1. Introdução aos conjuntos de dados
O conjunto de dados CIFAR-10 consiste em 60.000 imagens coloridas 32x32 em 10 categorias , 6000com 1 imagem em cada categoria. Existem 50000imagens de treinamento e 10000imagens de teste.
O conjunto de dados é dividido em 5 lotes de treinamento e 1 lote de teste, cada lote possui 10.000 imagens. O lote de teste contém exatamente 1.000 imagens selecionadas aleatoriamente de cada classe. Os lotes de treinamento contêm as imagens restantes em ordem aleatória, mas alguns lotes de treinamento podem conter mais imagens de uma classe do que de outra. Entre eles, o lote de treinamento contém exatamente 5.000 imagens de cada turma.
Resumir:
Size(大小):Imagem RGB 32 × 32, o conjunto de dados em si é o canal BGR,
Num(数量):conjunto de treinamento 50.000 e conjunto de teste 10.000, um total de 60.000 imagens
Classes(十种类别):de avião (aeronave), carro (carro), pássaro (pássaro), gato (gato), veado (veado) ), cachorro (cachorro), sapo (sapo), cavalo (cavalo), navio (navio), caminhão (caminhão)

Link para Download
Dream是个帅哥Compartilhando do blogger ( ):
Link: https://pan.baidu.com/s/1gKazlkk108V_1nrc68VoSQ código de extração: 0213
Pasta do conjunto de dados
Conjunto de dados CIFAR-100 (estendido)
Este conjunto de dados é semelhante ao CIFAR-10, exceto que possui 100 classes e cada classe contém 600 imagens. Existem 500 imagens de treinamento e 100 imagens de teste para cada aula. As 100 subcategorias do CIFAR-100 estão divididas em 20 categorias amplas. Cada imagem possui uma tag “fina” (a subcategoria à qual pertence) e uma tag “grossa” (a categoria principal à qual pertence).
Comparação entre o conjunto de dados CIFAR-10 e o conjunto de dados MNIST
- As dimensões são diferentes: o conjunto de dados CIFAR-10 tem 4 dimensões, e o conjunto de dados MNIST tem 3 dimensões (as quatro dimensões do CIRAR-10: o número de amostras de uma vez, a altura da imagem, a largura da imagem, o número de canais de imagem -> NHWC; as três dimensões do MNIST: número único de amostras, altura da imagem, largura da imagem -> NHW)
- Os tipos de imagens são diferentes: o conjunto de dados CIFAR-10 é uma imagem RGB (com três canais) e o conjunto de dados MNIST é uma imagem em tons de cinza, razão pela qual o conjunto de dados CIFAR-10 tem uma dimensão a mais que o conjunto de dados MNIST .
- O conteúdo das imagens é diferente: o conjunto de dados CIFAR-10 mostra uma variedade de objetos diferentes (gatos, cães, aviões, carros...), e o conjunto de dados MNIST mostra números manuscritos de 0 a 9 por pessoas diferentes.
2. Leitura do conjunto de dados
Leia o conjunto de dados
Selecione data_batch_1 para visualizar uma das imagens:
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
print(dict)
Resultados de saída:
Existem 4 chaves de dicionário em um lote de conjuntos de dados. O que precisamos usar é o rótulo de dados e o conteúdo dos dados (10.000 × 32 × 32 × 3, 10.000 imagens de três canais RGB de 32 × 32)

a saída é um dicionário :
{ b'batch_label': b'lote de treinamento 1 de 5', b'labels': [6, 9… 1,5], b'data': array([[ 59, 43,…, 84, 72], …[62, 61, 60,…, 130, 130, 131]], dtype=uint8), b'nomes de arquivos': [b'leptodactylus_pentadactylus_s_000004.png',…b'cur_s_000170.png'] }
Entre eles, o significado de cada representante é o seguinte:
b'batch_label': o conjunto de arquivos ao qual pertence
b'labels': rótulo da imagem
b'data' : dados da imagem
b'filename' : nome da imagem
Tipo de leitura
print(type(dict[b'batch_label']))
print(type(dict[b'labels']))
print(type(dict[b'data']))
print(type(dict[b'filenames']))
Resultado de saída:
<class 'bytes'>
<class 'lista'>
<class 'numpy.ndarray'>
<class 'lista'>
Leia fotos
img = dict[b'data']
print(img.shape)
Resultado de saída: (10000, 3072), onde 3072 = 32 * 32 * 3 (tamanho da imagem)
3. Chamada de conjunto de dados
Chamadas do TensorFlow
from tensorflow.keras.datasets import cifar10
(x_train,y_train), (x_test, y_test) = cifar10.load_data()
chamada local
def unpickle(file):
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
dict = unpickle('D:\PycharmProjects\model-fuxian\CIFAR\cifar-10-batches-py\data_batch_1')
4. Treinamento de rede neural convolucional
Referência aqui: Portal
1.Especifique a GPU
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.config.experimental.set_memory_growth(gpus[0],True)
#初始化
plt.rcParams['font.sans-serif'] = ['SimHei']
2. Carregar dados
cifar10 = tf.keras.datasets.cifar10
(train_x,train_y),(test_x,test_y) = cifar10.load_data()
print('\n train_x:%s, train_y:%s, test_x:%s, test_y:%s'%(train_x.shape,train_y.shape,test_x.shape,test_y.shape))
3. Pré-processamento de dados
X_train,X_test = tf.cast(train_x/255.0,tf.float32),tf.cast(test_x/255.0,tf.float32) #归一化
y_train,y_test = tf.cast(train_y,tf.int16),tf.cast(test_y,tf.int16)
4. Construa um modelo
Os parâmetros do algoritmo Adam usam os parâmetros públicos padrão de keras, a função de perda usa a função de perda de entropia cruzada esparsa e a precisão usa a função de precisão de classificação esparsa.
model = tf.keras.Sequential()
##特征提取阶段
#第一层
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu,data_format='channels_last',input_shape=X_train.shape[1:])) #卷积层,16个卷积核,大小(3,3),保持原图像大小,relu激活函数,输入形状(28,28,1)
model.add(tf.keras.layers.Conv2D(16,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2))) #池化层,最大值池化,卷积核(2,2)
#第二层
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.Conv2D(32,kernel_size=(3,3),padding='same',activation=tf.nn.relu))
model.add(tf.keras.layers.MaxPool2D(pool_size=(2,2)))
##分类识别阶段
#第三层
model.add(tf.keras.layers.Flatten()) #改变输入形状
#第四层
model.add(tf.keras.layers.Dense(128,activation='relu')) #全连接网络层,128个神经元,relu激活函数
model.add(tf.keras.layers.Dense(10,activation='softmax')) #输出层,10个节点
print(model.summary()) #查看网络结构和参数信息
#配置模型训练方法
model.compile(optimizer='adam',loss='sparse_categorical_crossentropy',metrics=['sparse_categorical_accuracy'])
5. Treine o modelo
O tamanho do treinamento em lote é 64, a iteração é 5 e a proporção do conjunto de testes é 0,2 (48.000 dados do conjunto de treinamento, 12.000 dados do conjunto de testes)
history = model.fit(X_train,y_train,batch_size=64,epochs=5,validation_split=0.2)
6. Avalie o modelo
model.evaluate(X_test,y_test,verbose=2) #每次迭代输出一条记录,来评价该模型是否有比较好的泛化能力
#保存整个模型
model.save('CIFAR10_CNN_weights.h5')
7. Visualização de resultados
print(history.history)
loss = history.history['loss'] #训练集损失
val_loss = history.history['val_loss'] #测试集损失
acc = history.history['sparse_categorical_accuracy'] #训练集准确率
val_acc = history.history['val_sparse_categorical_accuracy'] #测试集准确率
plt.figure(figsize=(10,3))
plt.subplot(121)
plt.plot(loss,color='b',label='train')
plt.plot(val_loss,color='r',label='test')
plt.ylabel('loss')
plt.legend()
plt.subplot(122)
plt.plot(acc,color='b',label='train')
plt.plot(val_acc,color='r',label='test')
plt.ylabel('Accuracy')
plt.legend()
8. Use modelos
plt.figure()
for i in range(10):
num = np.random.randint(1,10000)
plt.subplot(2,5,i+1)
plt.axis('off')
plt.imshow(test_x[num],cmap='gray')
demo = tf.reshape(X_test[num],(1,32,32,3))
y_pred = np.argmax(model.predict(demo))
plt.title('标签值:'+str(test_y[num])+'\n预测值:'+str(y_pred))
plt.show()
Resultados de saída:

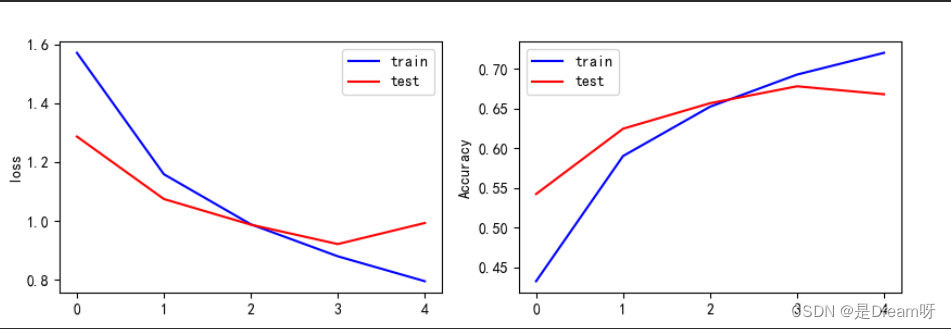
O conteúdo acima é o valor da função de perda e precisão da amostra de treinamento, e o valor da função de perda e precisão da amostra de teste. Você pode ver as mudanças na função de perda e precisão em cada iteração de treinamento, começando pela última resultado da iteração, parece que o valor da função de perda da amostra de teste atinge 0,9123 e a precisão atinge apenas 0,6839.
Este resultado não é muito bom. Tentei aumentar o número de iterações e descobri que o valor da função de perda da amostra de treinamento poderia chegar a 0,04 e a precisão chegar a 0,98. Mas, na verdade, o modelo de treinamento produziu erros de generalização crescentes. Este é o treinamento. O fenômeno do excesso é que depois de tentar, a melhor capacidade de generalização está na 5ª iteração, então só podemos optar por iterar 5 vezes.

Arquivo de modelo treinado – use diretamente
Introdução ao conjunto de dados CIFAR10 e uso de redes neurais convolucionais para treinar modelos de classificação de imagens - código completo e arquivos de modelo treinados anexados - use diretamente: https://download.csdn.net/download/weixin_51390582/88788820