
Desde o surgimento do ChatGPT no final de 2022, a inteligência artificial voltou a ser o foco do mundo, e a IA baseada em grandes modelos de linguagem (LLM) tornou-se um "frango quente" no campo da inteligência artificial. No ano desde então, testemunhamos o rápido progresso da IA no campo do texto Wensheng e das imagens Wensheng, mas o desenvolvimento no campo do vídeo Wensheng tem sido relativamente lento. No início de 2024, a OpenAI lançou mais uma vez um blockbuster - o modelo de vídeo de Vincent, Sora. A última peça do quebra-cabeça de criação de conteúdo foi concluída pela IA.
Há um ano, um vídeo de Smith comendo macarrão se tornou viral nas redes sociais. Na foto, o ator tinha um rosto horrível, traços faciais deformados e comia espaguete em uma postura distorcida. Esta imagem terrível lembra-nos que a tecnologia de vídeo gerado por IA estava apenas na sua infância naquela altura.

Apenas um ano depois, um vídeo de IA de “mulheres elegantes andando pelas ruas de Tóquio” gerado por Sora mais uma vez incendiou as redes sociais. No mês de março seguinte, Sora uniu forças com artistas de todo o mundo para lançar oficialmente uma série de curtas-metragens de arte surreal que subverteram a tradição. O seguinte curta-metragem "Air Head" foi criado pelo famoso diretor Walter e Sora. A imagem é requintada e realista, e o conteúdo é selvagem e imaginativo. Pode-se dizer que Sora "esmagou" os principais modelos de vídeo de IA, como Gen-2, Pika e Stable Video Diffusion, quando estreou.

A evolução da IA é muito mais rápida do que o esperado. Podemos facilmente prever que a estrutura industrial existente, incluindo vídeos curtos, jogos, cinema e televisão, publicidade, etc., será remodelada num futuro próximo. A chegada de Sora parece nos aproximar um passo de um modelo para a construção do mundo.
Por que Sora tem uma magia tão poderosa? Que tecnologias mágicas ele usa? Depois de revisar o relatório técnico oficial e muitos documentos relacionados, o autor explicará os princípios técnicos por trás do Sora e a chave para seu sucesso neste artigo.
1 Qual problema central Sora deseja resolver?
Resumindo em uma frase, o desafio que Sora enfrenta é como transformar vários tipos de dados visuais em um método de representação unificado para que o treinamento unificado possa ser realizado.
Por que precisamos de treinamento unificado? Antes de responder a esta pergunta, vamos primeiro dar uma olhada nas ideias anteriores de geração de vídeo de IA convencionais de Sora.
1.1 Método de geração de vídeo AI na era pré-Sora
- Expandir com base no conteúdo da imagem de quadro único
Extensões baseadas em imagens de quadro único usam o conteúdo do quadro atual para prever o próximo quadro. Cada quadro é uma continuação do quadro anterior, formando assim um fluxo de vídeo contínuo (a essência do vídeo é uma imagem exibida continuamente quadro a quadro). .
Nesse processo, geralmente são utilizadas descrições de texto para gerar imagens e, em seguida, são gerados vídeos com base nas imagens. Porém, há um problema com essa ideia: o próprio uso de texto para gerar imagens é aleatório. Essa aleatoriedade é amplificada duas vezes ao usar imagens para gerar vídeos, e a controlabilidade e estabilidade do vídeo final são muito baixas.
- Treine diretamente em todo o vídeo
Como o efeito de vídeo baseado na derivação de quadro único não é bom, a ideia muda para treinar o vídeo inteiro.
Aqui, um videoclipe de alguns segundos geralmente é selecionado e o modelo é informado sobre o que o vídeo mostra. Depois de muito treinamento, a IA pode aprender a gerar videoclipes com estilo semelhante aos dados de treinamento. A falha dessa ideia é que o conteúdo aprendido pela IA é fragmentado, é difícil gerar vídeos longos e a continuidade dos vídeos é ruim.
Algumas pessoas podem perguntar: por que não usar vídeos mais longos para treinamento? A principal razão é que os vídeos são muito grandes em comparação com texto e imagens, e a placa gráfica tem memória de vídeo limitada e não pode suportar treinamentos de vídeo mais longos. Sob diversas restrições, a quantidade de conhecimento da IA é extremamente limitada. Ao inserir conteúdo que “não conhece”, os resultados gerados são muitas vezes insatisfatórios.
Portanto, se você quiser romper o gargalo do vídeo de IA, deverá resolver esses problemas principais.
1.2 Desafios no treinamento de modelos de vídeo
Os dados de vídeo vêm em vários formatos, de tela horizontal a tela vertical, de 240p a 4K, diferentes proporções, resoluções e atributos de vídeo diferentes. A complexidade e diversidade dos dados trazem grandes dificuldades ao treinamento de IA, o que por sua vez leva a um baixo desempenho do modelo. É por isso que esses dados de vídeo devem primeiro ser representados de maneira unificada.
A principal tarefa do Sora é encontrar uma maneira de converter vários tipos de dados visuais em um método de representação unificado, para que todos os dados de vídeo possam ser treinados de forma eficaz em uma estrutura unificada.
1.3 Sora: Marcos em direção à AGI
Nossa missão é garantir que a inteligência artificial geral beneficie toda a humanidade. —— OpenAI
O objetivo da OpenAI sempre foi claro: alcançar a inteligência artificial geral (AGI), então qual é o significado do nascimento do Sora para atingir o objetivo da OpenAI?
Para implementar AGI, o grande modelo deve compreender o mundo. Ao longo do desenvolvimento do OpenAI, o modelo GPT inicial permitiu à IA compreender texto (uma dimensão, apenas comprimento), e o modelo DALL·E lançado posteriormente permitiu à IA compreender imagens (duas dimensões, comprimento e largura), e agora o modelo Sora permite que a IA entenda o vídeo (tridimensional, comprimento, largura e tempo).
Através da compreensão abrangente de textos, imagens e vídeos, a IA pode gradualmente compreender o mundo. Sora é o posto avançado da OpenAI para AGI. É mais do que apenas um modelo de geração de vídeo, como diz o título de seu relatório técnico [1]: “Um modelo de geração de vídeo como um simulador mundial”.
A visão do Tuoshupai coincide com o objetivo do OpenAI. Os extensionistas acreditam que a utilização de um pequeno número de símbolos e modelos computacionais para modelar a sociedade humana e a inteligência individual lançou as bases para a IA inicial, mas mais dividendos dependem de maiores quantidades de dados e de maior poder computacional. Quando não podemos construir um novo modelo inovador, podemos procurar mais conjuntos de dados e utilizar maior poder de computação para melhorar a precisão do modelo, trocar poder de computação de dados por poder de modelo e impulsionar a inovação em sistemas de computação de dados. No sistema de computação de dados de grande porte lançado por Tuoshupai, os modelos matemáticos, dados e cálculos de IA serão perfeitamente conectados e se reforçarão mutuamente como nunca antes, tornando-se uma nova força produtiva que promove o desenvolvimento de alta qualidade da sociedade [2].
2 Interpretação do princípio Sora
Sora não é o primeiro modelo de vídeo de Vincent a ser lançado, então por que isso está causando tanto rebuliço? Qual é o segredo por trás disso? Se você descrever o processo de treinamento de Sora em uma frase: o vídeo original é compactado no espaço latente por meio de um codificador visual e decomposto em fragmentos de espaço-tempo, que são combinados com texto. Restrições condicionais são usadas para realizar o treinamento de difusão e a geração por meio do transformador espaço-temporal gerado. os blocos de imagem são finalmente mapeados de volta ao espaço de pixels por meio do decodificador visual correspondente.
2.1 Rede de compressão de vídeo
Sora primeiro converte dados brutos de vídeo em recursos de espaço latente de baixa dimensão. Os dados de vídeo que assistimos todos os dias são muito grandes e devem primeiro ser convertidos em vetores de baixa dimensão que a IA possa processar. Aqui, OpenAI baseia-se em um artigo clássico: Modelos de Difusão Latente[3].
O ponto central deste artigo é refinar a imagem original em um recurso de espaço latente, que pode não apenas reter as principais informações do recurso da imagem original, mas também comprimir bastante a quantidade de dados e informações.
É provável que a OpenAI tenha atualizado o autoencoder variacional (VAE) para imagens neste artigo para suportar o processamento de dados de vídeo. Dessa forma, Sora pode converter uma grande quantidade de dados de vídeo originais em recursos de espaço latente de baixa dimensão, ou seja, extrair as informações principais do vídeo, que podem representar o conteúdo principal do vídeo.
2.2 Patches de Espaço-Tempo
Para conduzir treinamento em vídeo de IA em larga escala, a unidade básica de dados de treinamento deve primeiro ser definida. No modelo de linguagem grande (LLM), a unidade básica de treinamento é o Token[4]. OpenAI se inspira no sucesso do ChatGPT: o mecanismo Token unifica elegantemente diferentes formas de texto – código, símbolos matemáticos e várias linguagens naturais. Sora consegue encontrar seu “Token”?
Graças aos resultados de pesquisas anteriores, Sora finalmente encontrou a resposta – Patch.
- Transformador de visão (ViT)
O que é um patch? Patch pode ser entendido coloquialmente como um bloco de imagem. Quando a resolução da imagem a ser processada é muito grande, o treinamento direto não é prático. Portanto, um método é proposto no artigo Vision Transformer [5]: dividir a imagem original em blocos de imagem (Patch) do mesmo tamanho e, em seguida, serializar esses blocos de imagem e adicionar suas informações de posição (Position Embedding), de modo que imagens complexas pode ser convertido nas sequências mais familiares da arquitetura do Transformer, usando o mecanismo de autoatenção para capturar o relacionamento entre cada bloco de imagem e, por fim, compreender o conteúdo de toda a imagem.
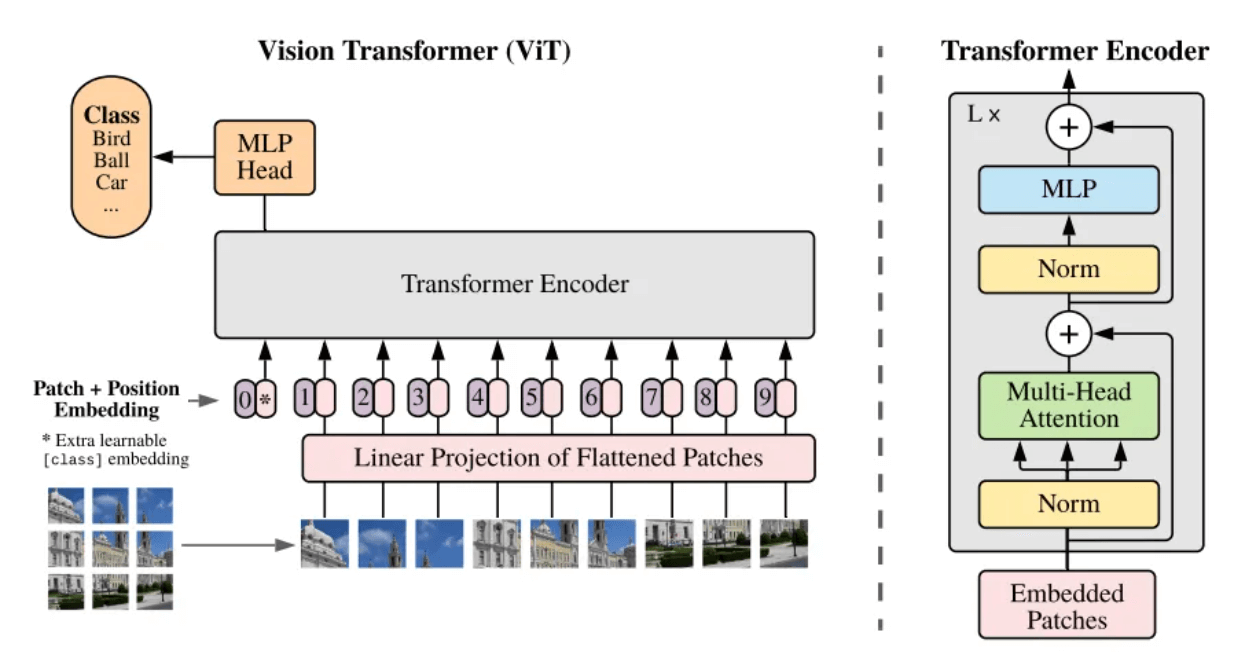
Estrutura estrutural do modelo ViT[5]
O vídeo pode ser visto como uma sequência de imagens distribuídas ao longo do eixo do tempo, então Sora adiciona a dimensão do tempo, atualizando blocos de imagens estáticas em patches de imagens do espaço-tempo (Spacetime Patches). Cada bloco de imagem espaço-temporal contém informações temporais e espaciais no vídeo. Ou seja, um bloco de imagem espaço-temporal não representa apenas uma pequena área espacial no vídeo, mas também representa as mudanças nesta área espacial durante um período de tempo. tempo.
Ao introduzir o conceito de patch, a correlação espacial pode ser calculada para blocos de imagem espaço-temporais em diferentes posições em um único quadro; a correlação temporal pode ser calculada para blocos de imagem espaço-temporais na mesma posição em quadros consecutivos; Cada bloco de imagem não existe mais isoladamente, mas está intimamente ligado aos elementos circundantes. Desta forma, Sora é capaz de compreender e gerar conteúdo de vídeo com ricos detalhes espaciais e dinâmica temporal.

Decompor quadros de sequência em blocos de imagem espaço-temporais
- Resolução nativa(NaViT)
Porém, o modelo ViT tem uma grande desvantagem - a imagem original deve ser quadrada e cada bloco de imagem tem o mesmo tamanho fixo. Os vídeos diários são apenas largos ou altos e não há vídeos quadrados.
Portanto, a OpenAI encontrou outra solução: a tecnologia "Patch n' Pack" [6] no NaViT , que pode processar conteúdo de entrada de qualquer resolução e proporção de aspecto.
Esta tecnologia divide o conteúdo com diferentes proporções e resoluções em blocos de imagens. Esses blocos de imagens podem ser redimensionados de acordo com diferentes necessidades. Os blocos de imagens de diferentes imagens podem ser empacotados de forma flexível na mesma sequência para treinamento unificado. Além disso, esta tecnologia também pode descartar blocos de imagens idênticos com base na semelhança das imagens, reduzindo significativamente o custo de treinamento e conseguindo um treinamento mais rápido.
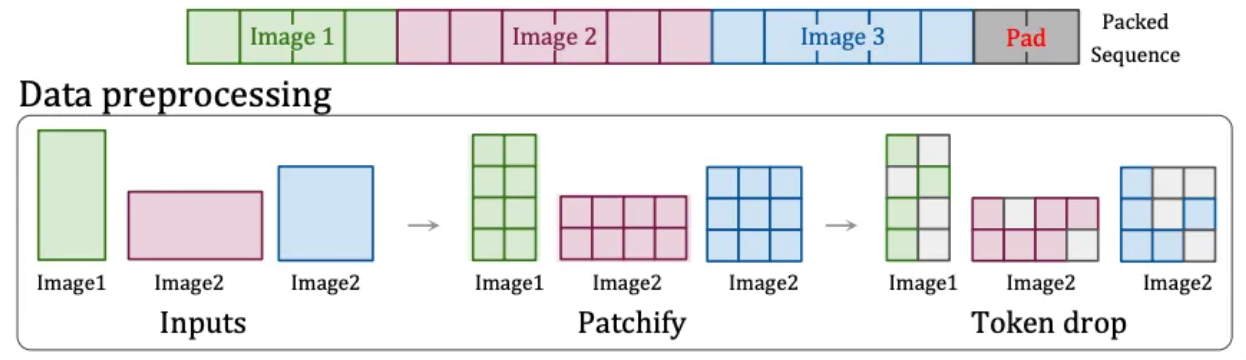
Tecnologia Patch n'Pack[6]
É por isso que Sora pode suportar a geração de vídeos de diferentes resoluções e proporções. Além disso, o treinamento com a proporção nativa pode melhorar a composição e o enquadramento do vídeo de saída, porque o corte inevitavelmente perderá informações e o modelo facilmente interpretará mal o conteúdo principal da imagem original, resultando em uma imagem com apenas parte do principal. corpo.
O papel desempenhado pelos Patches de Espaço-Tempo é o mesmo que o papel do Token no modelo de linguagem grande. É a unidade básica do vídeo. Quando compactamos e decompomos um vídeo em uma série de patches espaço-temporais, na verdade convertemos a informação visual contínua em. Uma série de unidades discretas que podem ser processadas pelo modelo, que são a base para o aprendizado e geração do modelo.
2.3 Descrição do texto do vídeo
Através da explicação acima, entendemos o processo de Sora converter vídeos originais em vetores espaço-temporais finais treináveis. Mas há um problema que precisa ser resolvido antes do treinamento propriamente dito: contar ao modelo do que se trata este vídeo.
Para treinar um modelo de vídeo Wensheng, é necessário estabelecer uma correspondência entre texto e vídeo . Durante o treinamento, é necessário um grande número de vídeos com descrições de texto correspondentes. No entanto, a qualidade das descrições anotadas manualmente é baixa e irregular, o que afeta a qualidade. resultados de treinamento. Portanto, a OpenAI pegou emprestada a tecnologia de re-captioning [7] do seu próprio DALL·E 3 e aplicou-a ao campo do vídeo.
Especificamente, o OpenAI primeiro treinou um modelo de geração de legendas altamente descritivo e usou esse modelo para gerar informações de descrição detalhadas para todos os vídeos no conjunto de treinamento de acordo com as especificações. Esta parte das informações de descrição do texto foi combinada com os patches de imagem espaço-temporais mencionados anteriormente durante o final. Após o treinamento e correspondência, Sora pode entender e corresponder à descrição do texto e aos blocos de imagens de vídeo.
Além disso, a OpenAI também usará GPT para converter as breves instruções do usuário em frases de descrição mais detalhadas, semelhantes às do treinamento, o que permite que Sora siga com precisão as instruções do usuário e gere vídeos de alta qualidade.
2.4 Treinamento e geração de vídeo
Está claramente mencionado no relatório técnico oficial [1] que Sora é um transformador de difusão, ou seja, Sora é um modelo de difusão com Transformer como rede backbone.
- Transformador de transmissão (DiT)
O conceito de Difusão vem do processo de difusão na física. Por exemplo, quando uma gota de tinta é lançada na água, ela se espalha lentamente ao longo do tempo. Essa difusão é o processo de baixa entropia a alta entropia. irá dispersar gradualmente de uma gota para várias partes da água.
Inspirado neste processo de difusão, nasceu o Modelo de Difusão. É um modelo clássico de "desenho" no qual se baseiam Stable Diffusion e Midjourney. Seu princípio básico é adicionar gradativamente ruído à imagem original, permitindo que ela se torne gradativamente um estado de ruído completo, e depois reverter esse processo, ou seja, eliminar ruído (Denoise) para restaurar a imagem. Ao permitir que o modelo aprenda um grande número de experiências de reversão, o modelo eventualmente aprende a gerar conteúdo de imagem específico a partir da imagem de ruído.
De acordo com o relatório, o método de Sora provavelmente substituirá a arquitetura U-Net no modelo Diffusion original pela arquitetura Transformer com a qual ele está mais familiarizado. Porque de acordo com a experiência em outras tarefas de aprendizagem profunda, em comparação com o U-Net, os parâmetros da arquitetura Transformer são altamente escaláveis. À medida que o número de parâmetros aumenta, a melhoria de desempenho da arquitetura Transformer será mais óbvia.
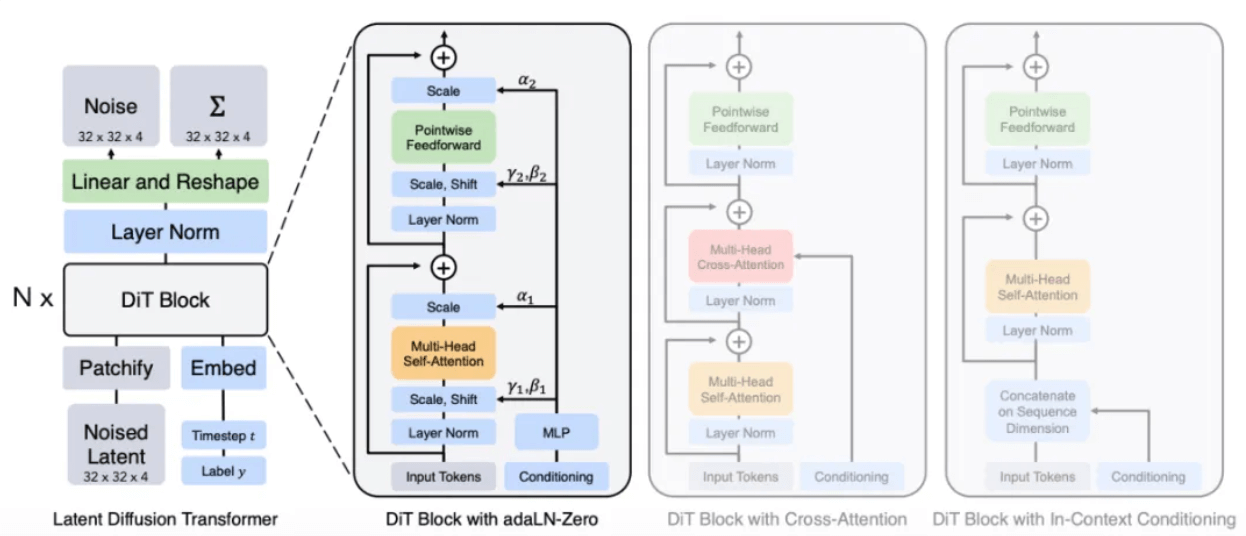
Arquitetura do modelo DiT[8]
Através de um processo semelhante ao modelo de difusão, patches de ruído (e informações condicionais, como prompts de texto) são fornecidos durante o treinamento, e o ruído é adicionado e eliminado repetidamente e, finalmente, o modelo aprende a prever os patches originais.

Restaure o patch de ruído para o patch de imagem original
- Processo de geração de vídeo
Por fim, resumimos todo o processo de geração de vídeos do Sora a partir de texto.
Quando o usuário insere uma descrição de texto, Sora primeiro chama o modelo para expandi-lo em uma frase de descrição de vídeo padrão e, em seguida, gera um bloco de imagem espaço-temporal inicial a partir do ruído com base na descrição. com base no bloco de imagem espaço-temporal existente e nas condições de texto, o próximo bloco de imagem espaço-temporal é especulado para ser gerado (semelhante ao GPT prevendo o próximo Token com base no Token existente) e, finalmente, a representação potencial gerada é mapeada de volta para. o espaço de pixel através do decodificador correspondente para formar um vídeo.
3 O potencial da computação de dados
Olhando para o relatório técnico de Sora, podemos descobrir que, na verdade, Sora não alcançou um grande avanço tecnológico, mas integrou bem o trabalho de pesquisa anterior. Afinal, nenhuma tecnologia aparecerá repentinamente. A razão mais crítica para o sucesso de Sora é o acúmulo de poder computacional e de dados.
Sora mostra efeitos de escala óbvios durante o processo de treinamento. A figura abaixo mostra que para insumos e sementes fixos, à medida que a quantidade de cálculo aumenta, a qualidade das amostras geradas melhora significativamente.

Comparação dos efeitos sob poder de computação básico, 4 vezes poder de computação e 32 vezes poder de computação
Além disso, ao aprender com grandes quantidades de dados, Sora também demonstrou algumas habilidades inesperadas.
➢ Consistência 3D: Sora é capaz de gerar vídeos com movimentos dinâmicos de câmera. À medida que a câmera se move e gira, os personagens e os elementos da cena sempre mantêm padrões de movimento consistentes no espaço tridimensional.
➢Consistência a longo prazo e persistência do objeto: Em planos gerais, pessoas, animais e objetos mantêm uma aparência consistente mesmo depois de serem ocluídos ou saírem do enquadramento.
➢Interatividade mundial : Sora pode simular comportamentos que afetam o estado do mundo de uma forma simples. Por exemplo, no vídeo que descreve a pintura, cada pincelada deixa uma marca na tela.
➢Simular o mundo digital: Sora também pode simular vídeos de jogos, como "Minecraft".
Estas propriedades não requerem uma tendência indutiva explícita para objetos 3D, etc., são puramente um fenômeno de efeitos de escala.
4 Sistema de computação de dados de modelo grande Tuoshupai
O sucesso de Sora prova mais uma vez a eficácia da estratégia “maior poder faz milagres” - a expansão contínua da escala do modelo promoverá diretamente a melhoria do desempenho, que é altamente dependente de um grande número de conjuntos de dados de alta qualidade e ultra- poder de computação em grande escala. Dados e computação são indispensáveis.
No início da sua criação, Tuoshupai posicionou a sua missão como “computação de dados, apenas para novas descobertas”, e o nosso objetivo é criar um “modelo de jogo infinito”. Seu sistema de computação de dados de grande modelo usa tecnologia nativa da nuvem para reconstruir o armazenamento e a computação de dados, com um armazenamento e computação de dados multimotor, tornando os modelos de IA maiores e mais rápidos e atualizando de forma abrangente o sistema de big data para a era dos grandes modelos.
No sistema de computação de dados de modelo grande, tudo no mundo e seus movimentos podem ser digitalizados em dados. Os dados podem ser usados para treinar o modelo inicial. O modelo treinado forma regras de cálculo e é então adicionado ao sistema de computação de dados. o processo continua a iterar e explorar infinitamente a inteligência da IA. No futuro, Tuoshupai continuará a explorar a área de dados, fortalecerá as principais capacidades de pesquisa tecnológica, trabalhará com parceiros da indústria para explorar as melhores práticas na indústria de elementos de dados e promoverá a tomada de decisões digitais inteligentes.
Nota: O relatório técnico oficial da OpenAI mostra apenas o método geral de modelagem e não envolve quaisquer detalhes de implementação. Se houver algum erro neste artigo, corrija-me e comunique-se comigo.
referências:
- [1] Modelos de geração de vídeo como simuladores mundiais
- [2] Sistema de computação de dados de grande modelo - teoria
- [3] Síntese de imagens de alta resolução com modelos de difusão latente
- [4] Atenção é tudo que você precisa
- [5] Uma imagem vale 16×16 palavras: transformadores para reconhecimento de imagem em escala
- [6] Patch n'Pack: NaViT, um transformador de visão para qualquer proporção e resolução
- [7] Melhorando a geração de imagens com legendas melhores
- [8] Modelos de Difusão Escaláveis com Transformadores