Os microsserviços são imortais – explicação detalhada da implementação de variáveis compartilhadas no projeto do mecanismo de política
Others
2024-04-17 01:17:14
views: null
fundo
1. Proposição de variáveis compartilhadas
Há algum tempo, um estudo de caso da equipe do Amazon Prime Video causou alvoroço na comunidade de desenvolvedores. Basicamente, como plataforma de streaming, o Prime Video oferece milhares de transmissões ao vivo aos clientes todos os dias. Para garantir que os clientes recebessem conteúdo sem problemas, a Prime Video precisava criar uma ferramenta de monitoramento para identificar problemas de qualidade em cada stream visualizado pelos clientes, o que impunha requisitos de escalabilidade extremamente elevados.
Nesse sentido, a equipe do Prime Video priorizou a arquitetura de microsserviços. Como os microsserviços podem decompor um único aplicativo em vários módulos, isso não apenas resolve o problema do desenvolvimento independente e da implantação de ferramentas, mas também fornece maior disponibilidade, confiabilidade e diversidade técnica para aplicativos. Em última análise, o serviço do Prime Video consiste em três partes: o conversor de mídia envia os fluxos de áudio e vídeo para o buffer de áudio e vídeo do detector; o detector de defeitos executa o algoritmo e envia notificações em tempo real quando os defeitos são encontrados; a orquestração de processos de serviço.
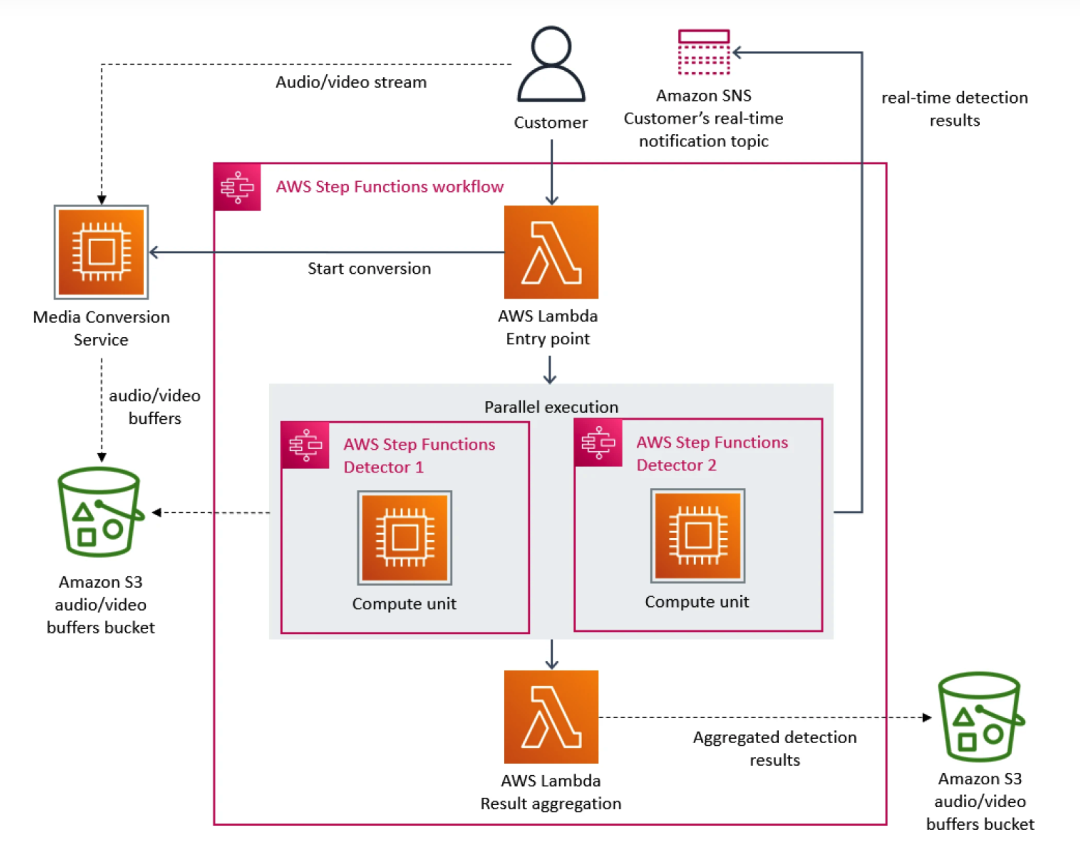 À medida que mais fluxos são adicionados ao serviço, o problema do custo excessivo começa a aparecer. Como o AWS Step cobra dos usuários com base nas transições de estado da função, quando um grande número de fluxos precisa ser processado, a sobrecarga de execução da infraestrutura em escala torna-se muito cara. O custo total de todos os blocos de construção é muito alto, o que impede o Prime Video. equipe de aceitar a solução inicial em grande escala. No final, a equipe do Prime Video reestruturou a infraestrutura e migrou de microsserviços para uma arquitetura monolítica. Segundo seus dados, os custos de infraestrutura foram reduzidos em 90%.
Este incidente também nos tornou mais conscientes de que a arquitetura distribuída também apresenta deficiências em comparação com a arquitetura de serviço único. Por exemplo, a equipe do Prime Video encontrou um problema: a arquitetura distribuída não pode compartilhar variáveis como a arquitetura monolítica, o que faz com que o serviço subjacente lide com mais solicitações iguais, resultando em custos crescentes. Este dilema também existe na arquitetura internacional do iQiyi, especialmente na relação de chamada do mecanismo estratégico.
À medida que mais fluxos são adicionados ao serviço, o problema do custo excessivo começa a aparecer. Como o AWS Step cobra dos usuários com base nas transições de estado da função, quando um grande número de fluxos precisa ser processado, a sobrecarga de execução da infraestrutura em escala torna-se muito cara. O custo total de todos os blocos de construção é muito alto, o que impede o Prime Video. equipe de aceitar a solução inicial em grande escala. No final, a equipe do Prime Video reestruturou a infraestrutura e migrou de microsserviços para uma arquitetura monolítica. Segundo seus dados, os custos de infraestrutura foram reduzidos em 90%.
Este incidente também nos tornou mais conscientes de que a arquitetura distribuída também apresenta deficiências em comparação com a arquitetura de serviço único. Por exemplo, a equipe do Prime Video encontrou um problema: a arquitetura distribuída não pode compartilhar variáveis como a arquitetura monolítica, o que faz com que o serviço subjacente lide com mais solicitações iguais, resultando em custos crescentes. Este dilema também existe na arquitetura internacional do iQiyi, especialmente na relação de chamada do mecanismo estratégico.
2. Relacionamento de chamada do mecanismo de estratégia no exterior iQiyi
2.1 Introdução ao relacionamento de chamada do mecanismo de política
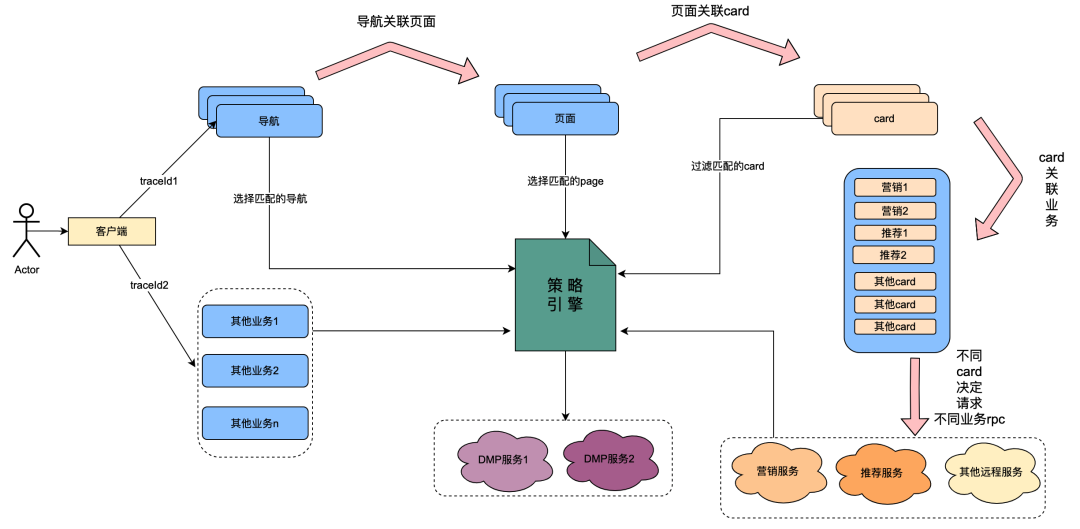
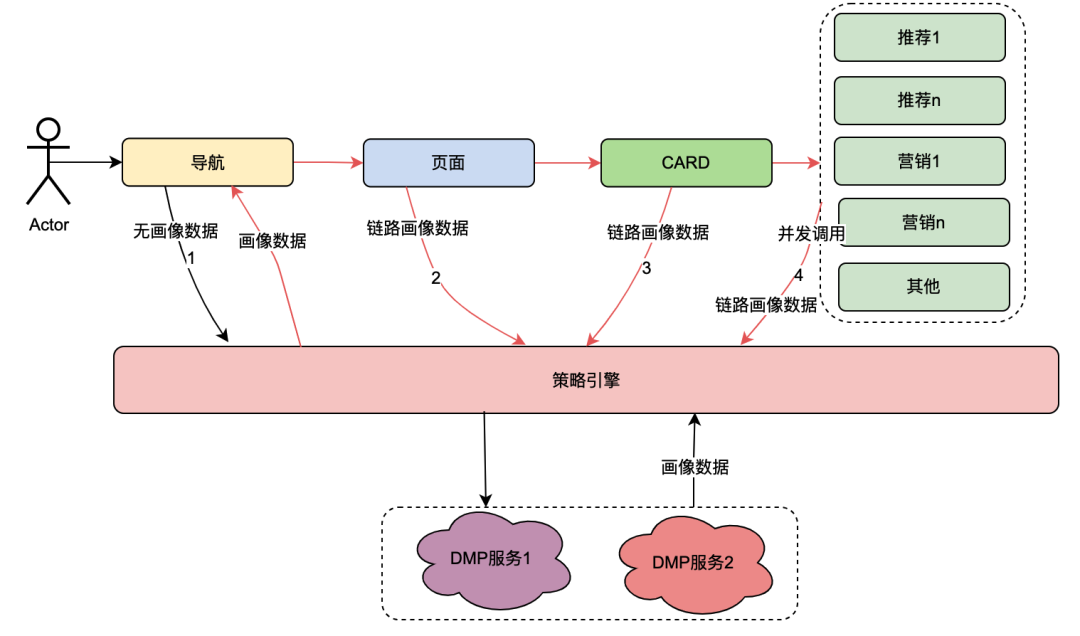
Entre eles, o cartão é o módulo de subdivisão de cada coluna da página. Normalmente colunas como séries de TV e filmes são um único cartão. As fontes de dados em cada cartão são diferentes, como dados de marketing obtidos de marketing, conteúdo obtido de recomendações, conteúdo de programa obtido do Chip, etc. Há um relacionamento de associação. Por exemplo, a página está associada à navegação, o cartão está associado à página e os dados comerciais específicos do cartão estão associados ao cartão.
O mecanismo de política é um serviço de correspondência para identificar grupos de pessoas. Por exemplo, uma política de grupo está atualmente configurada, que contém membros ouro japoneses, homens, dias de expiração de associação inferiores a 7 dias e preferência por anime japonês. O serviço do mecanismo de política pode identificar se um usuário pertence às políticas de grupo acima.
Após a transformação tecnológica do “ vale tudo ”, foi alcançada a capacidade de personalizar as dimensões do perfil do usuário de navegação, páginas, cartões e dados dentro dos cartões. A implementação geral é a seguinte: quando o cliente inicia uma solicitação, ele primeiro solicita a API de navegação. No contexto da configuração dos dados de navegação, os alunos de operações configuraram diferentes dados de navegação e cada dado de navegação foi associado a uma política. A API de navegação obtém internamente todos os dados de navegação e, em seguida, usa a política associada à navegação e o uid do usuário e o ID do dispositivo como parâmetros de entrada para solicitar o mecanismo de política. O mecanismo de política corresponderá e retornará a política correspondente. a navegação com a política que atende aos dados é retornada, realizando assim a capacidade de diferentes retratos de usuários verem diferentes dados de navegação. Páginas, cartões e dados dentro dos cartões são implementados aproximadamente da mesma maneira.
A partir do conteúdo acima, pode-se resumir que o link de chamada do mecanismo de política possui as seguintes características:
(1) Uma operação de abertura de uma página por um usuário chamará vários serviços de mecanismo de política em série.
(2) O desempenho da interface do mecanismo de política afeta diretamente a experiência do usuário: ele associa solicitações para muitos serviços de negócios de páginas.
(3) Os dados do mecanismo de estratégia requerem uma forte natureza em tempo real: depois que um usuário adquire uma assinatura, eles devem ser imediatamente associados às estratégias relacionadas aos membros.
2.2 Dilemas encontrados
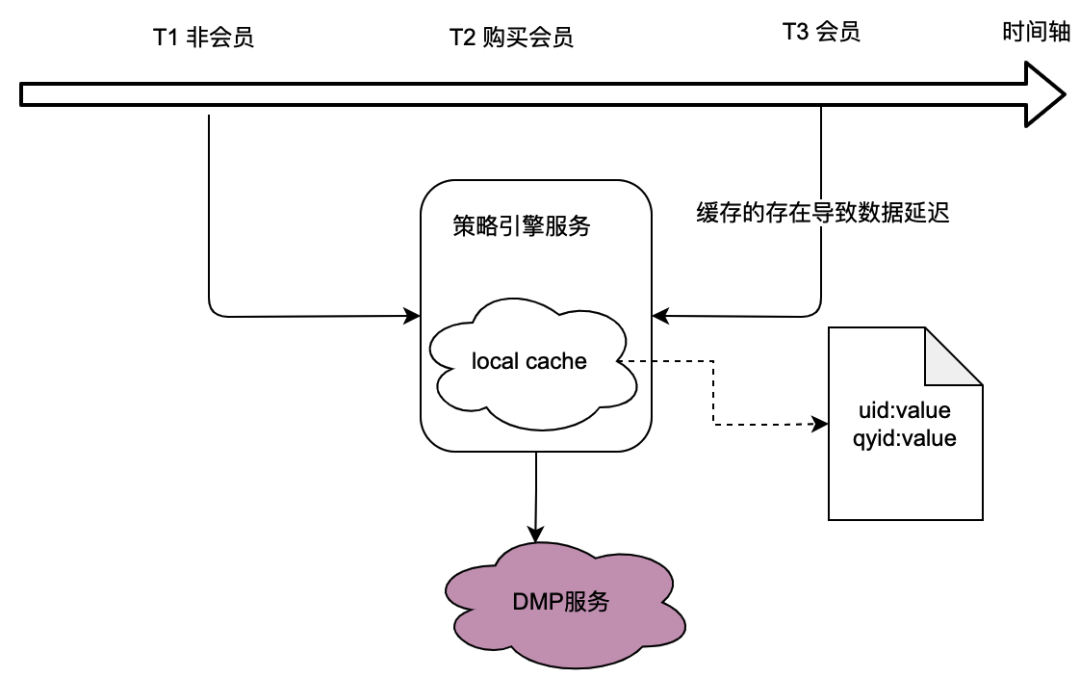
Como pode ser visto no relacionamento de chamada na seção anterior, o mecanismo de política, como serviço subjacente, assume o tráfego de muitas partes comerciais, e o mecanismo de política precisa obter dados de retrato do usuário para determinar se a política de multidão corresponde, o que em por sua vez, depende fortemente do serviço DMP (Data Management Platforms). Para reduzir o tráfego para o serviço DMP, consideramos uma solução de cache local.
No entanto, o problema com isso é óbvio, ou seja, não consegue atender aos requisitos de dados em tempo real . Quando um usuário adquire uma assinatura e os dados de retrato retornados pelo serviço DMP mudam, o usuário não consegue ver os dados mais recentes relacionados à política devido ao atraso no cache local, o que é obviamente intolerável.
Também consideramos soluções de cache distribuído. Se o ID do usuário for usado como chave, o problema será o mesmo do cache local, que não pode atender aos requisitos de tempo real.
Portanto, como otimizar o tráfego para serviços DMP e ao mesmo tempo atender aos requisitos de dados em tempo real é um desafio para a otimização de todo o projeto do mecanismo de política.
O surgimento das variáveis compartilhadas
1. Visão Geral
O cerne do dilema é que os serviços distribuídos não podem compartilhar variáveis. O comportamento de abertura da página de um usuário é acompanhado por múltiplas solicitações de back-end, e os dados de perfil do usuário associados a essas múltiplas solicitações de back-end são na verdade um, ou seja, os dados de perfil obtidos do serviço DMP devem ser os mesmos. A seguir, conduzimos uma análise abstrata do link de chamada do mecanismo de política para ver quais recursos ele possui.
2. Análise do link de chamada do mecanismo de política
O relacionamento de chamada do mecanismo de política foi introduzido no capítulo 1.2.1 Introdução ao relacionamento de chamada do mecanismo de política. Desta vez, classificamos principalmente seus links de chamada.
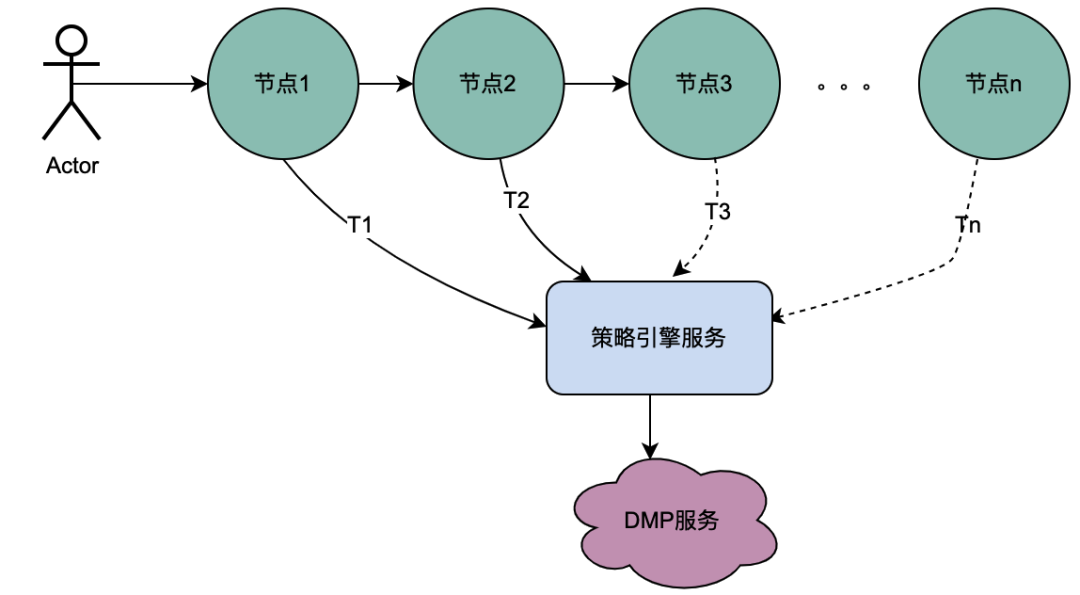
2.1 Cenário de chamada serial
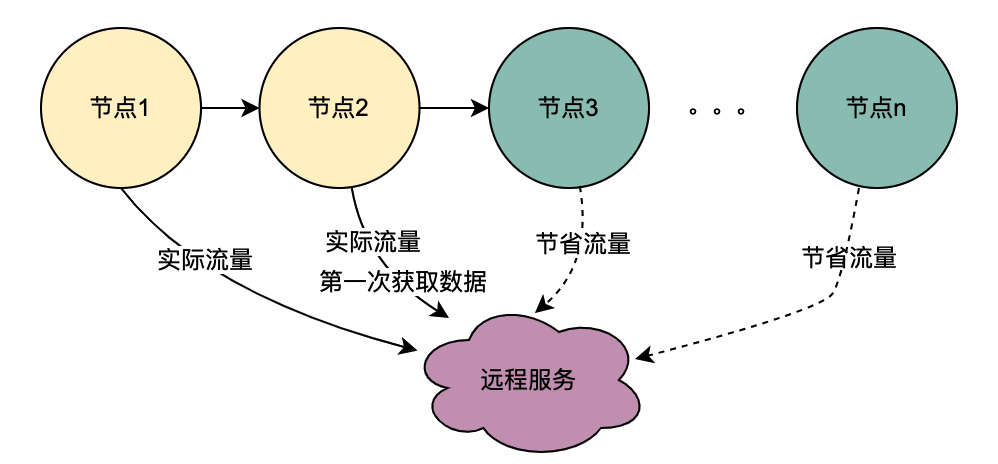
Como você pode ver na figura acima, um usuário inicia uma solicitação e passa por vários serviços de nó. Os serviços de nó estão em um relacionamento serial e cada nó depende do serviço de mecanismo de política. O serviço de mecanismo de política precisa obter o retrato do usuário. data , e obviamente, as solicitações de T1 para Tn são todas do mesmo usuário, e os dados obtidos pelo serviço DMP devem ser os mesmos. o serviço de T1 a Tn pode ser otimizado para 1 solicitação. Chamamos aqui os dados de retrato obtidos do serviço DMP de variáveis compartilhadas distribuídas .
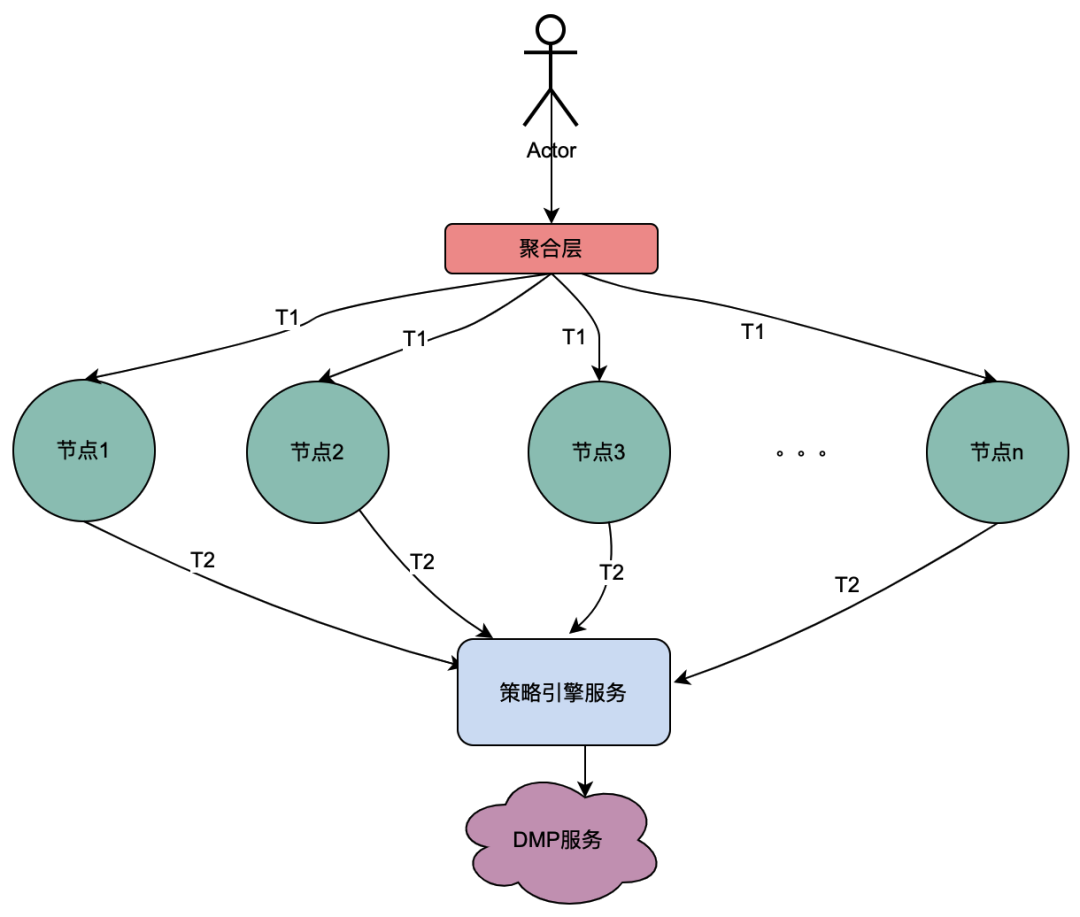
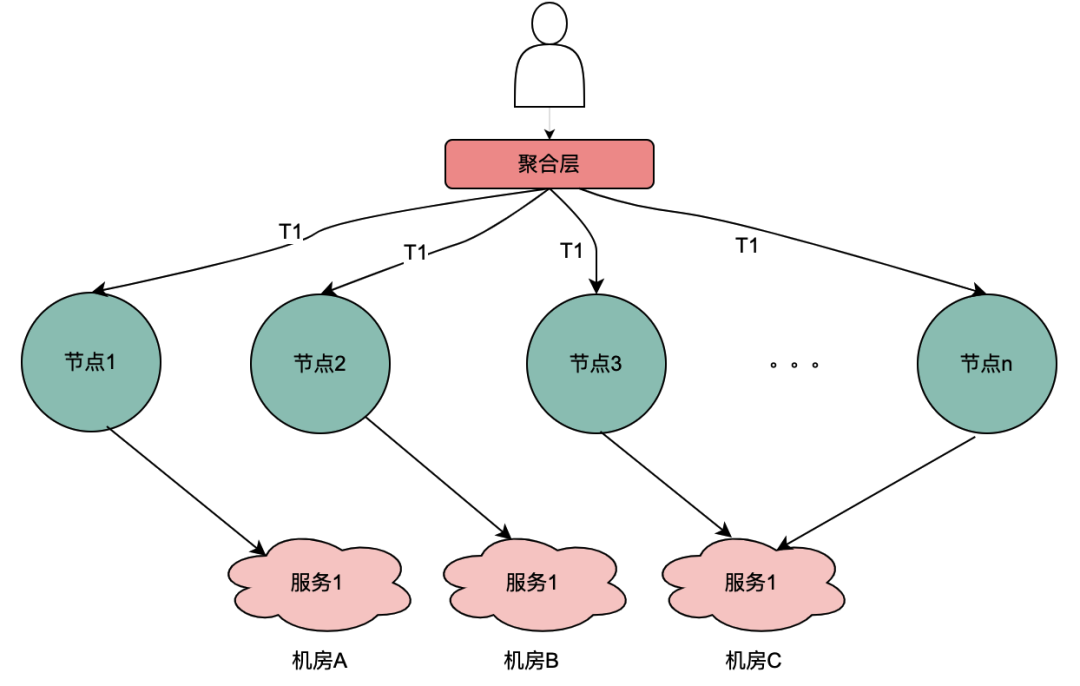
2.2 Cenário de chamada paralela
Diferente da cadeia de chamadas seriais acima, as chamadas seriais T1 a Tn estão em sequência de tempo e a chamada T1 deve ser anterior à chamada T2. Não há sequência de tempo para chamadas paralelas, ou seja, o mesmo usuário pode iniciar uma solicitação, e o negócio da camada de agregação pode iniciar uma solicitação ao serviço dependente ao mesmo tempo, e o serviço dependente depende do mecanismo de política. uma solicitação iniciada pelo mesmo usuário será executada ao mesmo tempo. Faça várias solicitações ao mecanismo de política. Então, se várias solicitações forem colocadas em uma fila, a primeira solicitação realmente solicitará o serviço DMP e as solicitações restantes aguardarão na fila pelos dados da primeira solicitação, n solicitações poderão ser otimizadas em 1 solicitação. Chamamos aqui os dados de retrato obtidos do serviço DMP de variáveis locais compartilhadas .
Introdução às variáveis compartilhadas distribuídas
1. Visão geral do princípio
Quando o usuário abrir a página, o cliente solicitará a navegação e, em seguida, obterá a página de recursos, o cartão específico e os dados do cartão de recursos em sequência. Cada link envolve o serviço do mecanismo de política. Em circunstâncias normais, uma solicitação do cliente acionará diversas chamadas ao mecanismo de política, causando, assim, diversas chamadas ao serviço DMP. Mas obviamente, esta é uma solicitação do mesmo usuário, e os dados de retrato do usuário obtidos por essas solicitações ao serviço DMP devem ser os mesmos.
Com base na análise acima, uma descrição simples do princípio das variáveis compartilhadas distribuídas é que quando [Navigation] obtém os dados do retrato pela primeira vez, ele coloca seu conteúdo no link de solicitação e o transmite de forma semelhante ao TraceId do completo link. Dessa forma, quando o downstream como [Page] solicitar novamente o mecanismo de política, ele poderá obter diretamente os dados do link no contexto do link TraceContext sem solicitar o serviço DMP. Para CARD, o mesmo se aplica ao negócio de páginas.
Vale ressaltar que o TraceContext só pode ser repassado por meio de solicitação. Dessa forma, quando os dados do link são armazenados, os dados do retrato só podem ser colocados no contexto do link TraceContext após [Navigation] obter os dados do mecanismo de política.
如果导航没有关联策略数据,无需请求策略引擎,但是后面的页面、CARD等又关联了策略引擎,那该怎么处理呢?我们参考了TraceId的处理方式,在每个调用策略引擎服务的节点(不同业务如页面、CARD等)进行判断是否有链路数据,如果没有,则获取策略引擎数据后放置进去,如果有则忽略。这样就保证最前置的节点拿到画像数据后,进行向后传递,减少后续节点对于DMP服务的流量。很明显,这些逻辑有一些业务侵入性,所以我们将调用策略引擎的方式优化为SDK调用,在SDK内部做了一些统一的逻辑处理,让业务调用方无感知。
2、全链路追踪 — 基于SkyWalking
skywalking 是分布式系统的应用程序性能监视工具,专为微服务、云原生架构和基于容器化技术(docker、K8s、Mesos)架构而设计,它是一款优秀的 APM(Application Performance Management)工具。skywalking 是观察性分析平台和应用性能管理系统。提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。对于为什么选择skywalking,除去skywalking本身的优势以外,业务上的理由是爱奇艺海外项目目前已经接入SkyWalking,开发成本最低,维护更加便利。所以,使用skywalking传递分布式共享变量只需要引入一个Maven依赖,调用其特有的方法,就可以将数据进行链路传递。
分布式共享变量的方案会增加网络传递数据的大小,增加网络开销;当链路数据足够大的时候甚至会影响服务响应性能。因此控制链路数据大小、链路数据的控制和评估链路数据对网络性能造成影响是尤为重要的。下面将详细介绍。
3、链路传输优化 — 压缩解压缩
3.1 压缩基本原理
目前用处最为广泛的压缩算法包括Gzip等大多是基于DEFLATE,而DEFLATE 是同时使用了 LZ77 算法与哈夫曼编码(Huffman Coding)的一种无损数据压缩算法。其中 LZ77 算法是先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记,依次来缩短字符串的长度。哈夫曼编码主要是用较短的编码代替较常用的字母,用较长的编码代替较少用的字母,从而减少了文本的总长度,其较少的编码通常使用构造二叉树来实现。
3.2 压缩选型
由于BI获取的用户画像TAG固定且个数较少,因此这里选择DMP数据作为实验对比数据。以下是不同场景下压缩大小对比数据

方案3得到的数据最小,因此选择方案3作为分布式共享变量的压缩方案。
4、数据大小导致的网络消耗分析和极端情况控制
4.1 背景概述
这种方案也存在一些弊端,即需要把用户画像数据通过网络传递,显然这增加了网络开销。理论上,网络数据量与传输速度成正比,但是在工程实践中,带宽肯定是有上限的,因此,对于DMP画像数据存入大小进行压测试验,以确定分布式共享变量对于网络性能的影响。
4.2 压测方案
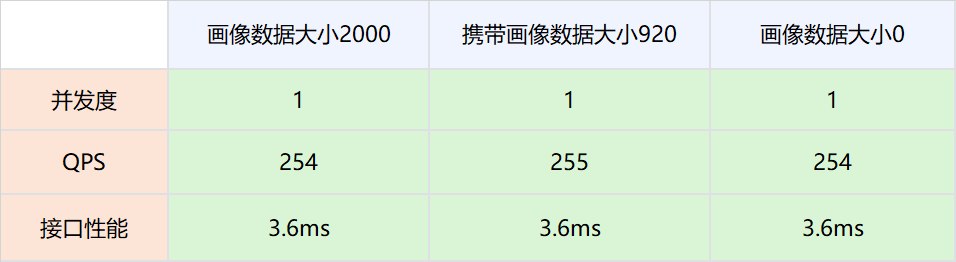
1.测试网络,画像数据不被策略引擎使用,策略引擎依然请求DMP服务。
实验组是请求策略引擎服务的时候带入压缩后的画像数据,对照组是请求策略引擎服务的时候不带入压缩后的画像数据。调整并发值,比较在不同QPS场景下两者的接口性能。
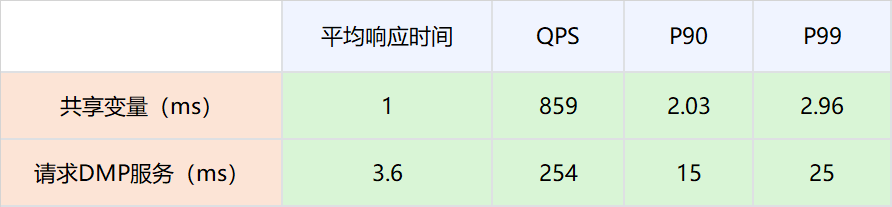
2.分布式共享变量的画像数据被策略引擎使用,策略引擎在有分布式共享变量画像数据的时候,不再请求DMP服务。
4.3结论
-
网络链路上存放数据大小在2000以下,对网络性能的影响可以忽略不计。
-
因为分布式共享变量的存在而减少对DMP服务的请求,接口性能可以有比较大的提升。具体数值为P99从25ms提升到2.96ms。
4.4 极端情况控制
因为DMP数据与用户行为相关,比如一个用户在海外站点所有站点都有购买会员的行为,那么其DMP画像数据就会很大。为了防止这种极端情况所以在判断压缩后的用户画像数据足够大的时候,将自动舍弃,而不是放入网络当中,防止大数据对整个网路数据的性能损耗。
5、线上运行情况
5.1 性能优化
|
|
|
|
|
|
|
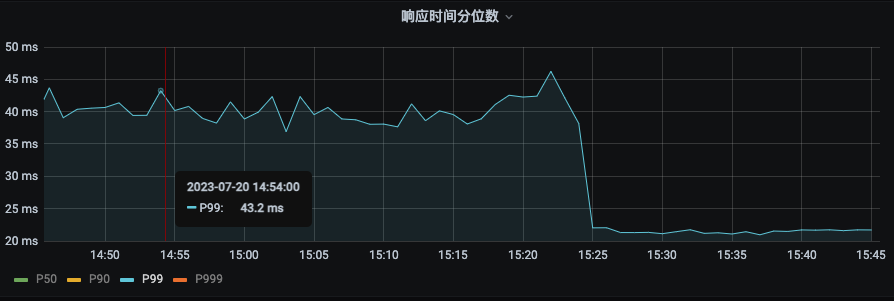
P99 由之前的43ms下降到22ms。下降幅度 48.8%
|
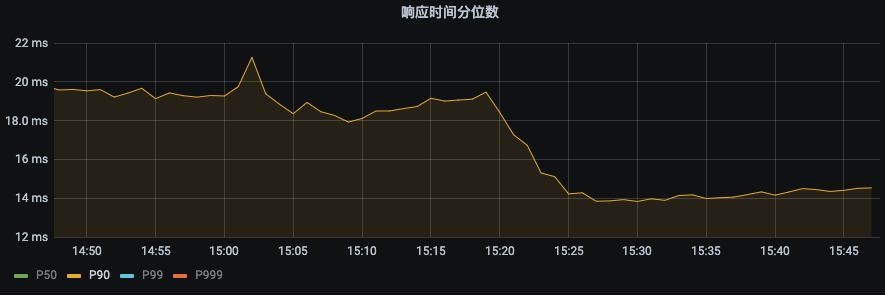
P90由之前19ms下降到14ms,下降幅度26.3%
|
5.2 对DMP服务的流量优化
|
|
|
|
|
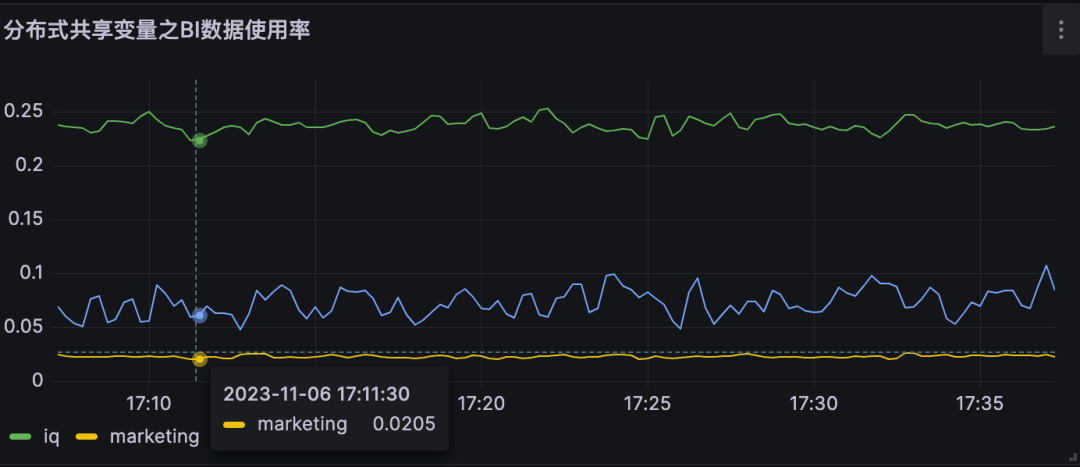
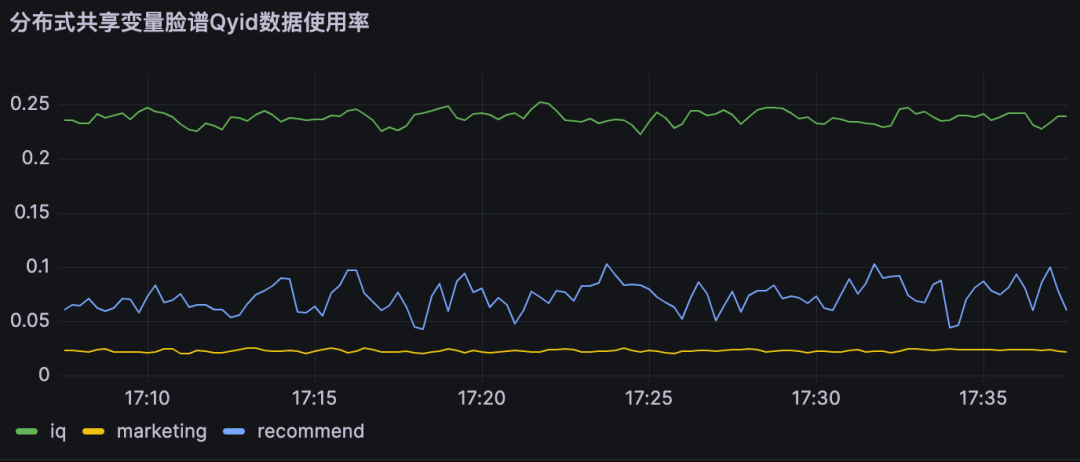
分布式共享变量使用率即为对不同DMP服务优化流量。
A业务节约大约25%的流量,B业务节约约10% 的流量,
|
|
|
|
|
6、结论
分布式共享变量在满足数据实时性要求的前提下,减少了对DMP服务的流量,同时提高了策略引擎服务的接口性能,具体优化指标见上节。
本地共享变量介绍
1、原理概述
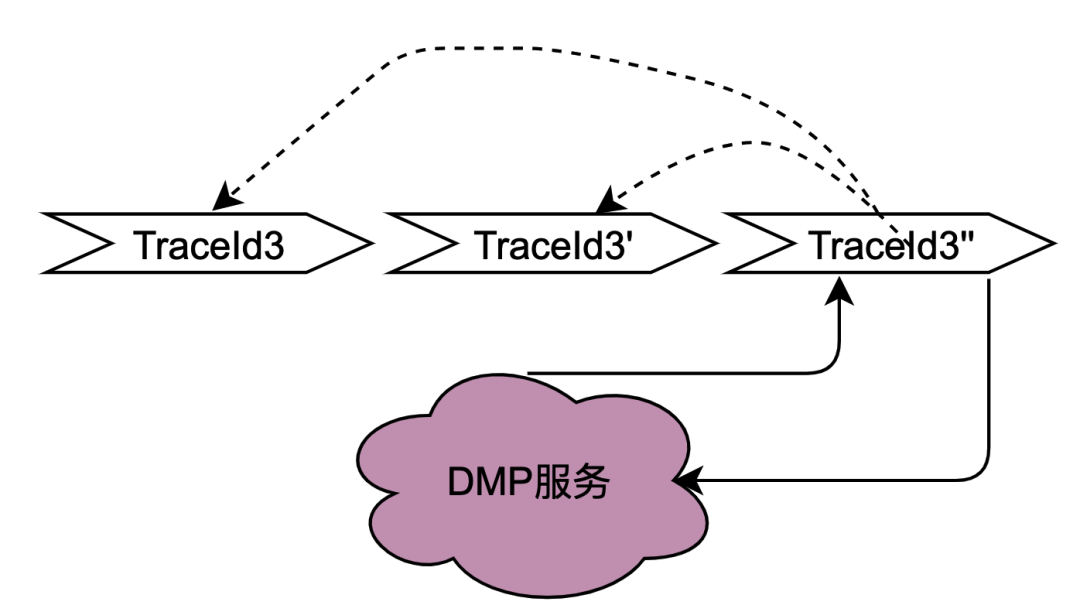
在2.2.2 并行调用场景章节对本地共享变量解决的调用场景进行了阐述,主要解决的是同一个用户并发请求策略引擎带来的多次请求DMP服务问题。如何区分是同一个用户的同一次请求呢?答案是TraceId。在一个请求下,TraceId一定是相同的,如果TraceId相同,那么策略引擎则可以认为是同一个用户的一次请求。
如上图,如果同时多个TraceId3的请求到达策略引擎,将这些请求放入队列,只要其中一个去获取用户画像数据(此处为TraceId3''),其余的请求TraceId3和TraceId3'在队列中等待TraceId3''的结果拿来用即可。
这种思路可以很好的优化并发请求的数据,符合策略引擎调用特性。实现起来有点类似AQS,开发落地有一些难点,比如Trace3''什么时候去请求DMP服务,当拿到数据后,后面仍然有其他trace3进来该如何处理,等待多少时间?这么一思考,这个组件的实现将会耗费我们很多的开发时长,那么有没有现成的中间件可以用呢?答案是本地缓存框架。
无论是本地缓存Caffeine 还是Guava Cache,有相同key的多个请求,只有一个key会请求下游服务,而其他请求会等待拿现成的结果。另外存放的时间可以通过配置缓存的失效时间来确定,至于失效时间的计算方法,将在下面章节会介绍。
2、网关层Hash路由方式的支持
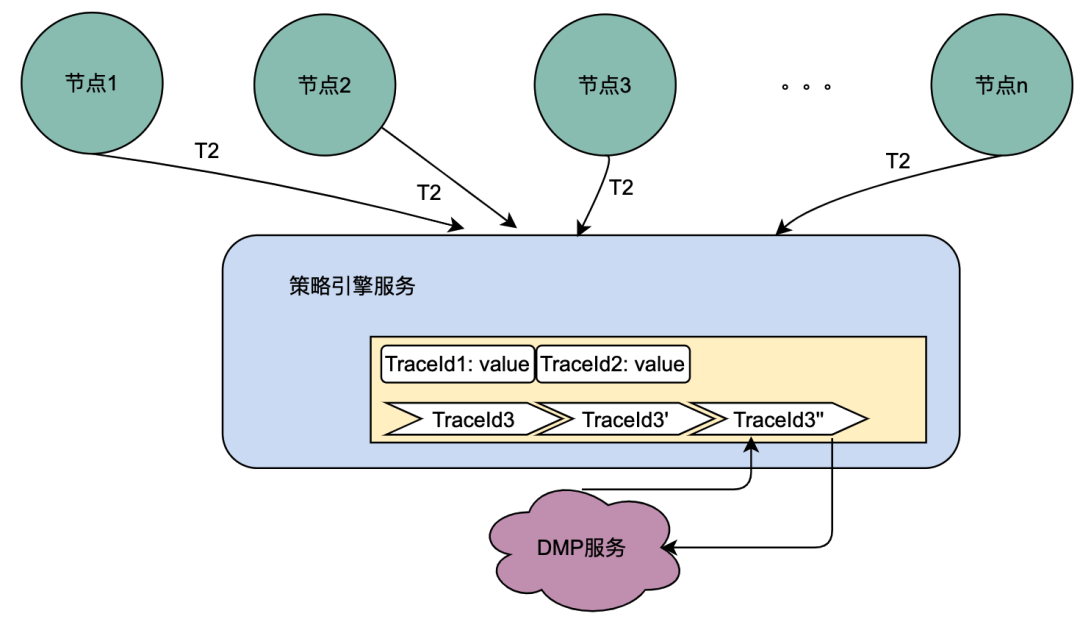
目前,主流的服务一般都是多机房多机器部署,这样有水平扩展能力可以应对业务增长带来的流量增加的问题。但同一个用户的同一个请求,很可能到不同的服务实例,这样上一次获取到的本地缓存数据在下一次请求当中就无法获取。
如上图,同一个用户的同一次请求,被聚合层并发请求到不同业务节点1到节点n。由于策略引擎服务是多实例部署,那么不同节点的请求可能到不同实例,那么本地共享变量的命中率就会大大降低,对DMP服务的流量节约数据就会小很多。因此,需要一个方案使得用户的多次请求能到同一个机房的同一个实例。
最终落地的方案是网关支持按照业务自定义字段Hash路由。策略引擎使用qyid进行hash路由,即同一个设备的所有请求到策略引擎服务,那么路由到的机器实例一定是同一个。这样可以很好的提升本地共享变量的命中率。这里提一下,相比轮询请求,字段Hash方式存在如流量偏移的问题,需要配合服务实例流量的监控和报警,避免某些实例流量过多而导致不可用。由于和本次主题无关,实例流量的监控和报警在这里就不做介绍。
3、本地共享变量个数和有效时间设计
和本地缓存不同,本地共享变量的最大个数和过期时间与命中率不成正比,这和具体业务指标相关。
假设策略引擎服务QPS10000,服务实例有50台,那么每台实例的QPS是200,即一台服务实例每秒的请求是200个。只需要保证,同一个TraceId的一批请求,在个数区间内不被淘汰,在时间区间内不被过期即可。我们通过网关日志查找历史上同一个traceId的请求时间戳,几乎都在100ms内。
那么过期时间设置为1s,最大个数设置为200个就可以保证绝大多数同一个TraceId的批次请求,只有一个请求下游服务,其余从缓存获取数据。我们为此也进行了实验,设置不同的过期时间和缓存最大个数,结论和以上分析完全一致。
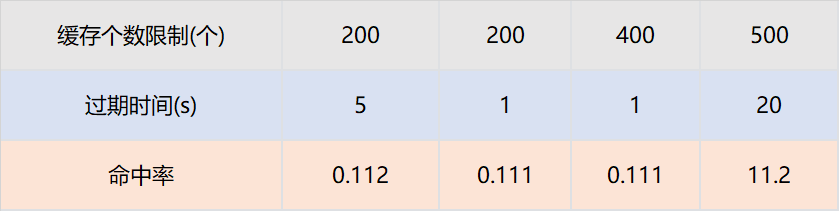
本地共享变量命中率与接口QPS和相同TraceId并发时间相关。
4、结论
-
对于DMP服务1,优化流量15.8%。对于DMP服务2,优化流量 16.7%。对于DMP服务3,优化流量16.2%。
-
与分布式共享变量一样,本地共享变量同样可以满足数据实时性要求,即不会存在1.2.2 遇到的困境 所遇到的缓存导致的数据实时性不够的问题。
总结和展望
本次优化是比较典型的技术创新项目。是先从社区看到一篇技术博客,然后想到爱奇艺海外遇到相同痛点问题的的项目,从而提出优化因为微服务导致的策略引擎对于DMP服务流量压力的目标。
在落地过程中,遇到使用本地缓存进行优化而无法克服数据实效性问题的挑战。最终沉下心分析策略引擎的调用链路,将调用链路一分为二:串行调用和并行调用,最终提出了共享变量的解决方案。因为串行调用和并行调用的特点迥异,依次针对两者进行分期优化,其中第一期通过分布式共享变量优化了串行调用DMP服务的流量,在第二期通过本地共享变量优化了并行调用DMP服务的流量。
参考文章:

也许你还想看
低代码、中台化:爱奇艺号微服务工作流实践
揭秘内存暴涨:解决大模型分布式训练OOM纪实
分布式系统日志打印优化方案的探索与实践
本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Origin my.oschina.net/u/4484233/blog/10924140