
Todos são bem-vindos para nos estrelar no GitHub:
Sistema distribuído de aprendizagem causal de link completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grande gráfico de conhecimento baseado em modelo OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizagem de gráficos em grande escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Título do artigo: PEACE: Protótipo de aprendizagem de estrutura transferível aumentada para recomendação entre domínios
Unidade organizacional: Grupo Ant
Conferência de Admissão: WSDM 2024
Link do artigo : https://arxiv.org/abs/2312.0191 6
O autor deste artigo: Gan Chunjing. As principais direções de pesquisa são algoritmos de grafos, algoritmos de recomendação, grandes modelos de linguagem e aplicação de gráficos de conhecimento. Os resultados da pesquisa estão incluídos nas principais conferências relacionadas ao aprendizado de máquina (WSDM/SIGIR/AAAI). O principal trabalho da equipe no ano passado foram modelos de recomendação pré-treinados baseados em gráficos de conhecimento, grandes modelos de linguagem baseados no aprimoramento do conhecimento e suas aplicações, incluindo a estrutura de rede neural gráfica baseada no desacoplamento multigranularidade no cenário de gestão financeira publicado no SIGIR'23 MGDL, o protótipo da estrutura de recomendação de pré-treinamento de domínios cruzados de gráfico de entidade baseado em aprendizagem PEACE publicado no WSDM'24.
fundo
Com o desenvolvimento do ecossistema de miniprogramas da Alipay, mais e mais comerciantes começaram a operar miniprogramas no Alipay. Ao mesmo tempo, a Alipay também espera alcançar uma estratégia descentralizada através da ecologia de miniprogramas + autooperação do comerciante.
No processo de autooperação dos comerciantes, cada vez mais pequenos e médios comerciantes têm necessidade de operações digitais e inteligentes, como melhorar a eficiência de marketing de suas posições de domínio privado de miniprogramas por meio de recursos de recomendação personalizados, mas para pequenos e empresas comerciais de médio porte, o custo técnico e o custo de mão de obra para construir recursos de recomendação personalizados de IA autoconstruídos são muito altos.
Neste contexto, esperamos fornecer aos comerciantes recomendações personalizadas visíveis, mas inacessíveis, e recursos de pesquisa com base nos enormes dados de comportamento do usuário do Ant para ajudar os comerciantes a criar miniprogramas inteligentes para aumentar a receita dos comerciantes na plataforma Alipay e fornecer aos usuários uma melhor experiência personalizada pode melhorar a retenção de usuários no Alipay e também pode acumular soluções técnicas comuns para otimizar ainda mais a experiência do comerciante/usuário.
Tem havido muitos casos de aplicação bem-sucedidos na indústria que usam dados de cenários comportamentais ricos para melhorar o efeito de recomendação em cenários de cauda média e longa. Por exemplo, o Taobao usa os dados comportamentais de primeira estimativa para melhorar o efeito de recomendação em outros pequenos. cenários. Fliggy usa o aplicativo e pequenos cenários Alipay para melhorar o efeito de recomendação. O terminal modela em conjunto para melhorar o efeito de recomendação geral.
No entanto, este tipo de método geralmente enfrenta vários cenários de recomendação com mentalidades semelhantes e usa dados de cenários com comportamentos ricos para melhorar o efeito de recomendação de cenários semelhantes com comportamentos esparsos, como Taobao, Fliggy, etc. No entanto, super APPs como o Alipay geralmente incluem vários miniprogramas, como viagens, assuntos governamentais, leasing, viagens, catering, necessidades diárias, etc. desafios:
- Os miniprogramas da Alipay estão espalhados em indústrias verticais com tipos de negócios muito diferentes, como assuntos governamentais, alimentos, leasing, varejo e gestão financeira. De modo geral, as informações não são compartilhadas entre esses miniprogramas e itens semelhantes podem não ter atributos semelhantes. transferindo diretamente vários comportamentos em todo o domínio para um cenário de classe vertical específico sem alinhar essas diferenças entre domínios, é difícil para o modelo aprender conhecimento útil para a classe vertical a partir dos comportamentos mistos de múltiplas classes verticais, e pode até ser Will provocar migração negativa;
- Embora a migração ponto a ponto do comportamento do usuário, por exemplo, a indústria alimentícia use apenas os comportamentos relacionados à alimentação dos usuários no Alipay, pode aliviar os problemas acima até certo ponto, mas cada vez que uma nova indústria é adicionada, a intervenção manual é necessária , que é caro e não pode realizar toda a cadeia. Além da automação rodoviária, alguns comerciantes também esperam que a plataforma Alipay possa fornecer soluções de recomendação personalizadas plug-and-play ao se conectar pela primeira vez, mesmo quando não há dados de comportamento do usuário. . Tal modelo não é viável neste cenário.
Com base nos desafios acima, propusemos PEACE, uma estrutura de aprendizagem por transferência multicenário de pré-treinamento gráfico baseada na aprendizagem de protótipos, baseada no problema de grandes diferenças entre domínios verticais da indústria.
Introduzimos o gráfico de entidade e esperávamos usar o gráfico de entidade como uma ponte para conectar as diferenças entre os diferentes domínios e mitigar seu impacto negativo na modelagem. No entanto, o gráfico de entidade no ambiente de produção é geralmente enorme, embora contenha um grande número de. entidades. No entanto, também introduzirá muito ruído. A agregação indiscriminada de informações estruturais no mapa de entidades geralmente reduzirá a robustez do modelo. Portanto, introduzimos o aprendizado de protótipo para melhorar a representação da entidade e do usuário no processo de modelagem. para restringir.
No geral, a estrutura PEACE é a ideia de design de migração do ONE FOR ALL. Usamos o comportamento de domínio público de múltiplas fontes do Alipay como entrada do modelo de pré-treinamento e aprendemos os interesses e preferências do usuário em vários setores. um através da ideia de representação desacoplada No modelo, combinado com a rede protótipo que captura sinais da indústria, ele só precisa pré-treinar um modelo unificado para migrar de forma adaptativa os múltiplos interesses dos usuários para diferentes indústrias verticais downstream para recomendações personalizadas ( recomendação normal + dose zero recomendada).
PEACE - Estrutura de recomendação de pré-treinamento de gráfico de entidade com base no aprendizado de protótipo
Alinhamento preliminar de conhecimento entre domínios com base no gráfico de entidade
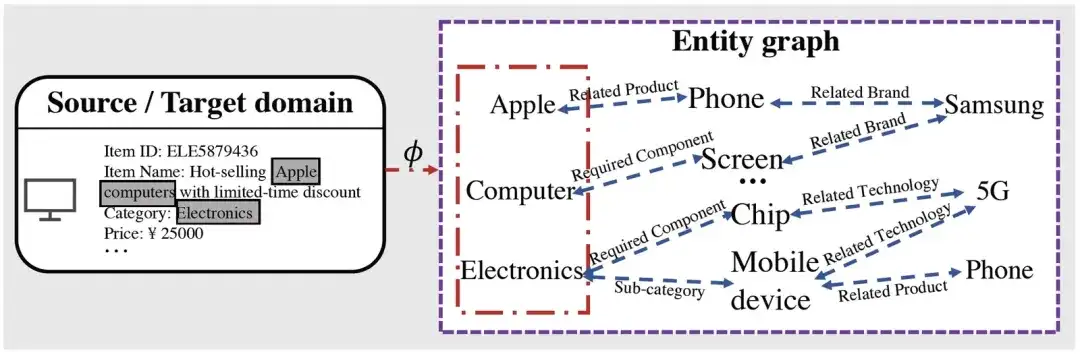

Percebe-se que após obter a entidade relacionada ao item correspondente por meio do mapeamento, com base no processo de raciocínio gráfico, podemos obter muitas informações de alto nível relacionadas à entidade mapeada. Por exemplo, a Apple possui produtos de telefonia móvel, e. empresas relacionadas a produtos de telefonia móvel Existem Samsung, etc., o que pode potencialmente encurtar o relacionamento com outras entidades relacionadas (como telefones celulares produzidos pela Samsung, etc.).
estrutura do modelo
Nesta seção, apresentaremos a estrutura de recomendação de vários domínios de pré-treinamento PEACE proposta neste artigo. A figura a seguir mostra a arquitetura geral do PEACE. No geral, a fim de alcançar melhor o alinhamento entre domínios e utilizar melhor as informações estruturais no gráfico da entidade, nossa estrutura geral é construída no módulo de pré-treinamento orientado à entidade , a fim de melhorar ainda mais o relacionamento entre usuários e entidades no; módulo de pré-treinamento Representação para torná-lo mais versátil e transferível, propomos um módulo de aprimoramento de representação de entidade baseado no aprendizado de contraste de protótipo e um módulo de aprimoramento de representação de usuário baseado no mecanismo de atenção de aprimoramento de protótipo para aprimorar sua representação nesta base, definimos objetivos de otimização ; e processo de implantação on-line leve na fase de pré-treinamento e na fase de ajuste fino . A seguir, apresentaremos cada módulo um por um.
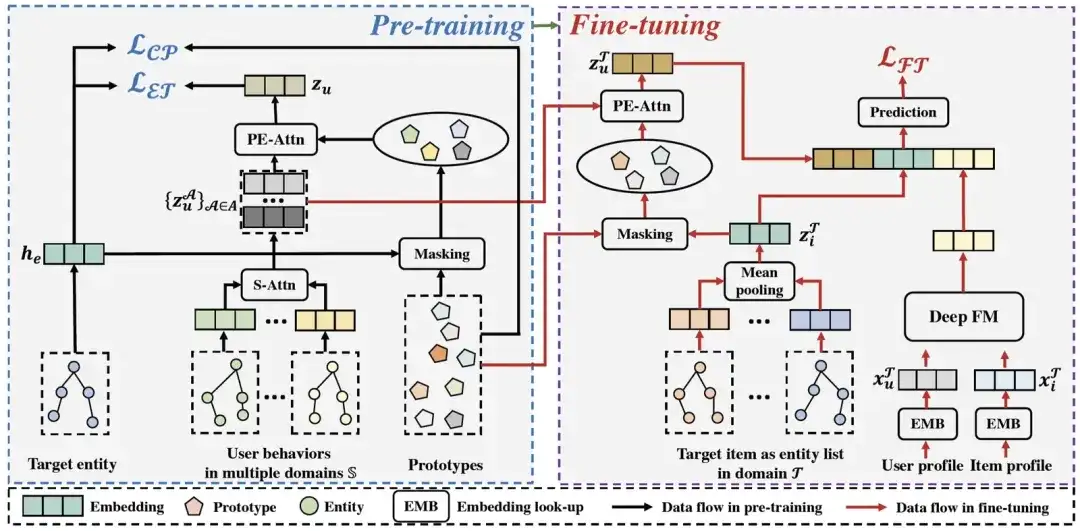
Arquitetura geral PAZ
01. Módulo de pré-treinamento orientado a entidades
Plataformas de serviços online como o Alipay reúnem uma variedade de pequenos programas/cenários fornecidos por diferentes provedores de serviços. De modo geral, as informações entre esses cenários não são interoperáveis e, portanto, não há sistema de dados compartilhado. categoria, os atributos dos produtos atuais não podem ser completamente alinhados (por exemplo, o iPhone 14 vendido em diferentes miniprogramas tem diferentes IDs de produto e nomes de categoria. Por exemplo, a categoria são produtos eletrônicos em um miniprograma e a categoria são eletrônicos em outro miniprograma). Para reduzir as diferenças causadas por esses potenciais problemas e seu impacto no desempenho da modelagem, e ao mesmo tempo fazer melhor uso dessas informações interativas, realizamos um pré-treinamento baseado no mapa de entidades, na esperança de introduzir informações granulares de entidade em desta forma. Obtenha um pré-treinamento com generalização mais forte.


Tomando a Figura 1 como exemplo, se for item→entidade→entidade, a partir deste produto, para Apple, só podemos saber que seus produtos relacionados são Telefone, mas através do pré-treinamento de entidade→entidade→entidade, podemos saber que a Apple não está apenas com produtos relacionados como o Phone, também podemos saber que está relacionado com a empresa Samsung, melhorando assim ainda mais a generalização das representações que aprendemos).
02. Módulo de aprimoramento de representação de entidade baseado em protótipo de aprendizagem contrastiva

03. Módulo de aprimoramento de representação do usuário baseado em protótipo de mecanismo de atenção aprimorada
Na fase de pré-treinamento, os dados coletados no domínio de origem contêm o comportamento do usuário em diferentes cenários. Por exemplo, ao fazer planos de viagem, os usuários visitarão cenários relacionados a viagens e, ao procurarem emprego, visitarão empregos on-line. cenários relacionados, no entanto, a representação geral do usuário aprendida na etapa anterior não leva em consideração o contexto relacionado ao usuário e à cena, o que torna impossível capturar a representação relacionada à cena em diferentes cenas. usar o mecanismo de atenção para melhorar o contexto de captura para melhorar a representação do usuário.

04. Treinamento e previsão do modelo
- Link de pré-treinamento do domínio de origem
Ao combinar o módulo de pré-treinamento orientado à entidade e o módulo de aprimoramento de aprendizagem do protótipo, o objetivo geral de otimização pode ser definido da seguinte maneira:
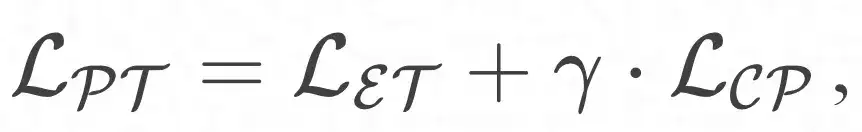

- Link de ajuste fino do domínio de destino

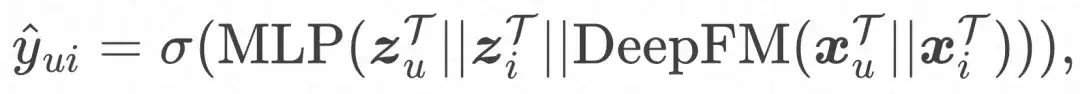
E a função de perda final:
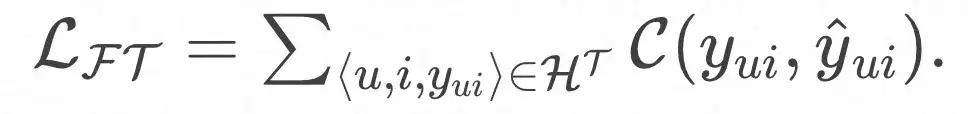

Implantação on-line
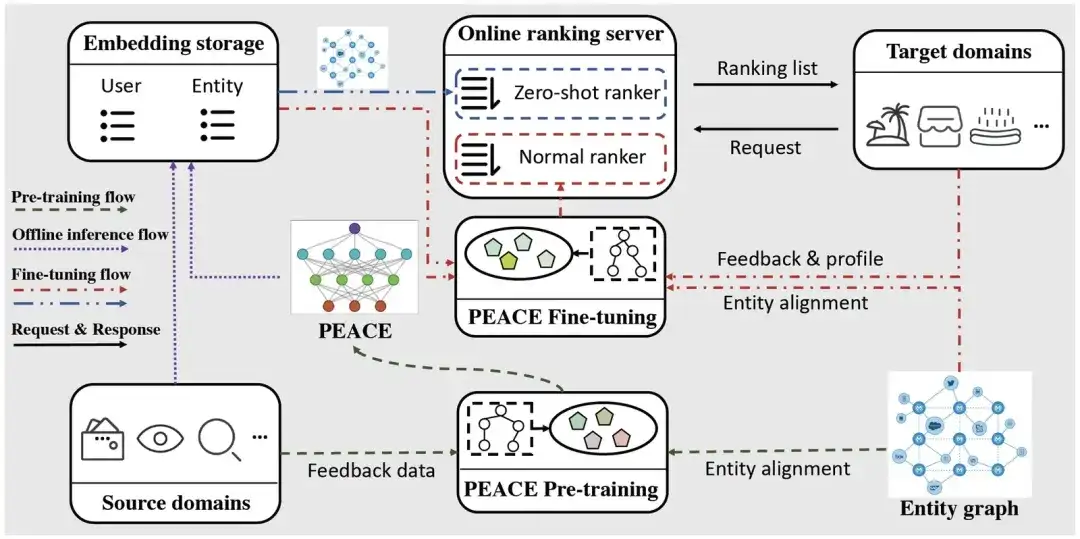
Para aliviar a pressão sobre os serviços online, utilizamos um método leve para implantar o modelo PEACE. O fluxo de implantação é dividido principalmente em três partes:
- Fluxo de pré-treinamento: Com base nos dados comportamentais de múltiplas fontes coletados e nos mapas de entidades, atualizamos o modelo PEACE diariamente para que o modelo possa aprender conhecimento transferível universal e urgente. Para o modelo pré-treinado, nós o armazenamos no ModelHub para facilitar o carregamento leve dos parâmetros do modelo para uso downstream.
- Fluxo de inferência offline: para reduzir a carga trazida pela rede neural gráfica ao sistema de serviço online, inferiremos as representações do usuário e da entidade antecipadamente e, em seguida, armazenaremos na tabela ODPS apenas durante o ajuste fino downstream. o MLP final A rede é ajustada sem refazer o processo de propagação de informações na rede neural gráfica, reduzindo significativamente a latência dos serviços online.
- Fluxo de ajuste fino: Como os miniprogramas/serviços recém-lançados não possuem dados interativos, o PEACE fornece serviços de recomendação através das duas etapas a seguir:
- Para o cenário de inicialização a frio, fazendo diretamente o produto interno das representações do usuário e do item, podemos obter a preferência do usuário por diferentes itens e classificá-los diretamente;
- Para cenários sem inicialização a frio, onde uma certa quantidade de dados foi acumulada, ajustamos com base na representação pré-treinada do usuário/item e nas informações básicas do usuário/item e, em seguida, usamos o modelo ajustado para serviços online.
Análise de eficácia
Experiência off-line
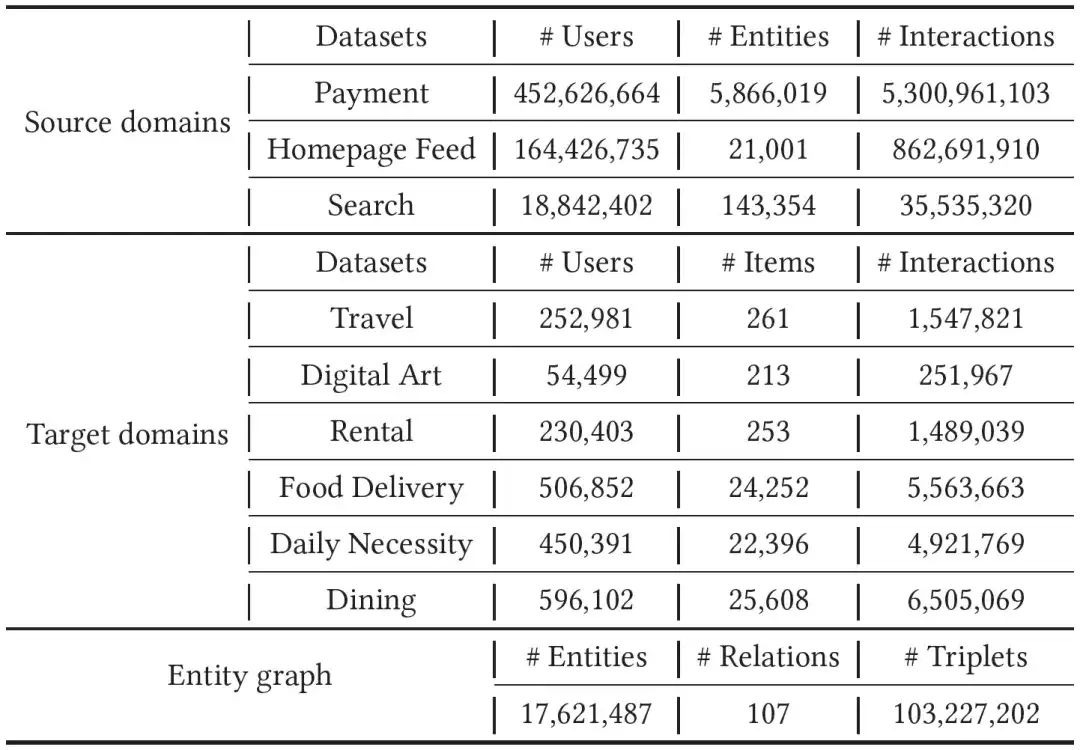
01. Introdução de dados
Coletamos contas Alipay de um mês, pegadas e dados de pesquisa como dados do domínio de origem. Para o domínio de destino, conduzimos experimentos em seis tipos de miniprogramas, ou seja, aluguel, viagens, coleções digitais, necessidades diárias, comida gourmet e entrega de comida. . Experimento, como os dados do domínio de destino são mais esparsos que o domínio de origem, coletamos dados comportamentais nos últimos dois meses para treinamento do modelo. Para preencher as enormes diferenças entre os diferentes domínios, introduzimos um gráfico de entidade com dezenas de milhões de nós, centenas de relacionamentos e bilhões de arestas. Dados específicos podem ser encontrados na tabela abaixo.
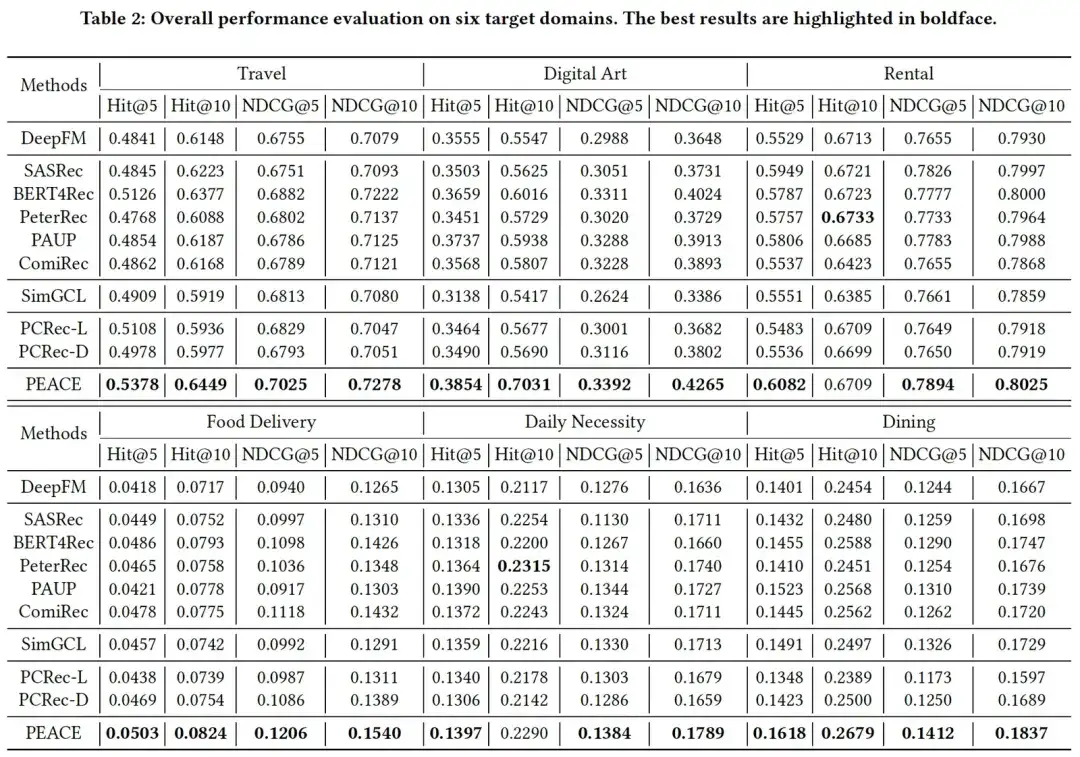
02. Experiência de eficácia
Combinando os resultados experimentais nas duas tabelas podemos constatar que, no geral, os resultados experimentais mostram:
- O PEACE alcançou melhorias significativas em comparação com a linha de base em ambos os cenários de arranque a frio/não a frio, o que demonstra a eficácia da combinação de pré-formação baseada na granularidade da entidade e mecanismos de melhoria baseados na aprendizagem de protótipos;
- Na maioria dos casos, o modelo pré-treinado + ajustado tem uma melhoria maior do que o DeepFM de base sem pré-treinamento, o que ilustra a eficácia da introdução de dados de múltiplas fontes para pré-treinamento. No entanto, em alguns casos, alguns O desempenho. do modelo não é tão bom quanto o DeepFM de base, e há um certo grau de transferência negativa, o que ilustra ainda mais a importância dos métodos de pré-treinamento;
- Em muitos casos, os modelos de recomendação entre domínios baseados em gnn não alcançaram bons resultados experimentais. Isso se deve em grande parte ao enorme ruído no gráfico de entidades. Desde que introduzimos o aprendizado de protótipo no modelo PEACE, o método de classe cria entidades semelhantes. têm distâncias semelhantes no espaço de representação, enquanto a distância entre diferentes entidades é ampliada, aliviando assim o impacto negativo desses ruídos no modelo.
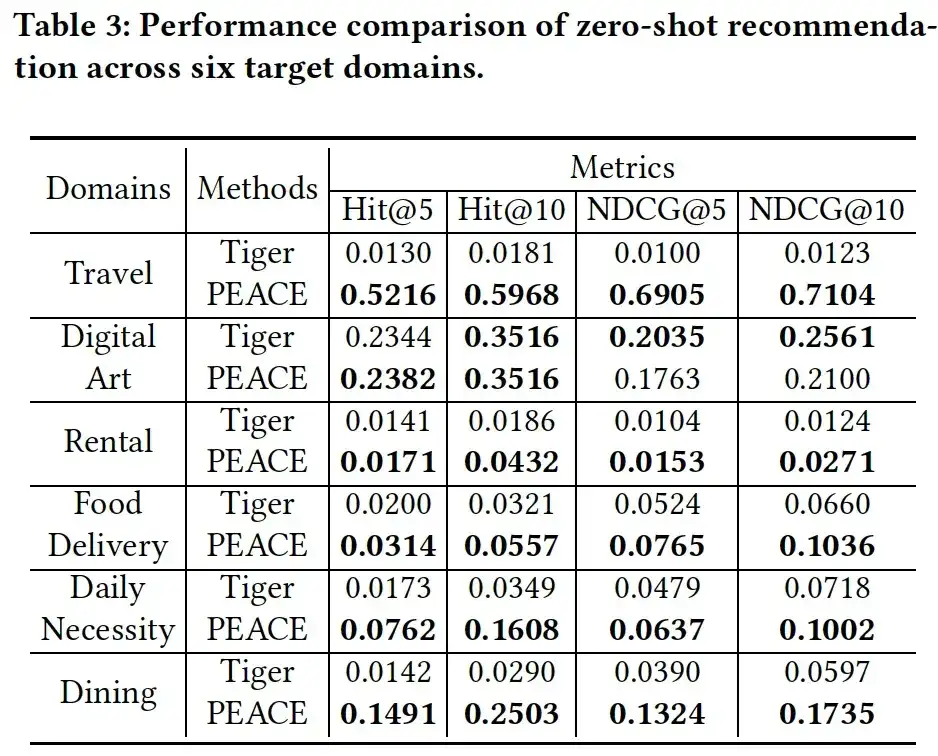
03. Análise de ablação
A fim de verificar melhor o papel de cada módulo no modelo PEACE, preparamos as três variantes a seguir para avaliar a eficácia de cada módulo:
- PEACE sem GL, o módulo de aprendizagem de gráficos quando as representações de entidades são removidas;
- PEACE sem CPL, ou seja, remoção do módulo de aprendizagem de protótipo baseado em comparação;
- PEACE sem PEA, que remove o módulo do mecanismo de atenção baseado no aprimoramento do protótipo. Como pode ser visto na Figura 4, quando qualquer módulo é removido, o desempenho do modelo cai significativamente, o que ilustra a indispensabilidade de cada módulo no modelo, além disso, pode-se observar que o desempenho do PEACE sem CPL Na pior das hipóteses, isso ilustra a importância da aprendizagem de protótipos na captura de conhecimento geral transferível.
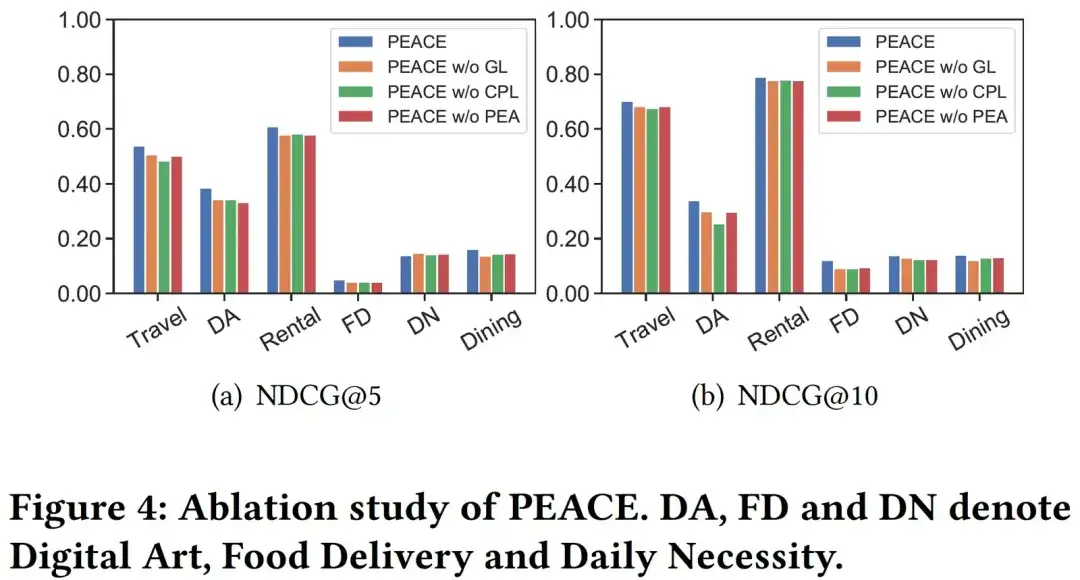
04. Análise visual
Para analisar o efeito do módulo CPL de forma mais explícita, selecionamos aleatoriamente 6.000 entidades no mapa de entidades e suas representações de entidades aprendidas por meio de PEACE sem modelos CPL e PEACE para visualizá-las. Aqui estão várias cores que correspondem aos diferentes protótipos pertencentes. para diferentes entidades. Na Figura 5 podemos ver que em comparação com a representação da entidade aprendida pelo PEACE sem CPL, a representação aprendida pelo modelo PEACE completo tem melhor coerência nos resultados do agrupamento, o que ilustra o módulo CPL e seu protótipo aprendido pode muito bem ajudar o o modelo reduz a distância entre entidades semelhantes no espaço de representação, ajudando assim melhor o modelo a aprender um conhecimento mais robusto e universal.
Experimentos online e implementação de negócios
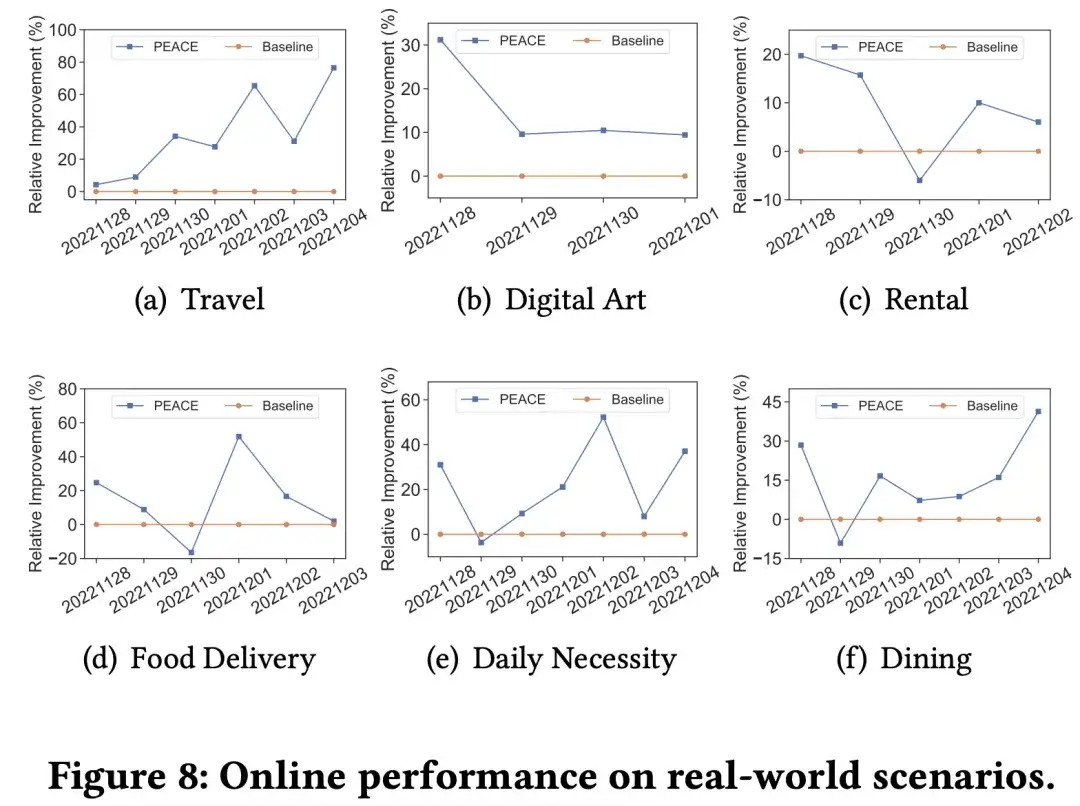
Para verificar melhor o efeito do modelo no ambiente de produção real, conduzimos experimentos AB online refinados em vários comerciantes em diferentes categorias verticais. Em vários cenários, o modelo PEACE alcançou resultados eficazes em comparação com a promoção da linha de base. No geral, o modelo de recomendação de pré-treinamento + aprendizagem por transferência baseado em PEACE foi totalmente aplicado como um modelo de linha de base para mais de 50 comerciantes para fornecer recomendações personalizadas após serem verificadas pelos efeitos ab nos principais comerciantes.
Recomendações de artigos
OpenSPG v0.0.3 é lançado, adicionando código aberto de extração de conhecimento unificado de modelo grande e visualização de gráfico! Ant Group e Zhejiang University lançam em conjunto OneKE, uma estrutura de extração de conhecimento de grande modelo de código aberto
Siga-nos
OpenSPG:
Site oficial: https://spg.openkg.cn
Github: https://github.com/OpenSPG/openspg
OpenASCE:
官网:https://openasce.openfinai.org/
GitHub:[https://github.com/Open-All-Scale-Causal-Engine/OpenASCE ]