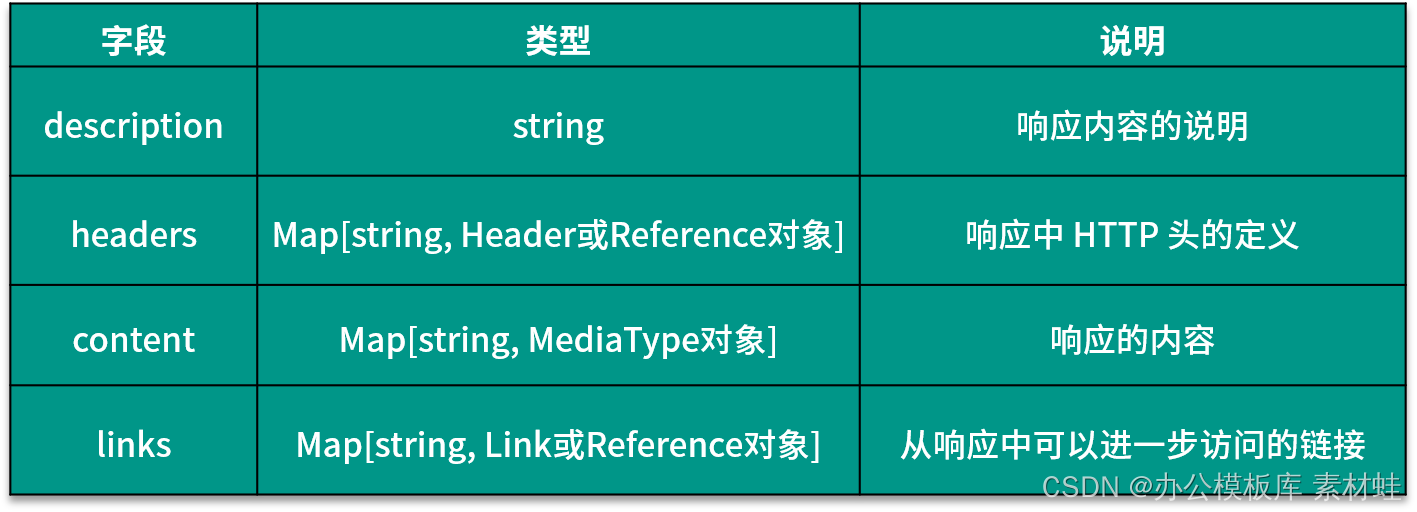 

Objeto de referência
Na descrição de diferentes tipos de objetos, o tipo do campo pode ser um objeto Reference, que representa uma referência a outros componentes, que contém apenas um campo $ref para declarar a referência. As referências podem ser a componentes dentro do mesmo documento ou de arquivos externos. Dentro do documento, diferentes tipos de componentes reutilizáveis podem ser definidos no objeto Components e referenciados pelo objeto Reference; a referência dentro do documento é um caminho de objeto começando com #, como #/components/schemas/CreateTripRequest.
Objeto de esquema
O objeto Schema é usado para descrever a definição do tipo de dados. O tipo de dados pode ser um tipo simples, uma matriz ou um tipo de objeto. O tipo pode ser especificado por meio do tipo de campo, e o campo de formato indica o formato do tipo . Se for um tipo array, ou seja, o valor do tipo é array, você precisa usar os itens do campo para representar o tipo dos elementos do array; se for um tipo objeto, ou seja, o valor do tipo é objeto , você precisa usar as propriedades do campo para representar o tipo de propriedade no objeto.
Exemplo de documentação completa
Abaixo está um exemplo de um documento OpenAPI completo. No objeto paths são definidas três operações, sendo que a definição do tipo de conteúdo da requisição da operação e formato da resposta é definida no campo schemas do objeto Components. Os campos requestBody e response de uma operação são referenciados usando um objeto Reference.
openapi: '3.0.3'
info:
título:
Versão do serviço de viagem: '1.0'
servidores:
- url: http://localhost:8501/api/v1
tags:
- nome:
descrição da viagem:
Caminhos relacionados à viagem:
/:
post:
tags:
-
resumo da viagem: criar viagem
operationId: createTrip
requestBody:
conteúdo:
application/json:
schema:
$ref: "#/components/schemas/CreateTripRequest"
obrigatório:
respostas verdadeiras:
'201':
descrição: criado com sucesso
/{tripId} :
obter:
tags:
-
resumo da viagem: get trip
operationId: getTrip
parameters:
- name: tripId
in: path
description: trip ID
required: true
schema:
type: string
answers:
'200':
description: get success
content:
application/json:
schema:
$ref: "#/components/schemas/TripVO"
'404':
descrição: Viagem não encontrada
/{tripId}/aceitar:
post:
tags:
- viagem
resumo: 接受行程
operationId: acceptTrip
parameters:
- name: tripId
in: path
description: 行程ID
required: true
schema:
type: string
requestBody:
content:
application/json:
schema:
$ref: "#/components/schemas/AcceptTripRequest"
required: true
respostas:
'200':
descrição: 接受成功
components:
esquemas:
CreateTripRequest:
tipo:
propriedades do objeto:
passageId:
tipo: string
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
obrigatório:
- passageId
- startPos
- endPos
AcceptTripRequest:
tipo:
propriedades do objeto:
driverId:
tipo: string
posLng:
type: number
format: double
posLat:
type: number
format: double
required:
- driverId
- posLng
- posLat
TripVO:
tipo de posLat: objeto
properties:
id:
tipo: string
passageId:
tipo: string
driverId:
tipo: string
startPos:
$ref: "#/components/schemas/PositionVO"
endPos:
$ref: "#/components/schemas/PositionVO"
estado:
tipo: string
PositionVO:
type: object
properties:
lng:
type: number
format: double
lat:
type: number
format: double
required:
addressId:
digite: string
-lng
-lat
Ferramentas OpenAPI
Podemos utilizar algumas ferramentas para auxiliar o desenvolvimento relacionado à especificação OpenAPI. Como predecessor da especificação OpenAPI, o Swagger fornece muitas ferramentas relacionadas ao OpenAPI.
editor swagger
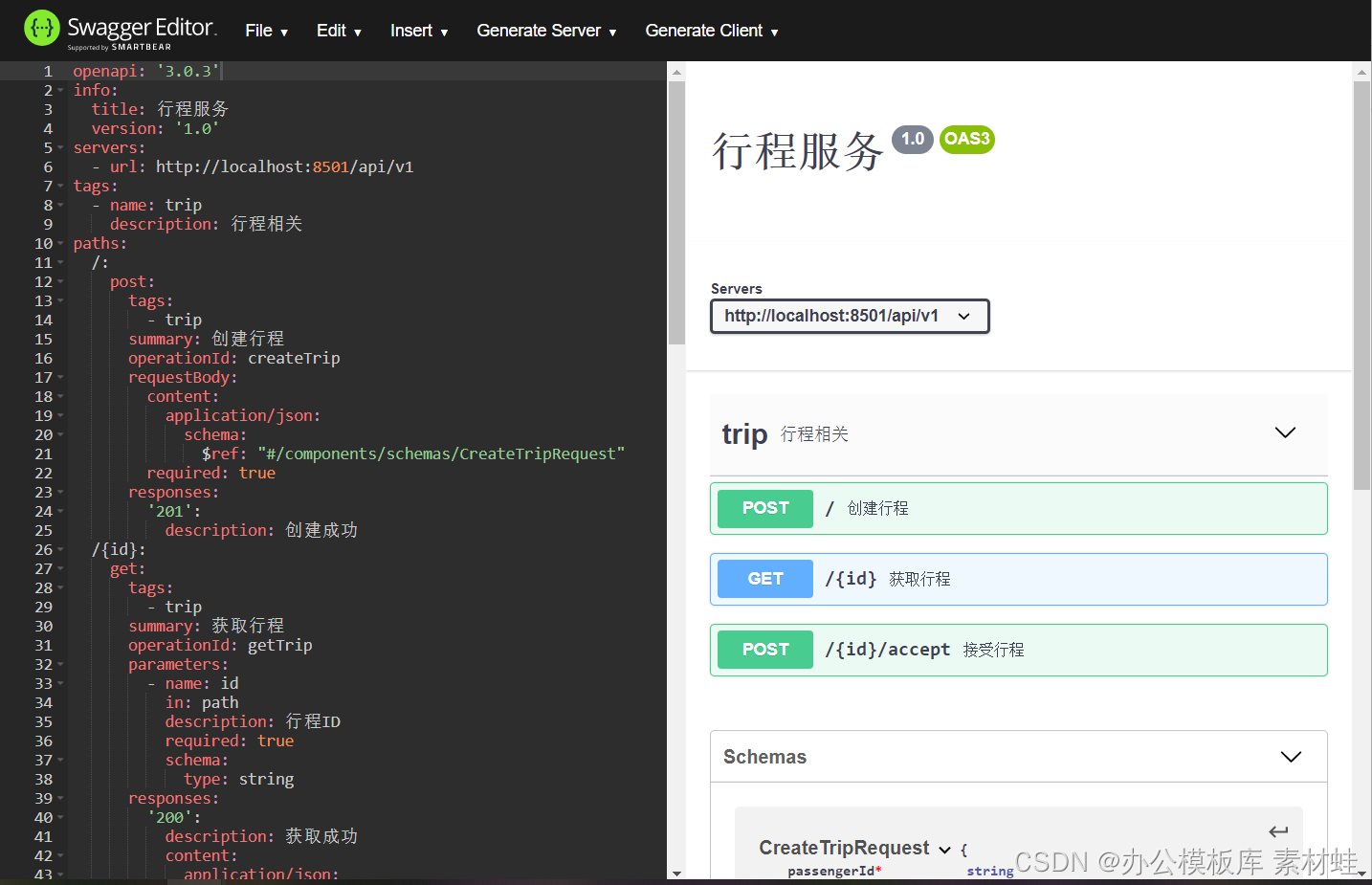
Swagger Editor é uma versão web do editor de documentação Swagger e OpenAPI. No lado esquerdo do editor está o editor e no lado direito está uma visualização da documentação da API. O editor Swagger fornece muitas funções úteis, incluindo destaque de sintaxe, adição rápida de diferentes tipos de objetos, geração de código de servidor e geração de código de cliente, etc.
Ao usar o editor Swagger, você pode usar a versão online diretamente ou executá-lo localmente. A maneira mais fácil de executá-lo localmente é usar a imagem do Docker swaggerapi/swagger-editor.
O código a seguir inicia o contêiner Docker do editor Swagger. Depois que o contêiner é iniciado, ele pode ser acessado por meio de localhost:8000.
docker run -d -p 8000:8080 swaggerapi/swagger-editor
A figura abaixo é a interface do editor Swagger.

Interface elegante
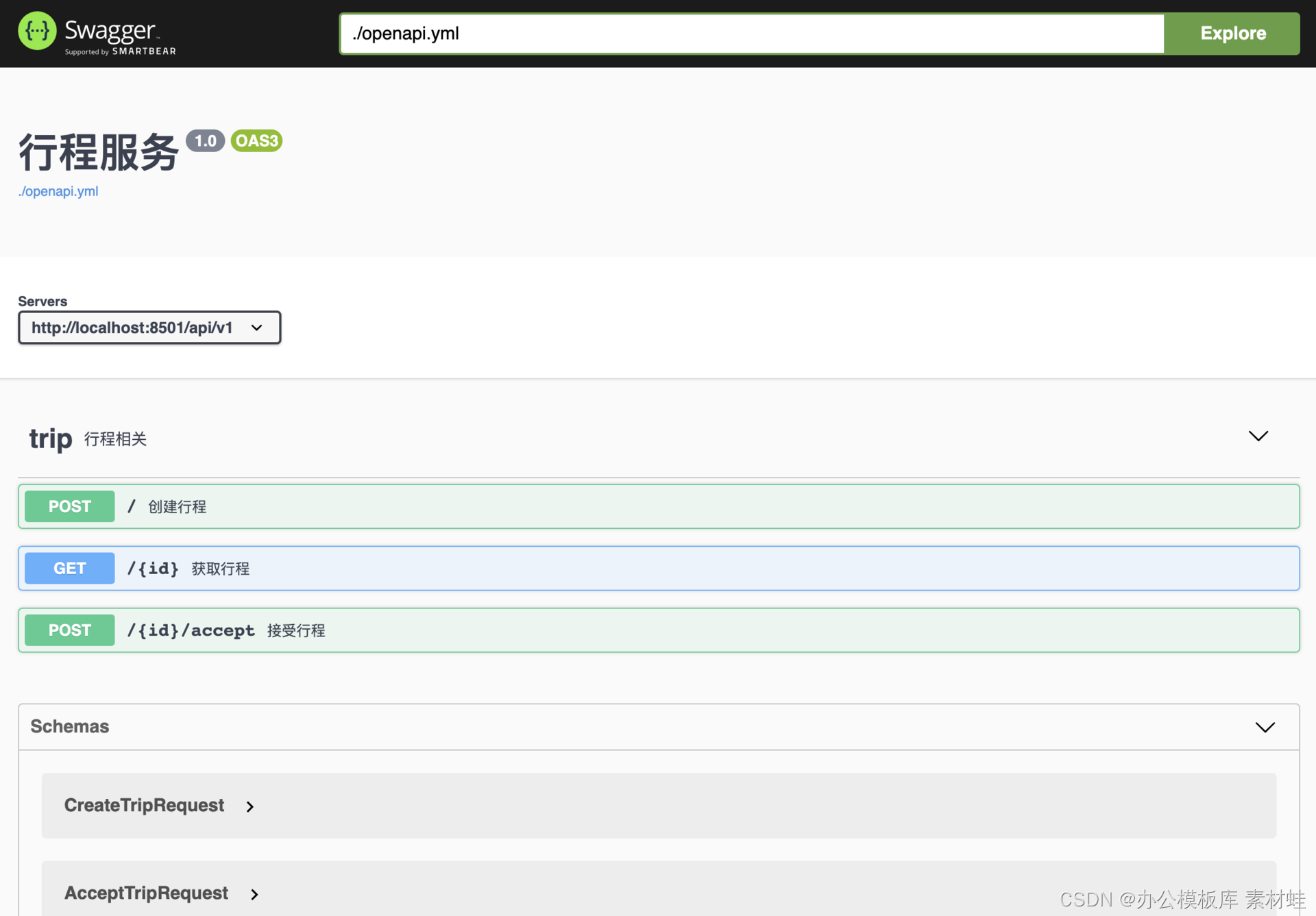
A interface do Swagger fornece uma maneira intuitiva de visualizar e interagir com a documentação da API. Por meio dessa interface, você pode enviar solicitações HTTP diretamente para o servidor da API e visualizar os resultados da resposta.
Da mesma forma, podemos usar o Docker para iniciar a interface Swagger conforme mostrado no comando abaixo. Depois que o contêiner é iniciado, ele pode ser acessado por meio de localhost:8010.
docker run -d -p 8010:8080 swaggerapi/swagger-ui
Para documentação OpenAPI local, uma imagem do Docker pode ser configurada para usar essa documentação. Supondo que haja um documento OpenAPI openapi.yml no diretório atual, você pode usar o seguinte comando para iniciar a imagem do Docker para exibir o documento.
docker run -p 8010:8080 -e SWAGGER_JSON=/api/openapi.yml -v $PWD:/api swaggerapi/swagger-ui
A figura abaixo é uma captura de tela da interface do Swagger.

geração de código
Por meio do documento OpenAPI, você pode usar a ferramenta de geração de código fornecida pelo Swagger para gerar automaticamente o código stub do servidor e o cliente. Diferentes linguagens de programação e frameworks podem ser usados para geração de código.
As linguagens de programação e estruturas suportadas pelas ferramentas de geração de código são fornecidas abaixo.
aspnetcore, csharp, csharp-dotnet2, go-server, dynamic-html, html, html2, java, jaxrs-cxf-client, jaxrs-cxf, inflector, jaxrs-cxf-cdi, jaxrs-spec, jaxrs-jersey, jaxrs- di, jaxrs-resteasy-eap, jaxrs-resteasy, micronaut , spring, nodejs-server, openapi, openapi-yaml, kotlin-client, kotlin-server, php, python, python-flask, r, scala, scal a- akka -http-server, swift3, swift4, swift5, typescript-angular, javascript
A ferramenta de geração de código é um programa Java que pode ser executado diretamente após o download. Depois de baixar o arquivo JAR swagger-codegen-cli-3.0.19.jar , você pode usar o seguinte comando para gerar o código do cliente Java, onde o parâmetro -i especifica o documento OpenAPI de entrada, -l especifica o idioma gerado e - o especifica o índice de saída.
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l java -o /tmp
Além de gerar o código do cliente, o código stub do servidor também pode ser gerado. O código a seguir é para gerar o código stub do servidor NodeJS:
java -jar swagger-codegen-cli-3.0.19.jar generate -i openapi.yml -l nodejs-server -o /tmp
Resumir
A estratégia API-first garante que a API do microsserviço seja projetada com total consideração pelas necessidades dos usuários da API, tornando a API um bom contrato entre o provedor e o usuário. Esta classe primeiro apresenta a estratégia de design da API primeiro, depois apresenta os diferentes métodos de implementação da API, depois apresenta a especificação OpenAPI da API REST e, finalmente, apresenta as ferramentas relacionadas da OpenAPI.