
Autor: Xingji, Changjun, Youyi, Liutao
Introdução ao conceito de memória de trabalho de contêiner WorkingSet
No cenário Kubernetes, as estatísticas de uso em tempo real da memória do contêiner (Pod Memory) são representadas pela memória de trabalho WorkingSet (abreviada como WSS).
O conceito de indicador do WorkingSet é definido pelo cadvisor para cenários de contêiner.
Memória de trabalho WorkingSet também é um indicador para decisões de agendamento do Kubernetes para determinar recursos de memória, incluindo remoção de nós.
Fórmula de cálculo do WorkingSet
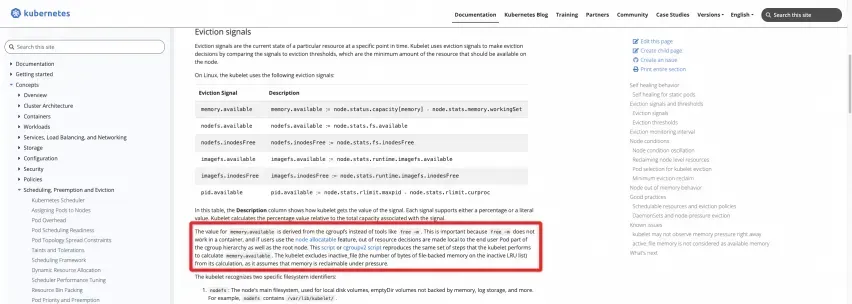
Definição oficial: consulte a documentação do site oficial do K8s
https://kubernetes.io/docs/concepts/scheduling-eviction/node-pression-eviction/#eviction-signals
Os dois scripts a seguir podem ser executados no nó para calcular diretamente os resultados:
Grupo CGV1
https://kubernetes.io/examples/admin/resource/memory-available.sh
#!/bin/bash
#!/usr/bin/env bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to root cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/memory/memory.usage_in_bytes)
memory_total_inactive_file=$(cat /sys/fs/cgroup/memory/memory.stat | grep total_inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
Grupo CGV2
https://kubernetes.io/examples/admin/resource/memory-available-cgroupv2.sh
#!/bin/bash
# This script reproduces what the kubelet does
# to calculate memory.available relative to kubepods cgroup.
# current memory usage
memory_capacity_in_kb=$(cat /proc/meminfo | grep MemTotal | awk '{print $2}')
memory_capacity_in_bytes=$((memory_capacity_in_kb * 1024))
memory_usage_in_bytes=$(cat /sys/fs/cgroup/kubepods.slice/memory.current)
memory_total_inactive_file=$(cat /sys/fs/cgroup/kubepods.slice/memory.stat | grep inactive_file | awk '{print $2}')
memory_working_set=${memory_usage_in_bytes}
if [ "$memory_working_set" -lt "$memory_total_inactive_file" ];
then
memory_working_set=0
else
memory_working_set=$((memory_usage_in_bytes - memory_total_inactive_file))
fi
memory_available_in_bytes=$((memory_capacity_in_bytes - memory_working_set))
memory_available_in_kb=$((memory_available_in_bytes / 1024))
memory_available_in_mb=$((memory_available_in_kb / 1024))
echo "memory.capacity_in_bytes $memory_capacity_in_bytes"
echo "memory.usage_in_bytes $memory_usage_in_bytes"
echo "memory.total_inactive_file $memory_total_inactive_file"
echo "memory.working_set $memory_working_set"
echo "memory.available_in_bytes $memory_available_in_bytes"
echo "memory.available_in_kb $memory_available_in_kb"
echo "memory.available_in_mb $memory_available_in_mb"
Mostre-me o código
Como você pode ver, a memória de trabalho do WorkingSet do nó é o uso de memória do cgroup raiz, menos o cache da parte Inactve(file). Da mesma forma, a memória de trabalho WorkingSet do contêiner no Pod é o uso de memória do cgroup correspondente ao contêiner, menos o cache da parte Inactve(file).
No kubelet do tempo de execução real do Kubernetes, o código real desta parte da lógica do indicador fornecido pelo cadvisor é o seguinte:
No código cadvisor [ 1] , você pode ver claramente a definição de memória de trabalho do WorkingSet:
The amount of working set memory, this includes recently accessed memory,dirty memory, and kernel memory. Working set is <= "usage".
E a implementação de código específico do cálculo de WorkingSet do cadvisor [ 2] :
inactiveFileKeyName := "total_inactive_file"
if cgroups.IsCgroup2UnifiedMode() {
inactiveFileKeyName = "inactive_file"
}
workingSet := ret.Memory.Usage
if v, ok := s.MemoryStats.Stats[inactiveFileKeyName]; ok {
if workingSet < v {
workingSet = 0
} else {
workingSet -= v
}
}
Casos comuns de usuários com problemas de memória de contêiner
No processo em que a equipe ACK fornece suporte de serviço para cenários de contêiner para um grande número de usuários, muitos clientes encontraram mais ou menos problemas de memória de contêiner ao implantar seus aplicativos de negócios em contêineres. Depois de enfrentar um grande número de problemas de clientes, a equipe ACK e a equipe do sistema operacional Alibaba Cloud resumiram os seguintes problemas comuns enfrentados pelos usuários em termos de memória do contêiner:
FAQ 1: Há uma lacuna entre o uso de memória do host e o uso agregado do contêiner por nó. O host é de cerca de 40% e o contêiner é de cerca de 90%.
Provavelmente é porque o pod do contêiner é considerado um WorkingSet, que contém caches como PageCache.
O valor da memória do host não inclui Cache, PageCache, Dirty Memory, etc., enquanto a memória de trabalho inclui esta parte.
Os cenários mais comuns são a conteinerização de aplicativos JAVA, Log4J de aplicativos JAVA e sua implementação muito popular, Logback. O Appender padrão começará a usar NIO de forma muito "simples" e usará mmap para usar Dirty Memory. Isso faz com que o cache de memória aumente, fazendo com que o WorkingSet da memória de trabalho do pod aumente.
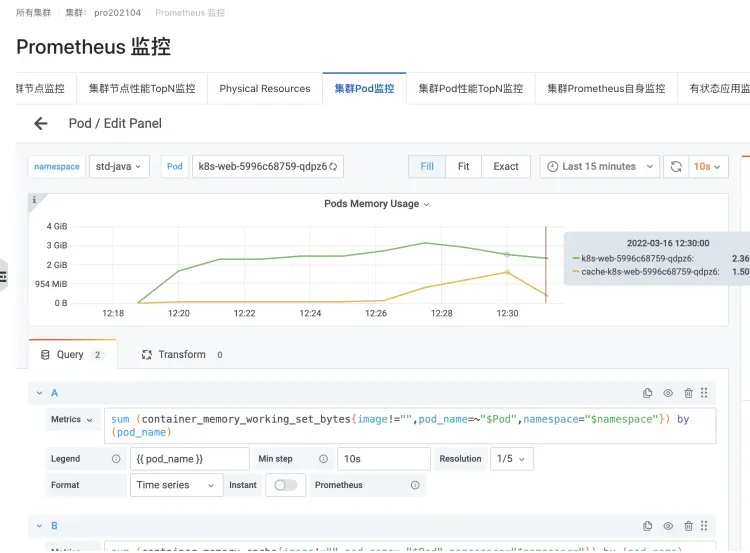
Cenário de registro de logback de um pod de aplicativo JAVA
Instâncias que causam um aumento na memória cache e na memória WorkingSet
FAQ 2: Ao executar o comando top em um pod, o valor obtido é menor que o valor da memória de trabalho (WorkingSet) visualizado pelo kubectl top pod.
Execute o comando top no pod. Devido a problemas como o isolamento do tempo de execução do contêiner, o isolamento do contêiner é realmente quebrado e o valor de monitoramento superior do host é obtido.
Portanto, o que você vê é o valor da memória da máquina host, que não inclui Cache, PageCache, Dirty Memory, etc., enquanto a memória de trabalho inclui esta parte, por isso é semelhante à FAQ 1.
FAQ 3: Problema de buraco negro na memória do pod
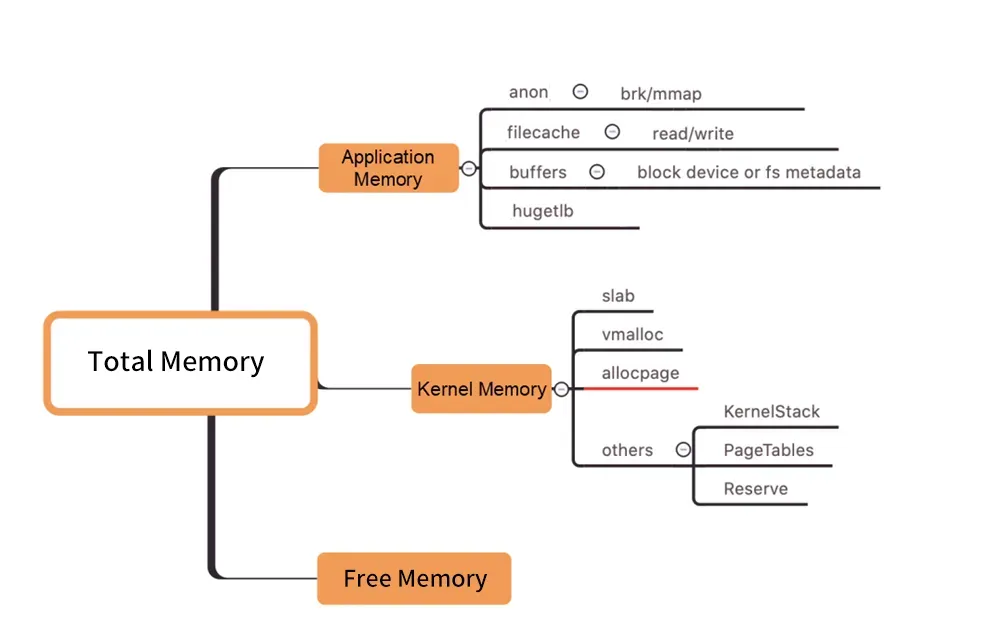
图/Distribuição de memória em nível de kernel
Conforme mostrado na figura acima, a memória de trabalho do Pod WorkingSet não inclui Inativo (anno), e os outros componentes da memória do Pod usados pelos usuários não atendem às expectativas, o que pode eventualmente fazer com que a carga de trabalho do WorkingSet aumente, eventualmente levando ao Node Despejo.
Encontrar a verdadeira causa do aumento da memória de trabalho entre os muitos componentes da memória é tão cego quanto um buraco negro. ("Buraco negro de memória" refere-se a este problema).
Como resolver o problema alto do WorkingSet
Normalmente, os atrasos na reciclagem da memória são acompanhados por um alto uso da memória do conjunto de trabalho. Então, como resolver esse tipo de problema?
Expansão direta
O planejamento de capacidade (expansão direta) é uma solução geral para o problema de recursos elevados.
"Buraco negro de memória" - o que fazer se for causado por custos profundos de memória (como PageCache)
No entanto, se quiser diagnosticar problemas de memória, você precisa primeiro dissecar, obter insights, analisar ou, em termos humanos, ver claramente qual parte da memória está mantida por quem (qual processo ou qual recurso específico, como um arquivo). Em seguida, execute a otimização de convergência direcionada para finalmente resolver o problema.
Etapa um: verifique a memória
Primeiro, como analisar os indicadores de memória de monitoramento do contêiner no nível do kernel do sistema operacional? A equipe ACK cooperou com a equipe do sistema operacional para lançar a função do produto SysOM (System Observer Monitoring) de monitoramento de contêiner na camada kernel do sistema operacional, que atualmente é exclusiva do Alibaba Cloud, visualizando o Pod Memory Monitor no SysOM Container. Dimensão System Monitoring-Pod , você pode obter informações sobre a distribuição detalhada do uso de memória do Pod, conforme mostrado abaixo:
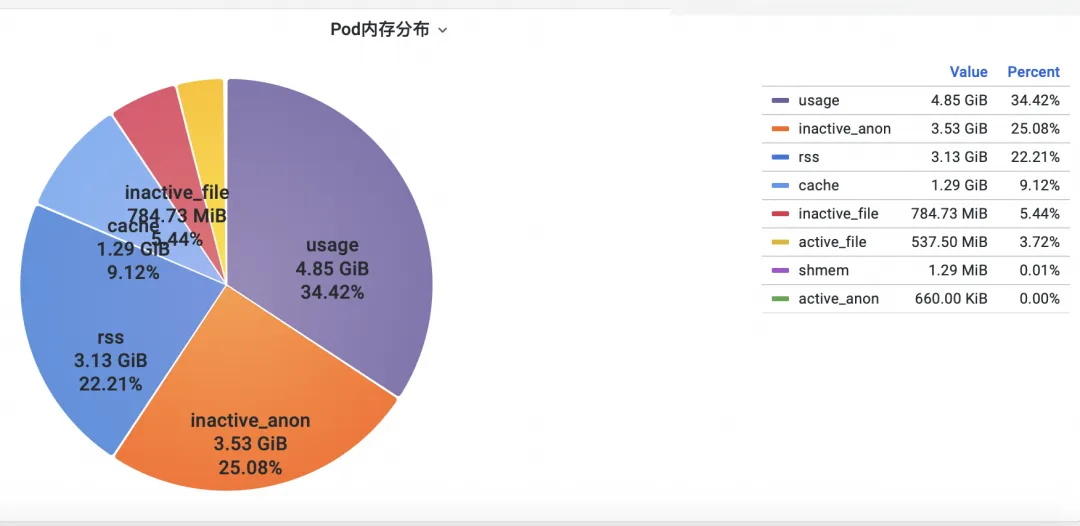
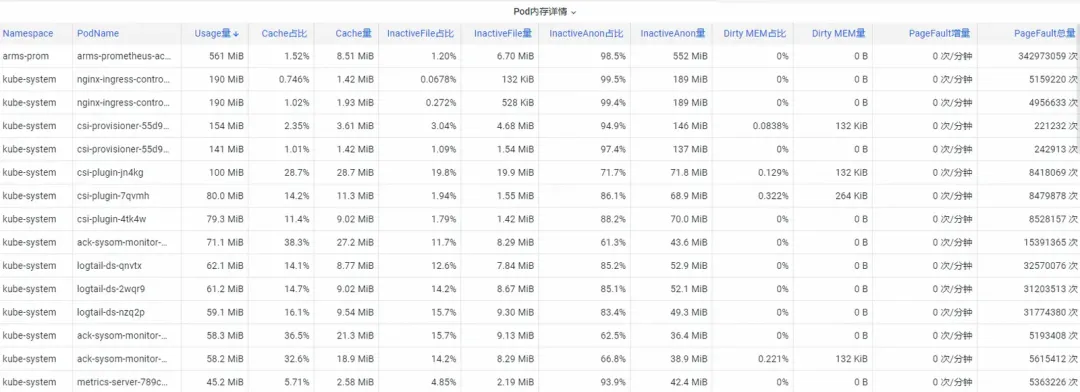
O monitoramento do sistema de contêineres SysOM pode visualizar a composição detalhada da memória de cada pod em um nível granular. Através do monitoramento e exibição de diferentes componentes de memória, como Pod Cache (memória cache), InactiveFile (uso de memória de arquivo inativo), InactiveAnon (uso de memória anônima inativa), Dirty Memory (uso de memória suja do sistema), problemas comuns de buraco negro de memória Pod são descoberto.
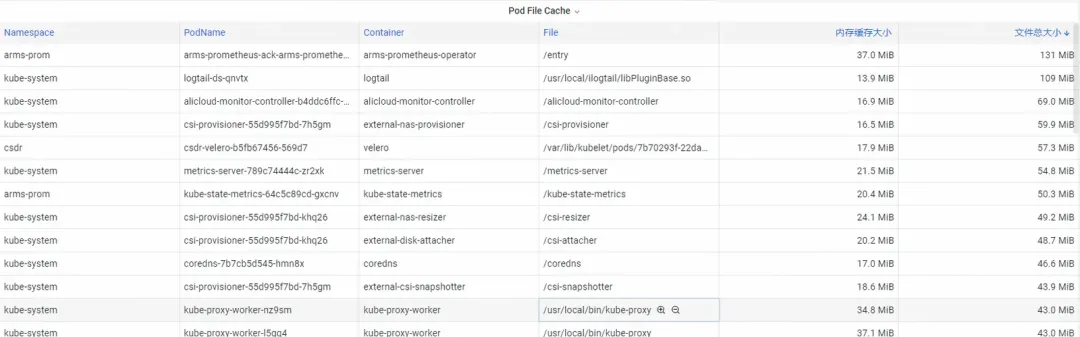
Para o Pod File Cache, você pode monitorar o uso do PageCache dos arquivos atualmente abertos e fechados do Pod ao mesmo tempo (excluir os arquivos correspondentes pode liberar a memória cache correspondente).
Etapa 2: otimizar a memória
Existem muitos consumos de memória profundos que os usuários não conseguem convergir facilmente, mesmo que os vejam claramente. Por exemplo, o PageCache e outras memórias que são recuperadas uniformemente pelo sistema operacional exigem que os usuários façam alterações intrusivas no código, como adicionar flush(. ) ao Appender do Log4J para chamar sync() periodicamente.
https://stackoverflow.com/questions/11829922/logback-file-appender-doesnt-flush-immediately
Isto é muito irrealista.
A equipe de serviço de contêiner ACK lançou a função de agendamento refinado Koordinator QoS .
Implementado no Kubernetes para controlar os parâmetros de memória do sistema operacional:
Quando a colocalização de SLO diferenciada estiver habilitada no cluster, o sistema priorizará a QoS da memória dos pods LS (sensíveis à latência) sensíveis à latência e atrasará o tempo dos pods LS, acionando a reciclagem de memória em toda a máquina.
Na figura abaixo, memory.limit_in_bytes representa o limite superior de uso de memória, memory.high representa o limite atual da memória, memory.wmark_high representa o limite de reciclagem de segundo plano da memória e memory.min representa o limite de bloqueio de uso de memória.
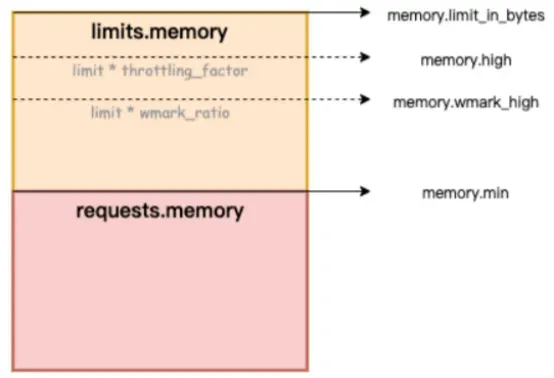
Figure/ack-koordinator fornece recursos de garantia de QoS (Qualidade de Serviço) de memória para contêineres
Como corrigir o problema do buraco negro de memória? O Alibaba Cloud Container Service usa a função de agendamento refinada e depende do projeto de código aberto Koordinator que fornece recursos de garantia de QoS (Qualidade de Serviço) de qualidade de serviço de memória para contêineres, melhorando a imparcialidade da memória. recursos com a premissa de garantir a imparcialidade dos recursos de memória O desempenho da memória do aplicativo em tempo de execução. Este artigo apresenta a função QoS da memória do contêiner. Para obter instruções detalhadas, consulte Container Memory QoS [ 3] .
Os contêineres têm principalmente as duas restrições a seguir ao usar memória:
1) Limite de memória própria: Quando a memória própria do contêiner (incluindo PageCache) se aproxima do limite superior do contêiner, a reciclagem de memória dimensional do contêiner será acionada. Este processo afetará o aplicativo de memória e liberará o desempenho dos aplicativos dentro do contêiner. Se a solicitação de memória não puder ser atendida, o contêiner OOM será acionado.
2) Limite de memória do nó: Quando a memória do contêiner é vendida em excesso (Limite de memória> Solicitação) e toda a máquina tem memória insuficiente, isso acionará a reciclagem global da memória na dimensão do nó. Esse processo tem um grande impacto no desempenho e, em casos extremos. , até faz com que toda a máquina fique anormal. Se a reciclagem for insuficiente, o contêiner será selecionado para OOM Kill.
Para resolver os problemas típicos de memória do contêiner acima, o ack-koordinator fornece os seguintes recursos aprimorados:
1) Nível de água de reciclagem em segundo plano da memória do contêiner: quando o uso da memória do pod está próximo do limite, uma parte da memória será reciclada de forma assíncrona em segundo plano para aliviar o impacto no desempenho causado pela reciclagem direta da memória.
2) Reciclagem/limitação do nível de água do bloqueio de memória do contêiner: Implemente uma reciclagem de memória mais justa entre os pods. Quando os recursos de memória de toda a máquina forem insuficientes, será dada prioridade à reciclagem da memória dos pods com uso excessivo de memória (Uso de memória> Solicitação) para evitar individual. Pods causando falha geral A qualidade dos recursos de memória da máquina se deteriorou.
3) Garantia diferenciada de reciclagem geral de memória: No cenário de sobrevenda de memória BestEffort, a prioridade é dada para garantir a qualidade de execução da memória dos Pods Garantidos/Burstable.
Para obter detalhes sobre os recursos do kernel habilitados pela QoS da memória do contêiner ACK, consulte Visão geral das funções e interface do kernel do Alibaba Cloud Linux [ 4] .
Depois que o problema do buraco negro da memória do contêiner for descoberto por meio da primeira etapa de observação, a função de agendamento fino ACK pode ser combinada com a seleção direcionada de Pods sensíveis à memória para permitir que a função QoS da memória do contêiner conclua o reparo de circuito fechado.
Documentação de referência:
[1] Documento de descrição da função ACK SysOM
[2] Documentação de melhores práticas
[3] Comunidade Dragão Lagarto Chinês
https://mp.weixin.qq.com/s/b5QNHmD_U0DcmUGwVm8Apw
[4] Estação Internacional Inglês
https://www.alibabacloud.com/blog/sysom-container-monitoring-from-the-kernels-perspective_600792
Links Relacionados:
[1] Código cadvisor
[2] Implementação de código específico do cálculo do WorkingSet pelo cadvisor
[3] QoS da memória do contêiner
https://help.aliyun.com/zh/ack/ack-owned-and-ack-dedicated/user-guide/memory-qos-for-containers
[4] Visão geral das funções e interfaces do kernel do Alibaba Cloud Linux
https://help.aliyun.com/zh/ecs/user-guide/overview-23
A equipe de IA da Microsoft na China fez as malas e foi para os Estados Unidos, envolvendo centenas de pessoas. Quanta receita um projeto de código aberto desconhecido pode trazer? A Huawei anunciou oficialmente que a posição da Universidade de Ciência e Tecnologia de Yu Chengdong foi ajustada. abriu oficialmente o acesso à rede externa Os fraudadores usaram o TeamViewer para transferir 3,98 milhões! O que os fornecedores de desktop remoto devem fazer? A primeira biblioteca de visualização front-end e fundador do conhecido projeto de código aberto ECharts do Baidu - um ex-funcionário de uma conhecida empresa de código aberto que "foi para o mar" deu a notícia: Depois de ser desafiado por seus subordinados, o técnico O líder ficou furioso e rude e demitiu a funcionária grávida. A OpenAI considerou permitir que a IA gerasse conteúdo pornográfico. A Microsoft relatou à The Rust Foundation doou 1 milhão de dólares americanos. ?