Diretório de artigos

Pensamentos desencadeados pela pergunta da entrevista "O Redis é single-threaded?"
Autor: Li Le
Fonte: IT Reading Ranking
Muitas pessoas se depararam com essa pergunta de entrevista: O Redis é de thread único ou multithread? Esta questão é simples e complexa. Diz-se que é simples porque a maioria das pessoas sabe que o Redis é de thread único e é considerado complexo porque a resposta é, na verdade, imprecisa.
O Redis não é de thread único? Iniciamos uma instância do Redis e a verificamos. O método de instalação e implantação do Redis é o seguinte:
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
Em seguida, inicie a instância do Redis e use o comando ps para visualizar todos os threads, conforme mostrado abaixo:
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
Na verdade, existem 6 tópicos! Não é dito que o Redis é single-threaded? Por que existem tantos tópicos?
Você pode não entender o significado desses seis threads, mas este exemplo pelo menos mostra que o Redis não é de thread único.
01 Multithreading em Redis
A seguir, apresentamos as funções dos 6 threads acima, um por um:
1) servidor redis:
O thread principal é usado para receber e processar solicitações de clientes.
2)jemalloc_bg_thd
jemalloc é uma nova geração de alocador de memória, usado pela camada inferior do Redis para gerenciar a memória.
3)bio_xxx:
Aqueles que começam com o prefixo bio são todos threads assíncronos, usados para executar algumas tarefas demoradas de forma assíncrona. Entre eles, o thread bio_close_file é usado para excluir arquivos de forma assíncrona, o thread bio_aof é usado para liberar arquivos AOF de forma assíncrona para o disco e o thread bio_lazy_free é usado para excluir dados de forma assíncrona (exclusão lenta).
Deve-se observar que o thread principal distribui tarefas para threads assíncronos por meio da fila, e esta operação requer bloqueio. O relacionamento entre o thread principal e o thread assíncrono é mostrado na figura abaixo:
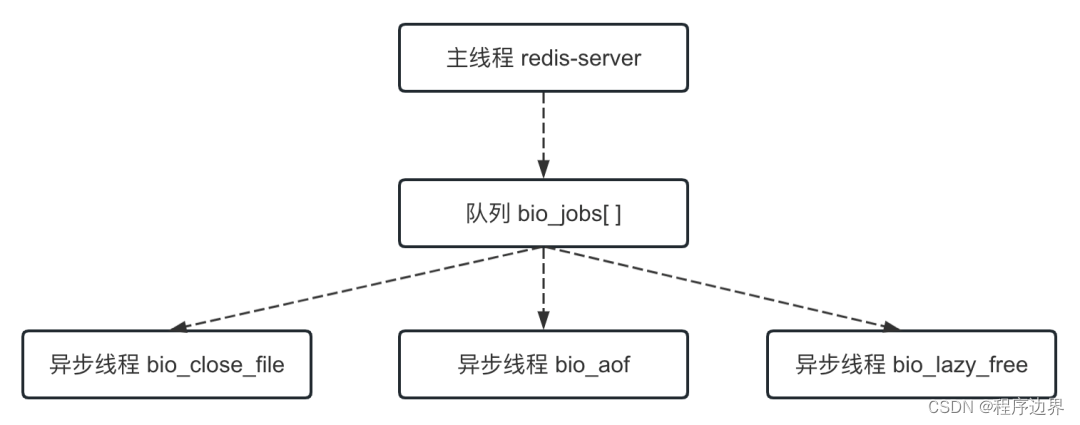
Thread principal e thread assíncrona Thread principal e thread assíncronaThread principal e thread assíncrono
Aqui tomamos a exclusão lenta como exemplo para explicar por que o thread assíncrono deve ser usado. Redis é um banco de dados na memória que oferece suporte a vários tipos de dados, incluindo strings, listas, tabelas hash, conjuntos, etc. Pense bem, qual é o processo de exclusão de dados do tipo lista (DEL)? A primeira etapa é excluir o par chave-valor do dicionário do banco de dados e a segunda etapa é percorrer e excluir todos os elementos da lista (liberando memória). Pense no que aconteceria se o número de elementos da lista fosse muito grande? Esta etapa consumirá muito tempo. Este método de exclusão é chamado de exclusão síncrona e o processo é mostrado na figura abaixo:
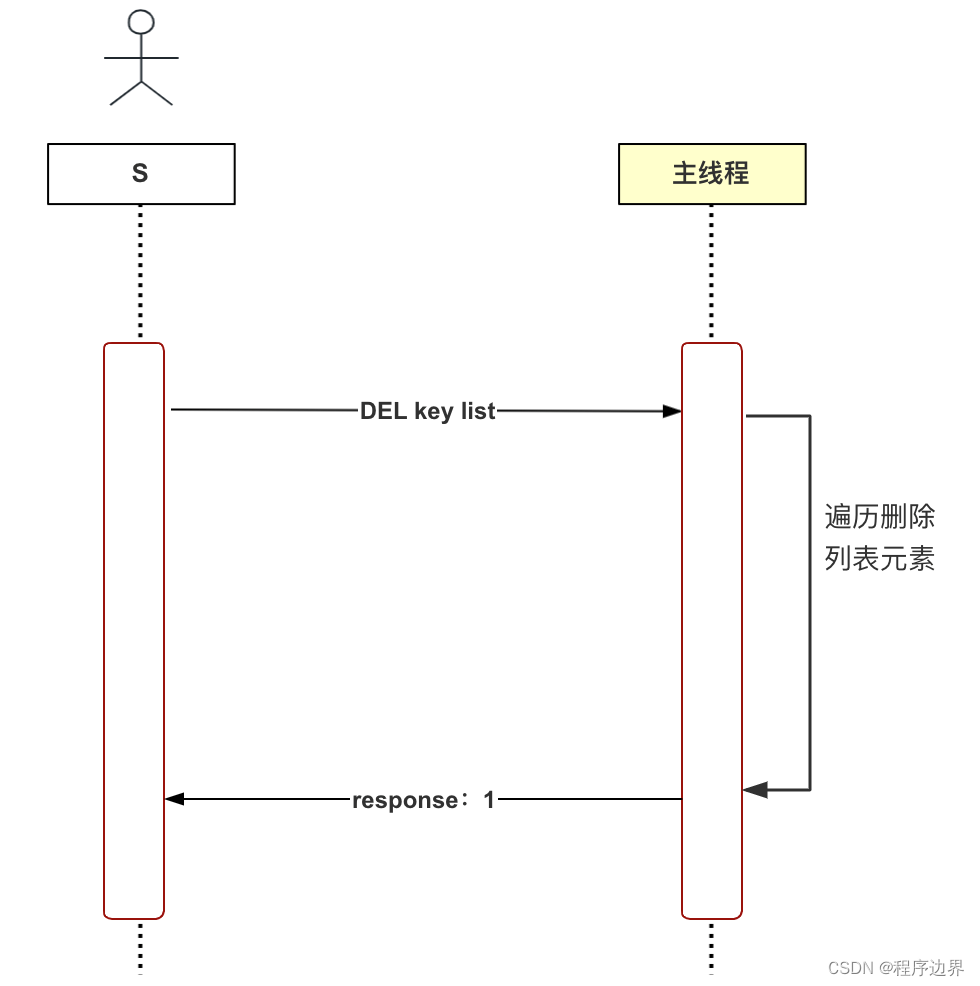
Fluxograma de exclusão síncrona Fluxograma de exclusão síncronaFluxograma de exclusão síncrona
Em resposta aos problemas acima, o Redis propôs a exclusão lenta (exclusão assíncrona).Quando o thread principal recebe o comando de exclusão (UNLINK), ele primeiro exclui o par chave-valor do dicionário do banco de dados e depois distribui a exclusão tarefa para o thread assíncrono.bio_lazy_free, a segunda etapa da lógica demorada é executada pelo thread assíncrono. O processo neste momento é mostrado abaixo:
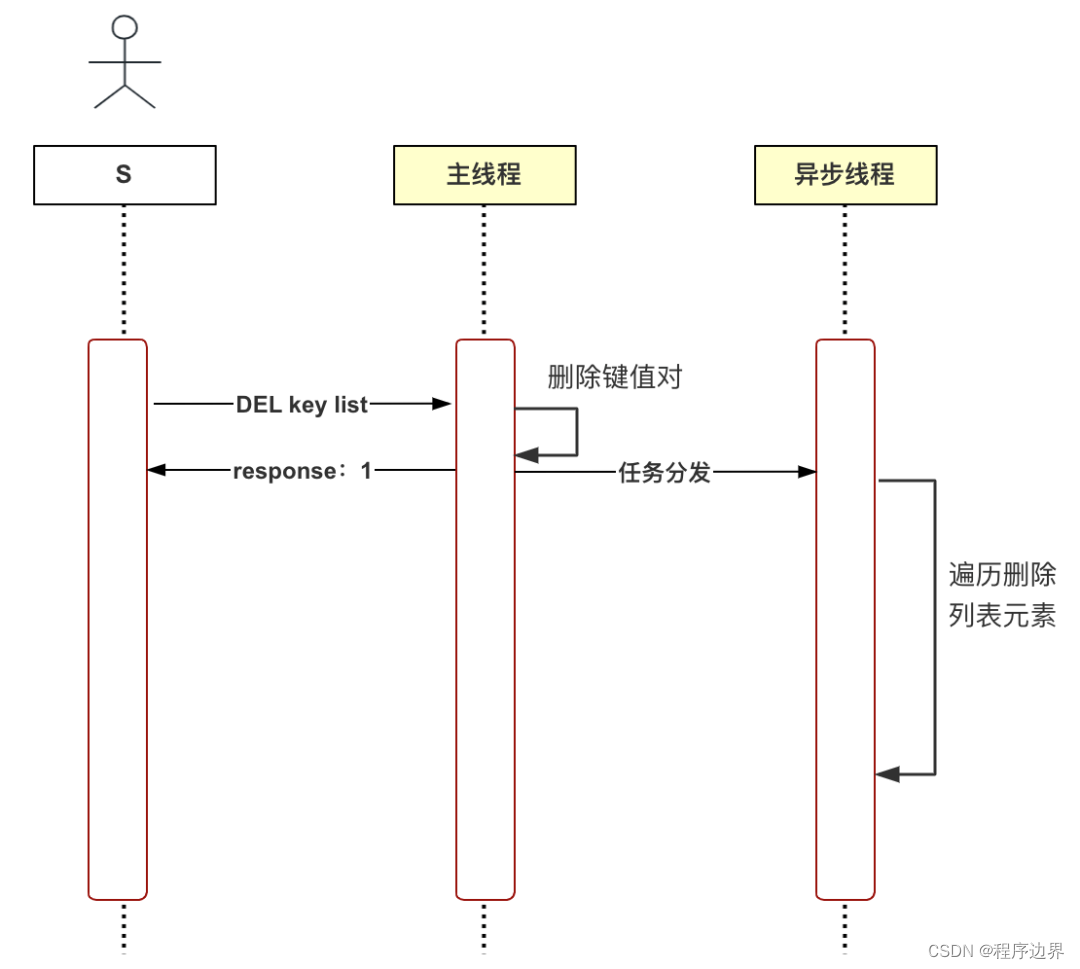
Fluxograma de exclusão lenta Fluxograma de exclusão lentaFluxograma de exclusão lenta
02 E/S multithreading
O Redis é multithread? Então, por que sempre dizemos que o Redis é single-threaded? Isso ocorre porque a leitura de solicitações de comando do cliente, a execução de comandos e o retorno de resultados ao cliente são concluídos no thread principal. Caso contrário, se vários threads operarem o banco de dados na memória ao mesmo tempo, como resolver o problema de simultaneidade? Se um bloqueio é bloqueado antes de cada operação, qual é a diferença entre ele e um único thread?
Claro, esse processo também mudou na versão Redis 6.0. Os funcionários do Redis apontaram que o Redis é um banco de dados de valores-chave baseado em memória. O processo de execução de comandos é muito rápido. Ele lê a solicitação de comando do cliente e retorna os resultados para o cliente (ou seja, E/S de rede) geralmente se torna o gargalo de desempenho do Redis.
Portanto, na versão Redis 6.0, o autor adicionou a capacidade de E/S multithread, ou seja, vários threads de E/S podem ser abertos, as solicitações de comando do cliente podem ser lidas em paralelo e os resultados podem ser retornados ao cliente em paralelo. A capacidade multithreading de E/S pelo menos dobra o desempenho do Redis.
Para ativar o recurso de E/S multithread, você precisa primeiro modificar o arquivo de configuração redis.conf:
io-threads-do-reads yes
io-threads 4
Os significados dessas duas configurações são os seguintes:
-
io-threads-do-reads: Para habilitar o recurso de E/S multithread, o padrão é "não";
-
io-threads: O número de threads de E/S, o padrão é 1, ou seja, apenas o thread principal é usado para realizar E/S de rede, e o número máximo de threads é 128; esta configuração deve ser definida de acordo com o número de núcleos de CPU. O autor recomenda definir 2 ~ 3 para threads de E/S de CPU de 4 núcleos, CPU de 8 núcleos define 6 threads de E/S.
Depois de ativar o recurso de E/S multithread, reinicie a instância do Redis e visualize todos os threads. Os resultados são os seguintes:
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
Como definimos io-threads como 4, 4 threads serão criados para realizar operações de E/S (incluindo o thread principal).Os resultados acima estão de acordo com as expectativas.
Claro, apenas a fase de E/S usa multithreading, e o processamento de solicitações de comando ainda é de thread único. Afinal, existem problemas de simultaneidade em operações multithread de dados de memória.
Finalmente, após a habilitação do multithreading de E/S, o fluxo de execução do comando é mostrado abaixo:
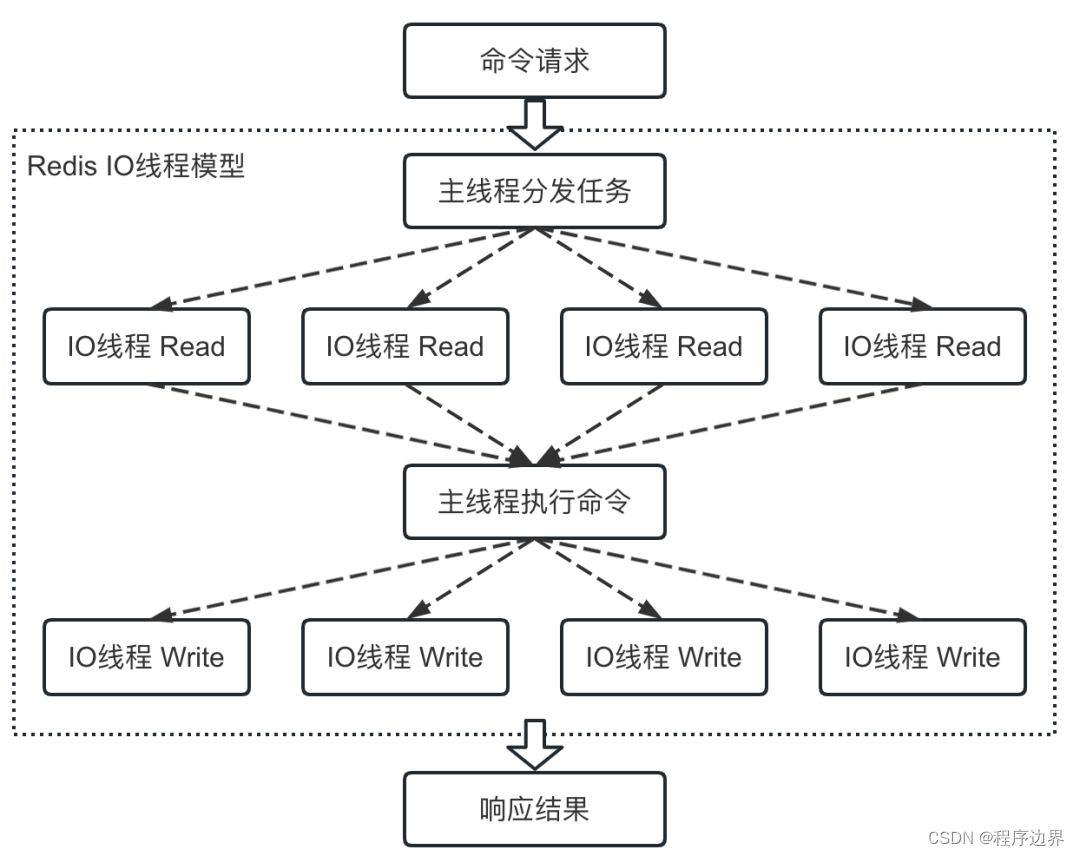
Fluxograma multithread de E/S Fluxograma multithread de E/SFluxograma multithreading de E / S
03 Multiprocesso no Redis
O Redis tem vários processos? Sim. Em alguns cenários, o Redis também criará vários subprocessos para executar algumas tarefas. Tomando a persistência como exemplo, o Redis oferece suporte a dois tipos de persistência:
-
AOF (Append Only File): Pode ser considerado um arquivo de log de comandos. O Redis anexará cada comando de gravação ao arquivo AOF.
-
RDB (Banco de Dados Redis): armazena dados na memória Redis na forma de snapshots. O comando SAVE é usado para acionar manualmente a persistência RDB. Pense nisso se a quantidade de dados no Redis for muito grande, a operação de persistência deve demorar muito e o Redis processa solicitações de comando em um único thread, então quando o tempo de execução do comando SAVE for muito longo, isso inevitavelmente afetará a execução de outros comandos.
O comando SAVE pode bloquear outras solicitações, por isso o Redis introduziu o comando BGSAVE, que criará um subprocesso para realizar operações de persistência, de forma que não afete o processo principal na execução de outras solicitações.
Podemos executar manualmente o comando BGSAVE para verificar. Primeiro, use o GDB para rastrear o processo Redis, adicionar pontos de interrupção e permitir que o processo filho seja bloqueado na lógica de persistência. Do seguinte modo:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
Após definir o ponto de interrupção, use o cliente Redis para enviar o comando BGSAVE. Os resultados são os seguintes:
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
Como você pode ver, o GDB está rastreando o processo filho e o ID do processo é 452541. Você também pode visualizar todos os processos através do comando ps do Linux. Os resultados são os seguintes:
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
Você pode ver que o nome do processo filho é redis-rdb-bgsave, o que significa que esse processo persiste em instantâneos de todos os dados em arquivos RDB.
Finalmente, considere duas questões.
- Pergunta 1: Por que usar subprocesso em vez de subthread?
Como o RDB armazena instantâneos de dados de forma persistente, se subthreads forem usados, o thread principal e os subthreads compartilharão dados de memória. O thread principal também modificará os dados de memória enquanto persiste, o que pode levar à inconsistência de dados. Os dados de memória do processo principal e do processo filho estão completamente isolados e esse problema não existe.
- Pergunta 2: Suponha que 10 GB de dados sejam armazenados na memória Redis. Depois de criar um processo filho para realizar operações de persistência, o processo filho também precisa de 10 GB de memória neste momento? Copiar 10 GB de dados de memória consumirá muito tempo, certo? Além disso, se o sistema tiver apenas 15 GB de memória, o comando BGSAVE ainda poderá ser executado?
Existe um conceito aqui chamado cópia na gravação. Depois de usar a chamada do sistema fork para criar um processo filho, os dados de memória do processo principal e do processo filho são temporariamente compartilhados, mas quando o processo principal precisa modificar os dados da memória, o o sistema fará automaticamente uma cópia deste bloco de memória para obter o isolamento dos dados da memória.
O fluxo de execução do comando BGSAVE é mostrado na figura abaixo:
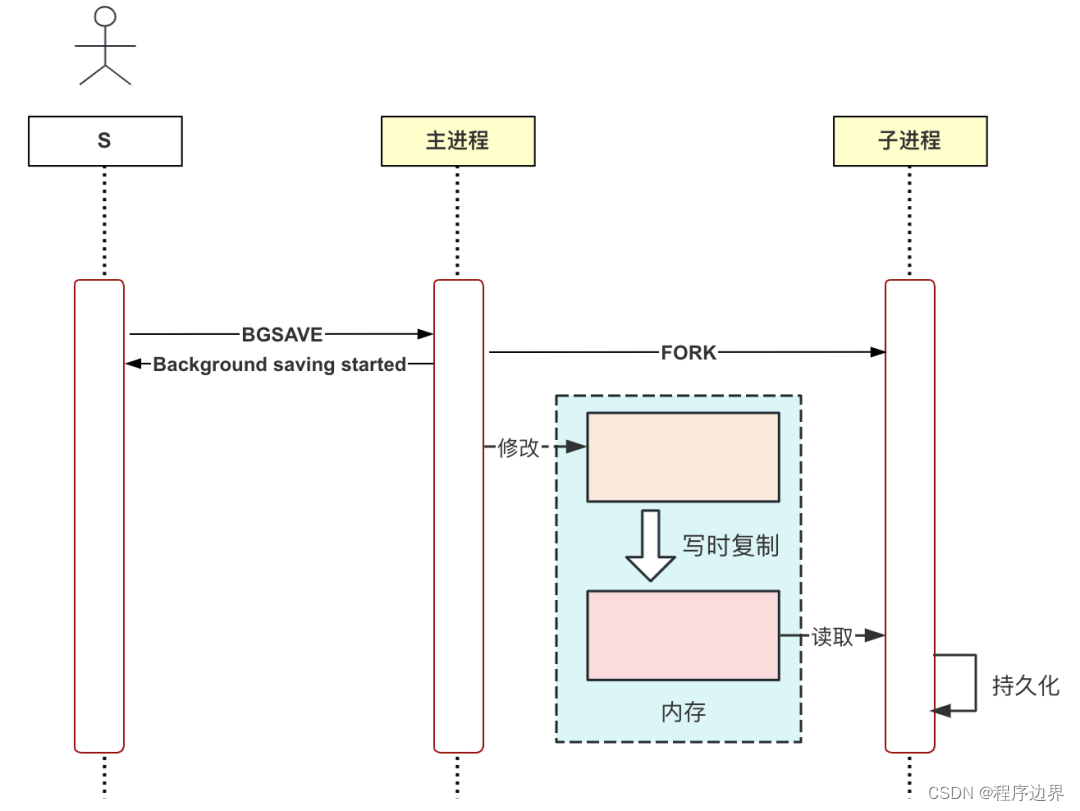
Processo de execução BGSAVE Processo de execução BGSAVEProcesso de execução BGS A V E
04 Conclusão
O modelo de processo/modelo de threading do Redis ainda é relativamente complexo. Aqui apresentamos apenas brevemente multi-threading e multiprocessamento em alguns cenários. Multi-threading e multiprocessamento em outros cenários ainda precisam ser estudados pelos próprios leitores.
Sobre o autor
Li Le: especialista em desenvolvimento de Golang na TAL e mestre pela Universidade de Ciência e Tecnologia Eletrônica de Xi'an. Ele já trabalhou para Didi. Ele está disposto a se aprofundar em tecnologia e código-fonte. Ele é coautor de "Usando Redis com eficiência: aprenda armazenamento de dados e clusters de alta disponibilidade em um livro" e "Redis5" Design e análise de código-fonte "" Design subjacente do Nginx e análise de código-fonte ".
▼Leitura estendida

"Usando o Redis com eficiência: aprenda sobre armazenamento de dados e clusters de alta disponibilidade em um livro" "Usando o Redis com eficiência: aprenda sobre armazenamento de dados e clusters de alta disponibilidade em um livro""Usando Redis com eficiência : aprenda armazenamento de dados e clusters de alta disponibilidade em um só livro "
Palavras recomendadas: Aprofunde-se na estrutura de dados do Redis e na implementação subjacente e supere os problemas de armazenamento de dados do Redis e gerenciamento de cluster.