
Autor: Wu Jipeng, gerente de tecnologia de big data do Wuxi Xishang Bank
Edição e finalização: equipe técnica do SelectDB
Introdução: A fim de realizar a transformação de valor dos ativos de dados e o gerenciamento de risco digital e inteligente abrangente, a plataforma de big data do Wuxi Xishang Bank experimentou a evolução do data warehouse offline Hive para o data warehouse em tempo real Apache Doris e atualmente tem acesso para centenas de tabelas em tempo real, centenas de interfaces de serviço de dados, e a interface QPS atinge milhões de níveis, resolvendo os problemas de pontualidade insuficiente, alto custo e baixa eficiência de data warehouses offline, acelerando as consultas em mais de 10 vezes. e fornecer aos usuários serviços de dados e experiência de uso oportunos, eficazes e seguros.
Confrontado com as mudanças trazidas ao sector financeiro pelas tecnologias emergentes, como o big data, a Internet das Coisas e a inteligência artificial, o Wuxi Xishang Bank coloca uma ênfase importante no desenvolvimento de capacidades tecnológicas e de big data. A fim de realizar a transformação de valor dos ativos de dados e o gerenciamento abrangente de risco digital e inteligente, o Wuxi Xishang Bank estabeleceu uma plataforma de big data baseada no layout de tecnologia integrada de três asas de "negócios on-line, controle de risco baseado em dados e baseado em plataforma arquitetura". Para gerenciar o fluxo maciço de registros de transações e dados de aplicativos de crédito todos os dias, e com a ajuda de retratos de usuários, relatórios em tempo real, controle de risco em tempo real e outros aplicativos, fornece aos usuários soluções mais oportunas, eficazes e seguras serviços de dados e experiência do usuário.
A plataforma de big data do Wuxi Xishang Bank evoluiu de um data warehouse offline baseado no Hive para um data warehouse em tempo real baseado no Apache Doris . Através da atualização da arquitetura, os problemas de pontualidade insuficiente, alto custo e baixa eficiência do data warehouse offline foram resolvidos, e a velocidade de consulta foi aumentada em 10 vezes, permitindo que os bancos percebam o comportamento do cliente com mais rapidez, obtenham insights oportunos em comportamentos de transação anormais e identificar e prevenir riscos potenciais. Este artigo apresentará em detalhes a evolução da plataforma de big data do Wuxi Xishang Bank e a implementação do Apache Doris em consultas em tempo real, serviços de marketing, serviços de controle de risco e outros cenários.
Armazém de dados off-line de big data baseado no Hive
01 Cenário de demanda
O Wuxi Xishang Bank construiu um data warehouse off-line de big data no estágio inicial, que atende principalmente a cenários como relatórios de dados, controle de risco de dados, operações de dados, consultas ad hoc e recuperação diária de dados. Os cenários de demanda incluem, mas não estão limitados a:
-
Relatórios de dados: risco do cliente, relatórios EAST, 1104, grande concentração, relatórios de crédito, relatórios de taxas de juros, combate à lavagem de dinheiro, relatórios de dados financeiros básicos, etc.
-
Controle de risco de dados: incluindo controle de risco em indicadores de controle de risco de empréstimo, indicadores de comportamento do usuário, antifraude, alerta precoce pós-empréstimo, gestão pós-empréstimo e outros controles de risco.
-
Operação de dados: Forneça dados em lote regulares para relatórios de negócios de BI, cockpit de gerenciamento, canais externos e vários sistemas do setor.
-
Consulta ad hoc e recuperação diária de dados: realize análise, desenvolvimento e extração de dados de acordo com as necessidades do negócio.
02 Arquitetura e pontos fracos
Nos primeiros data warehouses offline, os dados vinham principalmente de Oracle, MySQL, MongoDB, Elasticsearch e arquivos. Usando ferramentas como Sqoop, Spark, fontes de dados externas e Shell, os dados são extraídos offline para o data warehouse offline do Hive e processados hierarquicamente por meio de ODS, DWD, DWS e ADS no Hive. a camada de serviço de aplicação.
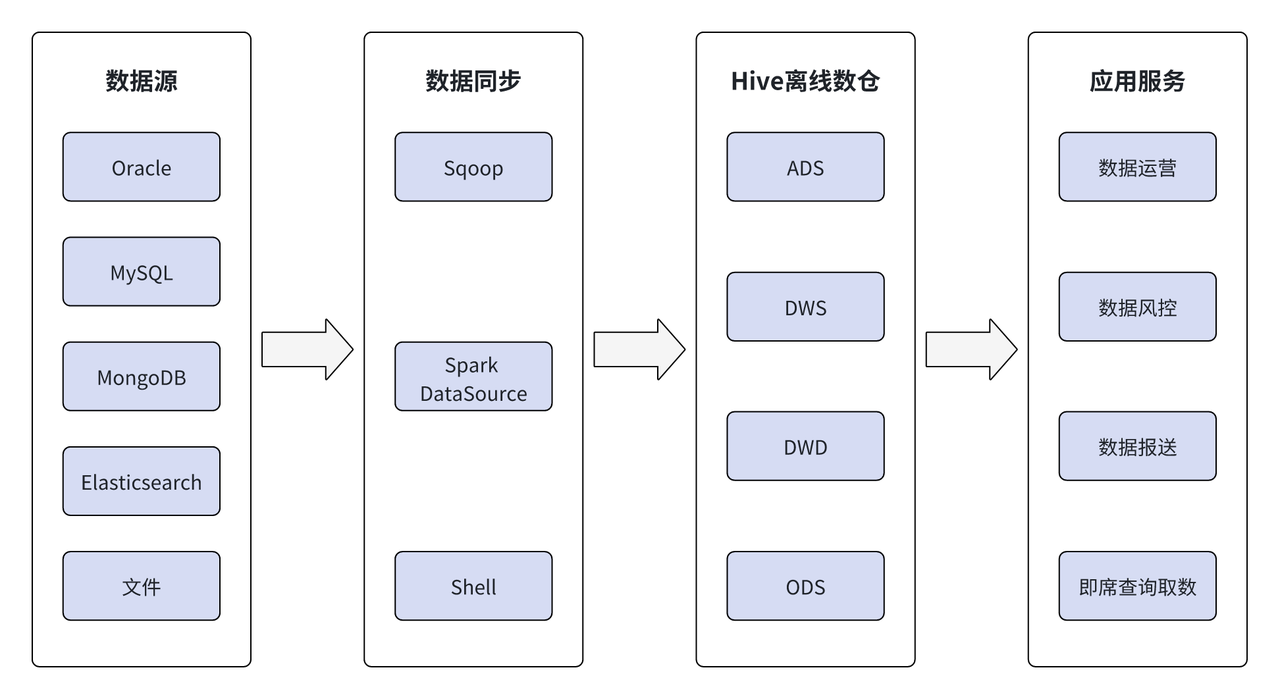
Nos últimos anos, com o desenvolvimento e expansão dos negócios do Wuxi Xishang Bank, os departamentos comerciais relevantes têm requisitos cada vez mais elevados para o processamento de dados. O armazém de dados offline já não consegue satisfazer as novas necessidades, o que se reflecte principalmente em:
-
Oportunidade de dados insuficiente: O data warehouse offline usa uma solução de extração offline e a atualidade dos dados é T+1. No entanto, relatórios, painéis de dados, indicadores de marketing e variáveis de controle de risco exigem atualizações de dados em tempo real, que a arquitetura atual não pode atender. .
-
A eficiência da consulta de dados é baixa: é necessária uma resposta de consulta no segundo nível e no nível de milissegundos. Os mecanismos de execução de data warehouse off-line são principalmente Hive e Spark. Quando o Hive é executado, ele decompõe a consulta em várias tarefas MapReduce e precisa ler e gravar dados no HDFS. O tempo de execução geralmente é de minuto, o que afeta seriamente a consulta. eficiência.
-
Altos custos de manutenção: A camada inferior do data warehouse offline envolve muitas pilhas de tecnologia, incluindo LDAP, Ranger, ZooKeeper, HDFS, YARN, Hive, Spark e outros sistemas, o que levará a altos custos de manutenção do sistema. Embora também existam armazenamento em tempo real e serviços de HBase + Phoenix online, ele ainda não pode resolver completamente o problema atual porque seus componentes são relativamente “pesados”, a comunidade não está ativa e alguns recursos não podem atender às necessidades de tempo real cenários.
Seleção de tecnologia
Diante dos problemas de pontualidade insuficiente dos data warehouses off-line, baixa eficiência de consulta e altos custos de manutenção causados por múltiplas pilhas de tecnologia, a construção de data warehouses em tempo real é imperativa. Depois de realizar pesquisas aprofundadas em vários bancos de dados MPP, o Wuxi Xishang Bank decidiu construir uma plataforma de data warehouse em tempo real com Apache Doris como núcleo. Esta seleção de tecnologia visa garantir que a plataforma possa atender aos elevados requisitos de análise de negócios em tempo real nos níveis de escrita de dados, consulta e serviço. As razões para escolher o Apache Doris são as seguintes:
-
Atualização de dados eficiente: Apache Doris Unique Key oferece suporte a atualizações de dados em grandes lotes, gravação em tempo real de dados em pequenos lotes e modificações leves na estrutura da tabela. Especialmente ao processar uma grande quantidade de dados e partições, ele pode efetivamente evitar o problema de grandes quantidades de modificações e modificações imprecisas, proporcionando assim atualizações de dados mais convenientes e em tempo real.
-
Gravação em tempo real de baixa latência: suporta gravação, atualização e exclusão de dados em tempo real no segundo nível; suporta fusão em tempo real de gravação de modelo de tabela de chave primária, permitindo gravação em tempo real de alta frequência de microlotes; modelo de chave primária Configurações da coluna de sequência para garantir a ordem da importação de dados no processo.
-
Excelente desempenho de consulta: Apache Doris possui poderosos recursos de junção de múltiplas tabelas. Contando com o mecanismo de execução vetorizado, otimizador de consulta CBO, arquitetura MPP, visualizações materializadas inteligentes e outras funções, ele pode obter resposta de consulta em nível de milissegundos para dados massivos, satisfazendo dados instantâneos. consultas. Ao mesmo tempo, o Apache Doris versão 2.0 suporta armazenamento misto de linhas e colunas e pode obter dezenas de milhares de respostas simultâneas em nível de milissegundos em cenários de consulta pontual.
-
A plataforma é extremamente fácil de usar: é compatível com o protocolo MySQL e oferece interfaces API ricas, o que pode reduzir a dificuldade de uso de aplicativos de camada superior. Ao mesmo tempo, Apache Doris possui uma arquitetura simplificada, com apenas dois processos, FE e BE. Simplifica a expansão e contração de nós, o gerenciamento de cluster e o gerenciamento de cópia de dados possuem as características de implantação simples, baixo custo de uso e. baixo custo de operação e manutenção.
Apresentando o Apache Doris para construir um data warehouse de big data em tempo real
Em abril de 2022, o Wuxi Xishang Bank introduziu o Apache Doris para construir uma plataforma de data warehouse em tempo real. Considerando que a escala dos dados bancários é muito grande, é difícil sincronizar a quantidade total de dados históricos do banco de dados de negócios durante o acesso aos dados em tempo real. Portanto, a construção inicial de dados em tempo real depende principalmente de dados off-line.
Primeiro, o método HDFS Broker é usado para inicializar com eficiência dados históricos em tempo real, ao mesmo tempo, a ferramenta de coleta DataPipeline é usada para coletar os dados no cluster Kafka em tempo real e, em seguida, Flink grava o modo codificado; grave os dados no Apache Doris em tempo real. Finalmente, com a ajuda dos recursos de serviço de interface da plataforma Feiliu, o Apache Doris é usado como um mecanismo unificado de armazenamento e consulta para fornecer serviços para cada linha de negócios.
A plataforma Feiliu é uma plataforma unificada e abrangente construída pelo Wuxi Xishang Bank para lidar com futuros cenários de negócios em tempo real. Inclui principalmente coleta em tempo real, ferramentas de sincronização em tempo real, armazenamento de dados em tempo real , cálculo em tempo real e serviços de dados. .
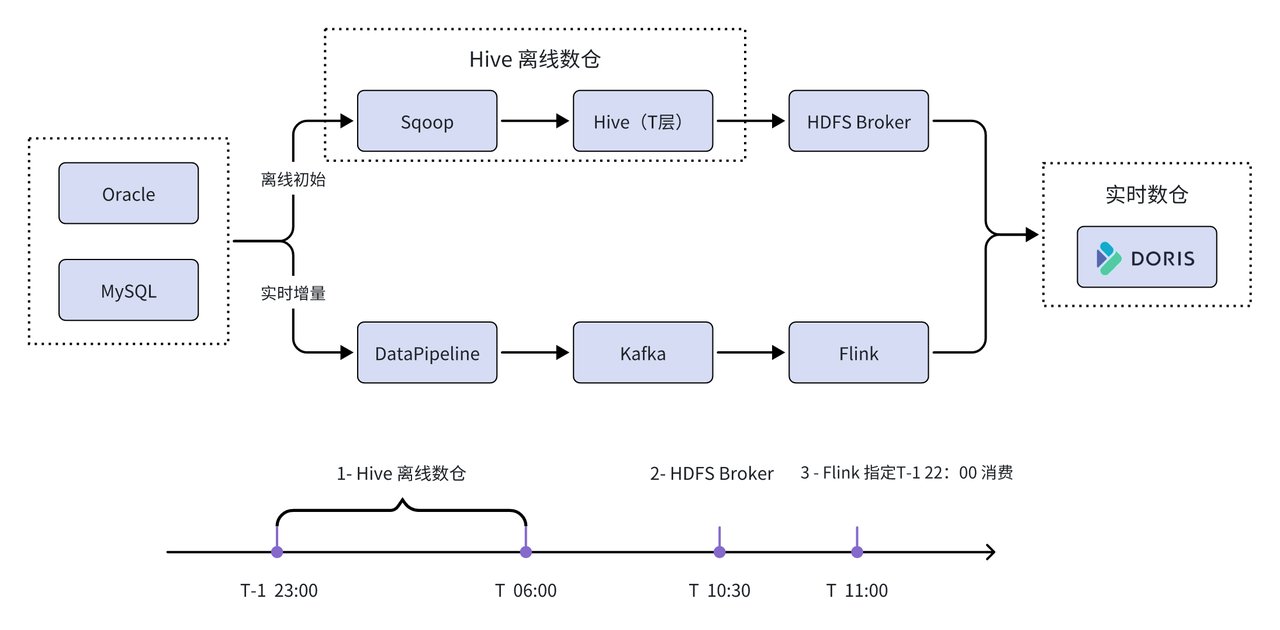
01 Melhore os links de fluxo de dados
Partindo das características dos dados bancários e combinando as vantagens funcionais do Apache Doris, o Wuxi Xishang Bank repensou e melhorou o link de fluxo de dados:
-
Sincronizar dados históricos de armazéns de dados offline minimiza riscos: O artigo mencionou que devido à enorme escala de dados bancários, se a quantidade total de dados históricos for sincronizada diretamente do Oracle e MySQL, uma grande quantidade de dados fluirá através de firewalls e switches, fazendo com que outras solicitações de negócios sejam bloqueadas e Problemas como tempo limite de serviço. Para evitar esses riscos e problemas potenciais, primeiro construa a estrutura da tabela Doris em lotes com base em Oracle e MySQL e, em seguida, use o HDFS Broker para sincronizar os dados T-1 completos da camada Hive ODS do data warehouse offline para Doris, minimizando assim riscos.
-
Extração incremental em tempo real, modo de extração mais seguro: A extração em tempo real produzirá uma quantidade muito pequena de E/S de disco, memória e consumo de CPU para evitar afetar o banco de dados de negócios principal, por padrão, o banco de dados escravo de negócios ou o mesmo. a recuperação de desastres da cidade será selecionada. Extração da biblioteca em tempo real. Para necessidades de negócios com altos requisitos de pontualidade, é necessária uma avaliação completa antes que os dados possam ser extraídos do banco de dados principal de negócios.
-
Construa a camada Kafka para garantir a consistência dos dados: Construa a camada Kafka como uma camada intermediária de transmissão de dados para garantir a ordem e consistência dos dados. A chave dos dados enviados pelo Datapipeline é configurada como Database-Table-PK, e é enviada para uma partição (Partition) do Kafka Topic de forma ordenada de acordo com a mesma dimensão. Como as respectivas partições do Kafka Topic são armazenadas em ordem, os consumidores downstream podem processar dados para evitar efeitos fora de ordem na precisão dos dados do data warehouse em tempo real. Além disso, a camada Kafka pode ser usada como uma camada pública de dados e pode ser usada em marketing, controle de risco e outros cenários de negócios.
-
Os dados são gravados em tempo real para garantir que os dados não sejam perdidos ou duplicados: Em cenários de aplicação reais, o link offline executa o lote de dados offline das 23h às 6h no dia T-1 e usa o método HDFS Broker às 10h. relógio do dia T. Inicialização dos dados históricos da tabela. O link em tempo real usa o Flink para apontar diretamente para o tópico Kafka consumido no T-1 às 22h para sincronização de dados em tempo real. No entanto, alguns dados sobrepostos aparecerão durante o processo de consumo em tempo real. Para lidar com este problema, o modelo Unique Key do Apache Doris é selecionado (este modelo suporta idempotência de dados), que pode cobrir rapidamente dados sobrepostos e o Flink-Doris-Connector é usado para melhorar o link do data warehouse em tempo real para garantir; sincronização consistente de dados em tempo real. Não é pesado para jogar fora.
02 Serviços de dados flexíveis
A fim de fornecer respostas de consulta precisas e eficientes, o Wuxi Xishang Bank adotou os três métodos a seguir para implementar serviços de dados:
-
Consulta de dados offline: Para requisitos offline, os dados precisam ser consultados rapidamente. O Wuxi Xishang Bank importa regularmente dados do data warehouse offline para a tabela Doris do data warehouse em tempo real. Isso permite consultas rápidas no data warehouse em tempo real para atender às necessidades de análise de dados off-line e tomada de decisões.
-
Requisitos simples em tempo real: Para requisitos descomplicados em tempo real, o Wuxi Xishang Bank usa os recursos de consulta eficientes do Apache Doris para fornecer a capacidade de configurar diretamente a interface de serviço de dados na plataforma "Fei Liu". Os usuários podem usar SQL com base na plataforma. Camada ODS do data warehouse em tempo real Execute a configuração manual. Desta forma, as necessidades de consultas simples de dados em tempo real podem ser rapidamente atendidas.
-
Requisitos complexos em tempo real: Para requisitos complexos em tempo real, o Wuxi Xishang Bank usa fluxo de dados Kafka em tempo real e computação leve Flink para gravar o fluxo de dados na tabela da camada DWD do armazém de dados em tempo real e com base em detalhes em a plataforma "Fei Liu" O SQL da tabela é agregado novamente e a interface de serviço de dados é configurada manualmente para atender às necessidades de consultas complexas de dados em tempo real.
Enfrentando cenários de serviço mais diversos
01 resposta de consulta de relatório de BI em segundos
Baseado no Apache Doris, o Wuxi Xishang Bank atende às necessidades de vários cenários, como análise diária de dados, recuperação diária de dados e relatórios de BI em tempo real. O tempo de resposta da consulta é bastante reduzido e os resultados da consulta podem ser retornados em 1 segundo . reduz muito o tempo de espera dos analistas de dados. Custo e consumo de recursos do servidor.
Por exemplo, em termos de relatórios de BI em tempo real, o Wuxi Xishang Bank estabeleceu tabelas de dados de empréstimos em tempo real, tabelas de dados de depósitos em tempo real, tabelas de saldos de contas e outros relatórios. **Esses relatórios têm em média 253 linhas de código SQL e um tempo médio de resposta de 1,5 segundos. **Além disso, ao otimizar o desempenho das consultas e o design do modelo de dados, o Wuxi Xishang Bank pode gerar relatórios precisos em tempo real em um curto período de tempo para fornecer suporte de dados oportuno para decisões de negócios.
02 Apoie planos de marketing personalizados
Em termos de serviços de dados de marketing, o Wuxi Xishang Bank baseou-se no Apache Doris para enriquecer as etiquetas dos clientes e melhorar os retratos precisos dos clientes, e realizou várias atividades de marketing, como atividades de aumento de ativos líquidos e atividades de caixa cega de artistas. Por meio da análise de dados em tempo real, os bancos podem observar o status de conversão dos usuários ativos em tempo hábil e ajustar prontamente a estratégia de seleção de operações para obter marketing personalizado de "mil pessoas têm uma face" para "mil pessoas têm uma face".
Por exemplo, em atividades de marketing, como atividades de aumento de ativos líquidos e atividades de caixa cega de artistas, o Wuxi Xishang Bank usa os recursos do data warehouse em tempo real Apache Doris para coletar, analisar e fornecer feedback contínuo de dados de atividades. Ao observar as conversões dos usuários em tempo real, podemos ajustar prontamente a estratégia de seleção de operações para garantir a correspondência entre pessoal e atividades. Esta estratégia de marketing personalizada permite que os bancos atendam melhor às necessidades dos clientes e aumentem o envolvimento, as taxas de resposta e a adesão dos usuários.
03 Identificação e controle eficiente de riscos
A introdução do Apache Doris permite que o Wuxi Xishang Bank calcule variáveis características de controle de risco e comportamentos anormais de transações com mais rapidez. Tomando como exemplo o registro de novos usuários, quando os usuários preenchem as informações, o sistema pode determinar rapidamente os resultados da estratégia de aprovação com base em variáveis características de controle de risco em tempo real, otimizar o modelo de estratégia em tempo hábil e garantir a qualidade e precisão de aprovação.
O Wuxi Xishang Bank também é capaz de identificar e prevenir riscos potenciais em tempo hábil. Por exemplo, os bancos podem recolher e monitorizar dados de transacções, tais como um grande número de transacções e montantes de transacções anormais num curto período de tempo em tempo real, para detectar atempadamente comportamentos de transacções anormais e fraudes. Através da análise de dados em tempo real, os bancos podem identificar rapidamente riscos potenciais e tomar medidas adequadas para prevenir e responder.
Além disso, o Wuxi Xishang Bank também usa o data warehouse em tempo real Apache Doris para realizar análises em tempo real do histórico de crédito dos clientes e das informações de aplicação de crédito. Ao determinar rapidamente se o montante da aplicação do cliente corresponde à sua capacidade de reembolso, os bancos podem tomar decisões e avaliações de risco atempadas para controlar eficazmente os riscos de crédito.
04 Os dados do fluxograma de negociação de sete dias são atualizados automaticamente.
Em cenários de aplicação reais, a quantidade de dados no fluxograma da transação é muito grande, envolvendo número de série da transação, data da transação, tipo de transação, valor da transação e outros dados. A fim de garantir a atualização oportuna dos dados, o Wuxi Xishang Bank optou por usar o recurso da tabela de partição dinâmica Apache Doris. Este recurso pode criar partições automaticamente e excluir automaticamente dados de fluxo de transações com mais de sete dias para obter atualização automática de dados na tabela de fluxo de transações de sete dias. As operações específicas incluem as seguintes etapas:
-
Construa uma pseudocoluna com a data comercial como chave primária conjunta;
-
Quando os dados do ID são
tran_dateatualizados ao longo dos dias, o código executa uma operação de retorno de tabela; -
Encontre o valor de data correspondente na tabela de inserção e partição dos dados, divida-o em Update Json e atualize-o no banco de dados.

Com a ajuda do particionamento dinâmico e do recurso de particionamento de tabela do Apache Doris, ele pode não apenas garantir a operação estável da chave primária e do servidor subjacentes, mas também atualizar e reter automaticamente apenas sete dias de dados de transação para os analistas consultarem e atender aos Requisito de resposta de consulta de 1,5 segundo abaixo de um milhão de QPS .
05 Consulta de ponto de alta simultaneidade
Os primeiros cenários de aplicativos de marketing e controle de risco dependiam principalmente de dois conjuntos de clusters HBase para oferecer suporte a serviços de enumeração. No entanto, em aplicativos reais, problemas como saída anormal do servidor mestre/região e RIT serão encontrados. Para evitar esse problema, você pode aproveitar a alta capacidade de consulta simultânea do Apache Doris e ativar a estratégia Merge-on-Write ao criar a tabela Unique Key, para que a consulta de chave primária possa ser concluída por meio de um caminho de execução SQL simplificado, com apenas um RPC é necessário. Resposta de consulta rápida completa.
Finalmente, através de testes de estresse em três nós, com cada nó configurado com 8C e 10GB, foram alcançados os seguintes benefícios significativos:
-
Em um cenário de consulta em que uma única tabela contém 50 milhões de dados, o QPS chega a 25.000;
-
Em um cenário de leitura e gravação multitabela envolvendo 50 milhões de dados, o QPS também chega a 20.000;
-
A estabilidade de consultas SQL complexas também permanece em um nível elevado de QPS 25.000;
-
No cenário de leitura e gravação em tempo real de múltiplas tabelas, o QPS também pode ser estabilizado em 25.000.
Conclusão
Atualmente, o Apache Doris acessou centenas de tabelas em tempo real, centenas de interfaces de serviço de dados e interface QPS, atingindo milhões no Wuxi Xishang Bank. Além disso, o Apache Doris, como um gateway de consulta unificado, melhora significativamente a eficiência da análise de dados históricos. Em comparação com o tempo de resposta original em nível de minuto, a velocidade da consulta é mais de 10 vezes.
No futuro, o Wuxi Xishang Bank continuará a explorar as vantagens do Apache Doris e a promover sua aplicação mais profunda em cenários em tempo real.
-
Em termos de desempenho: otimizar ainda mais a consulta de alta simultaneidade, particionamento e bucketing automáticos, mecanismo de execução e outros recursos para melhorar a eficiência da resposta à consulta de dados;
-
Em termos de balanceamento de carga: construir clusters duplos para alcançar o balanceamento de carga arquitetônico ao mesmo tempo, os mecanismos de alerta precoce e disjuntores da arquitetura serão melhorados para garantir operações comerciais ininterruptas;
-
Em termos de estabilidade do cluster: Realizar a “divisão de trabalho e colaboração” do cluster Apache Doris, para que cada um deles possa realizar tarefas como cálculo e armazenamento de data warehouse em tempo real, consulta acelerada de serviços de dados, etc., para melhorar ainda mais a estabilidade e confiabilidade do sistema.