
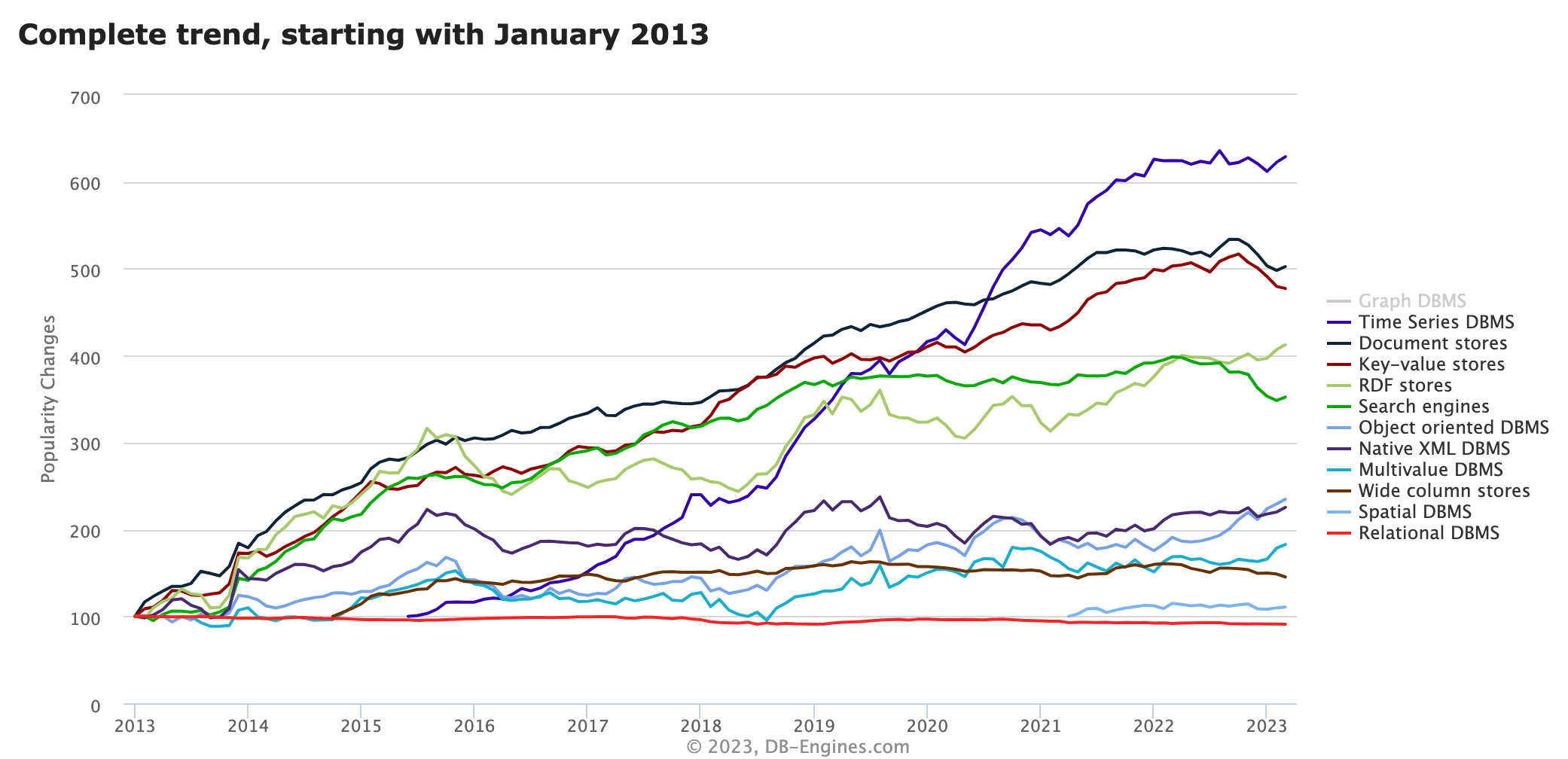
Nos últimos anos, a crescente popularidade da Internet das Coisas (IoT) e a necessidade de dados em tempo real levaram a um crescimento significativo na adoção de bancos de dados de séries temporais (TSDB). De acordo com o ranking do DB-Engines, a popularidade do TSDB supera a de qualquer outro tipo de banco de dados, perdendo apenas para o Graph DBMS .
Como uma ferramenta importante para armazenar, gerenciar e analisar dados de séries temporais, a demanda por bancos de dados de séries temporais (TSDB) provavelmente continuará a aumentar no futuro. Se você ainda não sabe muito sobre isso, este artigo apresentará de forma abrangente o que é um banco de dados de série temporal e por que você precisa de um banco de dados para dados de série temporal.
O que são dados de série temporal
Falando sobre a popularidade dos bancos de dados de séries temporais nos últimos anos, temos que falar primeiro sobre os dados de séries temporais. Por que é necessário um banco de dados especialmente otimizado para processamento? Um banco de dados relacional geral não pode satisfazê-lo?
Os chamados dados de série temporal, de uma perspectiva muito popular, são alguns valores (Valor) que mudam com o tempo. Ao mesmo tempo, esses valores são acompanhados por algumas tags que consistem em Key=Value.
Geralmente inclui os três atributos a seguir (da Wikipedia):
Série temporal
Um identificador exclusivo que consiste em um nome (geralmente chamado de métrica) e uma série de rótulos Chave=Valor (Rótulos ou geralmente chamados de Tags).
Par de valores-chave (carimbo de data e hora, valor)
Pares de valores-chave compostos de carimbos de data/hora e valores e são naturalmente classificados de acordo com carimbos de data/hora. Esses pares de valores-chave são geralmente chamados de amostras.
Valor
O valor no ponto 2 é geralmente um valor numérico, como temperatura, umidade, CPU, uso de memória, etc., mas também pode ser qualquer estrutura de dados (estruturada e não estruturada).
Caso de dados de série temporal
Por exemplo, faça uma captura de tela da previsão meteorológica para 15 dias de um site de meteorologia para Yuhang:
Analisando as duas linhas de temperatura máxima e temperatura mínima, os três atributos aqui são:
- Os cronogramas são: a. Temperatura máxima diária + <region=Yuhang> b.
- A sequência composta pelo timestamp e valor da temperatura máxima é de 15 pares de valores-chave de 29/08 a 06/09, e o valor é a temperatura máxima diária. As temperaturas mínimas são semelhantes.
- Aqui Valor é a temperatura, ou seja, um valor numérico. Por exemplo, a temperatura mais alta em 29/08 é 36 graus Celsius e a temperatura mais baixa é 25 graus Celsius.
Além das informações de previsão do tempo, os dados de séries temporais também existem amplamente nos seguintes campos:
Preço das ações : permite que analistas e traders de ações entendam a tendência e a direção de um determinado preço das ações.
Monitoramento de Saúde : Utilizado na área médica para monitorar a frequência cardíaca ou outros valores de saúde de pacientes que possam estar tomando determinados medicamentos.
Sensores físicos para a indústria e a Internet das Coisas : incluindo vários sensores de temperatura, umidade, velocidade, aceleração, direção, frequência cardíaca, oxigênio no sangue e outros sensores incluídos em vários smartphones, carros inteligentes e casas inteligentes, etc., que são amplamente utilizados na fabricação , indústrias médicas e outras. Vários sensores geram grandes quantidades de dados sensoriais o tempo todo e em intervalos fixos ou irregulares, que são usados principalmente para monitoramento diário e anormal de equipamentos e corpos humanos, e aplicações inteligentes baseadas nessa mineração massiva de dados (como. como otimização da linha de produção de fabricação inteligente), direção autônoma), etc.
Sensores de software : como monitoramento de sondagens intrusivas em DevOps tradicionais, sondagens não intrusivas em ambientes nativos da nuvem (como as soluções de sondagem não intrusivas atualmente populares baseadas em sondas de plano de dados eBPF e Service Mesh), vários softwares O objetivo principal de vários indicadores e os dados incorporados visam monitorar aplicativos de software diários e anormais para garantir a operação contínua e estável dos serviços de negócios. Juntamente com o desenvolvimento atual do campo AIOps, também são apresentados requisitos mais elevados para a escala e granularidade do uso de dados de séries temporais.
Características dos dados de série temporal
- Os dados são gerados com relativa frequência e de forma estável , e a frequência é geralmente estável e não muda com os ciclos de atividade diurna das pessoas. Existem muitos tipos de sensores, juntamente com um grande número de rótulos para indústrias e localizações geográficas, a escala de dados e os prazos são extremamente grandes. E a escala desses dados está a crescer rapidamente com a popularidade dos dispositivos inteligentes (dispositivos vestíveis, carros inteligentes, produção inteligente) e com as exigências mais sofisticadas das pessoas por estas aplicações de dados.
- As características de alteração dos dados são mais semelhantes ao método Append-Only . Os dados são adicionados continuamente e há menos cenários de atualização (mas ainda há atrasos nos dados, especialmente em ambientes de rede fracos. Os dados geralmente são excluídos com base no tempo de expiração). . Excluir em lotes por um período.
- Em termos de aplicações de dados, os mais comuns são o monitoramento diário e anormal . Com base nesses dados, são construídos relatórios de monitoramento visual e sistemas de alarme, seguidos de previsão de tendências futuras, ou seja, previsão de séries temporais, principalmente na área financeira.
Por que os dados de séries temporais são tão importantes
Embora os dados de série temporal não sejam um tipo de dados novo, sua popularidade e uso aumentaram significativamente nos últimos anos, conforme analisado pelo DB-Engines. Existem vários fatores que não podem ser ignorados, incluindo:
- O desenvolvimento da Internet e a digitalização de muitas indústrias . Isso leva diretamente à geração de dados massivos de séries temporais, como tráfego de sites, atividades de mídia social e leituras de sensores.
- Desenvolvimento de algoritmos de aprendizado de máquina . Como redes neurais recorrentes (RNN) e redes de memória de longo e curto prazo (LSTM), esses algoritmos são adequados para análise de dados de séries temporais, tornando mais fácil para as pessoas extrair informações valiosas desse tipo de dados, dando aos dados de séries temporais a oportunidade para gerar ainda mais valor.
- A ascensão da análise preditiva . Isso torna os dados de séries temporais uma ferramenta importante para prever tendências e resultados futuros.
- necessidades em áreas como finanças, cuidados médicos e transportes . Há uma necessidade crescente de tomada de decisões em tempo real nessas áreas, e a análise de dados de séries temporais pode lidar com essas situações em rápida mudança.
O que é um banco de dados de série temporal
Banco de dados de série temporal (banco de dados de série temporal), de acordo com a definição da Wikipedia, é um banco de dados otimizado especificamente para processamento de dados de série temporal. É um tipo de banco de dados de domínio e é projetado para serviços de processamento de dados em áreas de negócios específicas, como processamento de banco de dados gráfico, armazenamento de gráficos e. recuperação. , o banco de dados de documentos é usado para o armazenamento e recuperação de documentos semiestruturados, e o mecanismo de busca é usado especialmente para a recuperação de texto não estruturado.
Características do banco de dados de série temporal
Para abordar as características e desafios envolvidos nos dados de séries temporais descritos acima, o TSDB emprega diversas técnicas. Algumas dessas características típicas incluem:
Árvore de mesclagem estruturada em log (árvore LSM)
LSM-tree é uma estrutura de dados baseada em disco otimizada para cargas de trabalho com uso intenso de gravação que permite ingestão e armazenamento eficiente de dados, mesclando e compactando dados em uma série de camadas. Isso reduz a amplificação de gravação e fornece melhor desempenho de gravação em comparação com árvores B tradicionais.
particionamento baseado em tempo
Os bancos de dados de série temporal normalmente particionam os dados com base em intervalos de tempo, tornando as consultas mais rápidas e eficientes e facilitando a retenção e o gerenciamento dos dados. Essa abordagem ajuda a separar dados recentes e acessados com frequência de dados mais antigos e acessados com menos frequência, otimizando o armazenamento e o desempenho da consulta.
compressão de dados
Os bancos de dados de série temporal usam várias técnicas de compactação, como codificação delta, compactação Gorilla ou codificação de dicionário para reduzir os requisitos de espaço de armazenamento. Essas técnicas aproveitam padrões temporais e baseados em valor em dados de séries temporais para permitir armazenamento eficiente sem perder a fidelidade dos dados.
Funções e agregações baseadas em tempo integradas
Os bancos de dados de série temporal fornecem suporte nativo para funções baseadas em tempo, como médias móveis, porcentagens e agregações baseadas em tempo. Esses recursos integrados permitem que os usuários executem análises complexas de séries temporais de forma mais eficiente e com menos sobrecarga computacional em comparação com bancos de dados tradicionais.
Por que escolher o banco de dados de série temporal
A partir da introdução acima, também temos uma resposta preliminar sobre por que precisamos de um banco de dados no campo específico de banco de dados de séries temporais.
Com base nas características, escala e aplicação dos dados de séries temporais, o banco de dados de séries temporais pode fazer otimizações direcionadas: o armazenamento adota um algoritmo de compactação personalizado, o formato de armazenamento adota um formato de armazenamento misto de linha-coluna otimizado para gravação em massa de séries temporais e cenários de consulta; operadores de consulta Introduzem mais funções relacionadas à janela de tempo para temporização, otimizam o protocolo de consulta para modelos de temporização e adotam uma estratégia de expiração mais flexível para exclusão de dados .
Essas otimizações específicas de domínio podem proporcionar grandes vantagens aos bancos de dados de séries temporais em relação aos bancos de dados de uso geral em termos de capacidades de domínio, desempenho, custo, estabilidade e outras dimensões.
Resumir
Os bancos de dados de séries temporais têm sido amplamente utilizados na Internet das Coisas, análise de dados financeiros, sistemas de monitoramento e alarme, gerenciamento de energia, aplicações de saúde e outras indústrias sensíveis ao "tempo". Ao usar bancos de dados de séries temporais para analisar e prever dados de séries temporais, as empresas podem obter informações valiosas dos dados, tomando decisões mais informadas e obtendo vantagens competitivas exclusivas.
No entanto, os bancos de dados de séries temporais e os bancos de dados relacionais não são incompatíveis. Como os sistemas de negócios geralmente ainda usam extensivamente os bancos de dados relacionais, como os dados de séries temporais e os dados de negócios podem ser combinados de maneira mais conveniente e melhor para gerar maior valor de negócios? banco de dados de série precisa resolver.
Sobre o Greptime:
Greptime A Greptime Technology está comprometida em fornecer serviços de análise e armazenamento de dados eficientes e em tempo real para campos que geram grandes quantidades de dados de séries temporais, como carros inteligentes, Internet das Coisas e observabilidade, ajudando os clientes a explorar o valor profundo dos dados. Atualmente existem três produtos principais:
-
GreptimeDB é um banco de dados de série temporal escrito em linguagem Rust. É distribuído, de código aberto, nativo da nuvem e altamente compatível. Ele ajuda as empresas a ler, escrever, processar e analisar dados de série temporal em tempo real, reduzindo os custos de armazenamento de longo prazo.
-
GreptimeCloud pode fornecer aos usuários serviços DBaaS totalmente gerenciados, que podem ser altamente integrados com observabilidade, Internet das Coisas e outros campos.
-
GreptimeAI é uma solução de observabilidade adaptada para aplicações LLM.
-
A solução integrada veículo-nuvem é uma solução de banco de dados de série temporal que se aprofunda nos cenários reais de negócios das montadoras e resolve os reais pontos problemáticos dos negócios depois que os dados dos veículos da empresa crescem exponencialmente.
GreptimeCloud e GreptimeAI foram oficialmente testados. Bem-vindo a seguir a conta oficial ou o site oficial para os últimos desenvolvimentos! Se você estiver interessado na versão empresarial do GreptimDB, entre em contato com o assistente (pesquise greptime no WeChat para adicionar o assistente).
Site oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentação: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Folga: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuro