
Bem-vindo ao relatório de atualização de recursos do produto Kangaroo Cloud 09. Neste relatório, aderimos ao conceito de igual ênfase na inovação e otimização e realizamos um polimento profundo e uma atualização abrangente do produto. A melhoria de cada detalhe é a nossa busca incessante pela excelente qualidade. Esperamos que essas novas funções possam ajudar nas operações e no desenvolvimento do seu negócio, tornando o caminho para a transformação digital mais tranquilo.
A seguir está o conteúdo do Relatório de atualização de função do produto Kangaroo Cloud, edição 09. Para mais exploração, continue lendo.
Plataforma de desenvolvimento off-line
Novas atualizações de recursos
1. Modelo de tarefa
Histórico: os clientes esperam manter off-line os modelos de código comuns diários e referenciá-los diretamente durante o desenvolvimento de dados.
A diferença entre modelos e componentes:
1. A edição é suportada após a referência do código do modelo, mas a edição não é suportada após a referência do componente.
2. As alterações no modelo não afetarão as tarefas referenciadas, mas as alterações nos componentes afetarão as tarefas referenciadas.
Descrição do novo recurso: oferece suporte a modelos de código de projeto e modelos de código de locatário para cada tipo de tarefa e oferece suporte a modelos de código de referência ao criar tarefas .
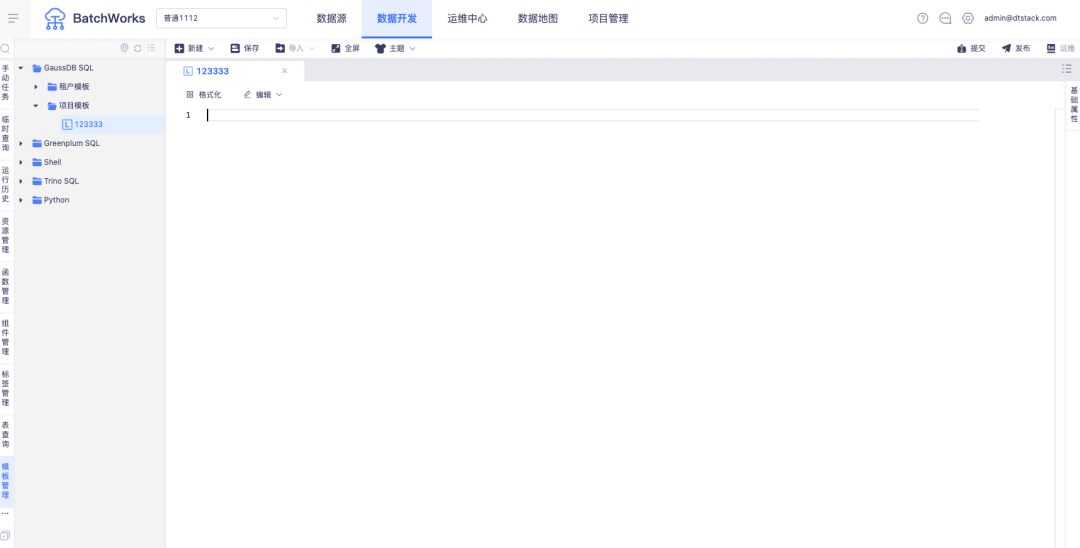
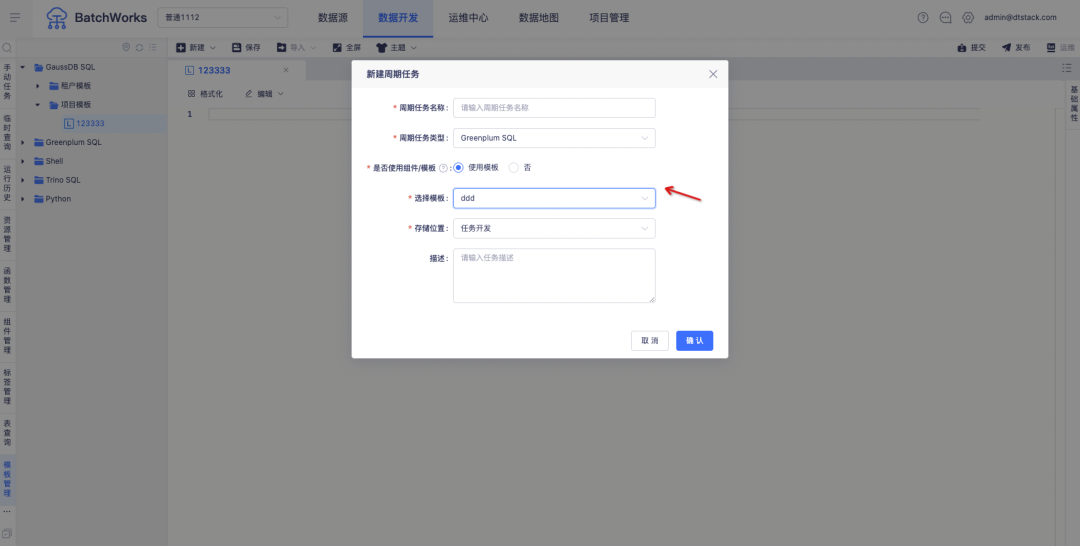
2.shell no agente/python no agente adiciona novo controle de dimensão do projeto
fundo:
Shell on Agent é um tipo de tarefa especial para plataformas offline.
A tarefa Shell não é executada diretamente na máquina implementada no cluster, mas o Shell é executado em um nó de servidor implementado de forma independente. Como uma tarefa offline requer dois núcleos, se houver muitas tarefas Shell no cenário do cliente, será fácil preencher os recursos do cluster . Portanto, executar tarefas como Shell e Python em nós implantados de forma independente pode reduzir efetivamente a pressão sobre o cluster.
Atualmente há um problema. Desde que o cliente configure o nó e o usuário do servidor no EM e no console, todos os projetos no cluster poderão usar o nó configurado e o usuário do servidor. Por exemplo, para usuários com permissões altas como root, os clientes prestam mais atenção às questões de segurança e não querem que todos os projetos possam usar esta conta. Portanto, é necessário projetar uma solução que possa controlar a configuração dos nós do servidor. e usuários do servidor para resolver este problema.
Descrição dos novos recursos:
1. O console controla as permissões de usuário do nó e do servidor por meio da autorização do projeto.
2. As tarefas em projetos off-line oferecem suporte à seleção de nós de servidor e usuários autorizados.
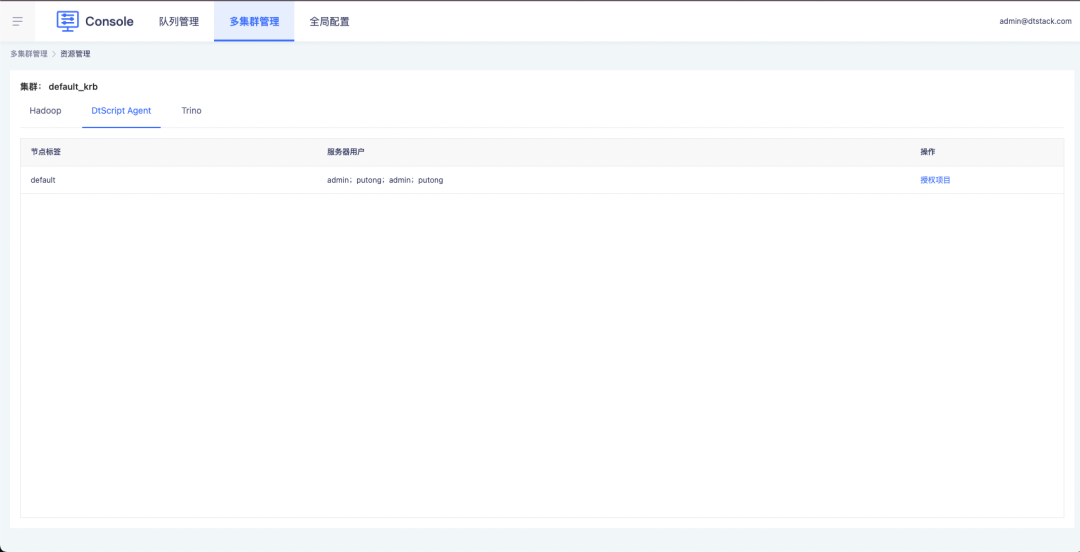
Otimização de função
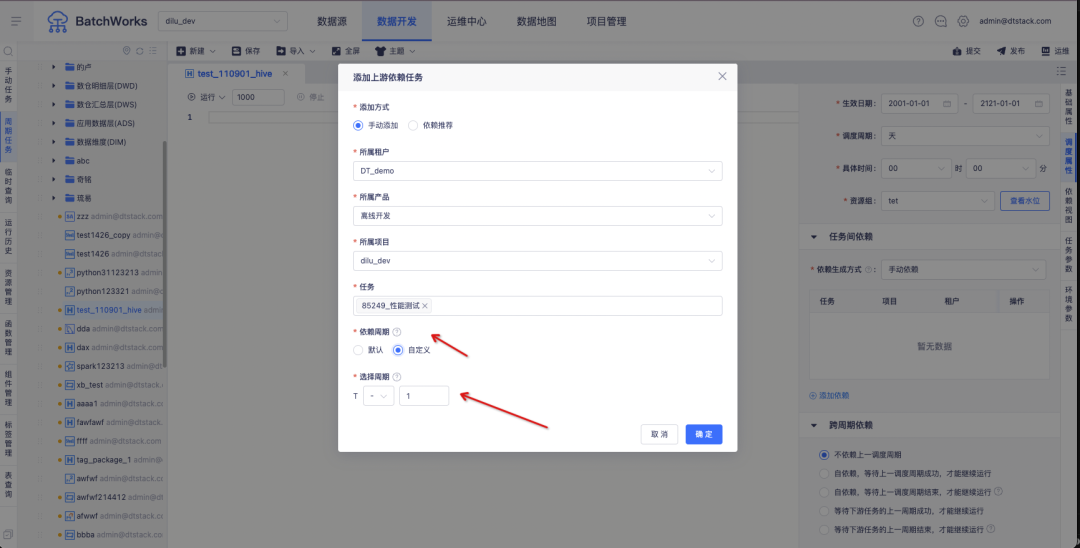
1. Agendamento de otimização de configuração, que pode controlar qualquer instância periódica que dependa de tarefas upstream
fundo:
Atualmente, o agendamento de tarefas Zhongtian só pode contar com a instância upstream do ciclo atual por padrão. Os clientes podem ter os seguintes cenários:
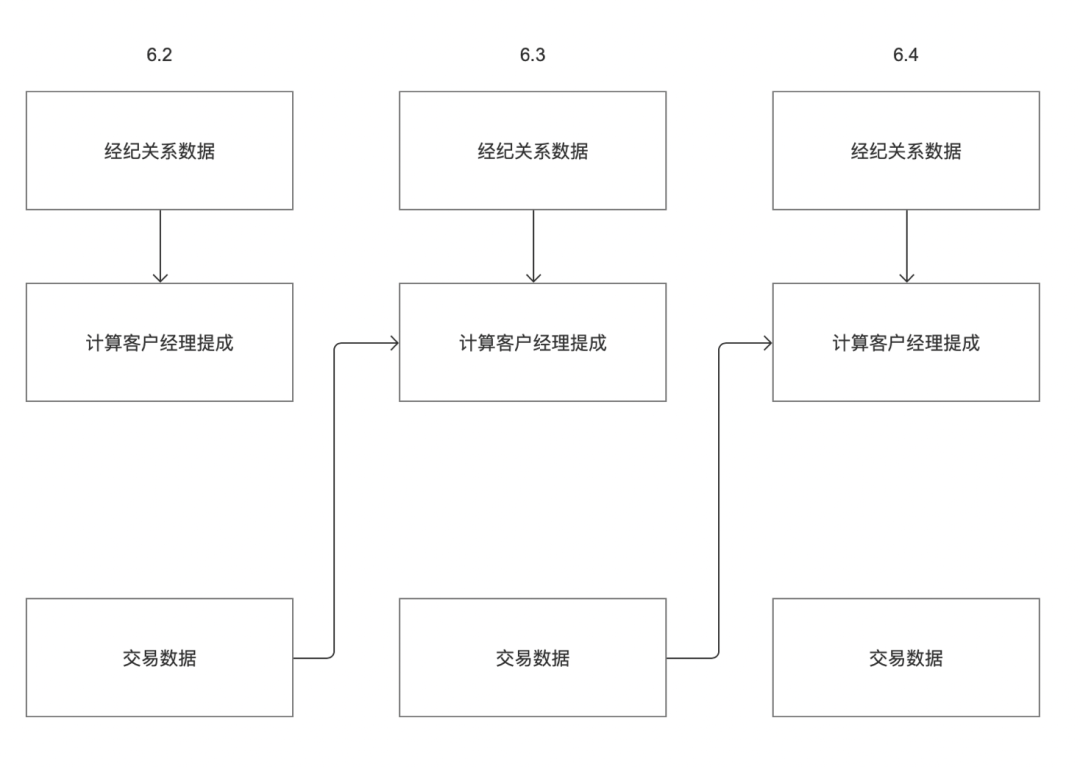
Por exemplo, um cliente tem dois sistemas de negócios "dados de relacionamento de corretagem" e "dados de transação". A comissão do cliente em 3 de junho precisa ser calculada com base nos "dados de relacionamento de corretagem" e "dados de transação", respectivamente. Como mostrado na figura acima, o horário de saída dos dados do sistema de negócios de "dados de relacionamento de corretagem" em 2 de junho é 3 de junho, o horário de saída de dados do sistema de negócios de "dados de transação" em 2 de junho é a noite de 2 de junho;
De acordo com a atual lógica de dependência offline upstream e downstream, a tarefa "Calcular Comissão do Gerente de Contas" só pode obter tarefas em 3 de junho, mas não pode obter tarefas em 2 de junho. pode ser ciclo personalizado.
Instruções de otimização de experiência:
Oferece suporte à personalização do ciclo de agendamento de tarefas upstream dependentes .
T representa o tempo planejado da tarefa atual (tarefa downstream), "+ -" representa a direção do deslocamento, "+" representa o deslocamento de tempo para o futuro, "-" representa o deslocamento de tempo para o passado e "-" é selecionado por padrão.
O deslocamento é uma caixa de entrada numérica com valor máximo de 10 e valor mínimo de 1, que representa o número de ciclos de tarefa upstream do deslocamento.
Plataforma de desenvolvimento em tempo real
Novas atualizações de recursos
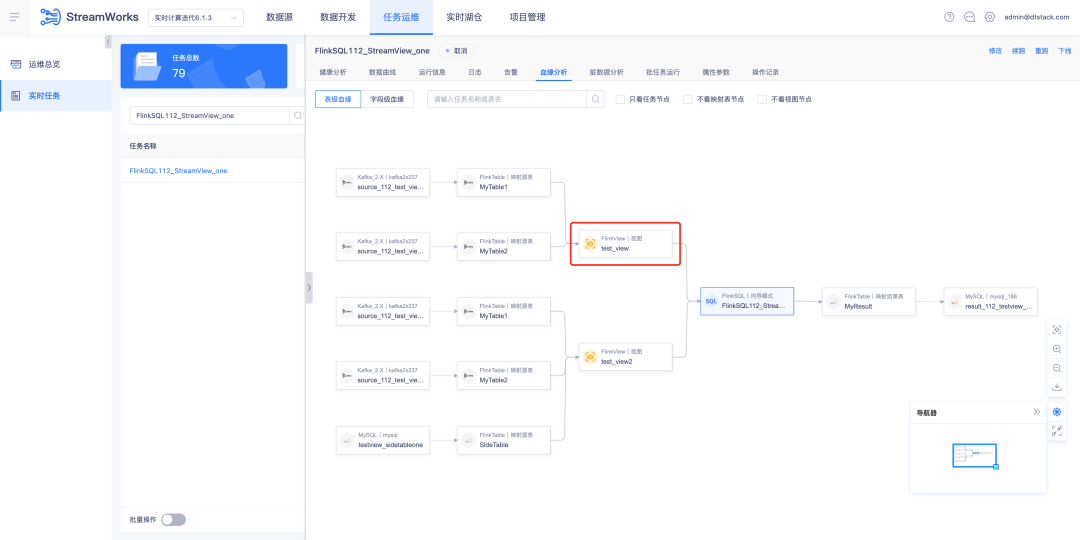
1. Veja a análise da linhagem sanguínea
Histórico: Atualmente, o SQLParser não oferece suporte à análise de linhagem de visualizações do FlinkSQL. No entanto, em cenários gerais de desenvolvimento, se a tarefa envolver mais de três tabelas, muitas reuniões optam por construir visualizações no IDE para facilitar a leitura da lógica SQL.
Função:
1. SQLParser suporta tabela de visualização FlinkSQL para exibir análises de parentesco sanguíneo
2. Operação e manutenção de tarefas - tarefas em tempo real - detalhes da tarefa FlinkSQL - função de exibição de análise de linhagem
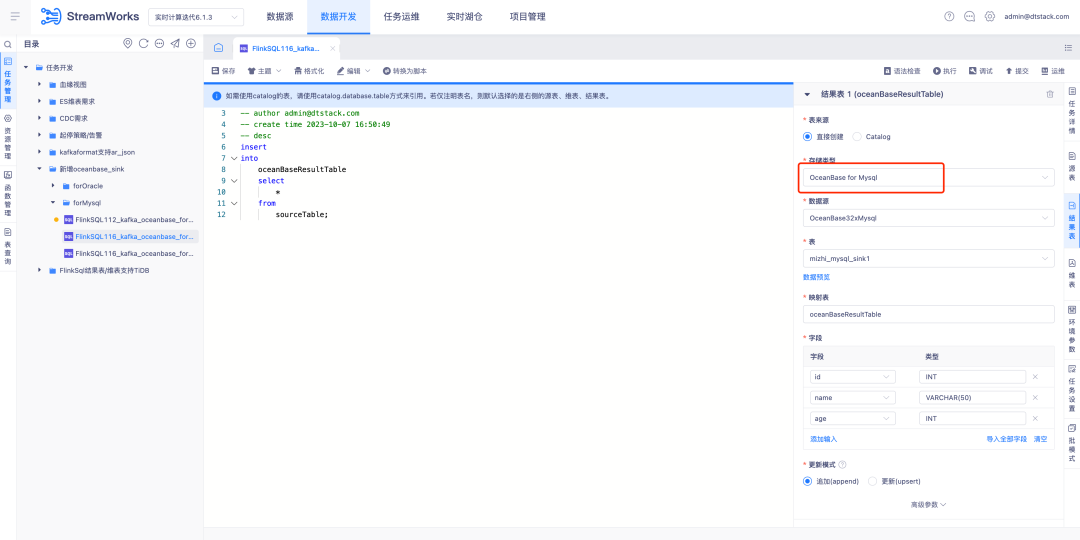
2.FlinkSQL suporta Oceanbase Sink
O FlinkSQL versão 1.16 suporta tabelas de resultados OceanBase e é compatível com os modos MySQL e Oracle do OceanBase versão 4.2.0, fornecendo aos usuários recursos de processamento de dados mais flexíveis e eficientes.
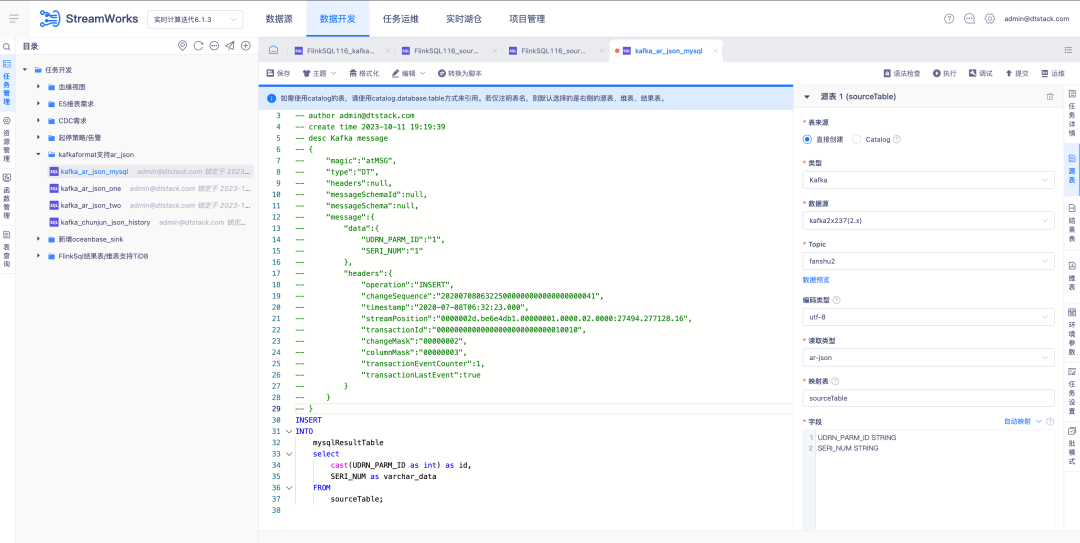
3. O tipo de leitura Kafka da tabela de origem suporta AR Json
Antecedentes: OGG e Attunity Replicate são dois produtos comerciais amplamente utilizados no exterior. Para melhor atender às necessidades dos clientes, precisamos garantir que o formato JSON do Kafka seja compatível com o tipo de leitura AR Json.
Descrição do novo recurso: Tabela de origem da versão FlinkSQL1.16 O tipo de leitura Kafka suporta o tipo AR Json e suporta funções relacionadas ao mapeamento automático para analisar Json.
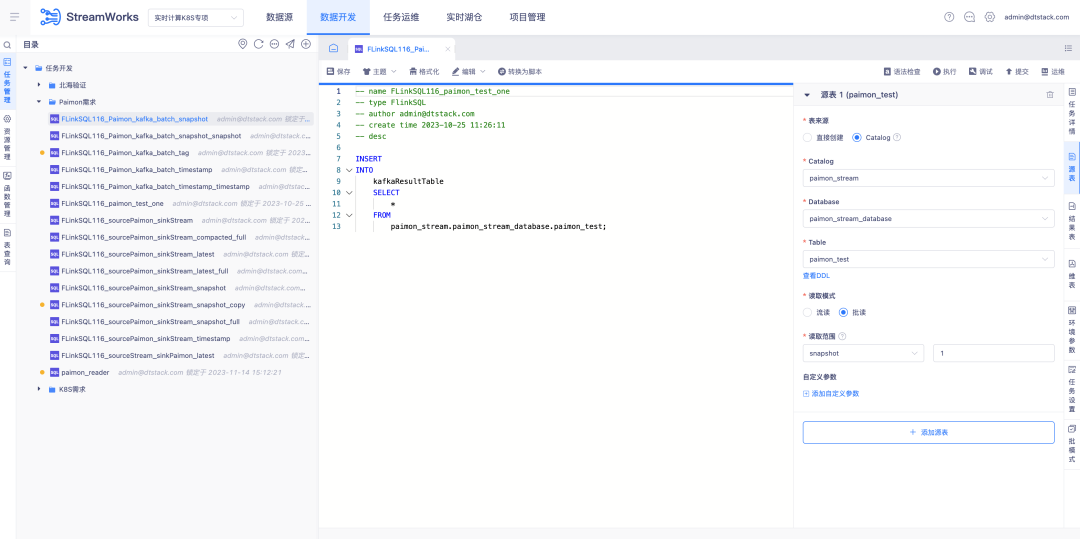
4. Suporte Paimon para armazém em lago em tempo real
Antecedentes: Com o desenvolvimento do Paimon, um novo modelo de desenvolvimento FlinkSQL precisa ser iterado desta vez. Usando este modelo, o módulo de gerenciamento de armazém do lago pode ser interligado em toda a cadeia.
Descrição dos novos recursos:
1. O gerenciamento do Lake Warehouse adiciona a capacidade de adicionar, excluir, modificar e consultar tabelas Paimon
2. Adicione a função de configuração visual da tabela Paimon à plataforma de desenvolvimento de dados.
3. A plataforma de desenvolvimento de dados usa o IDE para completar as funções de leitura e escrita da tabela Paimon.
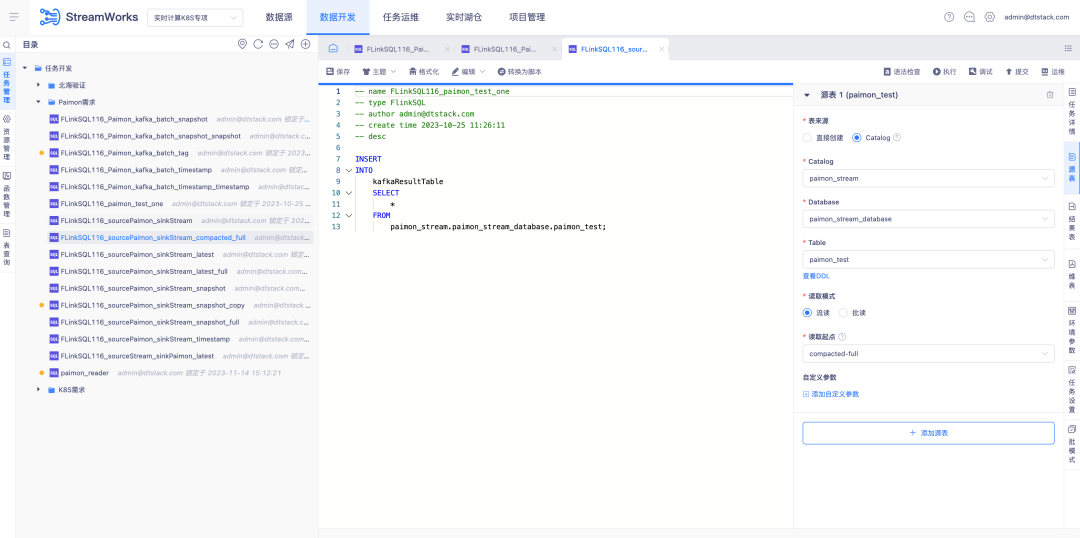
5.FlinkSQL FlinkCDC integrado
Antecedentes: FlinkCDC é um componente de coleta em tempo real de código aberto com velocidade de iteração muito rápida. A estrutura Flink subjacente na qual ele se baseia também é a mesma que a estrutura ChunJun que usamos. Portanto, consideramos torná-lo um componente padrão para implantação de plataforma em tempo real e empacotá-lo em nosso sistema.
Descrição dos novos recursos:
1. Pacote de implantação padrão em tempo real, configure a coleta em tempo real do FlinkCDC
2. Modo de script de plataforma, você precisa verificar os recursos de coleta integrados do FlinkCDC e os conectores suportados
3. O modo assistente de plataforma configurará a coleção de conectores suportada pelo FlinkCDC de acordo com a situação do projeto.
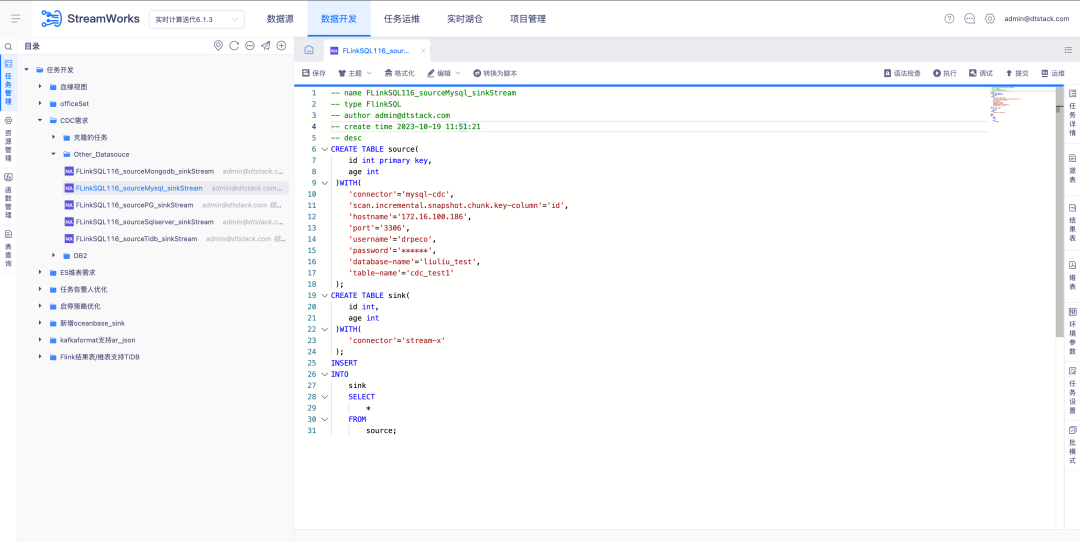
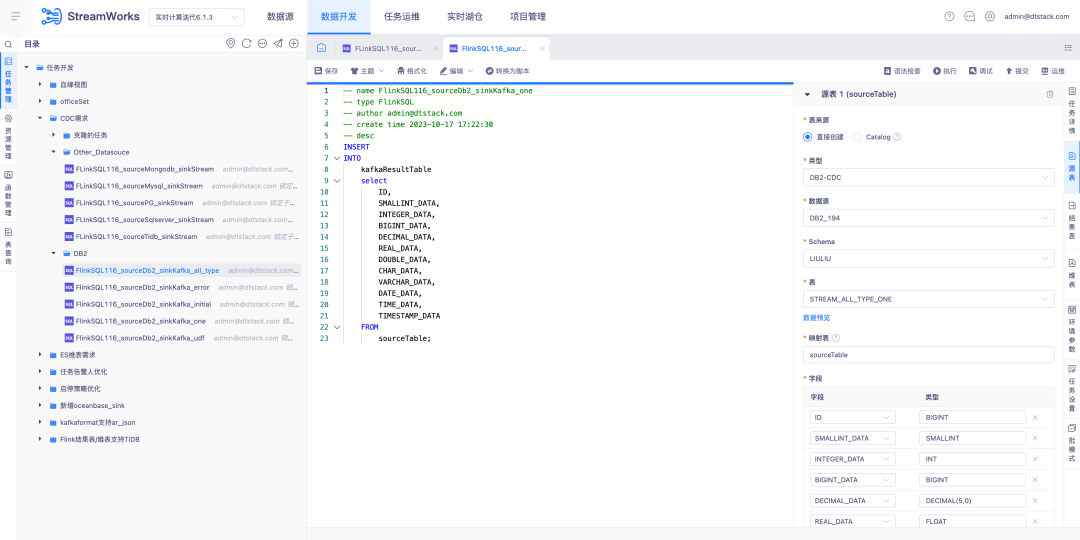
6.FlinkSQL suporta fonte de dados FlinkCDC DB2
Antecedentes: Os clientes precisam oferecer suporte à coleta de DB2 em tempo real. Considerando que o desenvolvimento do CDC Connector é difícil, o FinkCDC apenas o suporta, então a camada inferior empresta os recursos do FlinkCDC.
Nova descrição da função: A plataforma em tempo real suporta o modo assistente para configurar a tabela de origem como a fonte de dados DB2-CDC .
Otimização de função
1.Otimização da lógica de continuação
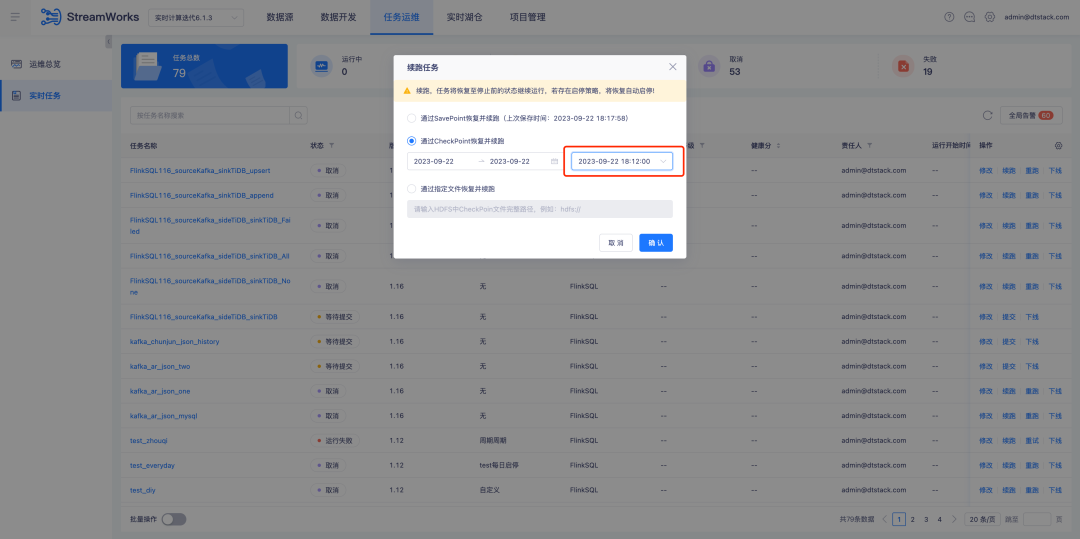
Histórico: quando uma tarefa em tempo real é retomada por meio do CheckPoint e continua em execução, um ponto no tempo precisa ser selecionado manualmente. No entanto, na verdade, a maioria dos cenários de continuação seleciona o CheckPoint mais recente.
Descrição da otimização da experiência: Ao otimizar para restaurar e continuar executando através do CheckPoint , o CheckPoint mais próximo dentro da data será selecionado automaticamente.
2. Estratégia start-stop/otimização externa
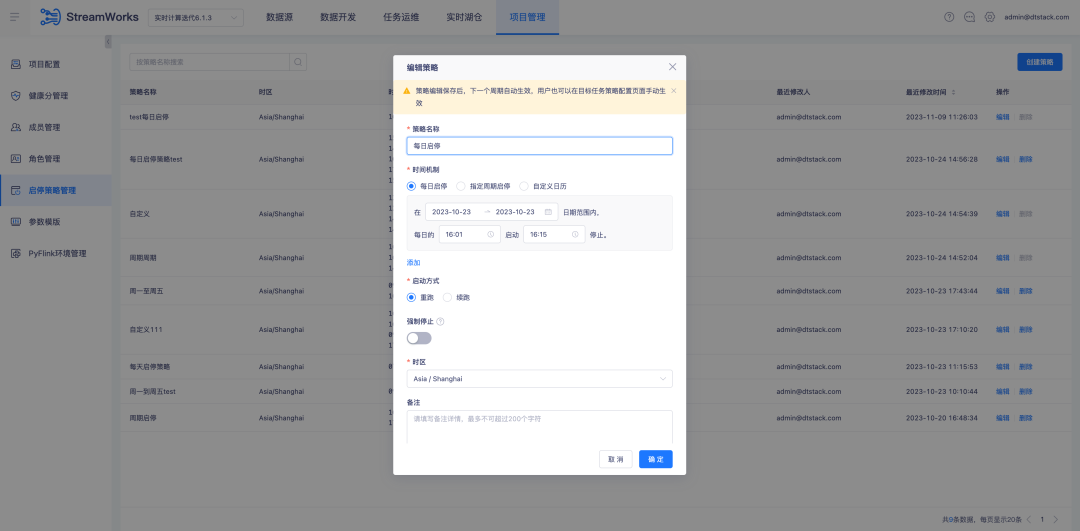
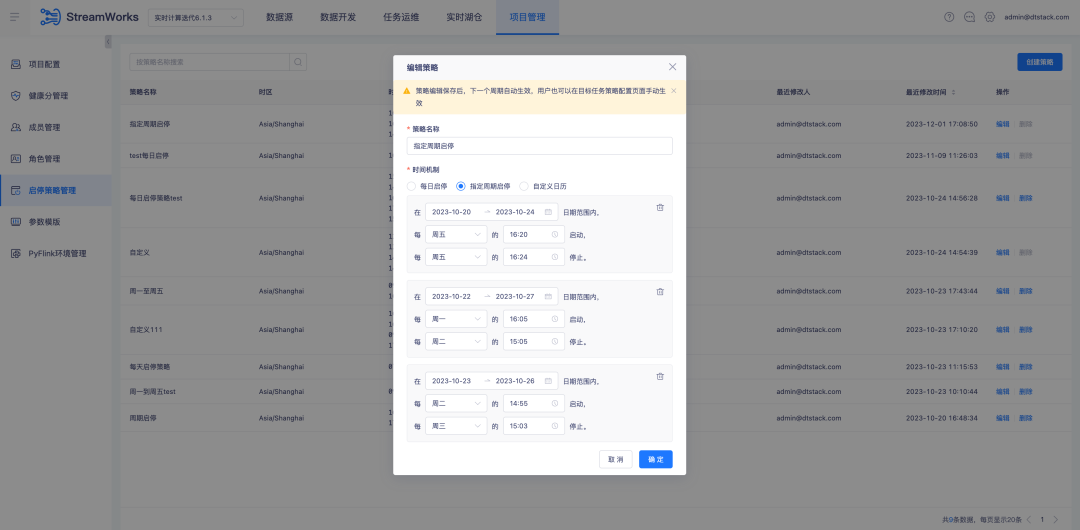
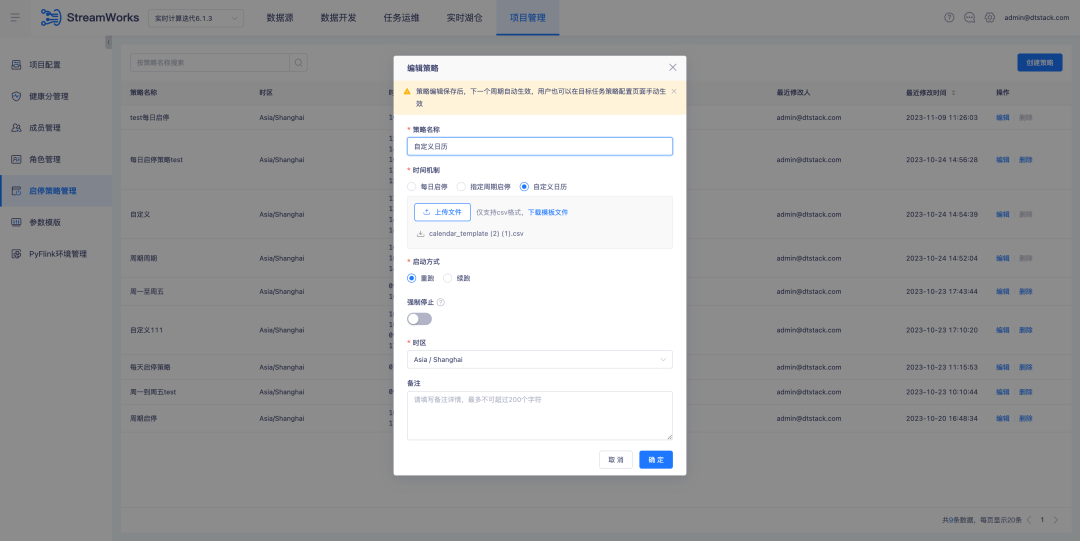
Histórico: Durante o uso aprofundado pelos clientes, descobrimos que aspectos como estratégia start-stop, envio e nova execução podem ser otimizados para alcançar um fluxo de trabalho mais eficiente e melhor experiência do usuário.
Atualmente, a configuração do carimbo de data/hora externo em nossas tabelas de origem de desenvolvimento de dados foi corrigida. No entanto, em cenários de computação de tarefas em tempo real, alguns clientes concentram-se apenas no cálculo dos dados do dia, por isso configuram uma política start-stop para executar novamente a tarefa todos os dias. Eles querem poder executar novamente a tarefa começando à meia-noite todos os dias, em vez de usar um carimbo de data/hora fixo. Embora o Latest possa teoricamente atender a esse requisito, o consumo do tempo de inicialização da tarefa em tempo real pode fazer com que o tempo real de execução se desvie de zero, resultando em erros de dados.
Instruções de otimização de experiência:
1. Otimize a configuração da política start-stop , agora ofereça suporte à política start-stop de vários dias e melhore a interação atual da página da política start-stop para fornecer uma experiência operacional mais eficiente e conveniente
2. Desenvolvimento de dados - tabela de origem, suporta configuração parametrizada de locais externos
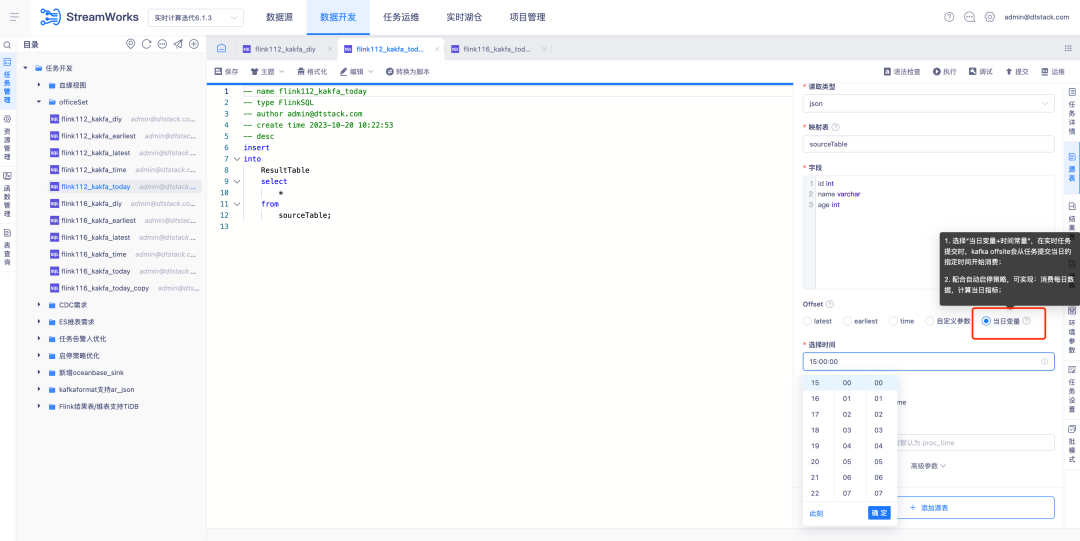
3. Otimização do plug-in ES7.x da versão FlinkSQL1.16
Antecedentes: O plug-in ES do FlinkSQL versão 1.10 suporta a configuração do tempo limite da tabela de dimensões e do limite de dados de tempo limite. Esta função está temporariamente indisponível na versão 1.16 atual do FlinkSQL e está sendo ativamente otimizada.
Instruções de otimização de experiência:
A tabela de dimensões do plug-in ES7.x da versão FlinkSQL1.16 configura table.exec.async-lookup.timeout ou usa sintaxe de dicas para definir o tempo limite. Quando a tarefa está sendo executada no modo LRU da tabela de dimensões, o tempo limite da consulta assíncrona leva. efeito.
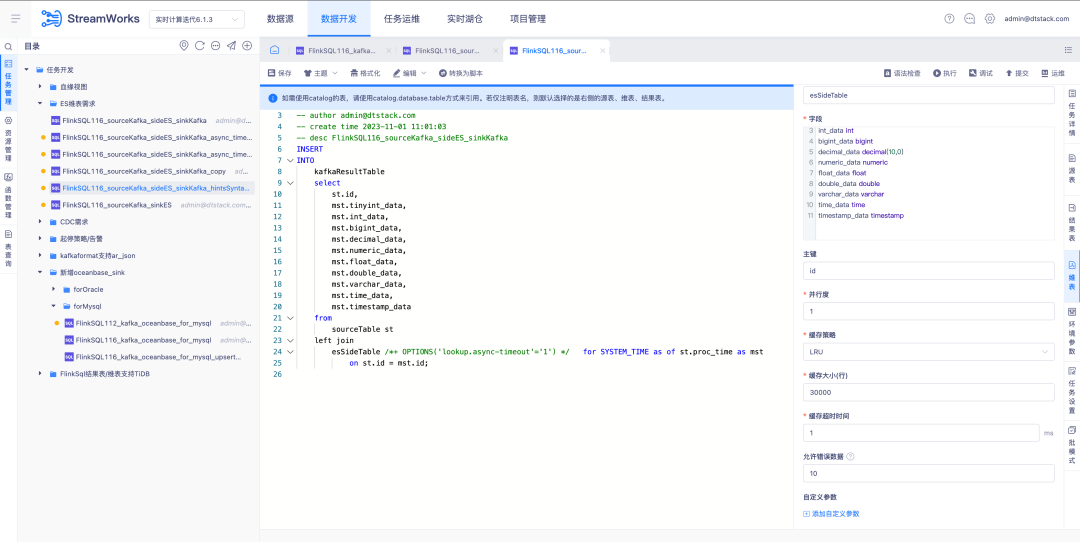
4. Otimização da configuração do alarme
Antecedentes: Nas regras de alarme de tarefa, a configuração de recebimento de alarme precisa ser selecionada manualmente. Não é possível combinar e enviar automaticamente informações de alarme de acordo com a pessoa responsável pela tarefa. impossível enviar automaticamente as informações de alarme correspondentes de acordo com a pessoa responsável pela tarefa.
Instruções de otimização de experiência:
1. Ajuste do destinatário da configuração da regra de alarme de tarefa única A pessoa responsável pela tarefa é selecionada por padrão. Outros destinatários podem ser selecionados através da caixa de seleção.
2. A configuração da regra de alarme global será realmente enviada para a pessoa responsável por cada tarefa quando a pessoa responsável pela tarefa for verificada. Quando outros destinatários forem selecionados, a tarefa selecionada será enviada ao destinatário selecionado quando a tarefa selecionada for anormal.
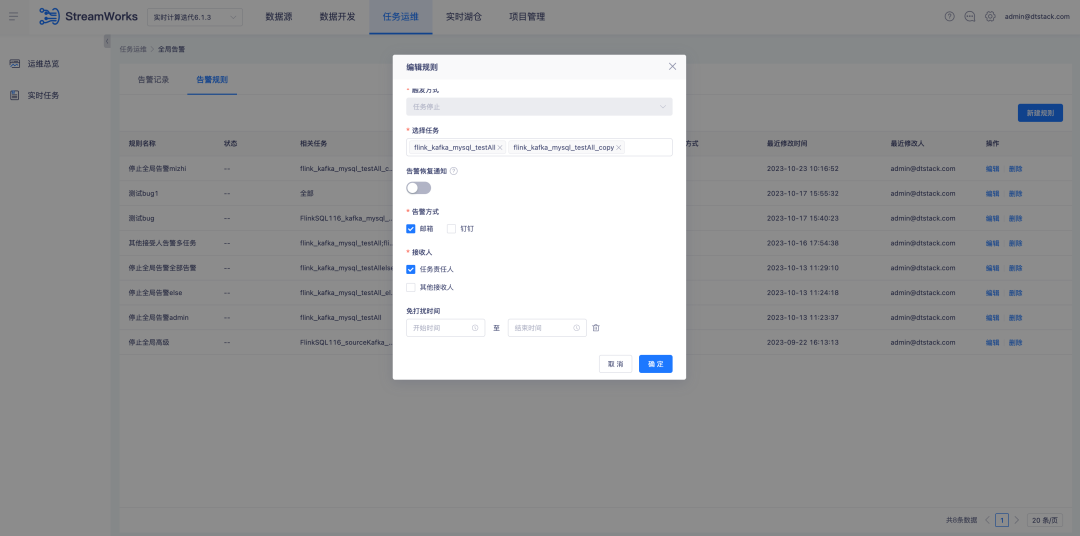
5. A plataforma de plug-in Tidb versão FlinkSQL1.12 e 1.16 é compatível
Antecedentes: As versões 1.12 e 1.16 do FlinkSQL completaram a adaptação ao Tidb. No entanto, a camada da plataforma só foi adaptada na versão 1.10, portanto as versões 1.12 e 1.16 não são suportadas.
Instruções de otimização de experiência:
A plataforma em tempo real é compatível com o plug-in Tidb versão 1.12 e 1.16 e precisa suportar tabelas de dimensões e tabelas de resultados.
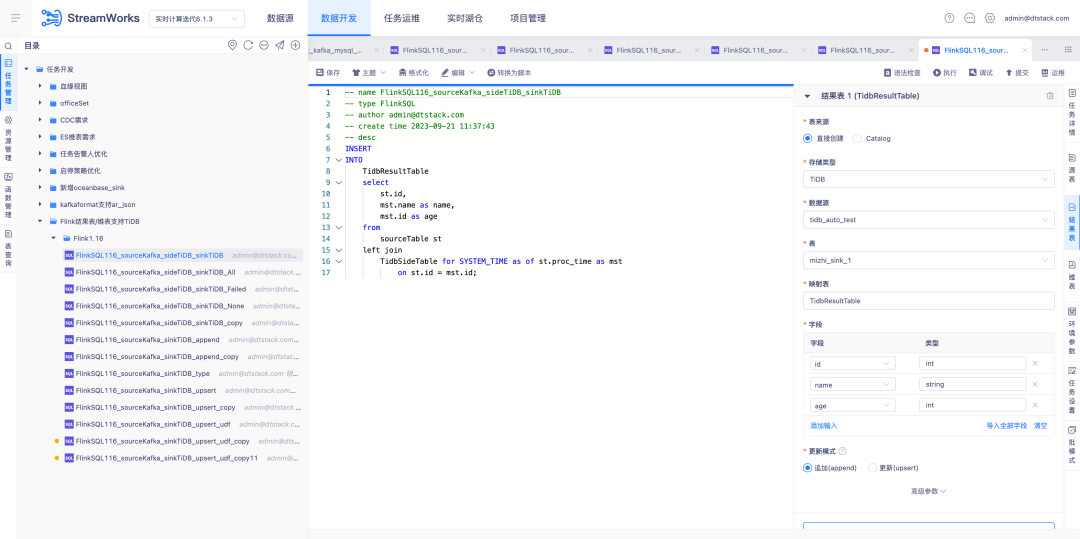
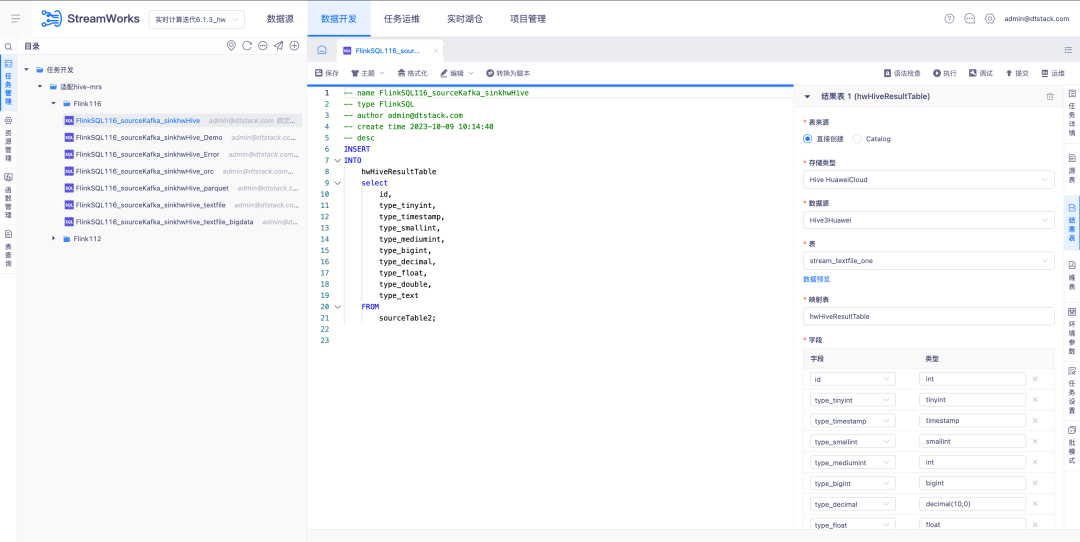
6.FlinkSQL1.12 e 1.16 versão Hive adaptação huaweiCloud
Antecedentes: O backup em tempo real dos dados do Kafka é inserido no MRS Hive. Quando há um problema com os dados de cálculo em tempo real, as mensagens de backup no Hive podem ser analisadas.
Instruções de otimização de experiência:
FlinkSQL versão 1.12 e 1.16 é adaptado para Hive huaweiCloud O centro de fonte de dados, mecanismo e plataforma são desenvolvidos simultaneamente para suportar a tabela de resultados Hive huaweiCloud .
Plataforma de serviço de dados
Novas atualizações de recursos
1. Suporte à API de criação de versão HBase TBDS
Adicionada API de criação de versão HBase TBDS, incluindo: API de geração de modo assistente , importação e exportação e publicação em projetos de destino.

Otimização de função
1. Fonte de dados Oracle suporta DML
Melhorar as fontes de dados suportadas pelo DML .
2. A análise de comentários no modo SQL personalizado não substitui mais a descrição
Plano de fundo: para lógica histórica, depois que o esquema SQL personalizado for analisado novamente para o banco de dados, os comentários que acompanham o banco de dados substituirão as instruções modificadas.
Instruções de otimização de experiência: Modifique a lógica histórica Para as instruções modificadas, os comentários no banco de dados não serão mais substituídos após a nova análise.
3. Depois que as permissões em nível de linha forem habilitadas, não será necessário preenchê-las por padrão.
Plano de fundo: para permissões históricas em nível de linha, as permissões em nível de linha serão habilitadas nos campos da tabela. Após serem habilitadas, os campos serão obrigatórios por padrão e o cancelamento do usuário não será suportado.
Descrição da otimização da experiência: esta iteração ajusta a lógica histórica. As permissões em nível de linha serão habilitadas no nível da API. Depois de habilitadas, quando a API usar a tabela, ela será restrita pelas permissões em nível de linha.
4. Versão da estrutura e atualização de componentes
A versão do framework Spring Cloud (Boot) foi atualizada e o componente Nacos foi atualizado para reduzir a probabilidade de vulnerabilidades e aumentar a estabilidade da própria API.
Plataforma de insights de dados do cliente
Novas atualizações de recursos
1.Suporte a funções UDF personalizadas
Antecedentes: O número de telemóvel, o número de identificação e outros dados envolvidos nos dados processados pelo cliente são dados encriptados. Do ponto de vista da auditoria, este tipo de dados não pode ser apresentado em texto simples, mas haverá cenários em que o conteúdo de texto simples é. exibido no negócio de nível superior. Por exemplo: marketing de SMS baseado em números de telefone celular.
Os clientes precisam atrasar o processo de descriptografia o mais tarde possível, colocá-lo na plataforma de rótulos para ser concluído e adicionar rótulos personalizados por meio da personalização da função UDF para concluir o processamento.
Descrição das novas funções: Um novo módulo de gerenciamento de funções foi adicionado ao tag center , sob o qual funções UDF podem ser criadas, visualizadas e excluídas (somente Trino385 e versões superiores suportam a criação de funções)
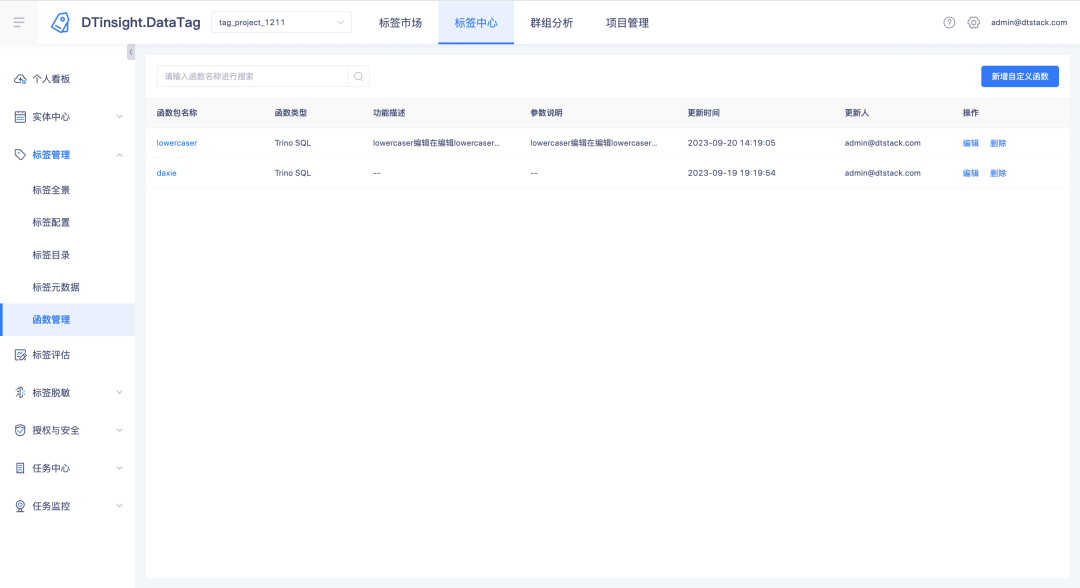
Para funções carregadas, você pode clicar no nome da função para visualizar os detalhes da função.
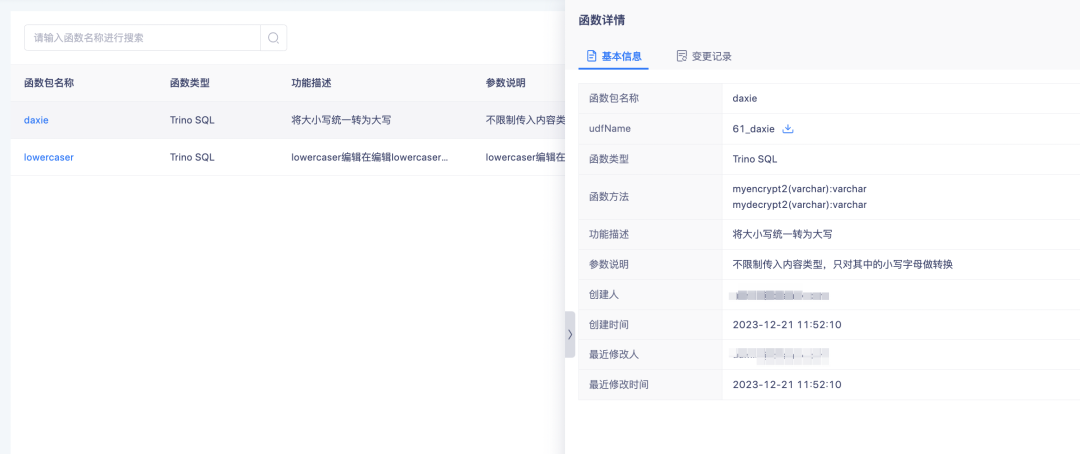
A função carregada é usada principalmente para processar tags SQL derivadas.
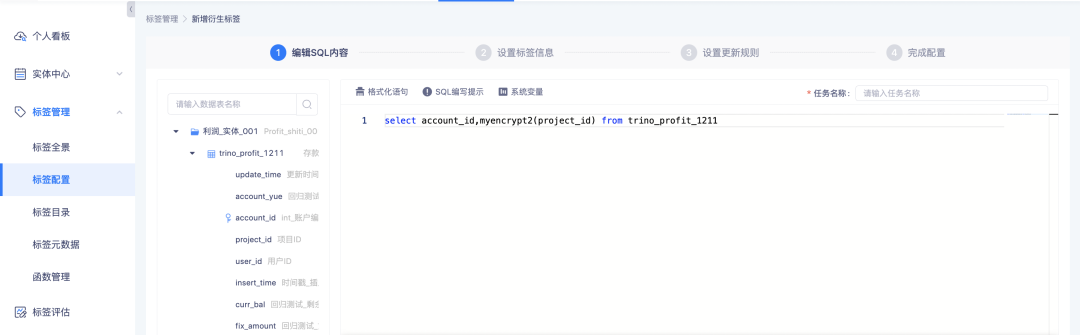
2. Suporte ao processamento de tags de vários valores
Antecedentes: As regras de processamento atuais para tags derivadas e tags combinadas são que quando uma instância atinge pela primeira vez uma determinada condição de regra, o valor da tag correspondente será marcado na instância e outros valores de tag não serão mais correspondidos. , os resultados da tag de valor único serão armazenados no banco de dados.
No entanto, em aplicações práticas, as condições não são necessariamente mutuamente exclusivas. Por exemplo, o usuário recebe um rótulo de preferência de produto com base no número de vezes que comprou um tipo específico de produto. Neste caso, vários valores precisam ser suportados.
Descrição dos novos recursos:
Tags de regra derivadas, tags SQL derivadas, tags de combinação e processamento de tags personalizado suportam configuração como tags de vários valores e o sistema as calcula com base no tipo de valor de tag definido.
• Tags de valor único: Correspondem em ordem de acordo com a configuração da regra. Interrompe a correspondência quando um determinado valor de tag é atingido. Existe no máximo um valor de tag no resultado dos dados.
• Tags multivalores: Correspondência em sequência de acordo com a ordem de configuração da regra. Cada regra será correspondida uma vez. Haverá no máximo n valores de tag configurados no resultado dos dados.
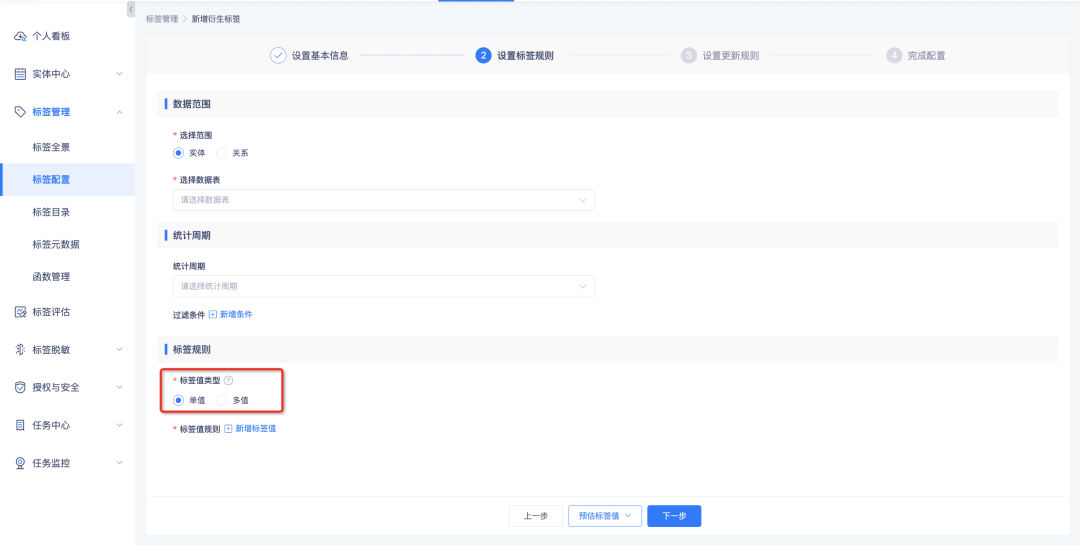
Com base nos resultados do cálculo, os detalhes do rótulo contarão o número de instâncias de cada rótulo individual, ou seja, a soma do número de instâncias cobertas por cada valor de rótulo de um rótulo de valor único é o número de instâncias cobertas pelo rótulo e o número de instâncias cobertas por cada valor de rótulo de um rótulo com vários valores. A soma dos números é maior ou igual ao número de instâncias de cobertura de rótulo.
3. Centro de negócios de encaixe de função personalizado
Histórico: Anteriormente, as funções eram funções integradas no sistema e as funções não podiam ser adicionadas/modificadas/excluídas. As permissões de função não podiam ser personalizadas. As funções eram muito fixas e não podiam ser ajustadas de forma flexível de acordo com os cenários reais de negócios. clientes. Na versão 6.0, o centro de negócios adicionou função de função de personalização, a etiqueta do produto está conectada a esta função do centro de negócios para obter os seguintes efeitos:
1. Apoie novas funções
2. Suporte a permissões de funções personalizadas
Nova descrição da função: Configure funções e suas permissões de indicadores no centro de negócios, e a plataforma de rotulagem apresentará automaticamente os resultados da configuração de permissão para consulta.
1. Adicione novas funções e configure pontos de permissão de função no centro de negócios:
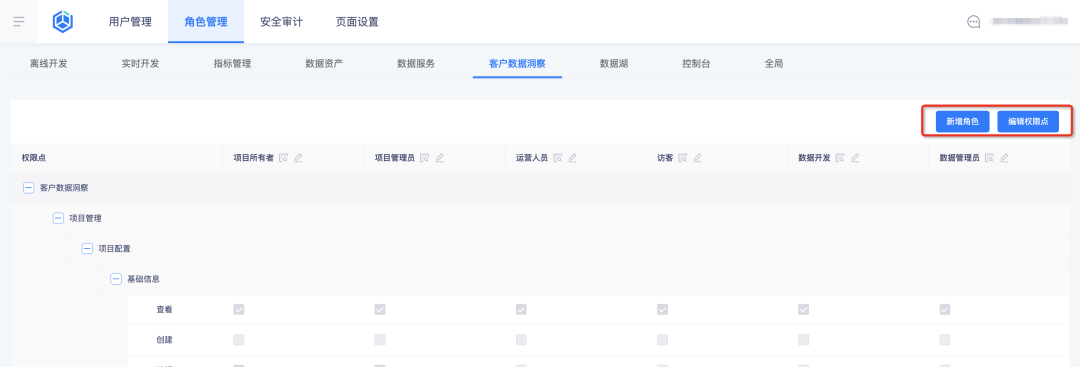
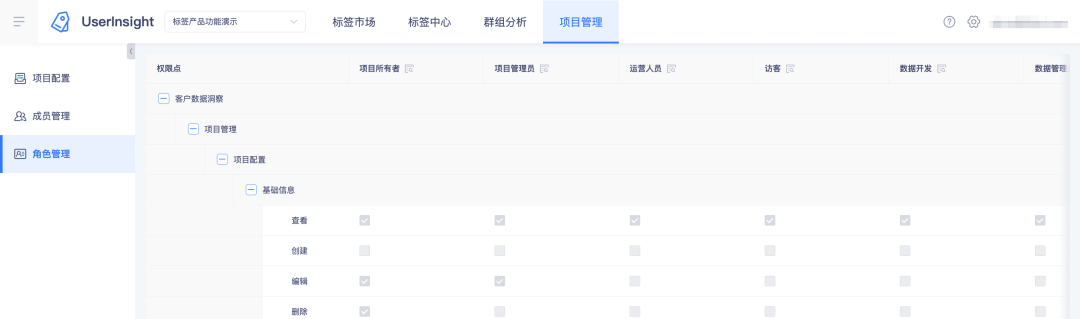
2. Visualize as funções e seus pontos de permissão na plataforma de tags:
4. O formato de exibição de dados suporta personalização
Plano de fundo: Para tags numéricas, a configuração da precisão de exibição não é suportada no momento, resultando em exibição irregular de páginas, como 1, e alguns decimais, como 1,234. A experiência geral de leitura não é alta. experiência, é necessário adicionar configurações de regras de exibição de dados.
Descrição dos novos recursos:
1. Ao criar/editar entidades, editar tags atômicas e criar/editar tags SQL derivadas, é possível definir regras de exibição para tags numéricas.
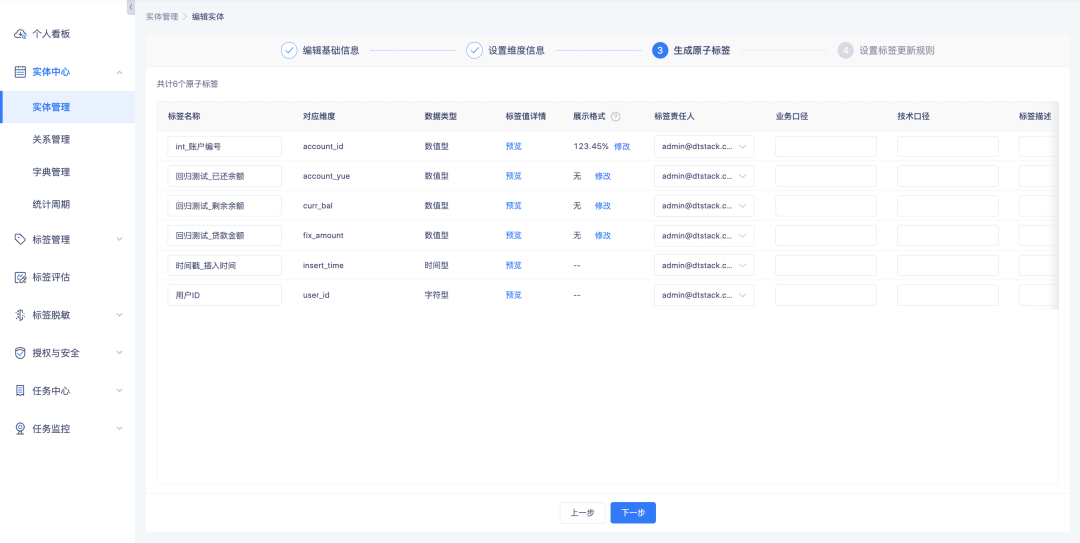
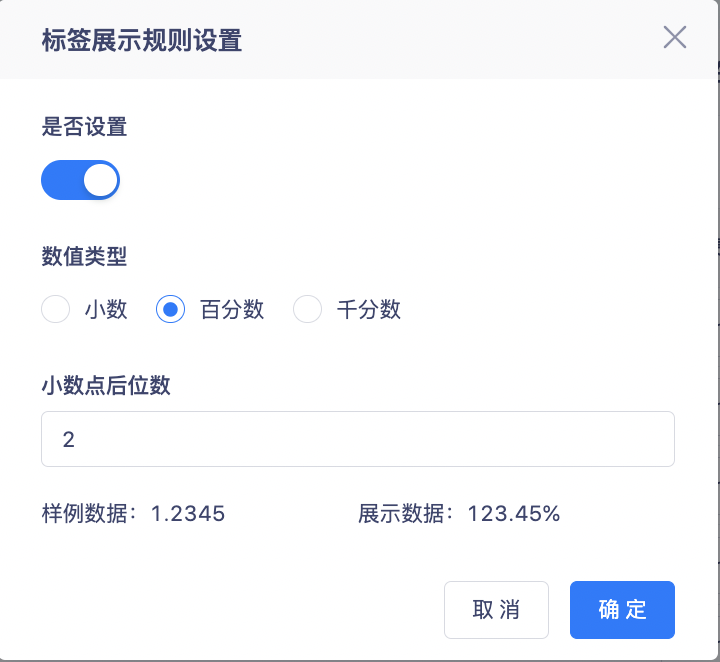
2. Suporta exibição como decimais, porcentagens e milésimos e suporta a configuração do número de dígitos após o ponto decimal.
3. Os dados de tags exibidos nas páginas relacionadas ao grupo são exibidos de acordo com as regras de exibição definidas.
5. O upload de arquivo de tag/grupo suporta a visualização do progresso do upload
Histórico: a função de importação de arquivo atualmente é carregada sem avisos de progresso. Quando o arquivo é muito grande, o tempo de espera é longo, o que fará com que os usuários entendam mal que a página está travada. Os prompts de progresso precisam ser adicionados para esclarecer o progresso atual. Usuários.
Descrição dos novos recursos:
1. Adicionados prompts de progresso durante tarefas de etiqueta, upload de arquivo de grupo e consulta offline.
2. O upload de arquivos em grupo foi ajustado para suportar o upload de arquivos de até 500 milhões de tamanho.
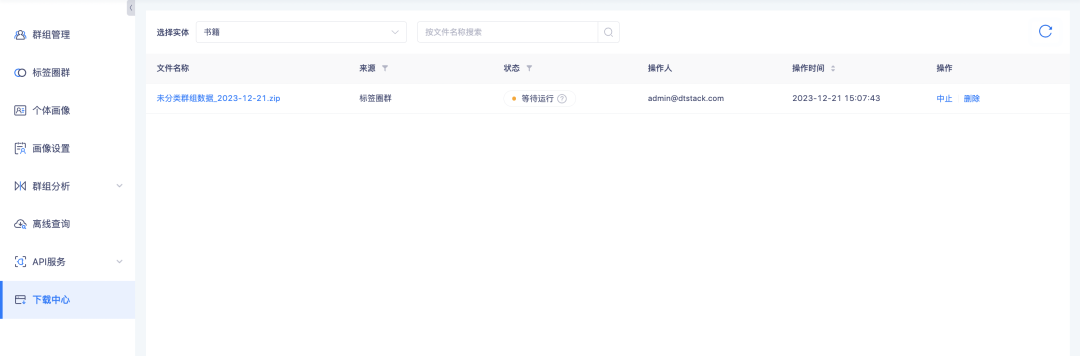
6. O centro de download oferece suporte à consulta do progresso do download.
Antecedentes: Durante o processo de download de dados, devido à grande quantidade de dados, leva muito tempo para prepará-los antes que possam ser baixados. Os usuários não esperam isso ao usá-los e precisam atualizá-los com frequência para determinar se o download. pode ser realizado. Avisos de progresso do download precisam ser adicionados para orientar os usuários a determinar quanto tempo esperar.
Nova descrição da função: O status da tarefa do centro de download adiciona o status de espera para execução e aborto. Entre eles, o download da lista de grupos de grupos de círculo de tags, lista de grupos de detalhes de grupo, upload de lista de instâncias de grupo local, lista de instâncias de detalhes de grupo de consulta offline, interseção de grupo e lista de instâncias de diferença depende dos dados da lista de grupos. o volume de download for grande, será executado no modo de download serial. As tarefas relacionadas à lista de grupos serão enfileiradas para execução em sequência. Aqueles que não estão na fila aguardam para serem executados. . Enquanto as tarefas estão em execução, você pode cancelar tarefas que não são mais necessárias.
Otimização de função
1. A exportação de dados é ajustada para baixar arquivos através do centro de download
Histórico: Os downloads de arquivos em algumas páginas são baixados diretamente, fazendo com que o botão esteja sempre em execução e o usuário não consiga perceber o progresso do download.
Descrição da otimização da experiência: Após clicar no botão relacionado à exportação de dados, o arquivo será baixado de forma assíncrona. Após a conclusão do download, você pode entrar no módulo "Centro de Download" para baixar os detalhes dos dados . Grupo de Círculo -Exportação de dados, Detalhes do grupo-Exportação de dados de lista de grupos, upload de lista de instâncias de grupo local-exportação de dados, consulta offline-upload de grupo local/interseção de grupo e detalhes de diferença-exportação de dados, interseção de grupo e exportação de dados de diferença.
Se a quantidade de dados for muito grande, o sistema irá exportá-los em arquivos separados com base no limite superior do número de registros definido pelo usuário.
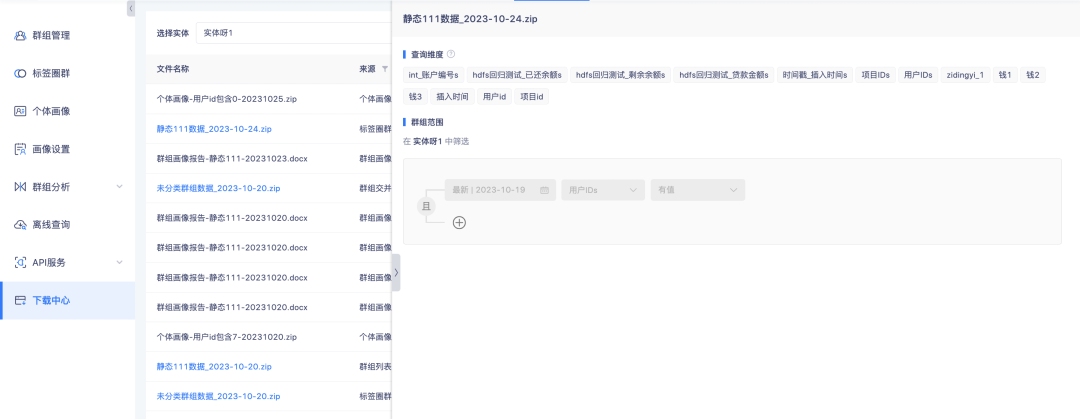
2. Listar dados de grupos de círculos de tags e detalhes de grupos no centro de download oferece suporte à visualização de detalhes de configuração.
Antecedentes: Atualmente, existem muitas fontes de arquivos no centro de download e é inconveniente distinguir o conteúdo com base apenas nos nomes dos arquivos. É necessário aumentar as fontes de dados dos arquivos para melhorar a disponibilidade dos dados.
Descrição da otimização da experiência: liste dados de grupos de círculos de tags e cliques de suporte de detalhes do grupo. Clique na barra lateral para abrir os detalhes de configuração.
3. Otimização de novas funções de tags no mercado de tags
Contexto: Atualmente, a plataforma não explica a definição de novas tags e precisa ser adicionada.
Descrição da otimização da experiência: Novas tags na plataforma são definidas como as últimas 24 horas, mas no uso real, as pessoas geralmente não prestam atenção nelas nos finais de semana. Quando voltarem a prestar atenção na segunda-feira, haverá situações em que as tags atualizadas partirão. De sexta a domingo de manhã não pode ser notificado no local.
4. Otimização de adaptação de permissão de troca entre subprodutos
Quando um produto marcado é alternado entre subprodutos, o conteúdo da guia na página estará ausente. Isso é causado por problemas de permissão. Essa otimização garante que a função esteja disponível ao alternar páginas entre produtos.
5. Suporte para ajuste e personalização da largura da coluna
Lista de grupos, lista de grupos de detalhes de grupo, lista de usuários de grupo de círculo de tags, interseção de grupo e lista de instâncias de diferença e largura de coluna de lista de tags suportam personalização.
Depois de personalizar a largura da coluna, ela terá efeito para usos subsequentes com base no navegador atual e no usuário conectado no momento. Quando o usuário fizer login usando um novo navegador ou limpar o cache do navegador atual, ou fizer login novamente, o. as configurações padrão serão exibidas.
Plataforma de gerenciamento de indicadores
Novas atualizações de recursos
1. Centro de negócios de encaixe de função personalizado
Histórico: Anteriormente, as funções eram funções integradas no sistema e as funções não podiam ser adicionadas/modificadas/excluídas. As permissões de função não podiam ser personalizadas. As funções eram muito fixas e não podiam ser ajustadas de forma flexível de acordo com o cenário de negócios real do cliente. .
Descrição dos novos recursos:
Configure a função e suas permissões de indicador no centro de negócios e a plataforma de indicadores apresentará automaticamente os resultados da configuração de permissão para consulta:
1. Adicione novas funções e configure pontos de permissão de função no centro de negócios
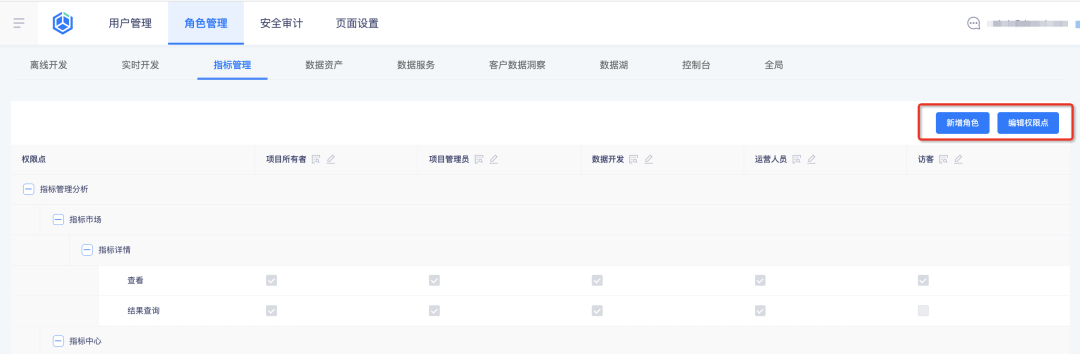
2. Visualize as funções e seus pontos de permissão na plataforma do indicador
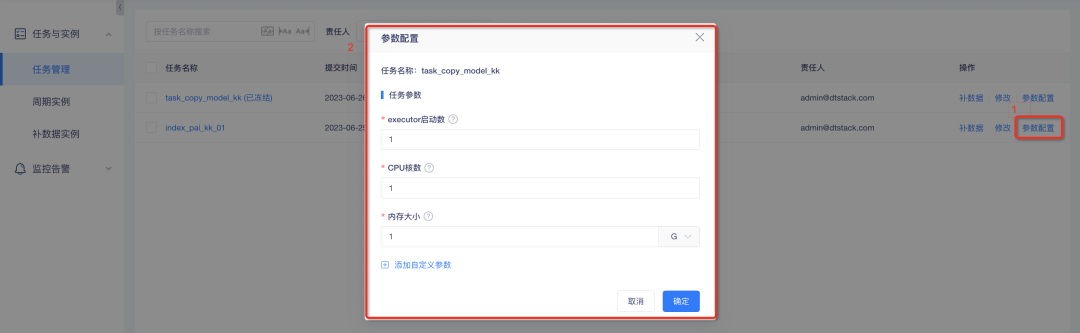
2. As tarefas de sincronização de dados e Spark suportam configuração de parâmetros personalizados
Antecedentes: Para tarefas Spark e tarefas de sincronização de dados, atualmente os ajustes de parâmetros só podem ser feitos através do console. Os resultados do ajuste terão efeito globalmente. No entanto, as diferenças de magnitude dos dados entre as tarefas do indicador são grandes e a configuração dos mesmos parâmetros causará um desperdício. de recursos. Portanto, parâmetros em nível de tarefa podem ser definidos para tarefas de sincronização de dados e Spark para facilitar o controle flexível de tarefas.
Descrição dos novos recursos:
1. Configuração de parâmetros personalizados da tarefa Spark : entre eles, o número de inicializações do executor, o número de núcleos da CPU e o tamanho da memória podem ser definidos;
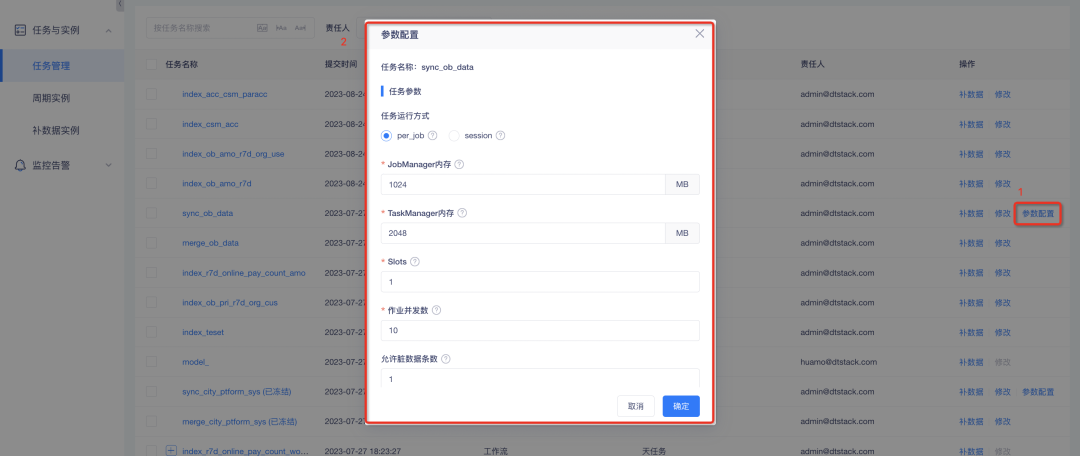
2. Configuração de parâmetros personalizados para tarefas de sincronização de dados : no modo por trabalho, a memória do gerenciador de tarefas, a memória do gerenciador de tarefas e os slots são necessários;
Otimização de função
1. O navegador suporta a abertura de vários projetos ao mesmo tempo
Antecedentes: Na função de histórico, o cookie não armazena parâmetros do projeto. Como resultado, quando a pilha de dados abre uma nova janela de projeto, o conteúdo da janela de histórico será atualizado e o usuário retornará à página de lista de projetos do projeto. seleção, o que afeta o uso do cliente.
Descrição da otimização da experiência: esta otimização permite que o navegador abra vários projetos ao mesmo tempo para consulta, operação, etc., para melhorar a eficiência do uso do produto.
Compatível com navegador 2.edge
Compatível com o navegador egde, as funções serão adaptadas de acordo para melhorar a usabilidade do produto nos navegadores convencionais.
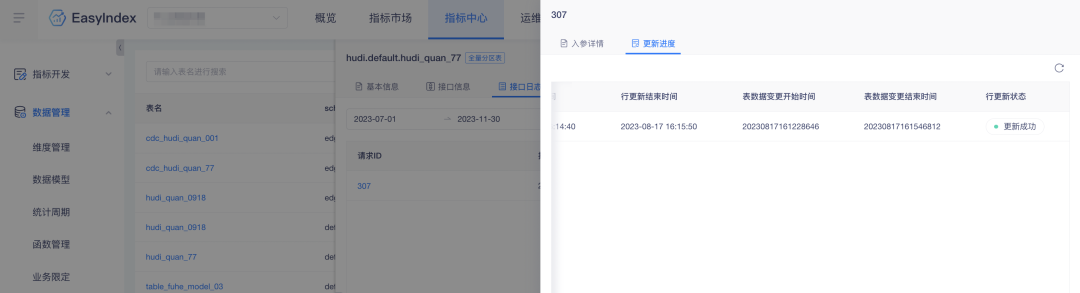
3. Tempo de atualização da tabela suplementar de atualização de linha
Antecedentes: O registro de dados de atualização de linha não possui o período de mudança de dados da tabela, o que torna a recuperação de dados inconveniente. Para melhorar a eficiência da recuperação de dados, dados relevantes são adicionados à plataforma.
Descrição da otimização da experiência: a atualização da linha do indicador adiciona horário de início e término da alteração dos dados da tabela.
4. Adicione função de atualização manual ao status de atualização de linha
Durante o processo de atualização de linha, para facilitar o acompanhamento oportuno do progresso da atualização, um botão de atualização é adicionado à página para melhorar a eficiência da atualização.
5. Otimização de objetos dimensionais preenchidos por modelo e funções de atributos dimensionais
Ao editar o modelo, na etapa de configuração das informações de dimensão, o sistema preencherá as informações de dimensão vinculadas aos campos principais da tabela de dimensões por padrão caso o usuário tenha modificado as dimensões associadas na versão histórica e se você não prestar atenção. ao ajuste durante o processo de edição, dados incorretos serão salvos. Para evitar taxa de erro de dados, ajustado para ecoar as informações salvas na versão anterior.
6. O gateway de API oferece suporte a prefixos personalizados
As informações de prefixo do indicador estão atualmente gravadas no item de configuração da API. Ao mesmo tempo, a API atualmente possui uma função de prefixo personalizada para melhorar a flexibilidade de configuração da API. Neste momento, quando os itens de configuração da API do indicador são inconsistentes com o prefixo personalizado da API, os dados não podem ser chamados normalmente. Eles precisam ser ajustados às configurações da API de encaixe para garantir que a configuração global seja exclusiva.
Endereço de download do "White Paper do produto Dutstack": https://www.dtstack.com/resources/1004?src=szsm
Endereço para download do "White Paper sobre práticas da indústria de governança de dados": https://www.dtstack.com/resources/1001?src=szsm
Para quem deseja conhecer ou consultar mais sobre produtos de big data, soluções industriais e cases de clientes, visite o site oficial da Kangaroo Cloud: https://www.dtstack.com/?src=szkyzg
Linus assumiu a responsabilidade de evitar que os desenvolvedores do kernel substituíssem tabulações por espaços. Seu pai é um dos poucos líderes que sabe escrever código, seu segundo filho é o diretor do departamento de tecnologia de código aberto e seu filho mais novo é um núcleo de código aberto. contribuidor Robin Li: A linguagem natural se tornará uma nova linguagem de programação universal. O modelo de código aberto ficará cada vez mais atrás da Huawei: levará 1 ano para migrar totalmente 5.000 aplicativos móveis comumente usados para Hongmeng. vulnerabilidades de terceiros. O editor de rich text Quill 2.0 foi lançado com recursos, confiabilidade e desenvolvedores. A experiência foi bastante melhorada. fonte de Laoxiangji não é o código, as razões por trás disso são muito comoventes. O Google anunciou uma reestruturação em grande escala.