
Todos são bem-vindos para nos estrelar no GitHub:
Sistema distribuído de aprendizagem causal de link completo OpenASCE: https://github.com/Open-All-Scale-Causal-Engine/OpenASCE
Grande gráfico de conhecimento baseado em modelo OpenSPG: https://github.com/OpenSPG/openspg
Sistema de aprendizagem de gráficos em grande escala OpenAGL: https://github.com/TuGraph-family/TuGraph-AntGraphLearning
Nos dias 25 e 26 de abril, a Conferência Global de Tecnologia de Aprendizado de Máquina foi realizada no Hyatt Regency Global Harbour Hotel em Xangai! Wang Qinlong, chefe de DLRover de código aberto do Ant Group, fez um discurso principal sobre "Autocura de falhas de treinamento DLRover: Melhorando significativamente a eficiência do poder de computação do treinamento de IA em larga escala" na conferência, compartilhando como se autocurar rapidamente de falhas em operações de treinamento de modelos em grande escala de quilocalorias Wang Qinlong apresentou os princípios técnicos e casos de uso por trás do DLRover, bem como os efeitos práticos do DLRover em grandes modelos comunitários.

Wang Qinlong, que está envolvido na pesquisa e desenvolvimento de infraestrutura de IA na Ant há muito tempo, liderou a construção dos projetos de tolerância elástica a falhas e de expansão e contração automática do treinamento distribuído da Ant. Ele participou de vários projetos de código aberto, como ElasticDL e DLRover, foi um Vibrant Open Source Contributor da Open Atomic Foundation em 2023 e um T-Star Outstanding Engineer de 2022 do Ant Group. Atualmente, ele é o arquiteto do projeto de código aberto Ant AI Infra DLRover, com foco na construção de sistemas de treinamento distribuídos em larga escala estáveis, escaláveis e eficientes.
Treinamento e desafios de grandes modelos
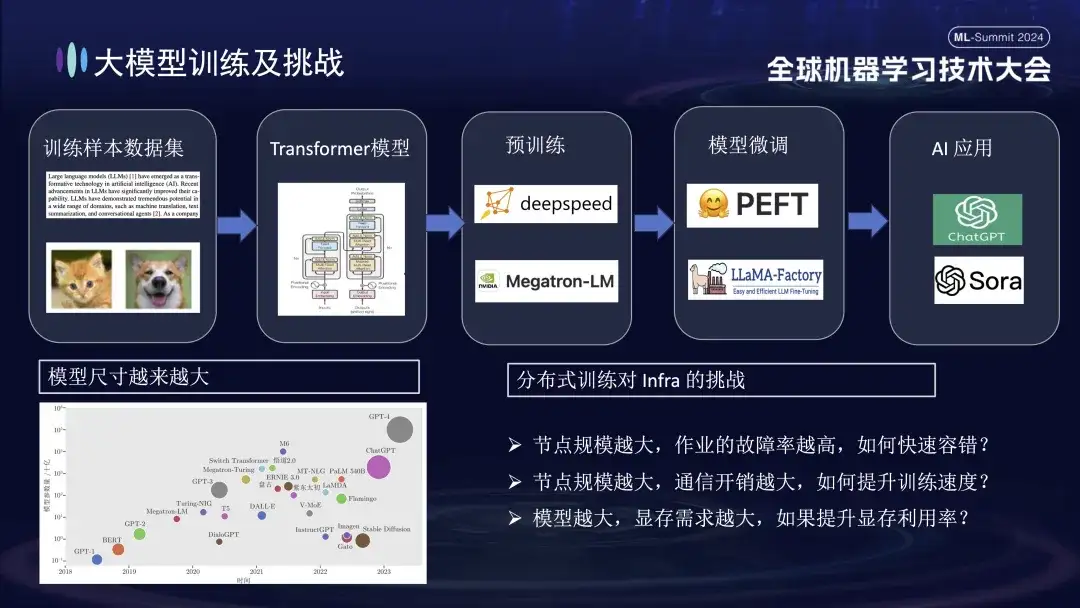
O processo básico de treinamento de modelos grandes é mostrado na figura acima. Ele requer a preparação de conjuntos de dados de amostra de treinamento, a construção do modelo Transformer, o pré-treinamento, o ajuste fino do modelo e, finalmente, a construção de um aplicativo de IA do usuário. À medida que os grandes modelos passam de um bilhão de parâmetros para um trilhão de parâmetros, o crescimento na escala de treinamento levou a um aumento nos custos dos clusters e também afetou a estabilidade do sistema. Os altos custos de operação e manutenção trazidos por um sistema de tão grande escala tornaram-se um problema urgente que precisa ser resolvido durante o treinamento de modelos de grande porte.
- Quanto maior o tamanho do nó, maior a taxa de falha do trabalho. Como tolerar falhas rapidamente ?
- Quanto maior o tamanho do nó, maior será a sobrecarga de comunicação. Como melhorar a velocidade de treinamento ?
- Quanto maior o tamanho do nó, maior será o requisito de memória. Como melhorar a utilização da memória ?
Pilha de tecnologia de engenharia Ant AI
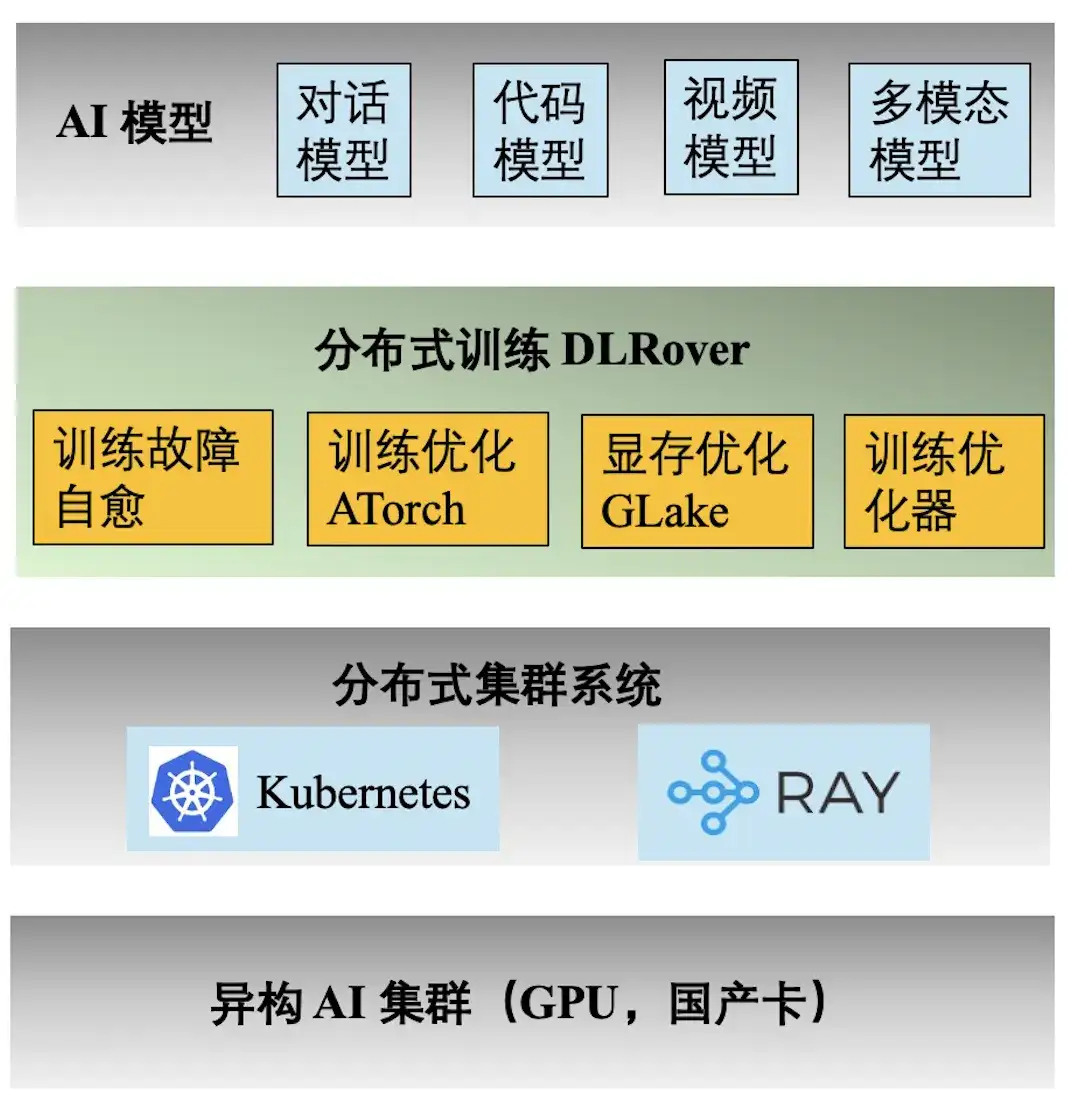
A figura acima mostra a pilha de tecnologia de engenharia do treinamento Ant AI. O mecanismo de treinamento distribuído DLRover suporta uma variedade de tarefas de treinamento para diálogo, código, vídeo e modelos multimodais do Ant. A seguir estão os principais recursos fornecidos pelo DLRover:
- **Autocura de falhas de treinamento:** Aumente o tempo efetivo de treinamento distribuído de quilocalorias para >97%, reduzindo o custo de poder computacional de falhas de treinamento em grande escala;
- **ATorch de otimização de treinamento:** Selecione automaticamente a estratégia de treinamento distribuído ideal com base no modelo e no hardware. Aumentar a taxa de utilização do poder computacional do hardware do cluster Kcal (A100) para >60%;
- **Otimizador de treinamento:** O otimizador equivale à navegação da iteração do modelo, o que pode nos ajudar a atingir o objetivo no caminho mais curto. Nosso otimizador melhora a aceleração de convergência em 1,5x em comparação com AdamW. Resultados relevantes foram publicados em ECML PKDD '21, KDD'23, NeurIPS '23;
- **Memória de vídeo e otimização de transmissão GLake: **Durante o processo de treinamento de modelos grandes, muitos fragmentos de memória de vídeo serão gerados, o que reduz bastante a utilização de recursos de memória de vídeo. Reduzimos os requisitos de memória de treinamento em 2 a 10 vezes por meio da memória integrada + otimização de transmissão e otimização de memória global. Os resultados foram publicados na ASPLOS'24.
Por que as falhas levam ao desperdício de poder computacional
A razão pela qual Ant presta especial atenção ao problema das falhas de treinamento é principalmente porque as falhas da máquina durante o processo de treinamento aumentam significativamente o custo do treinamento. Por exemplo, Meta anunciou os dados reais para seu treinamento de modelo grande em 2022. Ao treinar o modelo OPT-175B, ele usou 992 GPUs A100 de 80 GB, um total de 124 máquinas de 8 placas. De acordo com os preços da GPU da AWS, custa cerca de 700.000. por dia. . Devido à falha, o ciclo de treinamento foi estendido por mais de 20 dias, aumentando assim o custo do poder de computação em dezenas de milhões de yuans.

A imagem abaixo mostra a distribuição de falhas encontradas ao treinar modelos grandes em clusters do Alibaba Cloud. Algumas dessas falhas podem ser resolvidas reiniciando, enquanto outras não podem ser reparadas reiniciando. Por exemplo, o problema de queda do cartão, porque o cartão com defeito ainda está danificado após a reinicialização. A máquina danificada deve ser substituída antes que o sistema possa ser reiniciado e restaurado.
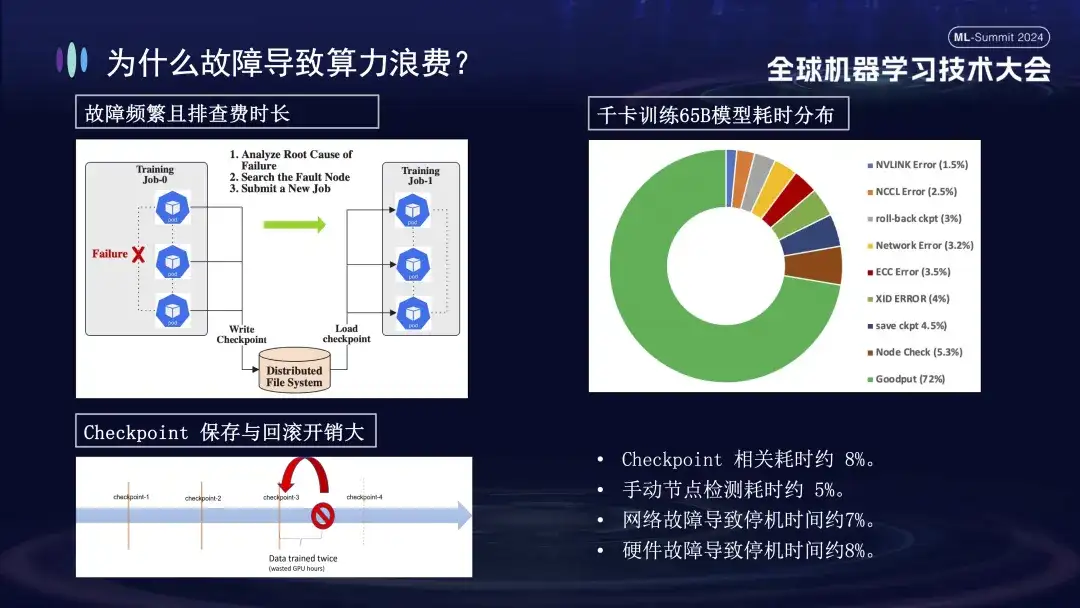
Por que as falhas de treinamento têm um impacto tão grande? Em primeiro lugar, o treinamento distribuído requer que vários nós trabalhem juntos. Se algum nó falhar (seja um problema de software, hardware, placa de rede ou GPU), todo o processo de treinamento precisará ser suspenso. Em segundo lugar, após ocorrer uma falha no treinamento, a solução de problemas é demorada e trabalhosa. Por exemplo, o método de inspeção manual comumente usado agora requer pelo menos 1 a 2 horas para ser verificado uma vez. Finalmente, o treinamento tem estado. Para reiniciar o treinamento, você precisa se recuperar do estado de treinamento anterior antes de continuar, e o estado de treinamento deve ser salvo após um período de tempo. O processo de salvamento leva muito tempo e a reversão de falhas também causará desperdício de cálculos. A imagem acima mostra a distribuição do tempo de treinamento antes de entrarmos online para realizar a autocorreção. Pode-se observar que o tempo relevante do Checkpoint é de cerca de 8%, o tempo de detecção manual do nó é de cerca de 5% e o tempo de inatividade causado. por falha de rede é de cerca de 7%, falha de hardware causa cerca de 8% de tempo de inatividade e o tempo final de treinamento efetivo é de apenas 72%.
Visão geral das funções de autocorreção de falhas de treinamento DLRover

A imagem acima mostra as duas funções principais do DLRover na tecnologia de autocorreção de falhas. Em primeiro lugar, o Flash Checkpoint pode salvar rapidamente o estado sem interromper o processo de treinamento e obter backup de alta frequência. Isto significa que, em caso de falha, o sistema pode recuperar imediatamente do ponto de verificação mais recente, reduzindo a perda de dados e o tempo de treino. Em segundo lugar, o DLRover usa Kubernetes para implementar um mecanismo inteligente de agendamento elástico. Este mecanismo pode responder automaticamente a falhas de nós. Por exemplo, se um nó falhar em um cluster de 100 máquinas, o sistema se ajustará automaticamente a 99 máquinas para continuar o treinamento sem intervenção manual. Além disso, é compatível com Kubeflow e PyTorchJob e fortalece os recursos de monitoramento da integridade dos nós para garantir que quaisquer falhas sejam rapidamente identificadas e respondidas em 10 minutos, mantendo a continuidade e a estabilidade das operações de treinamento.
Treinamento elástico de tolerância a falhas DLRover
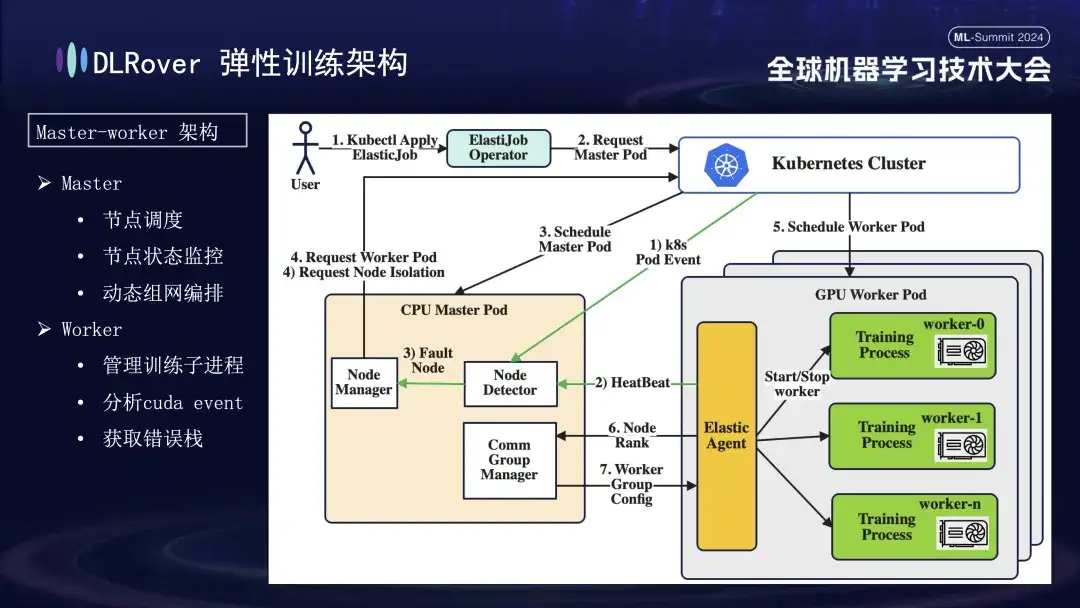
O DLRover adota uma arquitetura master-worker, o que não era comum nos primeiros dias do aprendizado de máquina. Neste projeto, o mestre atua como centro de controle e é responsável por tarefas importantes, como agendamento de nós, monitoramento de status, gerenciamento de configuração de rede e análise de log de falhas, sem executar o código de treinamento. Geralmente implantado em nós de CPU. Os trabalhadores suportam a carga de treinamento real e cada nó executará vários subprocessos para utilizar as múltiplas GPUs do nó para acelerar as tarefas de computação. Além disso, para aumentar a robustez do sistema, customizamos e aprimoramos o Elastic Agent no trabalhador para permitir detecção e localização de falhas mais eficazes, garantindo estabilidade e eficiência durante o processo de treinamento.
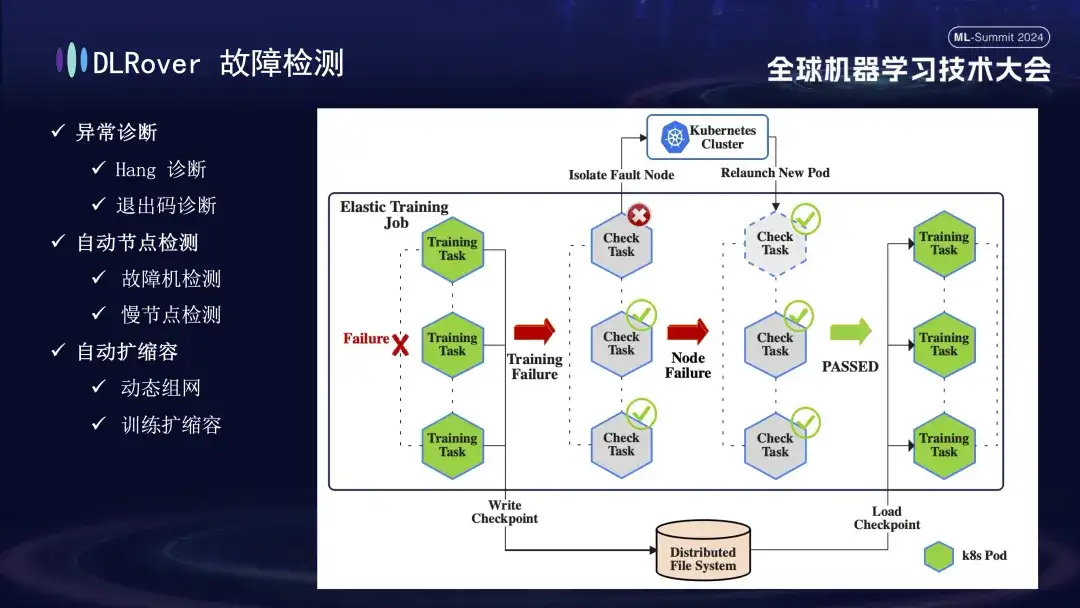
O próximo é o processo de detecção de falhas. Quando ocorre uma falha durante o processo de treinamento e a tarefa é interrompida, o desempenho intuitivo é que o treinamento é suspenso, mas a causa específica e a origem da falha não são diretamente aparentes, porque uma vez que ocorre uma falha, todas as máquinas relacionadas irão parar simultaneamente . Para resolver esse problema, executamos imediatamente o script de detecção em todas as máquinas após a ocorrência da falha. Assim que for detectado que um nó falhou na inspeção, o cluster Kubernetes será notificado imediatamente para remover o nó com falha e reimplantar um novo nó substituto. O novo nó conclui verificações de integridade adicionais com os nós existentes. Depois que tudo estiver correto, a tarefa de treinamento será reiniciada automaticamente. É importante notar que se um nó defeituoso for isolado e causar recursos insuficientes, implementaremos uma estratégia de redução (será apresentada em detalhes posteriormente). Quando a máquina original com defeito retornar ao normal, o sistema executará automaticamente operações de expansão de capacidade para garantir um treinamento eficiente e contínuo.
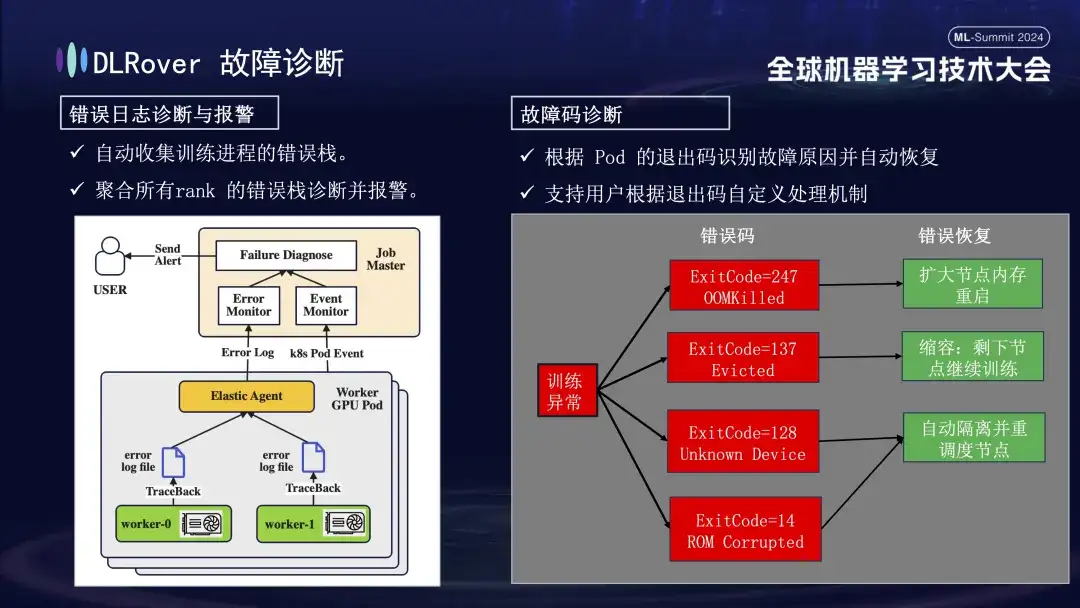
Em seguida vem o processo de diagnóstico de falhas, que utiliza os seguintes métodos abrangentes para obter localização e processamento de falhas rápidos e precisos:
- Primeiro, o Agente coleta informações de erro de cada processo de treinamento e resume essas pilhas de erros no nó mestre. O nó mestre então analisa os dados de erro agregados para identificar a máquina com o problema. Por exemplo, se um registro da máquina mostrar um erro de ECC, a falha da máquina será determinada e eliminada diretamente.
- Além disso, o código de saída do Kubernetes também pode ser usado para auxiliar no diagnóstico. Por exemplo, o código de saída 137 geralmente indica que a plataforma de computação subjacente encerra a máquina devido a um problema detectado, o código de saída 128 significa que o dispositivo não é reconhecido; o driver da GPU pode estar com defeito. Há também um grande número de falhas que não podem ser detectadas por meio de códigos de saída. As mais comuns incluem tempos limites de instabilidade da rede.
- Existem também muitas falhas, como tempos limite causados por flutuações na rede, que não podem ser identificadas apenas pelos códigos de saída. Adotaremos uma estratégia mais geral: independentemente da natureza específica da falha, o objetivo principal é identificar e remover rapidamente o nó defeituoso e, em seguida, notificar o mestre para detectar especificamente onde está o problema.
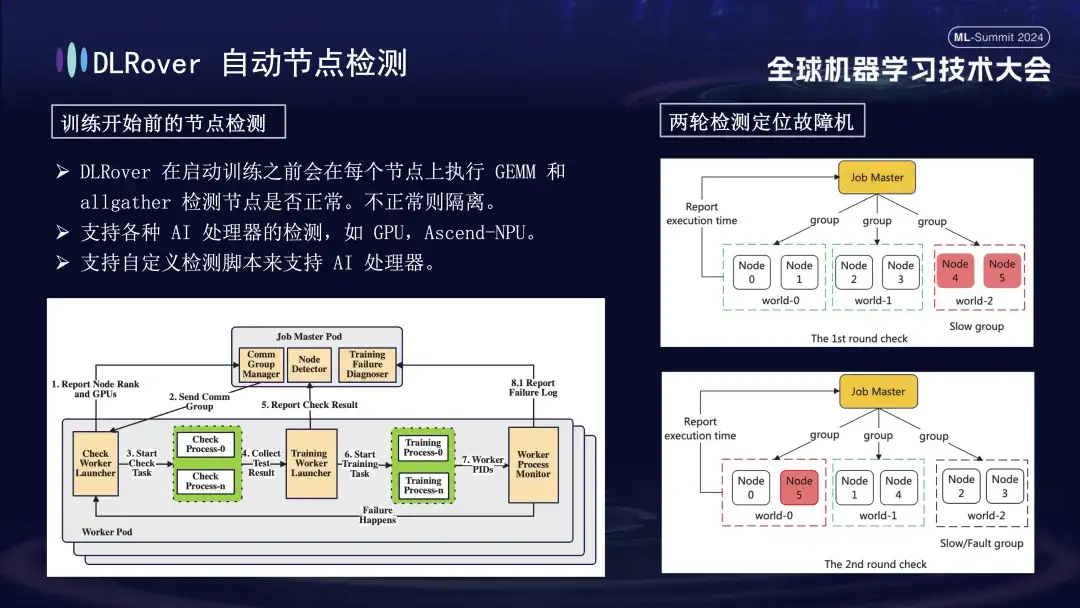
Primeiro, a multiplicação de matrizes é realizada em todos os nós. Posteriormente, os nós são emparelhados e agrupados. Por exemplo, em um Pod com 6 nós, os nós são divididos em três grupos (0,1), (2,3) e (4,5), e a detecção de comunicação AllGather é realizada. realizado. Se houver falha de comunicação entre 4 e 5, mas a comunicação nos demais grupos estiver normal, pode-se concluir que a falha existe no nó 4 ou 5. Em seguida, o nó suspeito de falha é emparelhado novamente com o nó normal conhecido para testes adicionais, por exemplo, combinando 0 e 5 para detecção. Ao comparar os resultados, o nó defeituoso é identificado com precisão. Este processo de inspeção automatizado diagnostica com precisão uma máquina defeituosa em dez minutos.
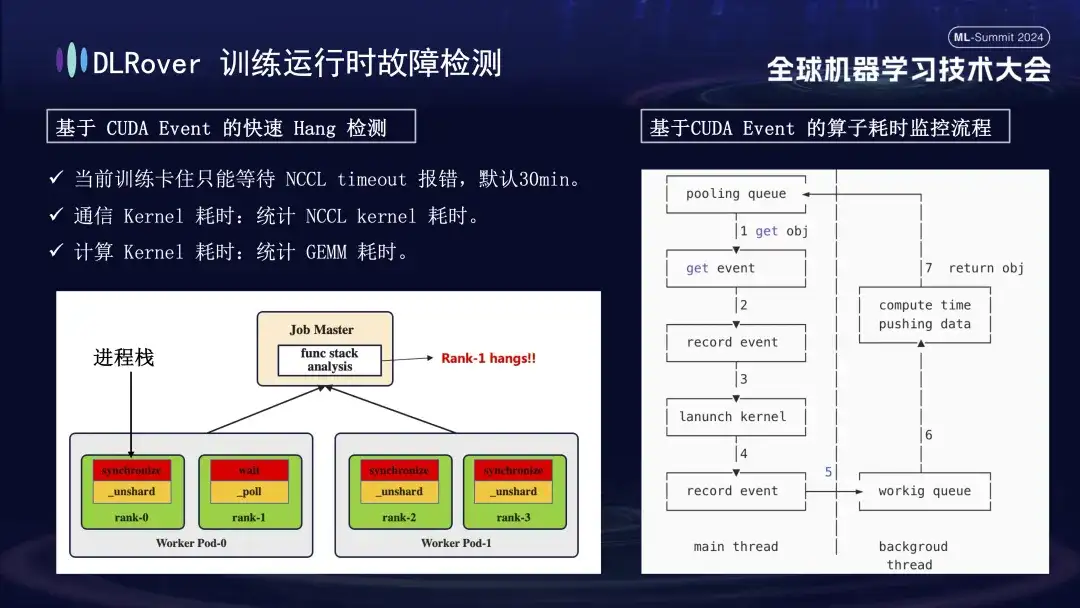
A situação de interrupção do sistema e detecção de falhas já foi discutida antes, mas o problema de identificação de máquina travada precisa ser resolvido. O tempo limite padrão definido pela NCCL é de 30 minutos, o que permite que os dados sejam retransmitidos para reduzir falsos positivos. No entanto, isso pode fazer com que cada cartão espere 30 minutos em vão quando o cartão estiver realmente preso, resultando em enormes perdas cumulativas. Para diagnosticar com precisão o travamento, é recomendado o uso de uma ferramenta de perfil refinada. Quando é detectado que o programa está pausado, por exemplo, não há alteração na pilha do programa em um minuto, as informações da pilha de cada cartão são registradas e as diferenças são comparadas e analisadas. Por exemplo, se for descoberto que 3 de 4 classificações realizam a operação de sincronização e 1 executa a operação de espera, você poderá localizar um problema com o dispositivo. Além disso, sequestramos o núcleo de comunicação e o núcleo de computação chave CUDA, inserimos o monitoramento de eventos antes e depois de sua execução e avaliamos se a operação estava funcionando normalmente calculando o intervalo de eventos. Por exemplo, se uma determinada operação não for concluída dentro dos 30 segundos esperados, ela pode ser considerada travada, e os logs e pilhas de chamadas relevantes serão automaticamente gerados e enviados ao mestre para comparação para localizar rapidamente a máquina defeituosa.
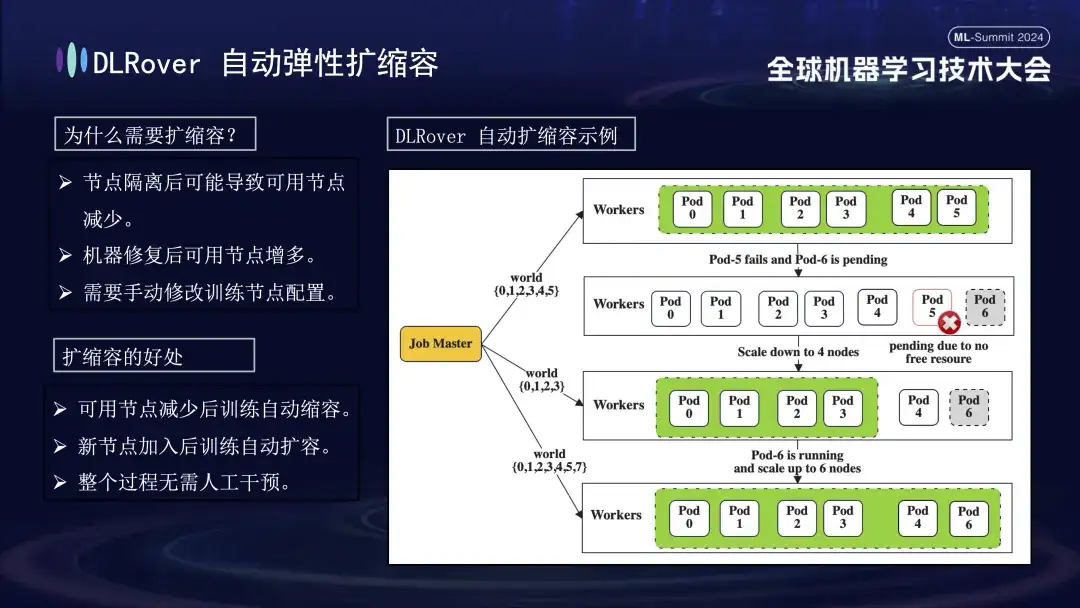
Após a identificação da máquina defeituosa, considerando custo e eficiência, embora houvesse um mecanismo de backup no treinamento anterior, o número era limitado. Neste momento, é particularmente importante introduzir uma estratégia elástica de expansão e contracção. Suponha que o cluster original tenha 100 nós. Depois que um nó falha, os 99 nós restantes podem continuar a tarefa de treinamento após o reparo do nó com falha, o sistema pode retomar automaticamente a operação para 100 nós e esse processo não requer intervenção manual; garantindo um ambiente de treinamento eficiente e estável.
Ponto de verificação de flash DLRover
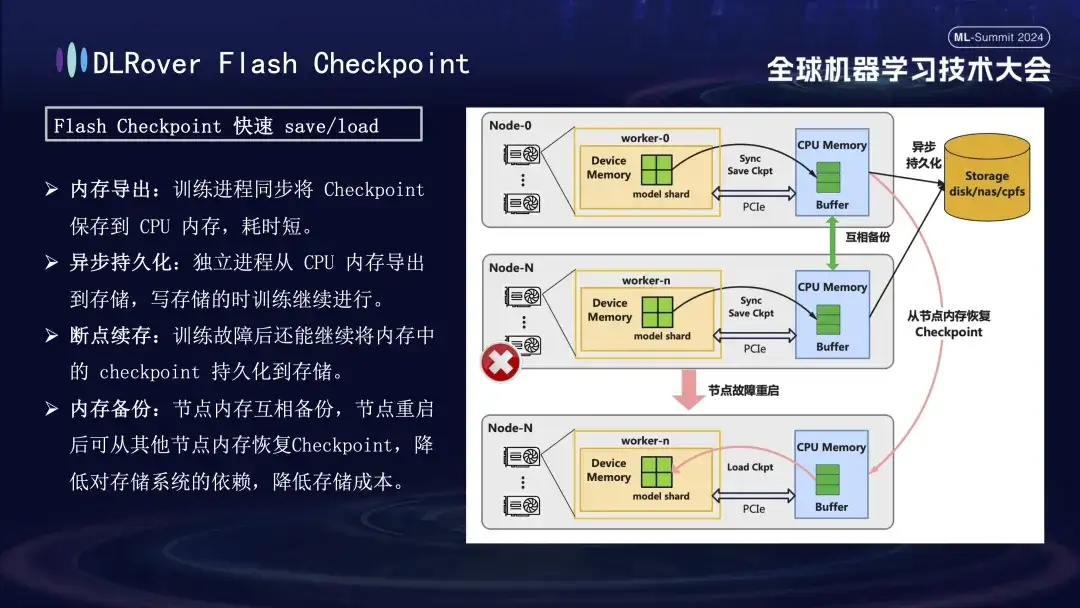
No processo de recuperação de falhas de treinamento, a chave é salvar e restaurar o estado do modelo. O método Checkpoint tradicional geralmente leva a uma baixa eficiência de treinamento devido à longa economia de tempo. Para resolver este problema, DLRover propôs de forma inovadora a solução Flash Checkpoint, que pode exportar o status do modelo da memória da GPU para a memória quase em tempo real durante o processo de treinamento. Ele também é complementado por um mecanismo de backup entre memórias para garantir que mesmo se. um nó falha, ele pode restaurar rapidamente o status de treinamento da memória do nó de backup, reduzindo significativamente o tempo de recuperação de falhas. Para o Megatron-LM comumente usado, o processo de exportação do Checkpoint requer um processo centralizado para coordenação e conclusão, o que não apenas introduz carga adicional de comunicação e consumo de memória, mas também resulta em custos de tempo mais elevados. DLRover adotou uma abordagem inovadora após a otimização, usando uma estratégia de exportação distribuída para que cada nó de computação (classificação) possa salvar e carregar de forma independente seu próprio Checkpoint, evitando assim efetivamente requisitos adicionais de comunicação e memória e melhorando significativamente a eficiência.
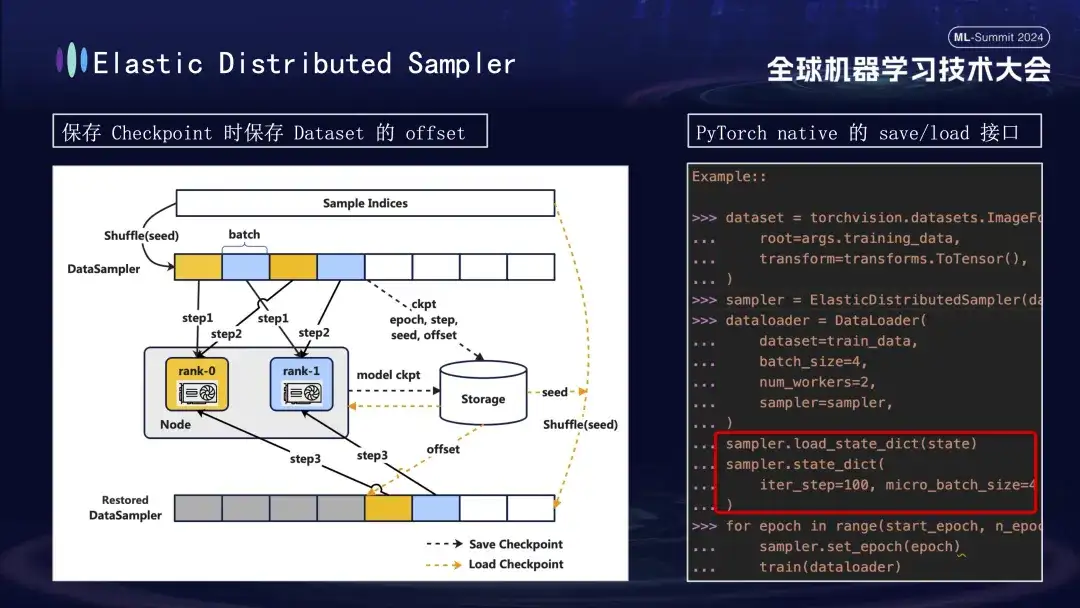
Ao criar o modelo Checkpoint, há outro detalhe que vale a pena prestar atenção. O treinamento do modelo é baseado em dados, assumindo que salvamos o Checkpoint na etapa 1000 do processo de treinamento. Se o treinamento for reiniciado mais tarde sem considerar o progresso dos dados, o consumo de dados diretamente do zero levará a dois problemas: novos dados subsequentes poderão ser perdidos e os dados anteriores poderão ser reutilizados. Para resolver este problema, introduzimos a estratégia Distributed Sampler. Ao salvar o Checkpoint, esta estratégia não apenas registra o status do modelo, mas também salva a posição de deslocamento da leitura dos dados. Desta forma, ao carregar o Checkpoint para retomar o treinamento, o conjunto de dados continuará a ser carregado a partir do ponto de deslocamento salvo anteriormente e então avançará o treinamento, garantindo assim a continuidade e consistência dos dados de treinamento do modelo e evitando erros de dados ou processamento repetido .
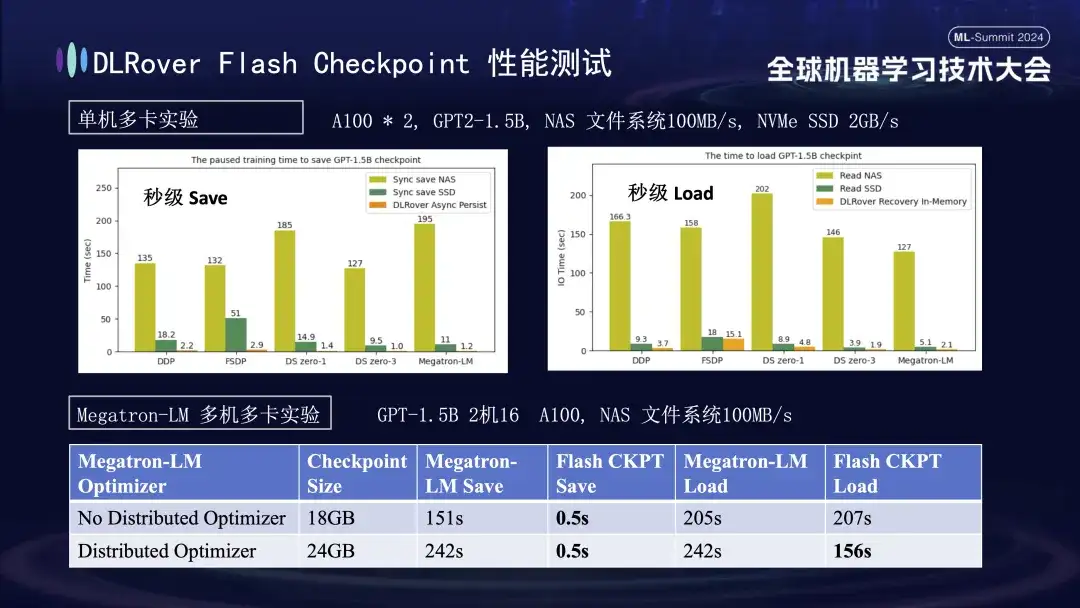
No gráfico acima, mostramos os resultados experimentais em um ambiente multi-GPU (A100) de máquina única, com o objetivo de comparar o impacto de diferentes soluções de armazenamento no tempo de bloqueio causado pelo salvamento de Checkpoint durante o processo de treinamento. Experimentos mostram que o desempenho do sistema de armazenamento afeta diretamente a eficiência: ao usar um método de armazenamento menos eficiente para gravar pontos de verificação diretamente no disco, o treinamento será significativamente bloqueado e o tempo será estendido. Especificamente, para um Checkpoint modelo 1,5B com tamanho de cerca de 20 GB, se o armazenamento NAS for usado, o tempo de gravação será de cerca de 2 a 3 minutos, adotando uma estratégia de otimização, ou seja, o armazenamento temporário e assíncrono dos dados na memória pode reduzir bastante; o tempo. Este processo leva apenas cerca de 1 segundo em média, o que melhora significativamente a continuidade e a eficiência do treinamento.

O recurso Flash Checkpoint do DLRover é amplamente compatível com as principais estruturas de treinamento de grandes modelos, incluindo DDP, FSDP, DeepSpeed, Megatron-LM, transformers.Trainer e Ascend-DDP. Ele possui APIs personalizadas para cada estrutura para garantir flexibilidade de uso extremamente fácil - Usuários. raramente é necessário ajustar o código de treinamento existente, ele funciona imediatamente. Especificamente, os usuários da estrutura DeepSpeed só precisam chamar a interface de salvamento do DLRover ao executar o Checkpoint, enquanto a integração do Megatron-LM é ainda mais simples. Eles só precisam substituir a instrução de importação nativa do Checkpoint pelo método de importação fornecido pelo DLRover. . Pode.
Prática de treinamento distribuído DLRover
Conduzimos uma série de experimentos para cada cenário de falha para avaliar a tolerância a falhas do sistema, a capacidade de lidar com nós lentos e a flexibilidade no aumento e redução de escala. Os experimentos específicos são os seguintes:
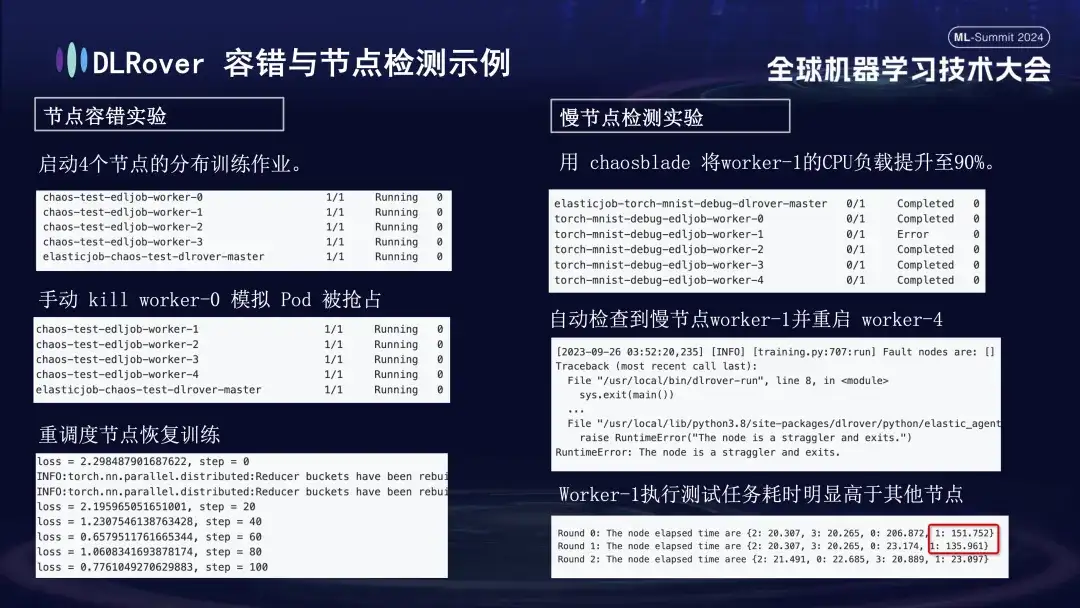
- Experimento de tolerância a falhas de nó: desligue manualmente alguns nós para testar se o cluster pode se recuperar rapidamente;
- Experimento de nó lento: use a ferramenta caosblade para aumentar a carga da CPU do nó para 90% para simular uma situação demorada de nó lento;
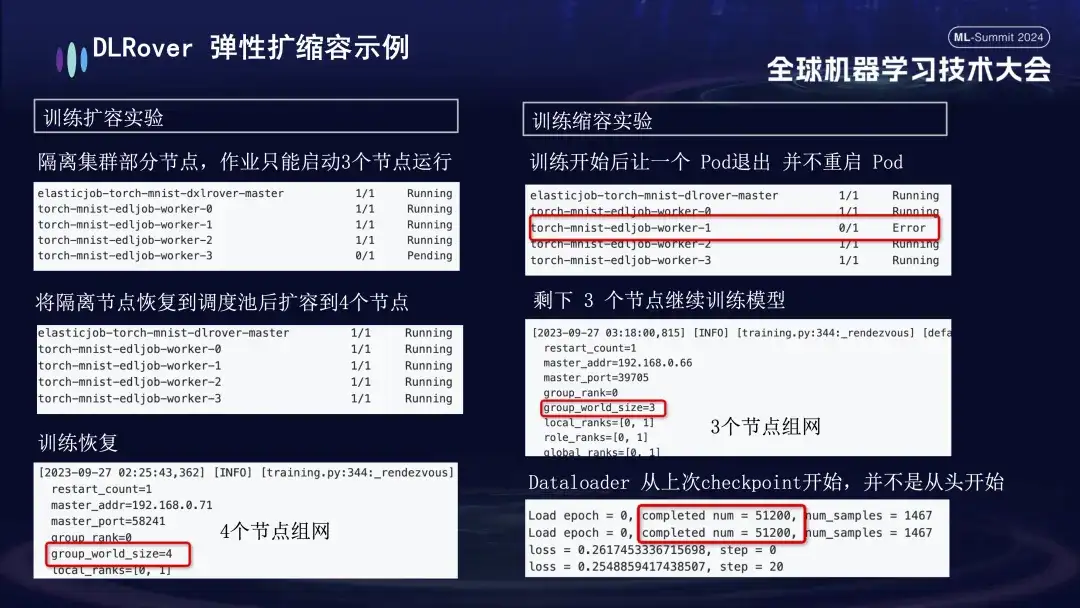
- Experimento de expansão e contração: simula um cenário onde os recursos da máquina são escassos. Por exemplo, se um trabalho estiver configurado com 4 nós, mas apenas 3 forem realmente iniciados, esses 3 nós ainda poderão ser treinados normalmente. Após um período de tempo, simulamos o isolamento de um nó e o número de Pods disponíveis para treinamento foi reduzido para 3. Quando esta máquina retornar à fila de agendamento, o número de Pods disponíveis poderá ser aumentado para 4. Neste momento, o Dataloader continuará treinando a partir do último Checkpoint em vez de recomeçar.
Prática do DLRover em cartões nacionais
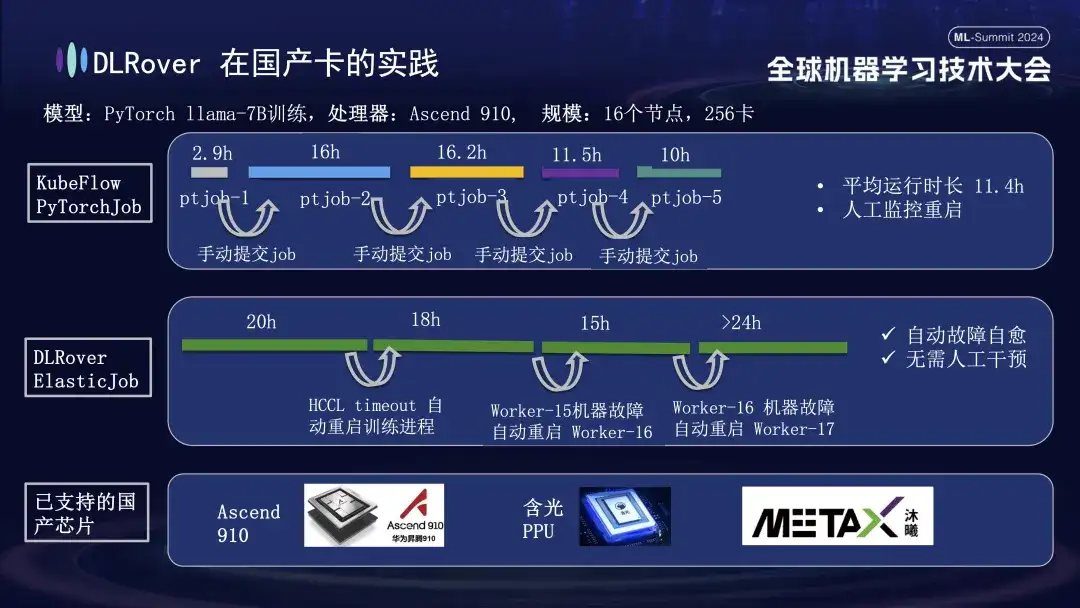
Além de oferecer suporte a GPUs, a autocorreção de falhas DLRover também oferece suporte ao treinamento distribuído de placas aceleradoras domésticas. Por exemplo, quando executamos o modelo LLama-7B na plataforma Huawei Ascend 910, usamos 256 cartões para treinamento em larga escala. A princípio utilizamos o PyTorchJob do KubeFlow, mas essa ferramenta não possuía tolerância a falhas, fazendo com que o processo de treinamento fosse encerrado automaticamente após durar cerca de dez horas. parado. O segundo diagrama descreve todo o processo de treinamento com a autocorreção de falhas de treinamento habilitada. Quando o treinamento progrediu por 20 horas, ocorreu uma falha de tempo limite de comunicação. Nesse momento, o sistema reiniciou automaticamente o processo de treinamento e retomou o treinamento. Cerca de quarenta horas depois, foi encontrada uma falha de hardware da máquina. O sistema isolou rapidamente a máquina defeituosa e reiniciou um pod para continuar o treinamento. Além de oferecer suporte ao Huawei Ascend 910, também somos compatíveis com o Hanguang PPU da Alibaba e cooperamos com a Muxi Technology para usar DLRover para treinar o modelo LLAMA2-65B em sua GPU Qianka desenvolvida de forma independente.
Prática de treinamento de modelo de mais de 1.000 placas e 100 bilhões de DLR
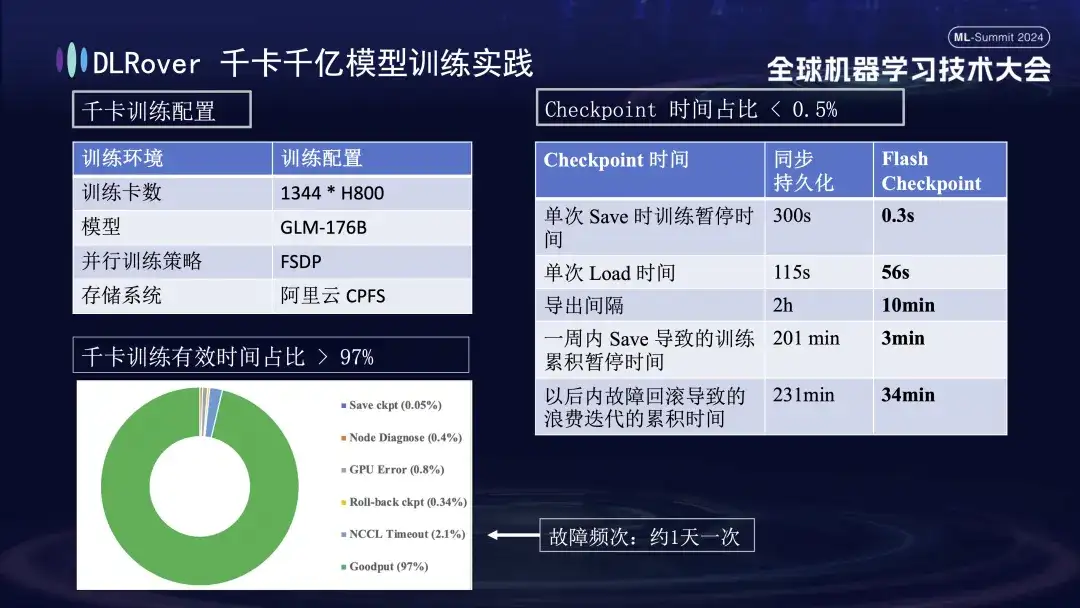
A figura acima mostra o efeito prático da autocorreção de falhas de treinamento DLRover no treinamento de quilo-cartão: mais de 1.000 cartões H800 são usados para executar o treinamento de modelo em larga escala. Quando a frequência de falha é uma vez por dia, após a auto-recuperação da falha de treinamento. função de cura é introduzida, o tempo de treinamento efetivo é responsável por mais de 97%. A tabela de comparação à direita mostra que, ao usar o FSDP de armazenamento de alto desempenho do Alibaba Cloud, um único salvamento ainda leva cerca de cinco minutos, enquanto nossa tecnologia Flash Checkpoint leva apenas 0,3 segundos para ser concluída. Além disso, através da otimização, a eficiência do nó foi melhorada em quase um minuto. Em termos de intervalo de exportação, a operação de exportação era originalmente realizada a cada 2 horas, mas após o lançamento da função Flash Checkpoint, a exportação de alta frequência pode ser realizada a cada 10 minutos. O tempo acumulado gasto em operações de salvamento dentro de uma semana é quase insignificante. Ao mesmo tempo, o tempo de reversão é reduzido cerca de 5 vezes em comparação com antes.
Plano DLRover e construção de comunidade

O DLRover lançou atualmente três versões principais. Espera-se o lançamento da V0.4.0 em junho, que lançará a detecção de falhas em tempo de execução baseada no evento CUDA.
- V0.1.0(2023/07): Tolerância elástica a falhas e expansão e contração automática do TensorFlow PS em k8s/ray;
- V0.2.0 (2023/09): Detecção de nós e tolerância elástica a falhas para treinamento síncrono PyTorch em k8s;
- V0.3.5(2024/03): Flash Checkpoint e detecção de falhas em cartões domésticos;
Em termos de planejamento futuro, o DLRover continuará a otimizar e melhorar as funções do DLRover nos aspectos de agendamento e gerenciamento de nós, compilação e otimização do lynx, estrutura de otimização de treinamento AToch e treinamento de cartão doméstico:
- **Programação e gerenciamento de nós: **Programação com reconhecimento de topologia de comunicação, reduzindo o tráfego de comunicação de switches de nível superior durante a comunicação AllReduce de hardware baseada em anel. Coleta de métricas e previsão de falhas;
- ** Otimização de compilação lynx: ** Otimização de agendamento de gráficos de computação, alcançando comunicação ideal e sobreposição de cálculo, ocultando atraso de comunicação treinamento distribuído automático;
- **Estrutura de otimização de treinamento ATorch: **Otimização de treinamento RLHF; aceleração de inicialização de treinamento distribuído; configuração automática de aceleração de treinamento;
- **Treinamento de cartão doméstico: **Expandir funções como autocorreção de falhas e aceleração de treinamento para cartões domésticos; fornecer melhores práticas para treinamento de cartão doméstico;

O progresso tecnológico começa com a colaboração aberta. Todos são bem-vindos para acompanhar e participar de nossos projetos de código aberto no GitHub.
DLRover:
https://github.com/intelligent-machine-learning/dlrover
Glaco:
https://github.com/intelligent-machine-learning/glake
Nossa conta pública do WeChat "AI Infra" também publicará regularmente artigos técnicos de ponta sobre infraestrutura de IA, com o objetivo de compartilhar os mais recentes resultados de pesquisas e insights técnicos. Ao mesmo tempo, a fim de promover mais intercâmbios e discussões, também criamos um grupo DingTalk. Todos são bem-vindos para participar e fazer perguntas e discutir questões técnicas relacionadas aqui. obrigado a todos!
Recomendações de artigos
