
Introdução do autor: Zhang Ji, envolvido na otimização de treinamento de Soutui/LLM, com foco na otimização da camada inferior/rede do sistema.
fundo
À medida que o número de parâmetros de modelos de grande escala salta de milhares de milhões para triliões, a rápida expansão da sua escala de formação não só desencadeia um aumento significativo nos custos do cluster, mas também coloca desafios à estabilidade do sistema, especialmente a ocorrência frequente de falhas de máquinas. uma questão que não pode ser ignorada. Para tarefas de treinamento distribuído em larga escala, os recursos de observabilidade tornaram-se a chave para solucionar problemas e otimizar o desempenho. Portanto, o pessoal técnico envolvido na área de treinamento de modelos em grande escala enfrentará inevitavelmente os seguintes desafios:
- Durante o processo de treinamento, o desempenho pode ser instável, flutuar ou até mesmo diminuir devido a vários fatores, como gargalos de rede e computação;
- O treinamento distribuído envolve vários nós trabalhando juntos. Se algum nó falhar (seja um problema de software, hardware, placa de rede ou GPU), todo o processo de treinamento precisa ser suspenso, afetando seriamente a eficiência do treinamento e desperdiçando recursos preciosos da GPU.
No entanto, no processo real de treinamento de modelos grandes, esses problemas são difíceis de solucionar. Os principais motivos são os seguintes:
- O processo de treinamento é uma operação síncrona e é difícil descartar quais máquinas apresentam problemas neste momento por meio de indicadores de desempenho geral. Uma máquina lenta pode diminuir a velocidade geral do treinamento;
- O desempenho lento do treinamento geralmente não é um problema com a lógica/estrutura do treinamento, mas geralmente é causado pelo ambiente. Se não houver dados de monitoramento relacionados ao treinamento, a impressão dos cronogramas na verdade não terá efeito, e os requisitos de armazenamento para armazenar arquivos de cronograma também serão. alto;
- O fluxo de trabalho de análise é complexo. Por exemplo, quando o treinamento é interrompido, é necessário concluir a impressão de todas as pilhas antes do tempo limite da tocha e, em seguida, analisá-las. Ao enfrentar tarefas de grande escala, é difícil concluí-las dentro do tempo limite da tocha.
Em operações de treinamento distribuído em larga escala, os recursos observáveis são particularmente importantes para solucionar problemas e melhorar o desempenho. Na prática de treinamento em larga escala, Ant desenvolveu a biblioteca xpu_timer para atender aos requisitos de observabilidade do treinamento em IA. No futuro, abriremos o temporizador xpu de código-fonte no DLRover. Todos são bem-vindos para cooperar e construir juntos:) A biblioteca xpu_timer é uma ferramenta de criação de perfil que intercepta a biblioteca cublas/cudart e usa cudaEvent para cronometrar as operações de multiplicação/comunicação de matrizes. treinamento, ele também possui funções como análise de linha do tempo, detecção de travamento e análise de pilha suspensa e foi projetado para oferecer suporte a uma variedade de plataformas heterogêneas. Esta ferramenta possui os seguintes recursos:
- Não há intrusão no código, não há perda no desempenho do treinamento e pode residir no processo de treinamento;
- Indiferente aos usuários e irrelevante para a estrutura
- Baixa perda/alta precisão
- A agregação/entrega de indicadores pode ser realizada para facilitar o processamento e análise de dados;
- Alta eficiência de armazenamento de informações
- Interface interativa conveniente: Fornece uma interface externa amigável para facilitar a integração com outros sistemas e direcionar a operação do usuário, acelerando o processo de percepção e tomada de decisão.
Projeto
Primeiro, para resolver o problema de travamentos de treinamento/degradação de desempenho, projetamos um tempo de kernel permanente:
- Na maioria dos cenários, os travamentos de treinamento são causados por operações nccl. Geralmente, você só precisa registrar a multiplicação da matriz e definir a comunicação;
- Para degradação de desempenho em uma única máquina (ECC, MCE), você só precisa registrar a multiplicação da matriz. Ao mesmo tempo, a análise da multiplicação da matriz também pode verificar se a forma da matriz do usuário é científica e maximizar o desempenho do tensorcore. usa cublas diretamente ao implementar a multiplicação de matrizes.
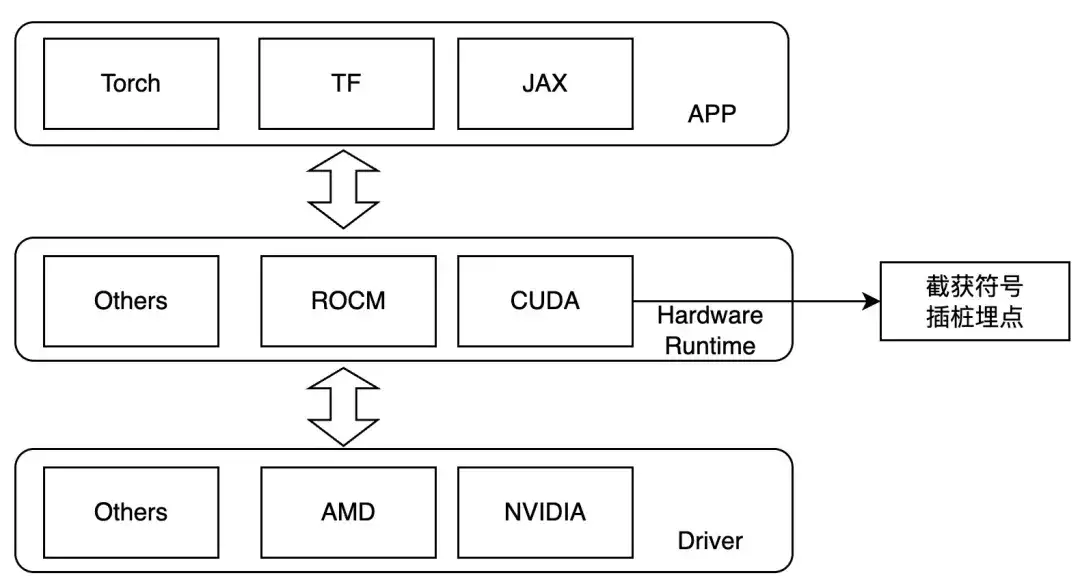
Portanto, projetamos interceptar na camada de inicialização do kernel e definir LD_PRELOAD durante o tempo de execução para rastrear as operações de interesse. Este método só pode ser usado no caso de ligação dinâmica. Atualmente, as estruturas de treinamento convencionais são de ligação dinâmica. Para GPUs NVIDIA, podemos prestar atenção aos seguintes símbolos:
- ibcudart.so
- cudaLaunchKernel
- cudaLaunchKernelExC
- libcublas.so
- cublasGemmEx
- cublasGemmStridedBatchedEx
- cublasLtMatmul
- cublasSgemm
- cublasSgemmStridedBatched
Ao se adaptar a diferentes hardwares, diferentes funções de rastreamento são implementadas por meio de diferentes classes de modelo.
Fluxo de trabalho
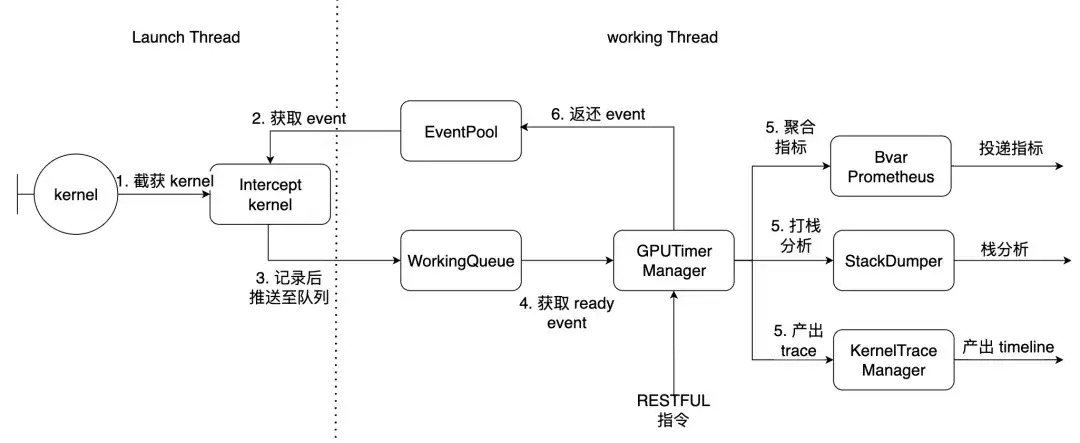
Tomando o PyTorch como exemplo, o Launch Thread é o thread principal da tocha, e o thread de trabalho é o thread de trabalho dentro da biblioteca. Os 7 kernels descritos acima são interceptados aqui.
Como usar e efeitos
Pré-condições
- NCCL é compilado estaticamente para libtorch_cuda.so
- tocha vincula dinamicamente libcudart.so
Se o NCCL estiver vinculado dinamicamente, compensações de funções personalizadas poderão ser fornecidas e resolvidas dinamicamente em tempo de execução. Depois de instalar o pacote Python, você terá as seguintes ferramentas de linha de comando
| xpu_timer_gen_syms | Deslocamento de função injetado dinamicamente na biblioteca para gerar e analisar nccl dinamicamente |
| xpu_timer_gen_trace_timeline | Usado para gerar rastreamento de cromo |
| xpu_timer_launch | Usado para montar pacotes de gancho |
| xpu_timer_stacktrace_viewer | Usado para gerar uma pilha visual após o tempo limite |
| xpu_timer_print_env | Imprima o endereço libevent.so e imprima as informações de compilação |
| xpu_timer_dump_timeline | Usado para acionar o despejo da linha do tempo |
LD_PRELOAD 用法:XPU_TIMER_XXX=xxx LD_PRELOAD=`path to libevent_hook.so` python xxx
Linha do tempo de captura dinâmica em tempo real
Cada classificação possui um serviço de porta, que precisa enviar comandos para todas as classificações ao mesmo tempo. A porta de inicialização é brpc. A porta de serviço possui um tamanho de dados de 32B para cada rastreamento de classificação. O tamanho do json da linha do tempo gerado é 150K * tamanho mundial, muito menor do que o uso básico
usage: xpu_timer_dump_timeline [-h]
--host HOST 要 dump 的 host
--rank RANK 对应 host 的 rank
[--port PORT] dump 的端口,默认 18888,如果一个 node 用了所有的卡,这个不需要修改
[--dump-path DUMP_PATH] 需要 dump 的地址,写绝对路径,长度不要超过 1000
[--dump-count DUMP_COUNT] 需要 dump 的 trace 个数
[--delay DELAY] 启动这个命令后多少秒再开始 dump
[--dry-run] 打印参数
Situação de máquina única
xpu_timer_dump_timeline \
--host 127.0.0.1 \
--rank "" \
--delay 3 \
--dump-path /root/lizhi-test \
--dump-count 4000
多机情况# 如下图所示,如果你的作业有 master/worker 混合情况(master 也是参与训练的)
# 可以写 --host xxx-master --rank 0
# 如果还不确定,使用 --dry-run
xpu_timer_dump_timeline \
--host worker \
--rank 0-3 \
--delay 3 --dump-path /nas/xxx --dump-count 4000
xpu_timer_dump_timeline \
--host worker --rank 1-3 \
--host master --rank 0 --dry-run
dumping to /root/timeline, with count 1000
dump host ['worker-1:18888', 'worker-2:18888', 'worker-3:18888', 'master-0:18888']
other data {'dump_path': '/root/timeline', 'dump_time': 1715304873, 'dump_count': 1000, 'reset': False}
Os arquivos a seguir serão adicionados à pasta da linha do tempo correspondente posteriormente.

Em seguida, execute xpu_timer_gen_trace_timeline neste arquivo
xpu_timer_gen_trace_timeline Serão gerados 3 arquivos:
- arquivo auxiliar merged_tracing_kernel_stack, arquivo original do gráfico em degradê
- linha do tempo mesclada trace.json
- tracing_kernel_stack.svg, pilha de chamadas para multiplicação de matrizes/nccl
Um caso de análise de 32 cartas de receitas de lhama
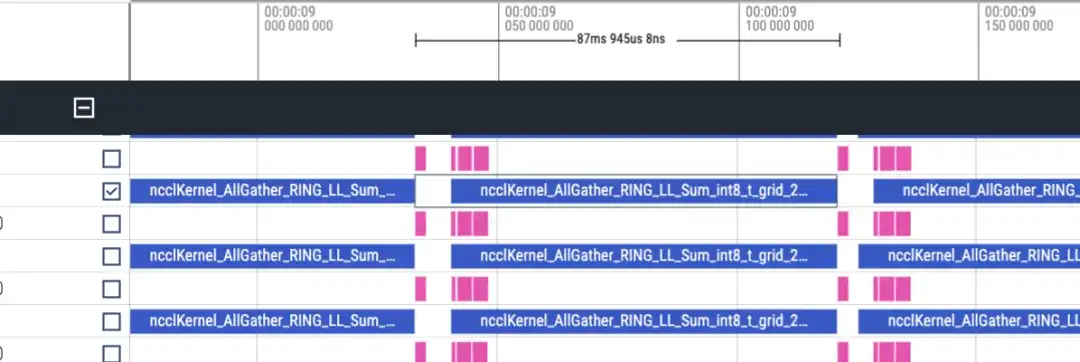
A linha do tempo é aproximadamente a seguinte. Cada classificação exibirá duas linhas de matmul/nccl e todas as classificações serão exibidas. Observe que não há informações de avanço/reverso aqui. Pode ser avaliado aproximadamente pela duração do reverso ser duas vezes maior que o avanço.

Linha do tempo avançada, cerca de 87ms
Linha do tempo reversa aproximadamente 173ms
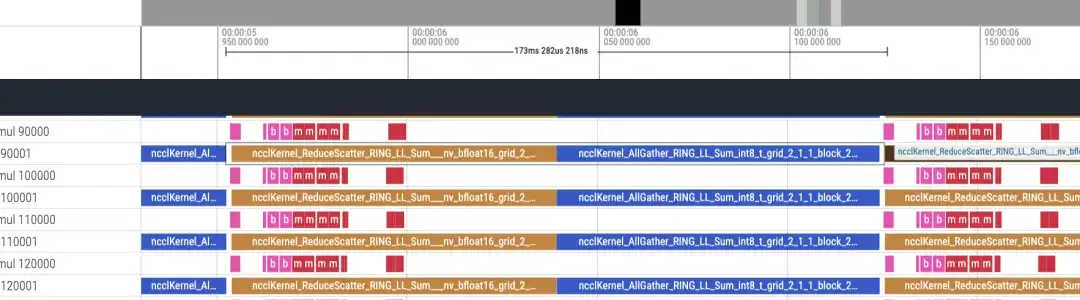
Existem 48 camadas no total, e o consumo total de tempo é (173+87)*48 = 12480ms. Incluindo lmhead, incorporação e outras operações, leva cerca de 13s. E através da linha do tempo, verifica-se que o tempo de comunicação é muito maior que o tempo de cálculo, podendo-se constatar que o gargalo é causado pela comunicação.
análise de pilha suspensa
Depois de instalar o pacote com pip, você pode analisá-lo por meio da ferramenta de linha de comando. Por padrão, o kernel imprimirá informações específicas da pilha após mais de 300 segundos. Arraste a imagem svg para o chrome para visualizá-la. imprima a pilha correspondente, imprima os resultados em stderr do processo de treinamento. Se você instalar o gdb através do conda, você usará a API python do gdb para obter a pilha. Você pode obter o nome lwp O gdb8.2 instalado padrão às vezes não pode ser obtido. gdb. A seguir está uma pilha de 2 placas para simular o tempo limite do NCCL:

A seguir está um exemplo de treinamento llama7B sft de 8 cartas em uma única máquina
Através das ferramentas fornecidas pelo pacote python, o gráfico da pilha de chama da pilha de agregação pode ser gerado. Aqui você pode ver a pilha sem classificação 1 porque o travamento é simulado matando -STOP classificação1 durante o treinamento de 8 cartas, então a classificação1 está no. estado de parada.
xpu_timer_stacktrace_viewer --path /path/to/stack
运行后会在 path 中生成两个 svg,分别为 cpp_stack.svg, py_stack.svg
Ao mesclar pilhas, acreditamos que o mesmo callpath pode ser mesclado, ou seja, o stacktrace é completamente consistente, então a maioria dos locais presos no thread principal serão os mesmos, mas se houver alguns loops e threads ativos, o impresso o topo da pilha pode ser inconsistente, mas a mesma pilha será executada na parte inferior. Por exemplo, os threads na pilha python ficarão presos em [email protected]. Além disso, o número de amostras no gráfico em chamas não tem significado. Quando um travamento é detectado, todas as classificações geram arquivos stacktrace correspondentes (a classificação1 é suspensa, portanto não há nenhum) e cada arquivo contém a pilha completa de python/c++.
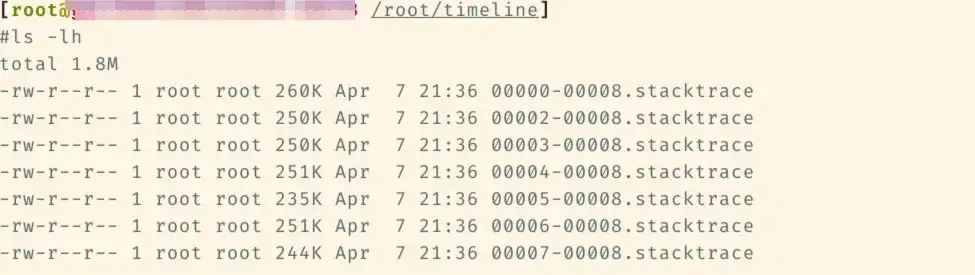
A pilha mesclada é a seguinte. Cores diferentes são usadas para distinguir as categorias da pilha. Na pilha python, pode haver apenas ciano e verde:
- Ciano é CPython/Python
- Vermelho é C/outro sistema relacionado
- Verde é Tocha/NCCL
- Amarelo é C++

A pilha Python é a seguinte, o diagrama de blocos azul é a pilha específica e a regra de nomenclatura é: func@source_path@stuck_rank|leak_rank
- func é o nome da função atual. Se o gdb não puder obtê-lo, ele será exibido?
- source_path, o endereço so/source deste símbolo no processo
- stick_rank representa quais pilhas de classificação entram aqui. Os números de classificação consecutivos serão dobrados no início e no fim, como classificação 0,1,2,3 -> 0-3.
- leak_rank representa quais pilhas não foram inseridas aqui, e o número da classificação aqui também será dobrado
Portanto, o significado da imagem é que o rank0, o rank2-7 estão todos presos na sincronização e o rank 1 não entra, então pode-se analisar que há um problema com o rank1 (na verdade suspenso). Esta informação só será adicionada no topo da pilha

Da mesma forma, você pode ver a pilha de cpp e pode ver que o thread principal está preso na sincronização e, finalmente, preso no tempo de aquisição em cuda.so. Também é apenas rank1. pilha onde __libc_start_main está localizado representa o ponto de entrada do processo.
Geralmente, pode-se considerar que há apenas um link mais profundo na pilha. Se ocorrer uma bifurcação, isso prova que diferentes classificações estão presas em links diferentes.
Análise da pilha de chamadas do kernel
Ao contrário da linha do tempo da tocha, a linha do tempo não possui uma pilha de chamadas. Ao gerar a linha do tempo, o nome do arquivo da pilha correspondente é tracing_kernel_stack.svg.
- Verde é operação NCCL
- O vermelho é a operação matmul
- O ciano é a pilha Python

Exibição do mercado Grafana
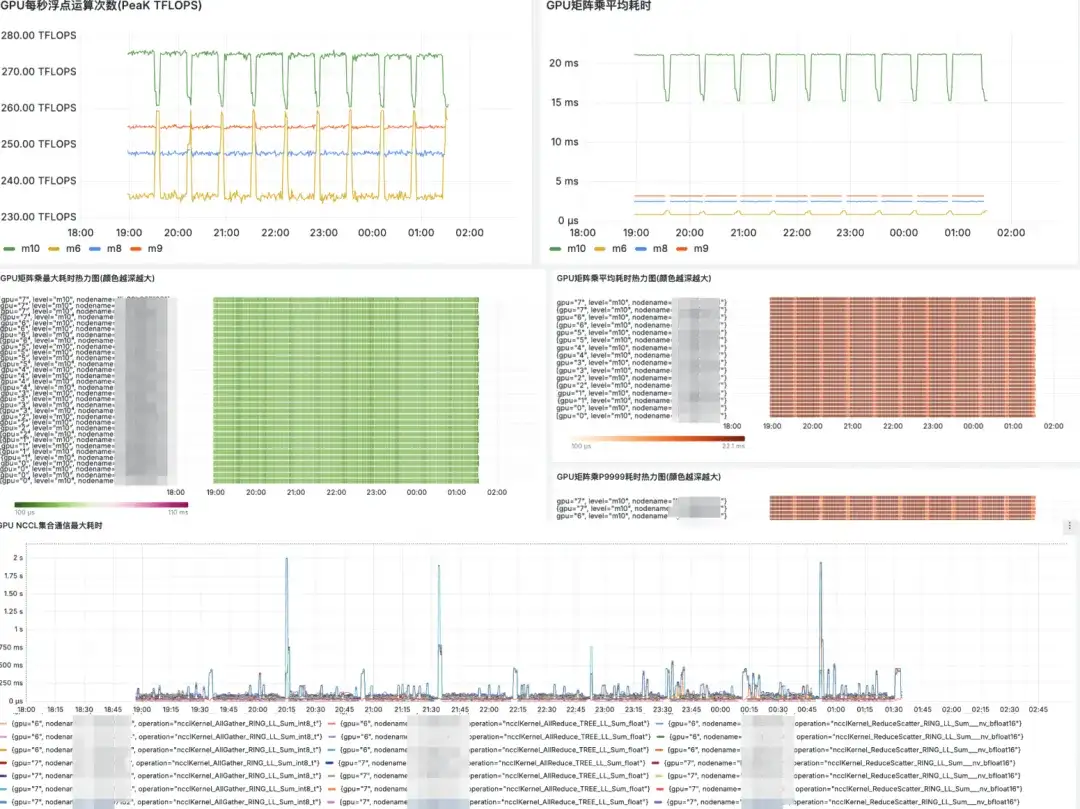
Plano futuro
- Adicione rastreamento mais refinado, como NCCL/eBPF, para analisar e diagnosticar com mais precisão a causa raiz dos problemas de travamento durante o treinamento;
- Suportará mais plataformas de hardware, incluindo várias placas gráficas nacionais.
Sobre DLRover
DLRover (Distributed Deep Learning System) é uma comunidade de código aberto mantida pela equipe Ant Group AI Infra. É um sistema inteligente de aprendizado profundo distribuído baseado em tecnologia nativa da nuvem. DLRover permite que os desenvolvedores se concentrem no design da arquitetura do modelo sem ter que lidar com detalhes de engenharia, como aceleração de hardware e operação distribuída. Ele também desenvolve algoritmos relacionados ao treinamento de aprendizado profundo para tornar o treinamento mais eficiente e inteligente, como otimizadores. Atualmente, o DLRover suporta o uso de K8s e Ray para operações automatizadas e manutenção de tarefas de treinamento de aprendizagem profunda. Para mais tecnologia AI Infra, preste atenção ao projeto DLRover.
Junte-se ao grupo de troca de tecnologia DLRover DingTalk: 31525020959
Estrela DLRover:
https://github.com/intelligent- machine -learning/dlrover
Recomendações de artigos
