
O que é alta cardinalidade
A cardinalidade é definida em matemática como um escalar usado para representar o número de elementos em um conjunto. Por exemplo, a cardinalidade de um conjunto finito A = {a, b, c} é 3. Existe também um conceito de cardinalidade para conjuntos infinitos. .Hoje falamos principalmente da área de informática, não vamos expandir aqui.
No contexto de um banco de dados, não existe uma definição estrita de cardinalidade, mas o consenso de todos sobre cardinalidade é semelhante à definição em matemática: é usada para medir o número de valores diferentes contidos em uma coluna de dados. Por exemplo , uma tabela de dados que registra usuários geralmente tem várias colunas UIDe Name, Genderobviamente, UIDa cardinalidade de tão alta quanto, e uma coluna de pode ter relativamente poucos valores. Assim, no exemplo da tabela do usuário, pode-se dizer que a coluna pertence à base alta e a coluna pertence à base baixa.IDNameUIDGenderUIDGender
Se for subdividido no campo do banco de dados de série temporal, a cardinalidade geralmente se refere ao número de linhas de tempo. Tomemos como exemplo a aplicação do banco de dados de série temporal no campo observável. Serviços de API. Para dar o exemplo mais simples, existem dois rótulos para o tempo de resposta de cada interface do serviço API de diferentes instâncias: API Routese Instance. Se houver 20 interfaces e 5 instâncias, a base da linha do tempo é (20+1)x(5. +1)-1 = 125 ( +1levando em consideração que o tempo de resposta de todas as interfaces de uma Instância ou o tempo de resposta de uma interface em todas as Instâncias pode ser visualizado separadamente), o valor não parece grande, mas deve-se ressaltar que o operador é um produto, portanto, desde que uma certa cardinalidade de um rótulo seja alta ou um novo rótulo seja adicionado, a cardinalidade da linha do tempo aumentará dramaticamente.
Por que isso importa
Como todos sabemos, bancos de dados relacionais como o MySQL, com os quais todos estão mais familiarizados, geralmente possuem colunas de ID, bem como colunas comuns, como email, número do pedido, etc. No entanto, certos problemas surgem devido a essa modelagem de dados. O fato é que no campo OLTP com o qual estamos familiarizados, a alta cardinalidade geralmente não é um problema, mas no campo do tempo, muitas vezes causa problemas por causa do modelo de dados. Antes de entrar no campo do tempo, ainda o discutiremos primeiro. Vamos dar uma olhada no que realmente significa um conjunto de dados de base alta.
Na minha opinião, em termos leigos, um conjunto de dados de alta base significa uma grande quantidade de dados. Para um banco de dados, o aumento na quantidade de dados terá inevitavelmente um impacto na escrita, na consulta e no armazenamento. impacto ao escrever é o índice.
Alta cardinalidade de bancos de dados tradicionais
Tomemos como exemplo a árvore B, a estrutura de dados mais comum usada para criar índices em bancos de dados relacionais. Normalmente, a complexidade de inserção e consulta é O (logN), e a complexidade do espaço é geralmente O (N). N é o número de elementos, que é a cardinalidade de que estamos falando. Naturalmente, quanto maior N terá um certo impacto, mas como a complexidade da inserção e da consulta é o logaritmo natural, o impacto não é tão grande quando a magnitude dos dados não é particularmente grande.
Portanto, parece que os dados de base alta não trazem nenhum impacto que não possa ser ignorado. Pelo contrário, em muitos casos, o índice de dados de base alta é mais selectivo do que o índice de dados de base baixa. pode filtrar dados grandes por meio de uma condição de consulta Dados parciais que não atendem às condições, reduzindo assim a sobrecarga de E/S do disco. Em aplicativos de banco de dados, é necessário evitar sobrecarga excessiva de E/S de disco e rede. Por exemplo select * from users where gender = "male";, o conjunto de dados resultante será muito grande e a E/S de disco e a E/S de rede serão muito grandes. Na prática, usar esse índice de baixa cardinalidade por si só não faz muito sentido.
Alta cardinalidade de bancos de dados de séries temporais
Então, o que há de diferente nos bancos de dados de série temporal que faz com que colunas de dados de raiz alta causem problemas? No campo de dados de séries temporais, seja modelagem de dados ou projeto de mecanismo, o núcleo girará em torno da linha do tempo. Conforme mencionado anteriormente, o problema de alta cardinalidade no banco de dados de séries temporais refere-se ao número e tamanho das linhas de tempo. Esse tamanho não é apenas a cardinalidade de uma coluna, mas o produto da cardinalidade de todas as colunas do rótulo. , pode-se entender que em bancos de dados relacionais comuns, a base alta é isolada em uma determinada coluna, ou seja, a escala dos dados cresce linearmente, enquanto a base alta em bancos de séries temporais é o produto de múltiplas colunas, o que não é linear crescimento. Vamos dar uma olhada mais de perto em como a linha do tempo de base alta é gerada no banco de dados de série temporal. Vejamos primeiro o primeiro cenário:
Quantidade de série temporal
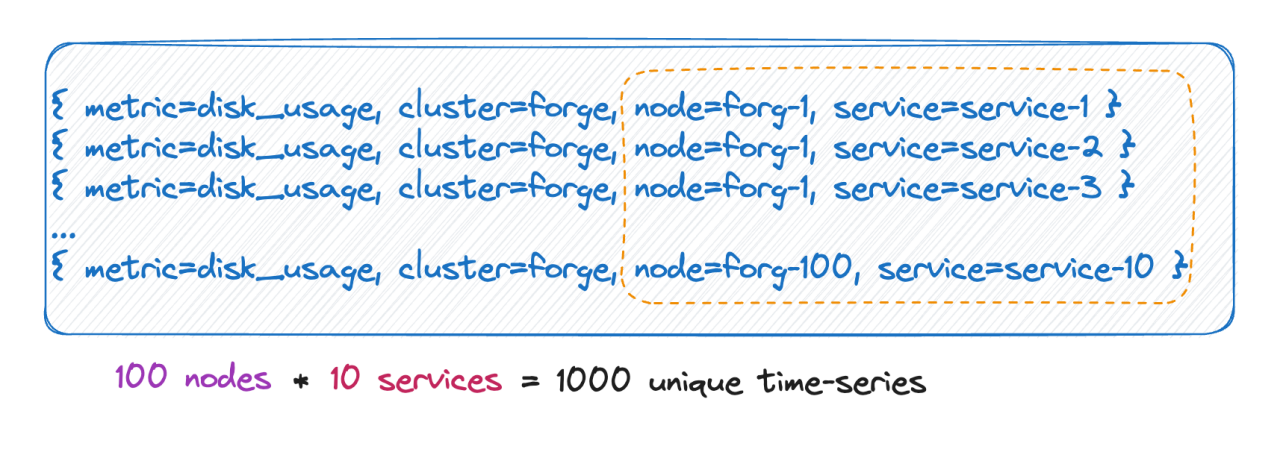
Sabemos que o número de linhas do tempo é na verdade igual ao produto cartesiano de todas as bases de rótulos. Conforme mostrado na imagem acima, o número de linhas do tempo é 100 * 10 = 1.000 linhas do tempo. Se 6 tags forem adicionadas a esta métrica, cada valor de tag terá 10 valores e o número de linhas do tempo será 10^9, que é 100 milhões. Uma linha do tempo, você pode imaginar essa magnitude.
Tag tem valores infinitos
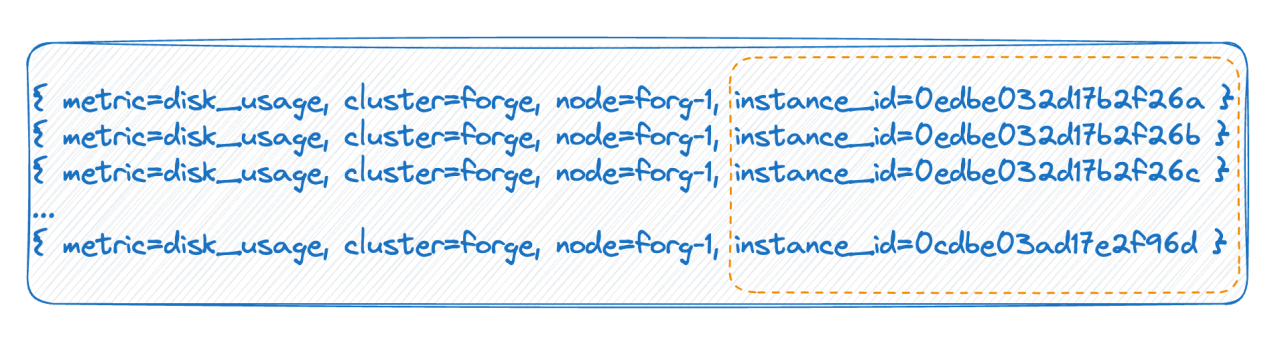
No segundo caso, por exemplo, em um ambiente nativo da nuvem, cada pod possui um ID. Cada vez que é reiniciado, o pod é realmente excluído e reconstruído, e um novo ID é gerado, o que faz com que o valor da tag seja muito. Existem muitos, e cada reinicialização completa fará com que o número de cronogramas dobre. As duas situações acima são as principais razões para a alta cardinalidade mencionada pela base de dados de séries temporais.
Como o banco de dados de série temporal organiza os dados
Sabemos como ocorre a alta cardinalidade. Precisamos entender quais problemas isso causará e também precisamos entender como os principais bancos de dados de séries temporais organizam os dados.
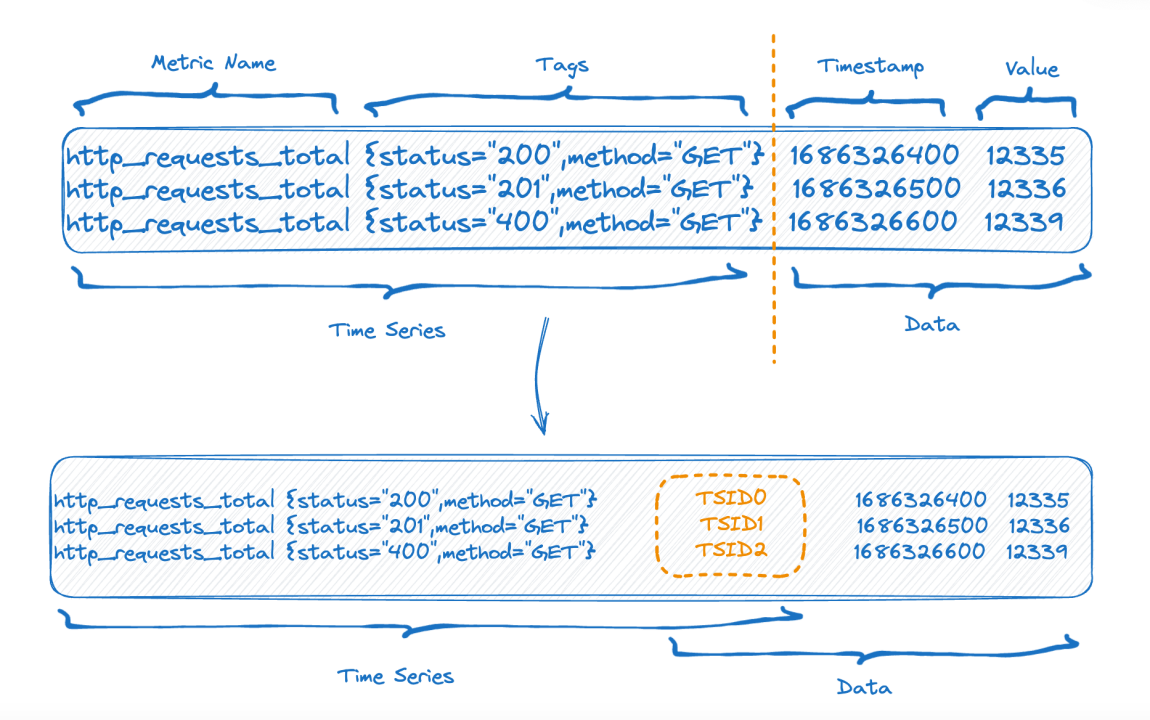
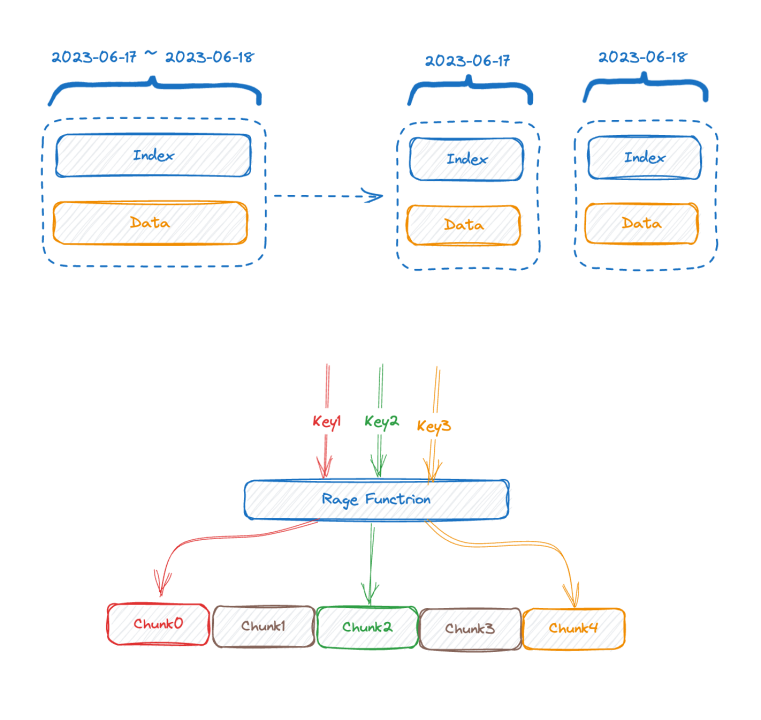
A metade superior da figura mostra a representação antes da gravação dos dados e a metade inferior da figura mostra a representação lógica após o armazenamento dos dados. O lado esquerdo são os dados do índice da parte da série temporal e o lado direito são os dados. papel.
Cada série temporal pode gerar um TSID exclusivo, e o índice e os dados são relacionados por meio do TSID. Amigos familiares podem ter visto esse índice, é um índice invertido.
Vejamos a imagem abaixo, que é uma representação do índice invertido na memória:
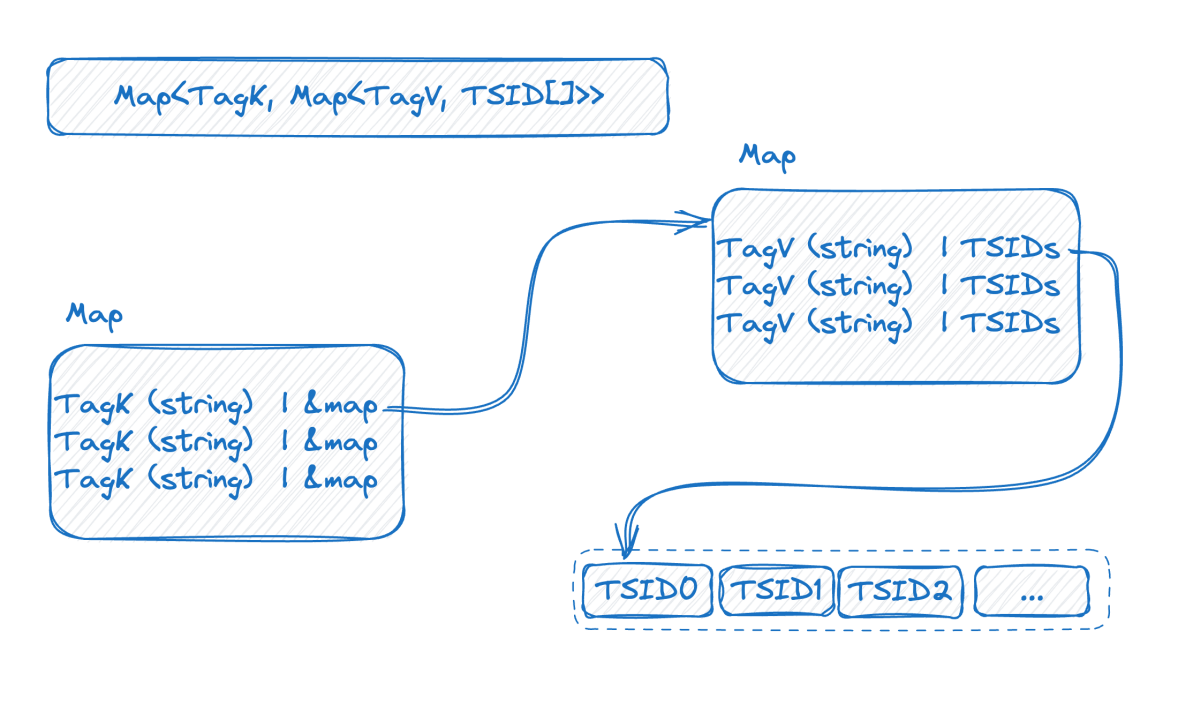
Este é um mapa de duas camadas. A camada externa primeiro encontra o mapa interno por meio do nome da tag. K no mapa interno é o valor da tag e V é o conjunto de TSIDs que contém o valor da tag correspondente.
Neste ponto, combinado com a introdução anterior, podemos ver que quanto maior a base dos dados da série temporal, maior será o mapa de camada dupla. Depois de compreender a estrutura do índice, podemos tentar entender como surge o problema de base alta:
Para obter gravação de alto rendimento, é melhor manter esse índice na memória. Alta cardinalidade fará com que o índice se expanda e você não conseguirá ajustá-lo na memória. Se a memória não puder ser armazenada, ela deverá ser trocada para o disco. Após a troca para o disco, a velocidade de gravação será afetada devido a uma grande quantidade de E/S aleatória do disco. Vejamos a consulta novamente. A partir da estrutura do índice, podemos adivinhar o processo de consulta, como as condições da consulta where status = 200 and method="get". O processo é primeiro encontrar statuso mapa com key , obter o mapa interno e, em seguida, "200"obter todos os conjuntos de TSID e verificar. novamente da mesma maneira. Uma condição e, em seguida, o novo conjunto de TSID obtido após a interseção dos dois conjuntos de TSID é usado para recuperar os dados um por um de acordo com o TSID.
Pode-se observar que o cerne do problema é que os dados estão organizados de acordo com a linha do tempo, então você deve primeiro obter a linha do tempo e, em seguida, encontrar os dados de acordo com a linha do tempo. Quanto mais cronogramas envolvidos em uma consulta, mais lenta será a consulta.
Como resolver isso
Se nossa análise estiver correta e soubermos a causa do problema de base alta no campo de dados de séries temporais, então será fácil resolvê-lo:
- Nível de dados: manutenção de índice e desafios de consulta causados por C(L1) * C(L2) * C(L3) * ... * C(Ln).
- Nível técnico: os dados são organizados de acordo com cronogramas, então você precisa primeiro obter o cronograma e depois encontrar os dados de acordo com o cronograma. Se houver mais cronogramas, a consulta será mais lenta.
O editor discutirá as soluções sob dois aspectos:
Otimização da modelagem de dados
1 Remova rótulos desnecessários
Muitas vezes definimos acidentalmente alguns campos desnecessários como rótulos, fazendo com que a linha do tempo fique inchada. Por exemplo, quando monitoramos o status do servidor, muitas vezes temos instance_name, ip, Na verdade, não é necessário que esses dois campos se tornem rótulos. Um deles provavelmente é suficiente e o outro pode ser definido como um atributo.
2. Modelagem de dados baseada em consultas reais
Tomemos como exemplo o monitoramento de sensores na Internet das Coisas:
- Dispositivos de 10 W
- 100 regiões
- 10 dispositivos
Se modelado em uma métrica, no Prometheus, resultará em uma linha do tempo de 10w * 100 * 10 = 100 milhões. (Cálculo não rigoroso) Pense bem, a consulta será realizada desta forma? Por exemplo, como consultar a linha do tempo de um determinado tipo de equipamento em uma determinada região? Isso parece irracional, porque uma vez especificado o dispositivo, o tipo é determinado, então os dois rótulos não precisam estar juntos, então pode se tornar:
- metric_one: dispositivos de 10 W
- métrica_dois:
- 100 regiões
- 10 dispositivos
- metric_três: (assumindo que um dispositivo pode ser movido para uma região diferente para coletar dados)
- Dispositivos de 10 W
- 100 regiões
O total é uma linha de tempo de 10w + 100 10 + 10w 100 ~ 1010w, que é 10 vezes menor que a anterior.
3. Gerencie separadamente dados valiosos de cronograma de alta base
Claro, se você achar que sua modelagem de dados é muito consistente com a consulta, mas o cronograma ainda não pode ser reduzido porque a escala de dados é muito grande, coloque todos os serviços relacionados a este indicador principal em uma máquina melhor.
Otimização da tecnologia de banco de dados de série temporal
- A primeira solução eficaz é a segmentação vertical. A maioria dos bancos de dados de séries temporais convencionais da indústria adotaram mais ou menos um método semelhante para segmentar o índice de acordo com o tempo, porque se essa segmentação não for feita, com o passar do tempo, o índice irá se expandir. cada vez mais, e finalmente a memória não será capaz de armazená-lo. Se for dividido de acordo com o tempo, o antigo pedaço do índice pode ser trocado para o disco ou até mesmo para armazenamento remoto.
- O oposto da segmentação vertical é a segmentação horizontal. É usada uma chave de sharding, que geralmente pode ser uma ou mais tags com a maior frequência de uso do predicado de consulta. A segmentação por intervalo ou hash é realizada com base nos valores dessas tags, que é realizada. equivalente a usar A ideia distribuída de dividir e conquistar resolve o gargalo em uma única máquina. O preço é que, se a condição de consulta não incluir uma chave de fragmentação, o operador não poderá ser empurrado para baixo e os dados só poderão ser movidos para o. camada superior para cálculo.
Os dois métodos acima são soluções tradicionais, que só podem aliviar o problema até certo ponto, mas não podem resolver o problema fundamentalmente. As próximas duas soluções não são soluções convencionais, mas são as direções que o GreptimeDB está tentando explorar. Elas são mencionadas apenas brevemente aqui, sem uma análise aprofundada, apenas para sua referência:
-
Podemos querer pensar se os bancos de dados de série temporal realmente precisam de índices invertidos. O TimescaleDB usa índices de árvore B e o InfluxDB_IOx não possui índices invertidos. Para consultas de alta cardinalidade, usamos varreduras de partição comumente usadas em bancos de dados OLAP combinados com min-max. índices. O efeito seria melhor se realizássemos alguma otimização de poda?
-
Indexação inteligente assíncrona Para ser inteligente, você deve primeiro coletar e analisar comportamentos e construir de forma assíncrona o índice mais apropriado para acelerar as consultas em cada consulta do usuário. Nenhuma inversão é criada para isso. Combinando as duas soluções acima, ao escrever, porque a inversão é construída de forma assíncrona, não afeta em nada a velocidade de escrita.
Olhando para a consulta novamente, como os dados da série temporal têm atributos de tempo, os dados podem ser agrupados de acordo com o carimbo de data e hora. Não indexamos o intervalo de tempo mais recente. A solução é realizar uma varredura completa e combinar alguns índices mínimo-máximo para otimização de remoção. Ainda é possível digitalizar dezenas de milhões ou centenas de milhões de linhas em segundos.
Quando chegar uma consulta, primeiro estime quantas timelines ela envolverá. Se envolver uma pequena quantidade, use inversão, e se envolver muito, vá diretamente para scan + filtro sem inversão.
Ainda estamos explorando as ideias acima e ainda não estamos perfeitos.
Conclusão
Uma base alta nem sempre é um problema. Às vezes, uma base alta é necessária. O que precisamos fazer é construir nosso próprio modelo de dados com base em nossas próprias condições de negócios e na natureza das ferramentas que usamos. É claro que às vezes as ferramentas têm certas limitações de cenário. Por exemplo, o Prometheus indexa rótulos em cada métrica por padrão. No entanto, isso não é um grande problema em um cenário de máquina única. esticado ao lidar com dados em grande escala. GreptimeDB está comprometido em criar uma solução unificada em cenários independentes e de grande escala. Também estamos explorando tentativas técnicas para problemas de base alta e todos são bem-vindos para discutir isso.
Referência
- https://en.wikipedia.org/wiki/Cardinalidade
- https://www.cncf.io/blog/2022/05/23/what-is-high-cardinality/
- https://grafana.com/blog/2022/10/20/how-to-manage-high-cardinality-metrics-in-prometheus-and-kubernetes/
Sobre o Greptime:
Greptime A Greptime Technology está comprometida em fornecer serviços de análise e armazenamento de dados eficientes e em tempo real para campos que geram grandes quantidades de dados de séries temporais, como carros inteligentes, Internet das Coisas e observabilidade, ajudando os clientes a explorar o valor profundo dos dados. Atualmente existem três produtos principais:
-
GreptimeDB é um banco de dados de série temporal escrito em linguagem Rust. É distribuído, de código aberto, nativo da nuvem e altamente compatível. Ele ajuda as empresas a ler, escrever, processar e analisar dados de série temporal em tempo real, reduzindo os custos de armazenamento de longo prazo.
-
GreptimeCloud pode fornecer aos usuários serviços DBaaS totalmente gerenciados, que podem ser altamente integrados com observabilidade, Internet das Coisas e outros campos.
-
GreptimeAI é uma solução de observabilidade adaptada para aplicações LLM.
-
A solução integrada veículo-nuvem é uma solução de banco de dados de série temporal que se aprofunda nos cenários reais de negócios das montadoras e resolve os reais pontos problemáticos dos negócios depois que os dados dos veículos da empresa crescem exponencialmente.
GreptimeCloud e GreptimeAI foram oficialmente testados. Bem-vindo a seguir a conta oficial ou o site oficial para os últimos desenvolvimentos! Se você estiver interessado na versão empresarial do GreptimDB, entre em contato com o assistente (pesquise greptime no WeChat para adicionar o assistente).
Site oficial: https://greptime.cn/
GitHub: https://github.com/GreptimeTeam/greptimedb
Documentação: https://docs.greptime.cn/
Twitter: https://twitter.com/Greptime
Folga: https://www.greptime.com/slack
LinkedIn: https://www.linkedin.com/company/greptime
Um programador nascido na década de 1990 desenvolveu um software de portabilidade de vídeo e faturou mais de 7 milhões em menos de um ano. O final foi muito punitivo! Alunos do ensino médio criam sua própria linguagem de programação de código aberto como uma cerimônia de maioridade - comentários contundentes de internautas: Contando com RustDesk devido a fraude desenfreada, serviço doméstico Taobao (taobao.com) suspendeu serviços domésticos e reiniciou o trabalho de otimização de versão web Java 17 é a versão Java LTS mais comumente usada no mercado do Windows 10 Atingindo 70%, o Windows 11 continua a diminuir Open Source Daily | Google apoia Hongmeng para assumir o controle de telefones Android de código aberto apoiados pela ansiedade e ambição da Microsoft; Electric desliga a plataforma aberta Apple lança chip M4 Google exclui kernel universal do Android (ACK) Suporte para arquitetura RISC-V Yunfeng renunciou ao Alibaba e planeja produzir jogos independentes para plataformas Windows no futuro