No desenvolvimento moderno de aprendizagem profunda, geralmente contamos com outros módulos para construir sistemas de software complexos, como blocos de construção. Esse processo costuma ser rápido e eficaz. No entanto, como localizar e resolver problemas rapidamente ao encontrá-los sempre preocupou os projetistas e mantenedores de sistemas de aprendizado profundo devido à complexidade e ao acoplamento do sistema.
Como membro da equipe técnica de back-end do iQiyi, registramos detalhadamente o processo de resolução de problemas relacionados à memória do treinamento de aprendizagem profunda, na esperança de fornecer alguma inspiração aos colegas que estão trabalhando duro para resolver problemas espinhosos.
fundo
No último trimestre, observamos fenômenos aleatórios de OOM de memória de CPU no cluster A100. Com a introdução do treinamento de grandes modelos, o oom tornou-se ainda mais insuportável, o que nos deixou determinados a resolver esse problema.
Olhando para trás, para o lugar de onde vim, de repente me senti iluminado. Na verdade, já estivemos muito perto da verdade do problema, mas faltou-nos imaginação suficiente e não a percebemos.
processo
No início, realizamos uma análise indutiva dos registros históricos. Foram descobertas diversas regras que têm um significado orientador muito bom para a solução final:
-
Este é um problema novo encontrado no cluster A100 e não foi encontrado em outros clusters.
-
O problema está relacionado ao treinamento distribuído ddp do pytorch; outros modos de treinamento usando pytorch não foram encontrados.
-
Este problema de OOM é bastante aleatório, alguns ocorrem dentro de 3 horas e outros só ocorrem depois de mais de uma semana.
-
O pico de memória ocorre durante o OOM, basicamente completando o aumento de 10% a 90% em 1 minuto e meio, conforme mostrado na figura abaixo:
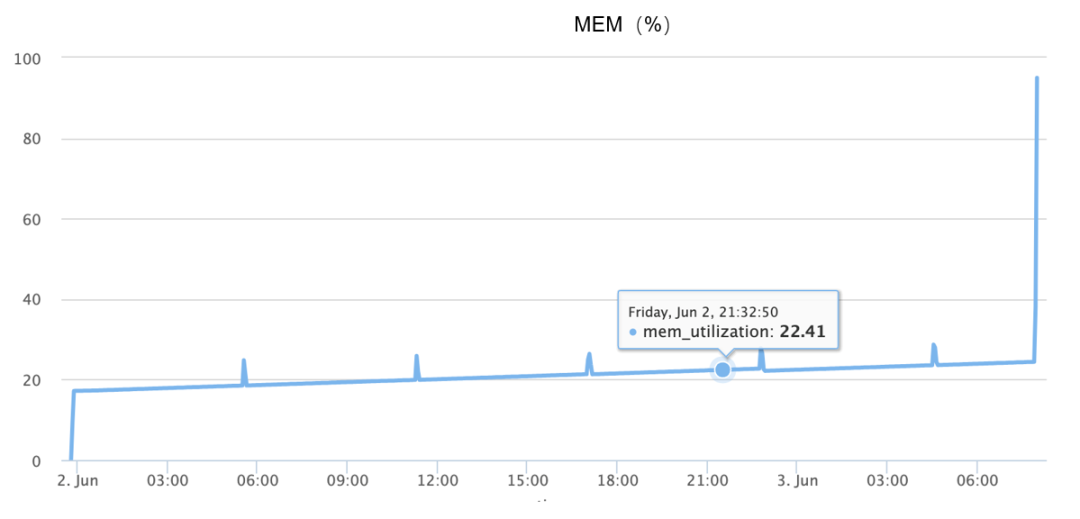
Embora as informações acima estejam disponíveis, uma vez que o problema não pode ser reproduzido de forma confiável, no início confiei inteiramente na imaginação divergente e adivinhei muitas causas possíveis, tais como:
-
Poderia ser um problema de código, porque o objeto não é reciclado, causando vazamentos contínuos de memória?
-
Poderia ser um problema com o alocador de memória subjacente, semelhante ao fato de que o alocador PTMALLOC da glibc tem muitos fragmentos, então, em um determinado momento, solicitações repentinas de memória levam à alocação contínua de memória?
-
Poderia ser um problema de hardware?
-
Poderia ser um bug em uma versão específica do software?
Abaixo apresentamos as duas primeiras suposições em detalhes.
-
É um problema com o código?
Para determinar se é um problema de código, adicionamos código de depuração à cena onde o problema ocorreu e o chamamos periodicamente. O código a seguir imprimirá todos os objetos que não podem ser reciclados pelo módulo python gc atual.
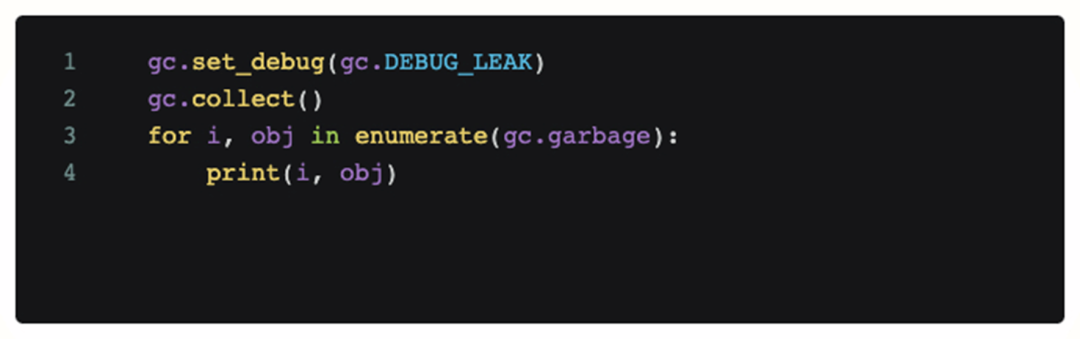 No entanto, após adicionar este código, a análise de log obtida mostra que não há nenhum objeto inacessível que ocupe muita memória durante o OOM, e o gc contínuo não pode aliviar o próprio OOM. Então neste ponto nosso primeiro palpite está falido, o problema não é causado pelo código (vazamento de memória).
No entanto, após adicionar este código, a análise de log obtida mostra que não há nenhum objeto inacessível que ocupe muita memória durante o OOM, e o gc contínuo não pode aliviar o próprio OOM. Então neste ponto nosso primeiro palpite está falido, o problema não é causado pelo código (vazamento de memória).
-
Isso é causado pelo alocador de memória?
Nesta fase, introduzimos o alocador de memória jemalloc Em comparação com o PTMALLOC padrão da glibc, sua vantagem é que ele pode fornecer uma alocação de memória mais eficiente e melhor suporte para depuração da própria alocação de memória.
-
Poderia ser um problema com o alocador de memória padrão?
-
Melhores ferramentas de depuração e análise
Para visualizar diretamente o status atual do jemalloc em python sem modificar o código da tocha em si, usamos ctypes para expor a interface jemalloc diretamente em python:
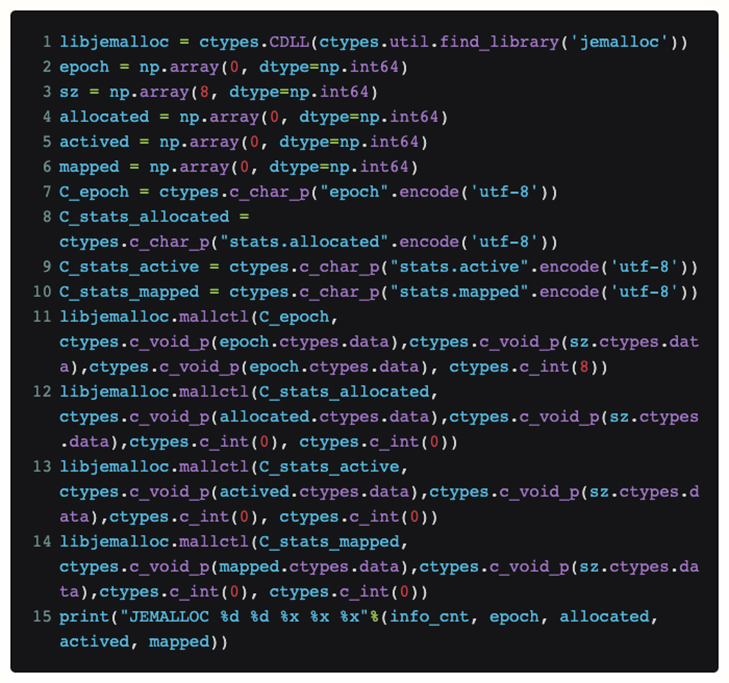
Desta forma, se colocarmos este código em uma função, podemos saber periodicamente a solicitação [alocada] atualmente recebida por jemalloc da camada superior, e o tamanho real da memória física [mapeada] que ela solicita do sistema.
Após o próprio processo de reprodução, foi finalmente constatado que os dois valores alocados e mapeados estão muito próximos quando ocorre OOM. Portanto, a nossa hipótese sobre a fragmentação da memória vai à falência.
-
O que exatamente causou o problema?
Quando estávamos no fim da linha, mais uma vez classificamos os registros OOM existentes e descobrimos que havia uma direção que não havia sido focada antes: ou seja, tínhamos várias máquinas operando em momentos semelhantes (1-2 minutos adjacentes) várias vezes) OOM ocorre.
Então, que explicação lógica existe para esta sincronicidade mágica? Bugs comuns não devem fazer com que tal coerência ocorra novamente. Portanto, pode haver alguma conexão inevitável entre eles.
Então de onde vem essa correlação? Para explorar esta questão, a perspectiva analítica muda para a comunicação em rede na formação distribuída.
A suspeita inicial sobre a comunicação estava focada em máquinas que experimentavam OOM. Suspeitava-se que elas estavam se comunicando por algum motivo, o que causaria problemas entre si. Portanto, o tcpdump foi adicionado ao treinamento diário para monitorar o tráfego da rede.
Finalmente, depois de ingressar no tcpdump, detectei a comunicação mais questionável durante um OOM. Ou seja, a máquina OOM recebeu tráfego de verificação de segurança alguns minutos antes de o problema ocorrer.
posicionamento final
Depois de detectar a equipe de segurança verificando o objeto suspeito, colaboramos com a equipe de segurança para realizar a análise e, finalmente, descobrimos que o problema de OOM poderia ser reproduzido de forma estável com base na verificação, de modo que a causa desencadeadora era quase certa. No entanto, neste ponto, só podemos reproduzir e alterar a estratégia de verificação de segurança para evitar o problema de OOM. Também precisamos analisar melhor o código e finalmente localizá-lo.
Depois de analisar e posicionar o código, foi finalmente determinado que o problema está no protocolo de treinamento distribuído DDP do pytorch. O código relevante é o seguinte:
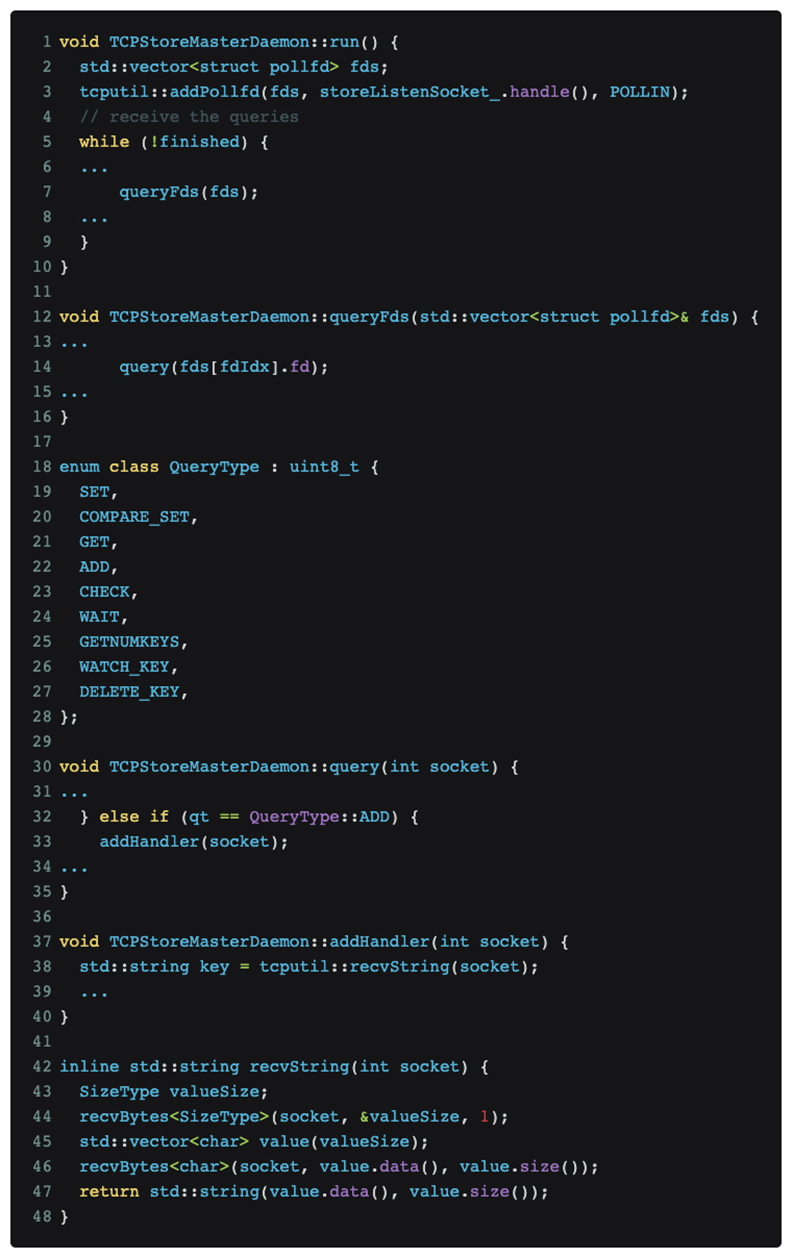
Conforme mostrado na figura acima, o treinamento distribuído pytorch continua escutando mensagens na porta mestre.

A varredura do Nmap [nmap -sS -sV] acionou o tipo de mensagem QueryType::ADD, que é o número da caixa verde [03] na parte de dados mostrada na imagem tcpdump acima, o que fez com que o pytorch tentasse usar o recvString função para pré-alocar um buffer para receber o que considera mensagens de acompanhamento. Mas esse comprimento de buffer é analisado usando um tipo uint64_t[little-endian] após [03], que é o número da caixa vermelha [e0060b0000], que é 962174058496 bytes. Este valor significa que os dados 1T serão recebidos e pytorch. will Depois que o alocador de memória solicitar a memória correspondente, o alocador de memória solicitará ainda a página física correspondente do kernel. Como nosso cluster de treinamento de GPU não está configurado com uma tabela de páginas enorme, o Linux só pode satisfazer gradualmente a solicitação de memória de 1T do alocador de memória em interrupções faltantes de página de acordo com a granularidade de 4K, o que significa que leva cerca de 1 minuto para alocar toda a memória, e O A OOM observada anteriormente provavelmente ocorre em resposta ao rápido crescimento da memória de cerca de 1 minuto.
solução
Depois de conhecer a causa e o efeito, a solução torna-se natural:
1. Curto prazo: alterar a política de verificação de segurança para evitar
2. Longo prazo: comunique-se com a comunidade para fortalecer a robustez [ 1 ]
Resumir
Depois de concluir o retrocesso do processo de investigação de problemas de OOM, descobrimos que, durante esse processo, havíamos conduzido uma rodada eficaz de testes em ferramentas relacionadas à memória e métodos de depuração.
Durante esse processo, descobrimos que existem alguns pontos comuns que podem ser usados como referência em pesquisas e desenvolvimento subsequentes:
-
Jemalloc pode fornecer uma análise quantitativa muito eficaz de problemas de memória e pode capturar problemas subjacentes relacionados à memória em sistemas de programação híbridos, como python+C.
-
Memray. Tínhamos grandes expectativas durante o processo de depuração, mas no final descobrimos que a área onde o memray pode ter melhor desempenho ainda é no lado do python puro e não é capaz de sistemas de programação híbridos como o pytorch DDP.
Às vezes ainda precisamos pensar nos problemas de uma dimensão maior. Por exemplo, se o processo de comunicação com serviços externos não relacionados não for incluído na consideração, a verdadeira causa raiz não será descoberta.
Talvez você também queira ver

