
Todos são bem-vindos para nos estrelar no GitHub:
Sistema distribuído de aprendizagem causal de link completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grande gráfico de conhecimento baseado em modelo OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizagem de gráficos em grande escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Em menos de 5 anos, a tecnologia de grandes modelos e transformadores mudou quase completamente o campo do processamento de linguagem natural e começou a revolucionar campos como visão computacional e biologia computacional. Dr. Sebastian Raschka se concentra em artigos de pesquisa acadêmica e preparou uma lista de leitura introdutória para pesquisadores e profissionais de aprendizado de máquina. Depois de lê-lo na ordem, você pode realmente começar no campo atual da tecnologia de grandes modelos.
Claro, o Dr. Sebastian Raschka também mencionou que existem muitos outros recursos úteis, como:
- Jay Alammar 《Transformador Ilustrado》;
- Mais postagens técnicas de Lilian Weng;
- Todos os catálogos e genealogia de Transformers organizados por Xavier Amatriain;
- Uma implementação de código mínimo de um modelo de linguagem generativa escrito para fins educacionais por Andrej Karpathy;
- e uma série de palestras e capítulo de livro do autor deste artigo.
Entenda a principal arquitetura e tarefas
Se você é novo em Transformers/modelos grandes, faz mais sentido começar do zero.
1. Tradução automática neural por Joint Learning to Align and Translate (2014)
Autor: Bahdanau, Cho Wa Bengio
Link do artigo: https://arxiv.org/abs/1409.0473
Se você tiver alguns minutos de sobra, recomendo começar com este artigo. Este artigo apresenta um mecanismo de atenção para redes neurais recorrentes (RNN) para aprimorar as capacidades de modelagem de sequências longas. Isso permite que os RNNs traduzam frases mais longas com mais precisão – que foi a motivação por trás do desenvolvimento da arquitetura original do Transformer.
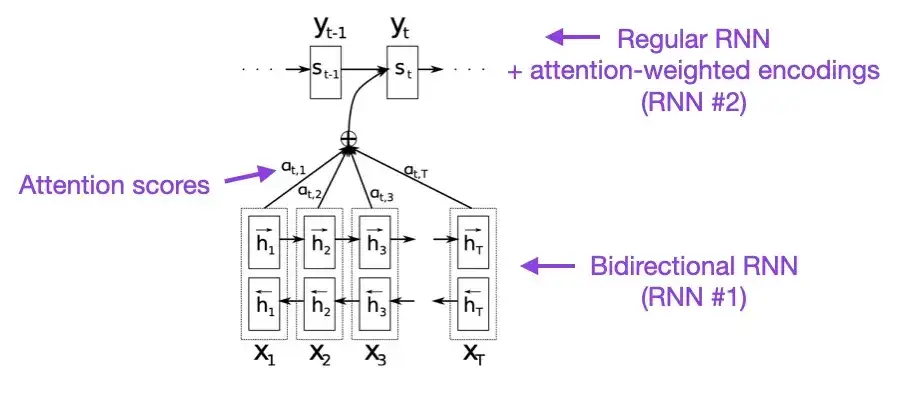
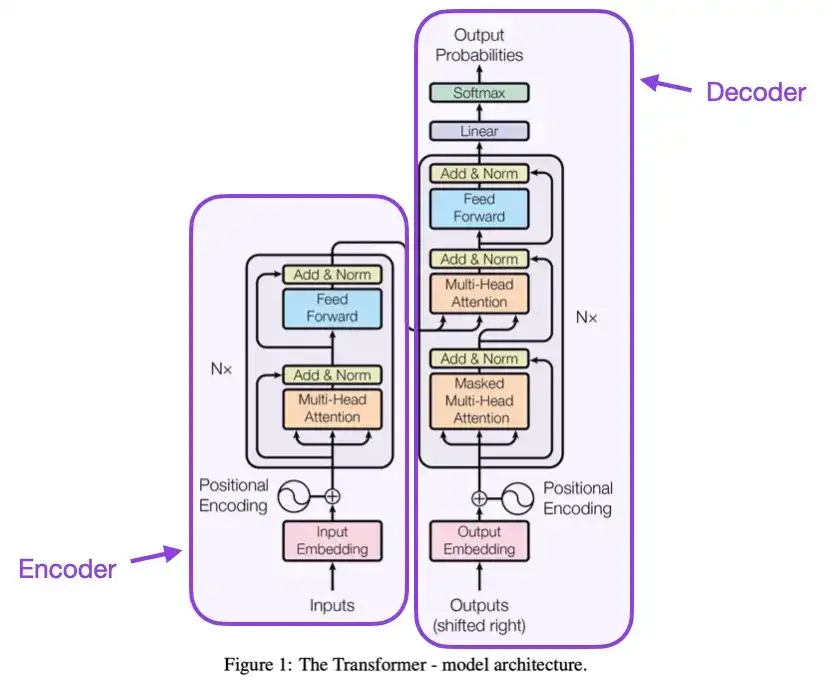
2. Atenção é tudo que você precisa (2017)
Créditos: Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser e Polosukhin
Link do artigo: https://arxiv.org/abs/1706.03762
Este artigo apresenta a arquitetura original do Transformer, que consiste em duas partes: um codificador e um decodificador. Essas duas partes posteriormente se tornarão módulos independentes para explicação. Além disso, este artigo também introduziu conceitos como escalonamento de mecanismos de atenção de produto escalar, blocos de atenção com múltiplas cabeças e codificação de entrada posicional, que ainda são a base dos modelos modernos de Transformer.
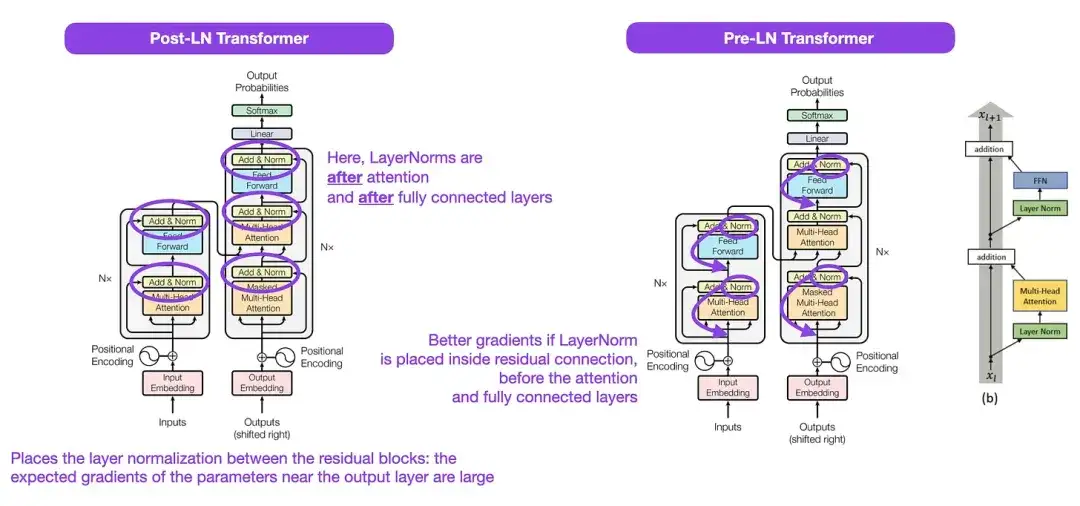
3. Sobre normalização de camadas na arquitetura do transformador __ (2020)
Autores: Yang, He, K Zheng, S Zheng, Xing, Zhang, Lan, Wang, Liu
Link do artigo: https://arxiv.org/abs/2002.04745
Embora a estrutura original do Transformer mostrada na figura acima seja um resumo muito bom da arquitetura original do codificador-decodificador, a posição do LayerNorm na figura tem sido controversa. Por exemplo, o diagrama de estrutura do Transformer em "Attention Is All You Need" coloca LayerNorm entre blocos residuais, o que é inconsistente com a implementação de código oficial (atualizada) que acompanha o artigo original do Transformer. A variante mostrada na imagem de "Atenção é tudo que você precisa" é chamada Post-LN Transformer, e a implementação de código atualizada usa a variante Pré-LN por padrão.
No artigo “Normalização de camadas na arquitetura do transformador”, aponta-se que o Pré-LN funciona melhor e pode resolver o problema do gradiente. Conforme mostrado abaixo, muitas arquiteturas adotam essa abordagem na prática, mas ela pode levar ao colapso da representação. Portanto, enquanto a discussão sobre o uso de Pós-LN ou Pré-LN continua, um novo artigo "ResiDual: Transformador com conexões residuais duplas" ( https://arxiv.org/abs/2304.14802 ) propõe utilizar ambas as vantagens; sua eficácia na prática ainda está para ser vista.
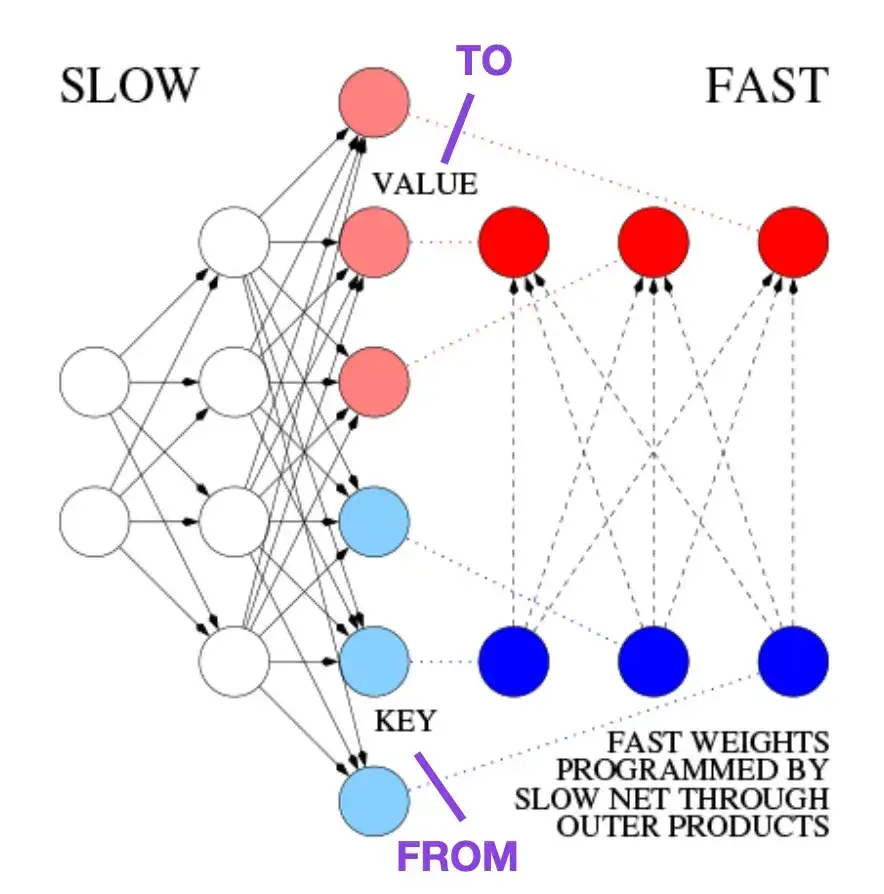
4. Aprendendo a controlar memórias de peso rápido: uma alternativa para redes neurais recorrentes dinâmicas __ (1991)
Autor: Schmidhuber
Link do papel:
Este artigo é recomendado para leitores interessados em anedotas históricas e tecnologias iniciais semelhantes à arquitetura moderna do Transformer. Por exemplo, em 1991, aproximadamente 25 anos antes do artigo original do Transformer, Atenção é tudo que você precisa , Juergen Schmidhuber propôs um Fast Weight Programmer (FWP) como alternativa às redes neurais recorrentes. O método FWP envolve uma rede neural feedforward que aprende lentamente por meio de gradiente descendente para programar as rápidas mudanças de peso de outra rede neural. A analogia com um Transformer moderno é explicada na seguinte postagem do blog:
Na terminologia atual do Transformer, FROM e TO são chamados de chaves e valores, respectivamente. A INPUT usada por redes rápidas é chamada de consulta. Essencialmente, a consulta é processada por meio de uma matriz de pesos rápida, que é a soma dos produtos externos de chaves e valores (ignorando normalização e projeção). Como todas as operações de ambas as redes são diferenciáveis, obtemos controle ativo diferenciável ponta a ponta de mudanças rápidas de peso através da adição de produtos externos ou produtos tensoriais de segunda ordem. Portanto, a rede lenta pode ser aprendida via gradiente descendente, modificando rapidamente a rede rápida durante o processamento da sequência. Isso é matematicamente equivalente (exceto pela normalização) ao que ficou conhecido como Transformador Linear de Autoatenção (ou Transformador Linear).
Conforme mencionado no trecho da postagem do blog acima, essa abordagem agora é conhecida como “Transformador Linear” ou “Transformador com autoatenção linearizada”. Posteriormente, a equivalência entre a autoatenção linearizada e os programadores de peso rápidos da década de 1990 foi claramente demonstrada no artigo de 2021 "Transformadores lineares são programadores de peso secretamente rápidos".
5. Ajuste fino do modelo de linguagem universal para classificação de texto (2018)
Autor; Howard, Ruder
Endereço do artigo: https://arxiv.org/abs/1801.06146
Este é um artigo muito interessante do ponto de vista histórico. Foi escrito um ano após o lançamento de "Attention Is All You Need", mas não envolvia o Transformer, mas focava em redes neurais recorrentes. No entanto, ainda merece atenção, pois propõe efetivamente modelos de linguagem pré-treinados e transfere a aprendizagem para tarefas posteriores. Embora a aprendizagem por transferência esteja bem estabelecida no campo da visão computacional, ela ainda não se tornou popular no processamento de linguagem natural (PNL). ULMFit é um dos primeiros artigos a demonstrar modelos de linguagem pré-treinados e ajustá-los para tarefas específicas, resultando em resultados de última geração em muitas tarefas de PNL.
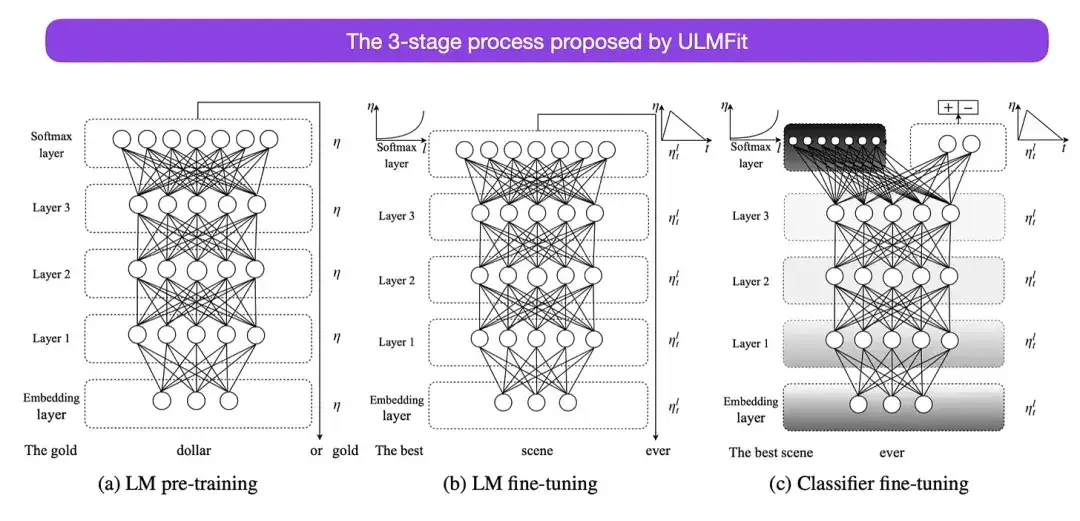
O processo de três estágios de ajuste fino dos modelos de linguagem proposto pelo ULMFit é o seguinte:
- Treine um modelo de linguagem em um grande corpus de texto;
- Ajuste este modelo de linguagem pré-treinado em dados específicos da tarefa para adaptá-lo ao estilo e vocabulário do texto específico;
- Evite o esquecimento catastrófico descongelando gradualmente as camadas enquanto ajusta o classificador em dados específicos da tarefa.
Este método - primeiro treinar um modelo de linguagem em um grande corpus e, em seguida, ajustá-lo para tarefas posteriores - é o método central dos modelos baseados em Transformer e modelos básicos (como BERT, GPT-2/3/4, RoBERTa, etc.). No entanto, a parte principal do ULMFit, o descongelamento gradual, geralmente não é executado rotineiramente durante a operação da arquitetura do conversor e, geralmente, todas as camadas são ajustadas de uma só vez.
6. BERT: Pré-treinamento de transformadores bidirecionais profundos para compreensão de linguagem **** (2018)
Elenco: Devlin, Chang, Lee, Toutanova
Link do artigo: https://arxiv.org/abs/1810.04805
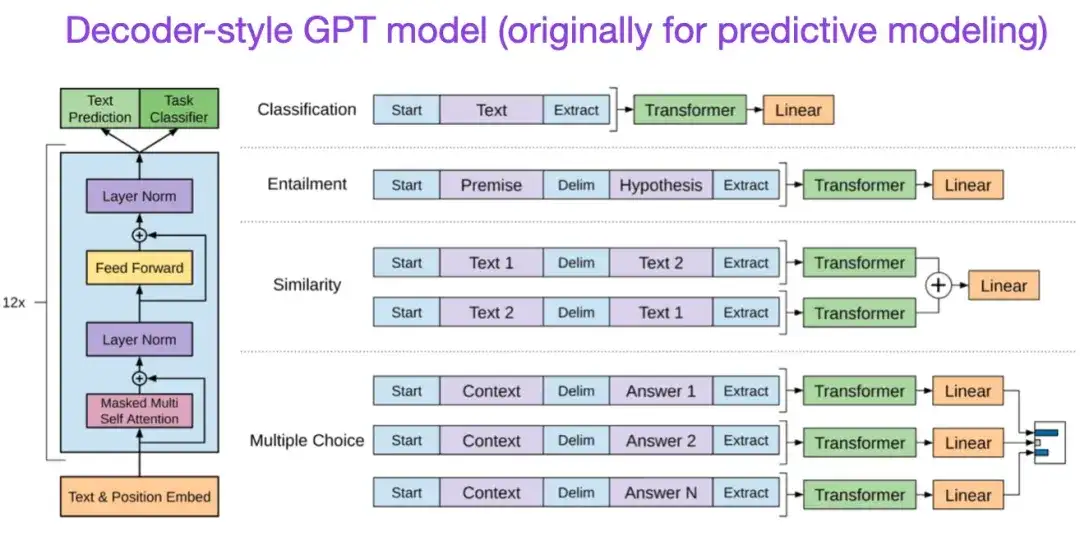
De acordo com a arquitetura original do Transformer, a pesquisa em modelos de linguagem em larga escala começou a divergir em duas direções: Transformers baseados em codificador para tarefas de modelagem preditiva (como classificação de texto) e tarefas de modelagem generativa (como tradução, resumo e decodificador A). estilo Transformer para outras formas de criação de texto).
O artigo BERT mencionado acima introduziu os conceitos originais de modelagem de linguagem mascarada e previsão da próxima frase, e continua sendo a arquitetura de estilo de codificador mais influente. Se você estiver interessado neste ramo de pesquisa, recomendo que continue aprendendo sobre o RoBERTa, que simplifica o objetivo do pré-treinamento ao remover a tarefa de previsão da próxima frase.
** 7. Melhorando a compreensão da linguagem por meio de pré-treinamento generativo (2018) ** Autor: Radford e Narasimhan Endereço do artigo:
O artigo original do GPT introduziu a popular arquitetura de estilo decodificador e o pré-treinamento por meio da previsão da próxima palavra. Enquanto o BERT pode ser visto como um transformador bidirecional devido ao seu objetivo de pré-treinamento do modelo de linguagem mascarada, o GPT é um modelo autoregressivo unilateral. Embora os embeddings GPT também possam ser usados para classificação, os métodos GPT estão no centro dos grandes modelos de linguagem (LLMs) mais influentes da atualidade, como o ChatGPT.
Se você estiver interessado nesta direção de pesquisa, recomendo que continue aprendendo mais sobre os artigos relacionados ao GPT-2 e GPT-3. Esses dois artigos demonstram que os LLMs podem alcançar aprendizado de zero e poucos disparos e destacam as capacidades emergentes dos LLMs. GPT-3 ainda é o modelo básico e de base mais comumente usado para o treinamento do LLM atual. A tecnologia InstructGPT que deu origem ao ChatGPT será apresentada em uma entrada separada posteriormente.
Artigos relacionados ao GPT2: https://www.semanticscholar.org/paper/Language-Models-are-Unsupervised-Multitask-Learners-Radford-Wu/9405cc0d6169988371b2755e573cc28650d14dfe
Artigos relacionados ao GPT3: https://arxiv.org/abs/2005.14165
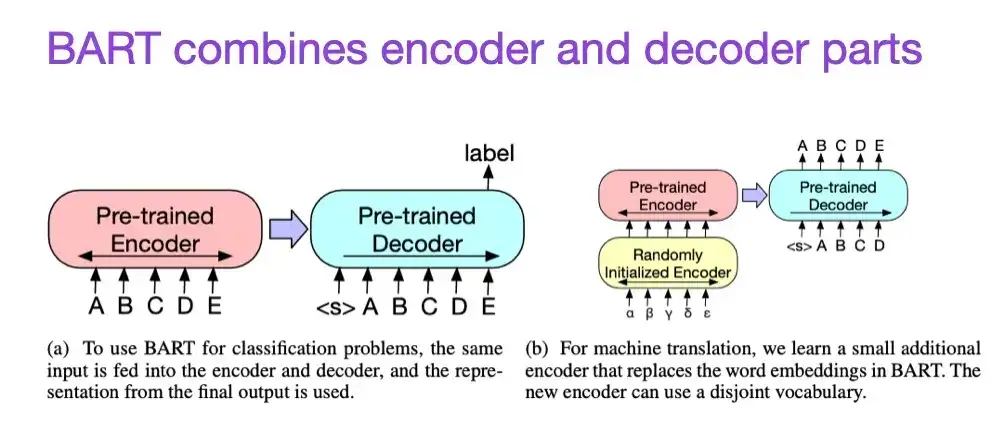
8. BART: Pré-treinamento de eliminação de ruído sequência a sequência para geração, tradução e compreensão de linguagem natural (2019)
Elenco: Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov, Zettlemoyer
Link do artigo: https://arxiv.org/abs/1910.13461 .
Conforme mencionado anteriormente, os grandes modelos de linguagem (LLMs) do tipo codificador do tipo BERT são geralmente mais adequados para tarefas de modelagem preditiva, enquanto os LLMs do estilo decodificador do tipo GPT são melhores na geração de texto. Para combinar o melhor dos dois mundos, o artigo BART mencionado acima combina as partes do codificador e do decodificador (que é semelhante à estrutura original do Transformer apresentada no segundo artigo).
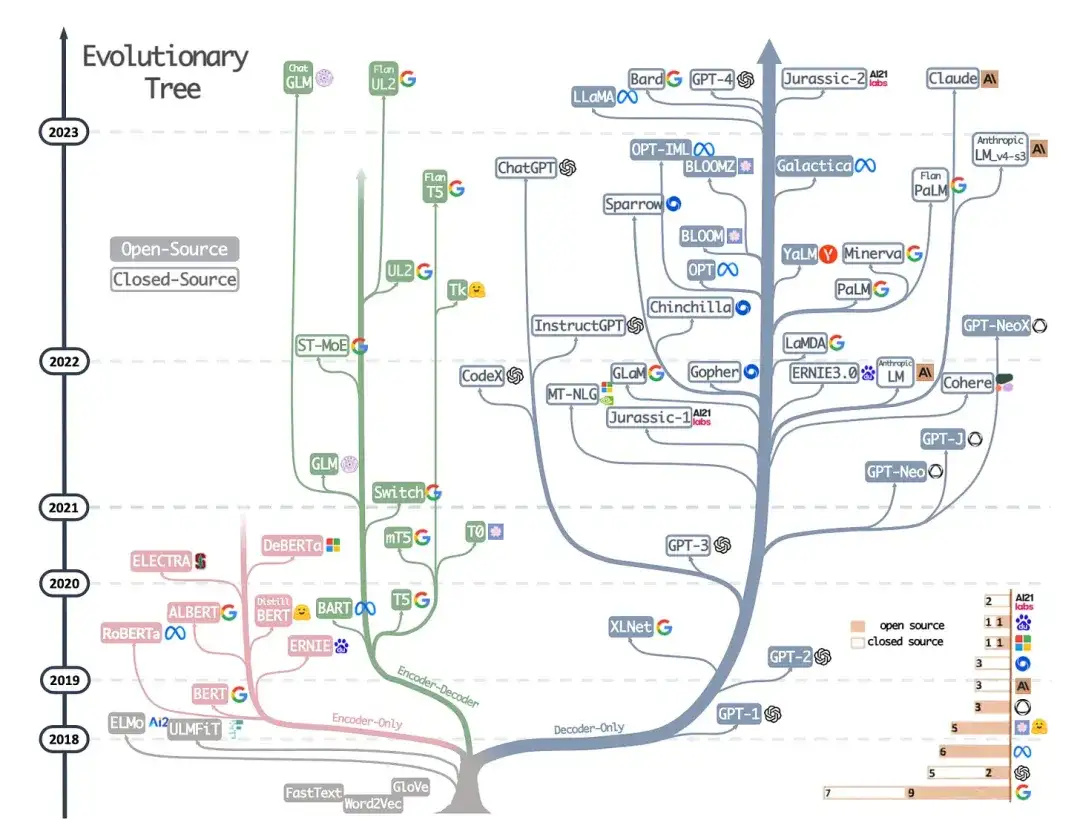
9. Aproveitando o poder dos LLMs na prática: uma pesquisa sobre ChatGPT e além (2023)
Autor: Yang, Jin, Tang, Han, Feng, Jiang, Yin, Hu,
Link do artigo: https://arxiv.org/abs/2304.13712
Este não é um artigo de pesquisa, mas é provavelmente o melhor artigo de visão geral da arquitetura até agora e mostra vividamente como as diferentes arquiteturas evoluíram. No entanto, além de discutir modelos de linguagem mascarada (codificadores) no estilo BERT e modelos de linguagem autorregressiva (decodificadores) no estilo GPT, ele também fornece discussão e orientação úteis sobre pré-treinamento e ajuste fino de dados.
Dimensionando leis e melhorando a eficiência
Se você quiser aprender mais sobre várias técnicas para melhorar a eficiência do transformador, recomendo a leitura do artigo de 2020 "Transformadores eficientes: uma pesquisa" e do artigo de 2023 "Uma pesquisa sobre treinamento eficiente de transformadores". Além disso, aqui estão alguns artigos que achei particularmente interessantes e que valem a pena ler.
- 《Transformadores Eficientes: Uma Pesquisa》:
https://arxiv.org/abs/2009.06732
- 《Uma Pesquisa sobre Treinamento Eficiente de Transformadores》:
https://arxiv.org/abs/2302.01107
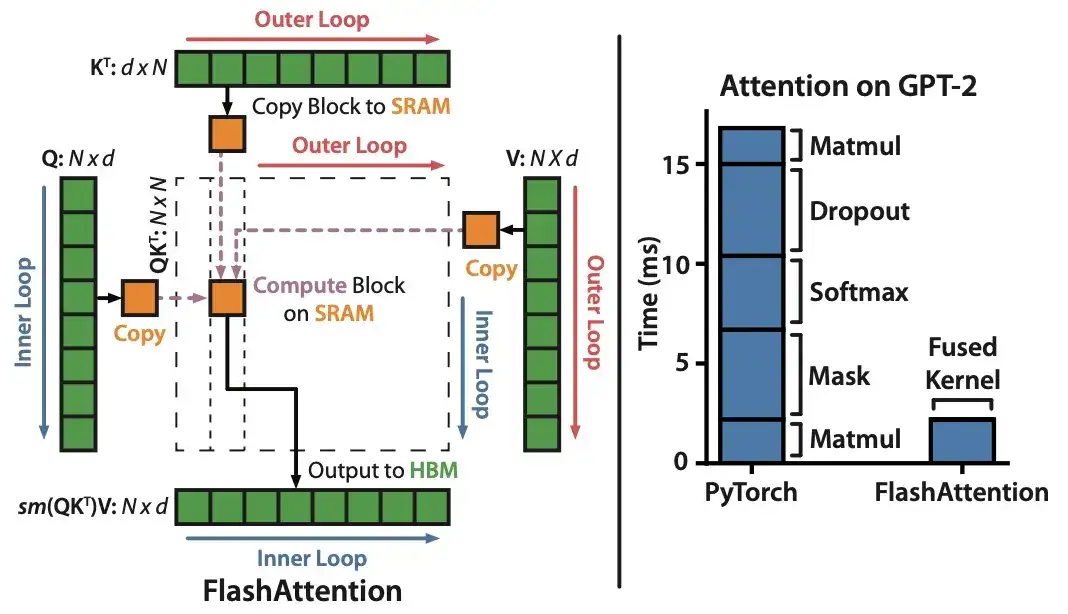
10. FlashAttention: atenção exata rápida e com uso eficiente de memória com IO-Awareness (2022)
Autor: Dao, Fu, Ermon, Rudra, Ré
Link do artigo: https://arxiv.org/abs/2205.14135 .
Embora a maioria dos artigos do Transformer não se preocupem em substituir o mecanismo de produto escalar original para obter autoatenção, o único mecanismo que vejo citado mais recentemente é o FlashAttention.
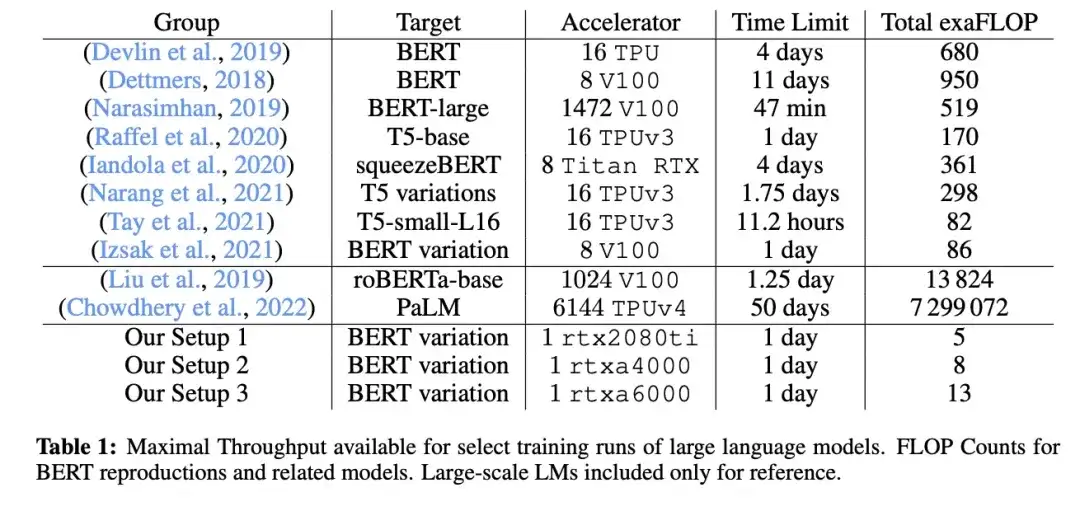
11. Cramming: treinando um modelo de linguagem em uma única GPU em um dia (2022)
_Autor:_Geiping e Goldstein,
Link do artigo: https://arxiv.org/abs/2212.14034
Neste artigo, os pesquisadores usaram uma única GPU para treinar um modelo de linguagem mascarado/modelo de linguagem grande estilo codificador (aqui BERT) por 24 horas. Para efeito de comparação, o artigo original do BERT em 2018 foi treinado em 16 TPUs durante quatro dias. Uma descoberta interessante é que, embora modelos menores tenham maior rendimento, eles também aprendem com menos eficiência. Portanto, modelos maiores não requerem tempos de treinamento mais longos para atingir um determinado limite de desempenho preditivo.
12. LoRA: Adaptação de baixo nível de modelos de linguagem grande (2021)
Autor: por Hu, Shen, Wallis, Allen-Zhu, Li, L Wang, S Wang, Chen
Link do artigo: https://arxiv.org/abs/2106.09685 .
Os modelos modernos de linguagem de grande escala exibem capacidades emergentes através de pré-treinamento em conjuntos de dados de grande escala e funcionam bem em uma variedade de tarefas, incluindo tradução de idiomas, geração de resumos, programação e resposta a perguntas. No entanto, há valor no ajuste fino de um transformador para melhorar suas capacidades em dados específicos de domínio e em tarefas especializadas. A adaptação de baixa classificação (LoRA) é um dos métodos mais influentes para o ajuste fino com eficiência de parâmetros de grandes modelos de linguagem.
Embora existam outros métodos para ajuste fino de parâmetros eficientes, o LoRA merece atenção especial porque é elegante e muito geral e pode ser aplicado a outros tipos de modelos. Os pesos de um modelo pré-treinado têm classificação completa na tarefa para a qual foram pré-treinados, enquanto os autores do LoRA observam que grandes modelos de linguagem têm menor “dimensionalidade intrínseca” quando são adaptados a novas tarefas. Portanto, a ideia central do LoRA é decompor a mudança de peso ΔW em representações de classificação inferior para obter maior eficiência dos parâmetros.

13_. Reduzindo para aumentar: um guia para ajuste fino com eficiência de parâmetros (2022)_
Autor: Lialin, Deshpande, Rumshisky
Link do artigo: https://arxiv.org/abs/2303.15647 .
Esta revisão revisa mais de 40 artigos sobre métodos eficientes de ajuste fino de parâmetros (abrangendo técnicas populares como ajuste de prefixo, adaptadores e adaptação de baixa classificação), com o objetivo de tornar o processo de ajuste fino (extremamente) computacionalmente eficiente.
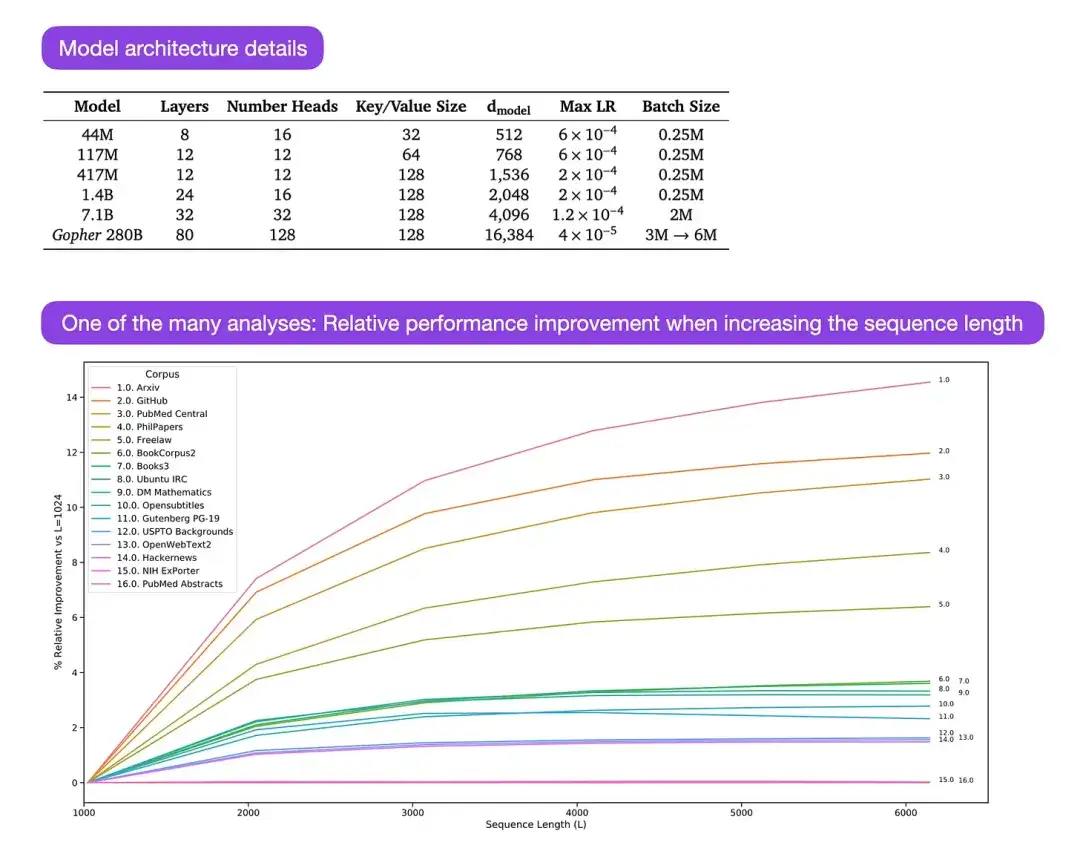
** 14. Escalando modelos de linguagem: métodos, análises e insights do Training Gopher (2022)** Autor: Rae e 78 colegas
Link do artigo: https://arxiv.org/abs/2112.11446
Gopher é um artigo particularmente bom que contém muitas análises para compreender o processo de treinamento de grandes modelos de linguagem (LLM). O pesquisador treinou um modelo com parâmetros de 280B e 80 camadas aqui. O modelo foi treinado com base em tokens de 300B. Ele contém algumas melhorias arquitetônicas interessantes, como o uso de RMSNorm (normalização quadrática média) em vez de LayerNorm (normalização de camada). Tanto o LayerNorm quanto o RMSNorm são preferidos ao BatchNorm porque não dependem do tamanho do lote e não exigem sincronização, o que é especialmente vantajoso ao usar lotes menores em configurações distribuídas. No entanto, acredita-se geralmente que o RMSNorm é mais eficaz na estabilização do processo de treinamento de arquiteturas profundas.
Além desses detalhes interessantes, o foco principal do artigo é a análise do desempenho de tarefas em diferentes escalas. Avaliações de 152 tarefas diversas mostram que o aumento do tamanho do modelo tem o efeito de melhoria mais significativo em tarefas como compreensão, verificação de fatos e identificação de linguagem prejudicial. Entretanto, tarefas relacionadas ao raciocínio lógico e matemático se beneficiam menos das extensões arquiteturais.
15. Treinamento de modelos de linguagem grande com otimização de computação (2022)
Elenco: Hoffmann, Borgeaud, Mensch, Buchatskaya, Cai, Rutherford, de Las Casas, Hendricks, Welbl, Clark, Hennigan, Noland, Millican, van den Driessche, Damoc, Guy, Osindero, Simonyan, Elsen, Rae, Vinyals, e Sifre
Link do artigo: https://arxiv.org/abs/2203.15556 .
Este artigo apresenta um modelo de parâmetros de 70B chamado Chinchilla, que supera o popular modelo GPT-3 de 175B em tarefas de modelagem generativa. No entanto, seu ponto central é apontar que os atuais modelos de grandes linguagens estão "significativamente subtreinados". O artigo define uma lei de escala linear para treinamento de modelos de linguagem de grande porte. Por exemplo, embora o Chinchilla tenha apenas metade do tamanho do GPT-3, ele supera o GPT-3 porque foi treinado em 1,4 trilhão de tokens (em vez de apenas 300 bilhões). Em outras palavras, o número de tokens de treinamento é tão importante quanto o tamanho do modelo.
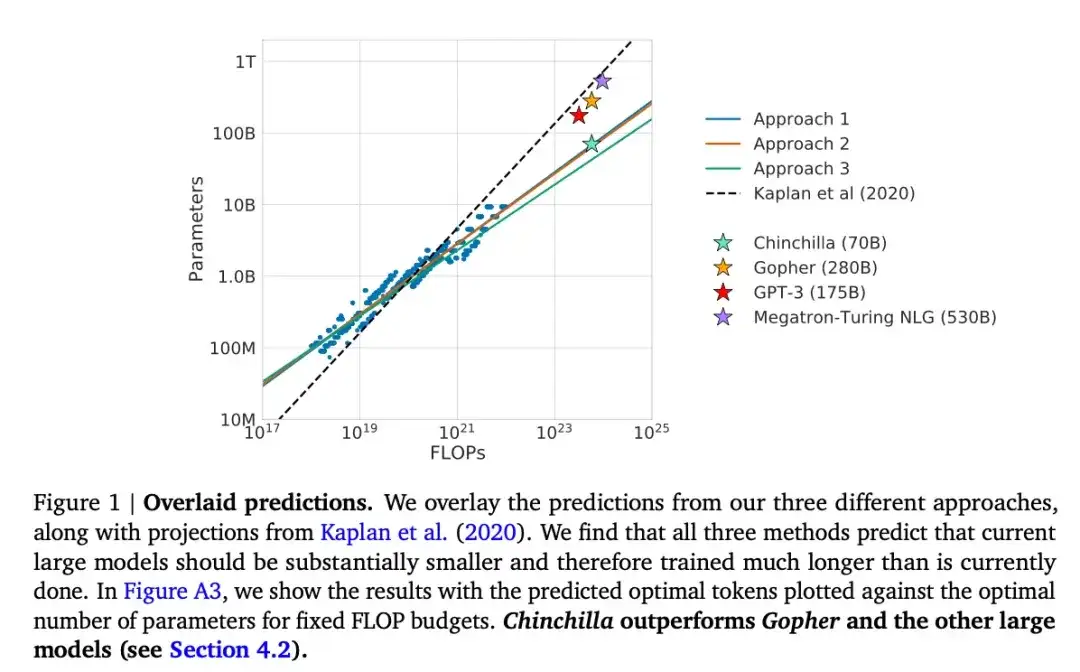
16.Pythia : um conjunto para análise de grandes modelos de linguagem em treinamento e escalonamento (2023)
Elenco: Biderman, Schoelkopf, Anthony, Bradley, O'Brien, Hallahan, Khan, Purohit, Prashanth, Raff, Skowron, Sutawika, e van der Wal
Link do artigo: https://arxiv.org/abs/2304.01373
Pythia é uma série de modelos de linguagem grande de código aberto (variando de parâmetros de 700M a 12B), projetados para estudar a evolução de modelos de linguagem grande durante o processo de treinamento. Sua arquitetura é semelhante ao GPT-3, mas inclui algumas melhorias, como Flash Attention (semelhante ao LLaMA) e Rotary Positional Embeddings (semelhante ao PaLM). Pythia é treinado no conjunto de dados The Pile (825 Gb) e o treinamento usa tokens de 300B (aproximadamente equivalente a 1 época no PILE regular ou 1,5 épocas no PILE desduplicado).
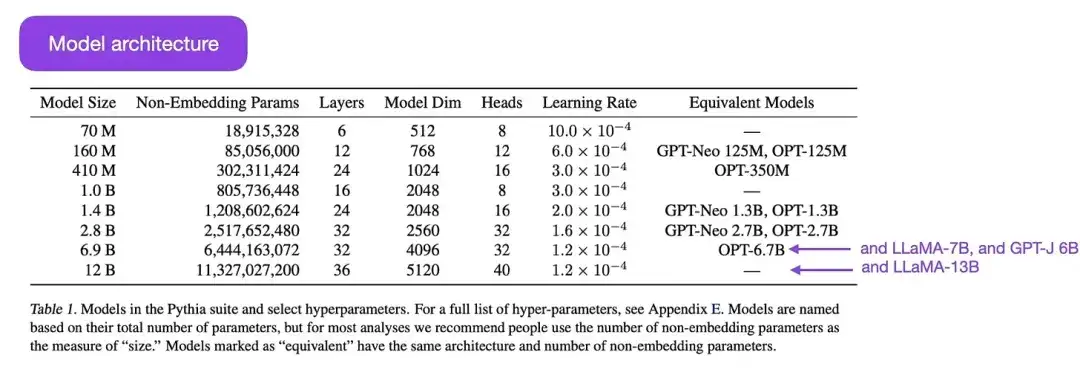
As principais conclusões do estudo Pythia são as seguintes:
- O treinamento em dados repetidos (o que significa treinamento para mais de uma época devido à forma como os grandes modelos de linguagem são treinados) não ajuda nem prejudica o desempenho;
- A ordem do treino não afeta o efeito memória. Isso é lamentável, porque se o oposto fosse verdade, poderíamos aliviar o indesejável problema de memória literal reordenando os dados de treinamento;
- A frequência das palavras durante o pré-treinamento afeta o desempenho da tarefa. Por exemplo, para palavras que aparecem com mais frequência, a precisão com um número menor de amostras tende a ser maior;
- Dobrar o tamanho do lote reduz pela metade o tempo de treinamento sem afetar a convergência.
Alinhamento: Guie grandes modelos de linguagem para objetivos e interesses desejados
Nos últimos anos, temos testemunhado uma série de modelos de linguagem em grande escala que são relativamente poderosos e capazes de gerar texto realista (como GPT-3 e Chinchilla, etc.). Parece que atingimos um limite máximo do que pode ser alcançado sob os paradigmas de pré-formação habitualmente utilizados.
Para tornar o modelo de linguagem mais útil e reduzir a geração de desinformação e linguagem prejudicial, os pesquisadores desenvolveram paradigmas de treinamento adicionais para ajustar o modelo básico pré-treinado.
17. Treinamento de modelos de linguagem para seguir instruções com feedback humano ****(2022)
Elenco: Ouyang, Wu, Jiang, Almeida, Wainwright, Mishkin, Zhang, Agarwal, Slama, Ray, Schulman, Hilton, Kelton, Miller, Simens, Askell, Welinder, Christiano, Leike, 和Lowe,
Link do artigo: https://arxiv.org/abs/2203.02155 .
No chamado artigo InstructGPT, os pesquisadores usaram um mecanismo de aprendizagem por reforço combinado com feedback humano (RLHF). Eles primeiro usaram o modelo básico GPT-3 pré-treinado e o ajustaram ainda mais por meio de aprendizado supervisionado em pares de resposta-sugestão gerados por humanos (etapa 1). Em seguida, eles treinaram um modelo de recompensa fazendo com que humanos classificassem os resultados do modelo (etapa 2). Finalmente, eles usaram o modelo de recompensa para atualizar o modelo GPT-3 pré-treinado e ajustado por meio do método de aprendizagem por reforço de otimização de política proximal (etapa 3).
Aliás, este artigo também é considerado o que explica a ideia por trás do ChatGPT - de acordo com rumores recentes, o ChatGPT é uma versão em escala do InstructGPT que foi ajustada com um conjunto de dados maior.
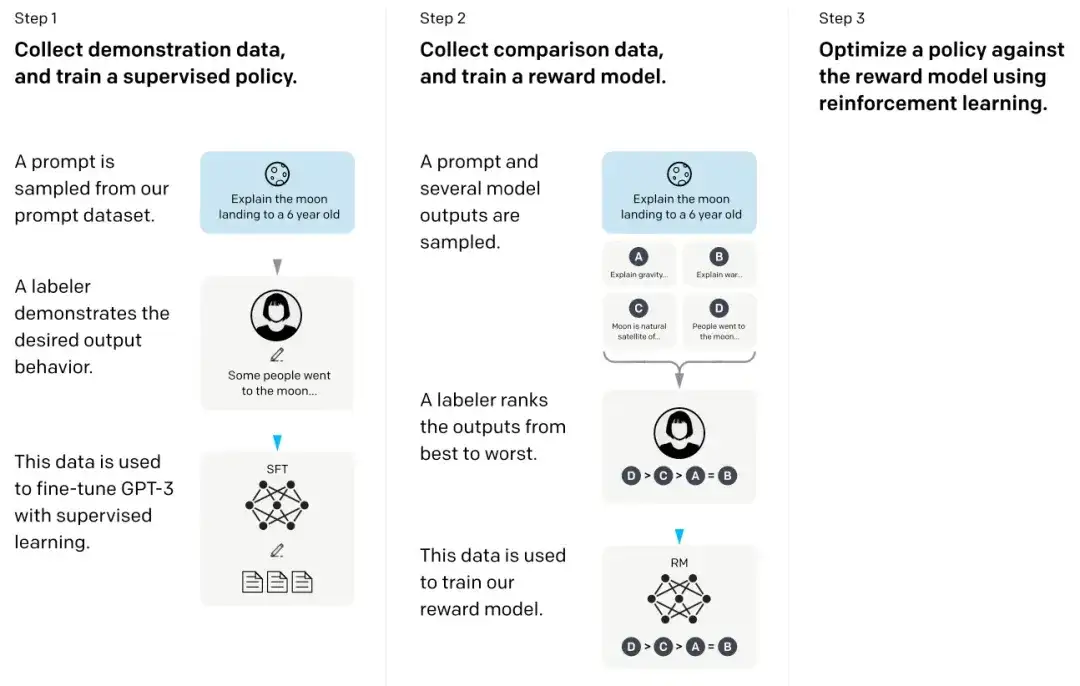
18. IA constitucional: inocuidade do feedback da IA (2022 )
Em destaque: Yuntao, Saurav, Sandipan, Amanda, Jackson, Jones, Chen, Anna, Mirhoseini, McKinnon, Chen, Olsson, Olah, Hernandez, Drain, Ganguli, Li, Tran-Johnson, Perez, Kerr, Mueller, Ladish, Landau, Ndousse, Lukosuite, Lovitt, Sellitto, Elhage, Schiefer, Mercado, DasSarma, Lasenby, Larson, Ringer, Johnston, Kravec, El Showk, Fort, Lanham, Telleen-Lawton, Conerly, Henighan, Hume, Bowman, Hatfield-Dodds, Mann , Amodei, Joseph, McCandlish, Brown, Kaplan
Link do artigo: https://arxiv.org/abs/2212.08073 .
Neste artigo, os pesquisadores desenvolvem ainda mais a ideia de “alinhamento” e propõem um mecanismo de treinamento para criar sistemas de IA “inofensivos”. Em vez da supervisão humana direta, os pesquisadores propõem um mecanismo de autotreinamento baseado em uma lista de regras fornecidas por humanos. Semelhante ao artigo do InstructGPT mencionado acima, o método proposto utiliza métodos de aprendizagem por reforço.
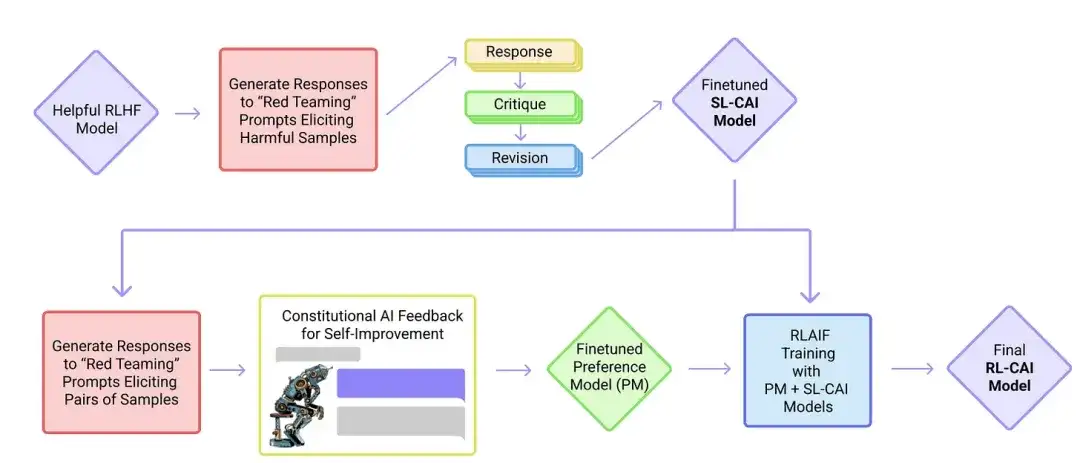
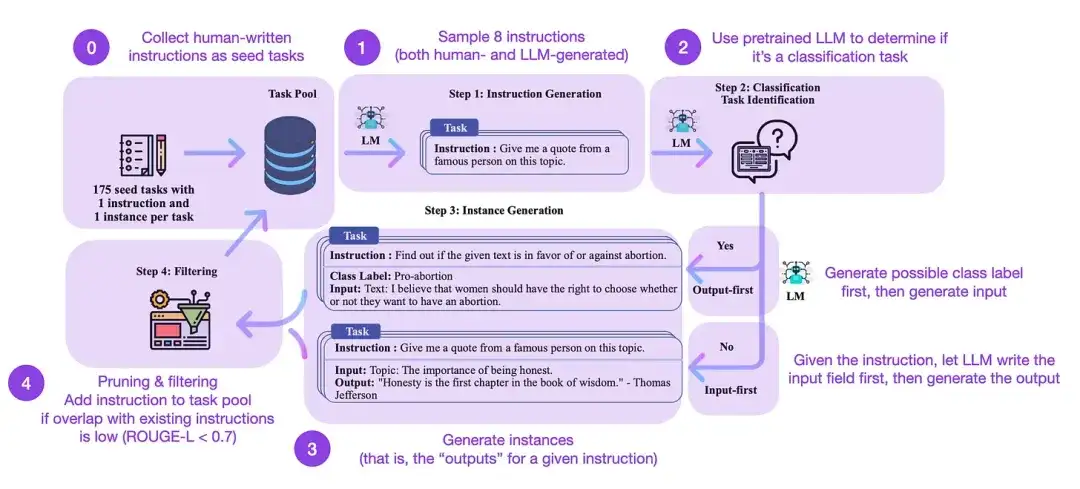
19. Autoinstrução: Alinhando modelo de linguagem com instrução autogerada (2022)
Autores do artigo: Wang, Kordi, Mishra, Liu, Smith, Khashabi e Hajishirzi
Link do artigo: https://arxiv.org/abs/2212.10560
O ajuste fino de instruções é como fazemos a transição de modelos básicos pré-treinados, como GPT-3, para LLMs mais poderosos, como ChatGPT. Conjuntos de dados de instruções de código aberto gerados por humanos, como databricks-dolly-15k, podem ajudar a tornar esse processo possível. Mas como alcançar escala? Uma abordagem é permitir que o LLM realize o aprendizado bootstrap com base em seu próprio conteúdo gerado.
Self-Instruct é um método (quase sem anotações) de alinhar LLMs pré-treinados com instruções. Como funciona esse processo? Resumindo, consiste em quatro etapas:
- Inicialize um conjunto de tarefas com um conjunto de instruções escritas por humanos (175 neste caso) e exemplos de instruções dele;
- Use um LLM pré-treinado (como GPT-3) para determinar a categoria da tarefa;
- Para novas instruções, deixe o LLM pré-treinado gerar respostas;
- Essas respostas são coletadas, filtradas e filtradas antes de serem adicionadas ao pool de tarefas.
Desta forma, o método de autoinstrução pode efetivamente melhorar a capacidade do modelo de linguagem pré-treinado de seguir e gerar instruções, ao mesmo tempo que reduz a anotação manual, expandindo e otimizando assim as capacidades do modelo.
Na prática, este método tem um desempenho relativamente bom com base na pontuação ROUGE. Por exemplo, o ajuste fino autoguiado de grandes modelos de linguagem (LLMs) superou o modelo básico GPT-3 e foi capaz de competir com LLMs pré-treinados em grandes conjuntos de instruções escritas por humanos. Além disso, a autoorientação também pode beneficiar os LLMs que foram aperfeiçoados por instruções humanas.
Obviamente, o padrão ouro para avaliar o LLM é convidar avaliadores humanos para participarem. Com base na avaliação humana, os métodos autoguiados vão além do LLM básico, bem como do LLM treinado em conjuntos de dados de instrução humana de maneira supervisionada (como SuperNI, T0 Trainer). Mas, curiosamente, a autoorientação não superou aqueles treinados através de métodos de aprendizagem por reforço que incorporam feedback humano (RLHF).
O que é mais promissor: conjuntos de dados de instruções gerados por humanos ou conjuntos de dados autoguiados? Estou otimista em ambos. Por que não começar com um conjunto de dados de instruções gerado por humanos, como as 15.000 instruções em databricks-dolly-15k, e depois estendê-lo de forma autodirigida?
Aprendizagem por Reforço e Feedback Humano (RLHF) Para obter mais explicações sobre Aprendizagem por Reforço e Feedback Humano (RLHF), bem como artigos relacionados sobre otimização de políticas proximais para implementar RLHF, consulte meu artigo mais detalhado abaixo:
Ao discutir grandes modelos de linguagem (LLMs), seja em atualizações de pesquisas ou tutoriais, costumo me referir a um processo chamado aprendizagem por reforço com feedback humano (RLHF). O RLHF tornou-se uma parte importante do pipeline de treinamento LLM moderno porque pode incorporar as preferências humanas na estrutura de otimização, melhorando assim a utilidade e a segurança do modelo.
Leia o artigo completo:
https://magazine.sebastianraschka.com/p/llm-training-rlhf-and-its-alternatives
Conclusão e leitura adicional
Tentei manter a lista acima concisa e concisa, concentrando-me nos dez principais artigos (mais três artigos sobre RLHF) que compreendem o design, as limitações e a evolução dos modelos contemporâneos de linguagem em grande escala. Para um estudo mais aprofundado, recomenda-se consultar os documentos citados nos artigos acima. Aqui estão alguns recursos adicionais:
Alternativas de código aberto para GPT:
- BLOOM: Um modelo de linguagem multilíngue de acesso aberto com parâmetros 176B (2022), https://arxiv.org/abs/2211.05100
- OPT: Modelos de linguagem de transformador pré-treinados abertos (2022), https://arxiv.org/abs/2205.01068
- UL2: Unificando Paradigmas de Aprendizagem de Línguas (2022), https://arxiv.org/abs/2205.05131
Alternativas ChatGPT:
- LaMDA: Modelos de linguagem para aplicativos de diálogo (2022), https://arxiv.org/abs/2201.08239
- (Bloomz) Generalização translíngue por meio de ajuste fino multitarefa (2022), https://arxiv.org/abs/2211.01786
- (Sparrow) Melhorando o alinhamento dos agentes de diálogo por meio de julgamentos humanos direcionados (2022), https://arxiv.org/abs/2209.14375
- BlenderBot 3: um agente conversacional implantado que aprende continuamente a se envolver de maneira responsável, https://arxiv.org/abs/2208.03188
Grandes modelos em biocomputação:
- ProtTrans: Rumo a decifrar a linguagem do código da vida por meio de aprendizado profundo autosupervisionado e computação de alto desempenho (2021), https://arxiv.org/abs/2007.06225
- Previsão de estrutura de proteína altamente precisa com AlphaFold (2021), https://www.nature.com/articles/s41586-021-03819-2
- Grandes modelos de linguagem geram sequências funcionais de proteínas em diversas famílias (2023), https://www.nature.com/articles/s41587-022-01618-2
Recomendações de artigos
7 dicas rápidas para tornar sua conversa com IA mais eficaz
Numa época em que todos são desenvolvedores, ainda é útil aprender programação?
Se houver alguma violação, entre em contato conosco para excluí-la. Links de referência:
https://magazine.sebastianraschka.com/p/understanding-large-language-models
Siga-nos
OpenSPG:
Site oficial: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
Site oficial: https://openasce.openfinai.org/
GitHub: [https://github .com/Open-All-Scale-Causal-Engine/OpenASCE ]