
Olá a todos, sou Wang Chunxiao, do Centro Provincial de Computação de Shandong (Centro Nacional de Supercomputação de Jinan). Participo de projetos de supercomputação na Internet desde 2022. Sou o principal responsável pela pesquisa e desenvolvimento de uma plataforma de armazenamento unificada para redes de computação. também fiz alguns trabalhos em bases de armazenamento. Depois de muita pesquisa, finalmente escolhi a plataforma Alluxio. Depois de mais de um ano de muito trabalho, estou muito grato ao Alluxio pelo apoio e ajuda.
A seguir, vamos nos concentrar no tema da supercomputação da Internet e compartilhar com vocês três aspectos:
(1) Problemas e desafios existentes na construção da Internet supercomputadora;
(2) Pesquisa sobre tecnologias-chave de plataforma de armazenamento unificado de supercomputação na Internet;
(3) Aplicação e desenvolvimento futuro da Internet de supercomputação
Assista ao compartilhamento completo
1. Problemas e desafios na construção da Internet supercomputadora

Em primeiro lugar, deixe-me apresentar brevemente o National Supercomputing Jinan Center. Foi fundado em 2011 e é o berço do servidor doméstico "Sunway Blu-ray" do meu país. Claro, a escala do Sunway Blu-ray agora aumentou de petaflops. para exaescala. A partir de 2019, começamos a desenvolver e construir uma plataforma universal baseada na plataforma nacional. Ou seja, a Plataforma de Supercomputação Sunward, cuja CPU, GPU e largura de banda de armazenamento atingiram uma escala considerável, desempenha um importante papel de apoio em muitas indústrias na província de Shandong.
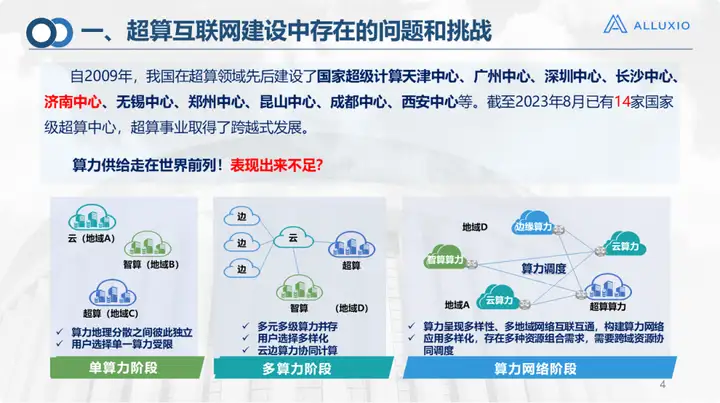
Desde 2009, nosso país estabeleceu sucessivamente muitos centros de supercomputação. Até agosto de 2023, nosso país terá 14 centros de supercomputação de nível nacional, mais de 30 centros de computação inteligentes e mais de 500 grandes centros de dados em nuvem. Com esse tamanho, também está na vanguarda do fornecimento de energia computacional global.
Hoje em dia, com o aumento da demanda por modelos grandes e muitas outras coisas, algumas deficiências no poder computacional também foram expostas. Isso é inseparável da complexidade do desenvolvimento de nossos aplicativos: os aplicativos de hoje não podem mais ser resolvidos apenas com o poder da computação. No passado, você poderia apenas pegar alguns dados e um modelo e executá-los em um determinado recurso. Agora é o estágio do poder de computação múltipla. Em alguns cenários de aplicações de escala relativamente grande, há demandas quanto à escala e ao tipo de poder de computação e armazenamento. Por exemplo, a computação convergente, como a computação em nuvem, a computação de alto desempenho e a computação de IA, bem como o cenário de computação no leste e no oeste proposto pelo nosso país, é realmente difícil resolver o problema se simplesmente aumentar o poder de computação ou armazenamento em uma determinada área. É claro que existem diferenças regionais na procura de poder computacional e na distribuição de recursos do meu país. Esta é também a intenção original da proposta do meu país de construir uma Internet de supercomputação.

Em abril de 2023, o Ministério da Ciência e Tecnologia lançou o trabalho de construção de uma Internet nacional de supercomputação para construir uma rede integrada de energia de supercomputação e plataforma de serviços. O Centro Nacional de Supercomputação de Jinan também é uma das unidades de supercomputação da Internet. O que está fazendo atualmente é conduzir gerenciamento unificado de recursos, controle e coordenação de redes e armazenamento de energia de computação de área ampla para obter o layout ideal de recursos.
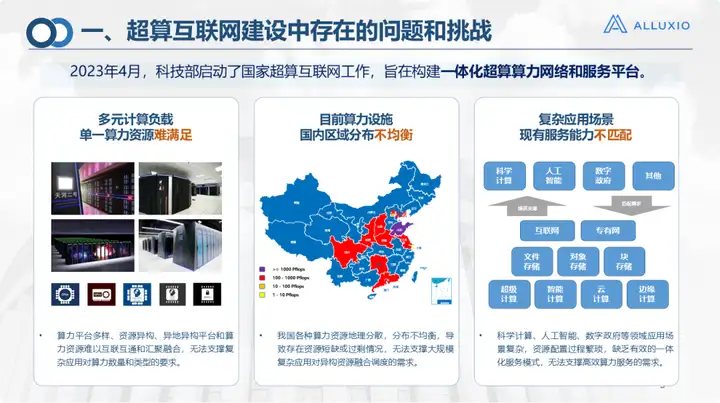
O Centro Nacional de Supercomputação em Jinan planeja e constrói uma Internet de supercomputação desde 2016 e realiza trabalhos em todos os níveis. Claro, também existem muitos problemas encontrados na construção e aplicação de redes de potência computacional.
1. A primeira é a questão das plataformas diversificadas de poder computacional, incluindo o surgimento interminável de várias plataformas em nuvem, plataformas de IA e plataformas de armazenamento;
2. O segundo é o problema dos recursos heterogêneos, incluindo padrões de chips de grupos domésticos, que são muito diferentes, e os sistemas de armazenamento também possuem várias interfaces, que são muito dispersas, possuem estruturas complexas e possuem muitos protocolos, o que torna difícil alcançar interconexão e interoperabilidade, é necessário construir uma plataforma unificada;
3. O terceiro é a distribuição desigual do poder computacional, que é um problema comum em nosso país. Tomando como exemplo a província de Shandong, a computação está em Jinan e o armazenamento está em Zibo. Se houver um gargalo na rede intermediária, será basicamente difícil conseguir montagem, chamada ou mesmo transmissão remota.
Existem também alguns cenários de aplicação complexos, como os campos de sensoriamento remoto meteorológico marinho, cujos procedimentos operacionais são relativamente complexos. Os dados podem ser armazenados em um local e precisam ser transferidos para outro local para pré-processamento de dados, simulação, treinamento de modelo e. outras operações, mas essas operações podem ter que ser realizadas em plataformas diferentes, ou mesmo em regiões diferentes. Sem uma plataforma de serviços integrada, é difícil trabalhar e ser proficiente no uso de todas estas plataformas. problemas e desafios É também isso que precisamos resolver ao construir o núcleo da supercomputação da Internet.
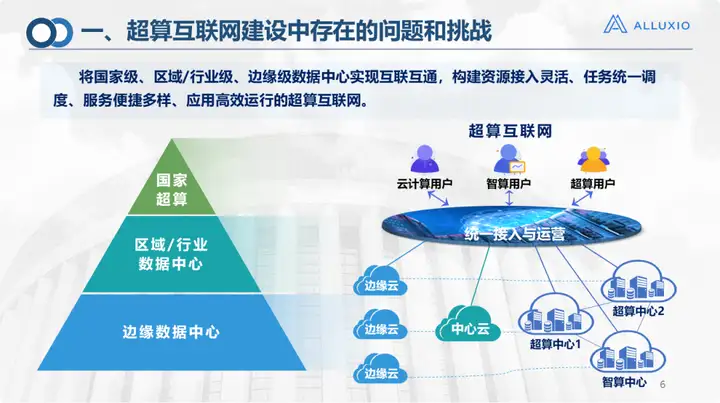
Esta é a estrutura da Internet de supercomputação – permitindo que data centers nacionais, empresariais/regionais e de ponta alcancem interconexão e classificação hierárquica. A interoperabilidade visa permitir acesso e operação relativamente fáceis e unificados de poder de computação, armazenamento e redes. Ele pode fluir como água e eletricidade e ser fornecido aos níveis superiores para uso por vários usuários. Alguns são até usuários mistos: por exemplo, um algoritmo deve usar alto desempenho e IA. Este também é o nosso objetivo de construção.
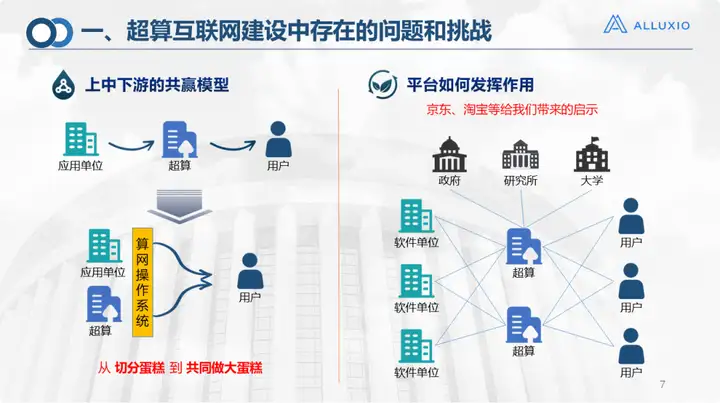
Essa foi a cadeia industrial para o desenvolvimento da Internet de supercomputação naquela época. No passado, os usuários usavam poder de computação, armazenamento e software por meio de supercomputação ou data centers, e havia uma unidade de aplicativos de terceiros. Agora adicionamos uma camada intermediária, com três camadas de definições superior, intermediária e downstream: as unidades de aplicação e os supercomputadores na primeira camada servem como provedores de recursos paralelos, e o sistema operacional da rede de supercomputação serve como camada intermediária para fornecer poder de computação correspondente e rede de armazenamento. O modelo operacional pode referir-se a plataformas como JD.com e Taobao, que podem ser usadas como plataforma intermediária. Assim como JD.com e Taobao, eles vendem mercadorias, mas o que operamos é um recurso, que é um modelo que vai desde o corte do bolo até a confecção do bolo juntos.
2. Pesquisa sobre tecnologias-chave de plataforma de armazenamento unificado de supercomputação na Internet
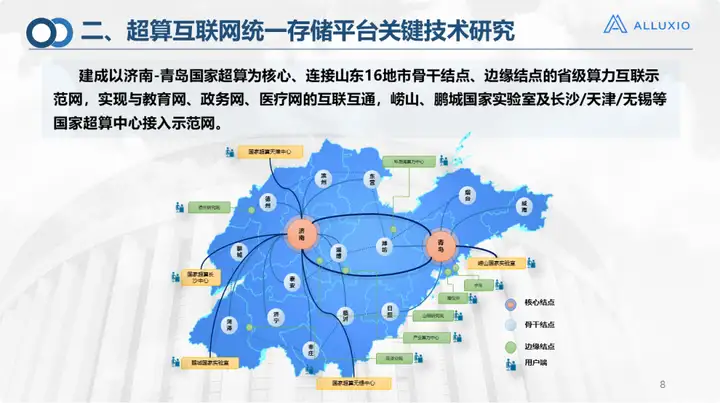
Esta é a situação atual da construção da Internet de supercomputação. Ela foi testada pela primeira vez em Shandong, cobrindo 16 cidades na província de Shandong, incluindo os dois nós principais de Jinan e Qingdao. Agora, Jinan e Qingdao operam por meio de interconexão de alta velocidade, e as demais cidades. são Use linhas dedicadas. Existem também 30 nós de borda que podem ser conectados usando Sdone ou Internet. Ao mesmo tempo, também conectamos 28 clusters de computação e 45 sistemas de armazenamento de 7 tipos. A plataforma unificada do sistema de armazenamento é construída com Alluxio. Esta é a escala da nossa primeira versão do sistema operacional de rede de supercomputação. Atualmente, a camada superior suporta três tipos de serviços: computação em nuvem, HPC e IA. Fornece recursos principalmente em três aspectos:
1. Recursos computacionais;
2. Recursos de armazenamento;
3. Recursos de rede.
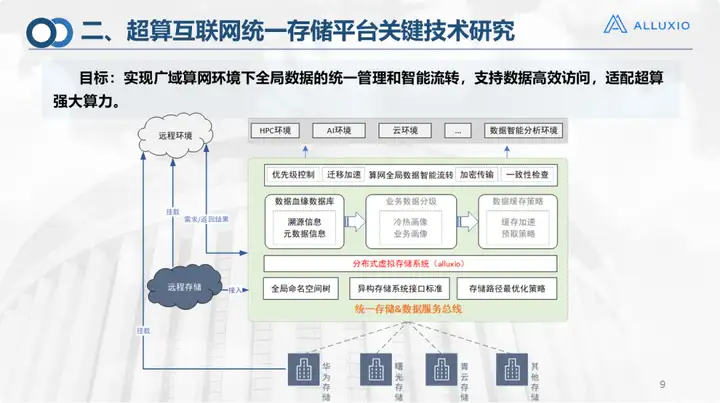
Como sou o principal responsável pela plataforma de armazenamento unificado, vou me concentrar na introdução da plataforma de armazenamento unificado. Este é o diagrama da estrutura de design naquele momento. Na verdade, não importa se o objetivo da plataforma de armazenamento unificado. é qualquer tipo de armazenamento na parte inferior ou na nuvem. Todos nós precisamos gerenciar o armazenamento. A camada que trata do sistema de armazenamento usa o Alluxio como base de armazenamento. Com base nisso, também fizemos alguns trabalhos de otimização, incluindo otimização de caminho, estratégia de migração de dados, transmissão criptografada, verificação de consistência, etc. Alguns deles ainda estão em processo de verificação e não foram adicionados à primeira versão. plano geral.
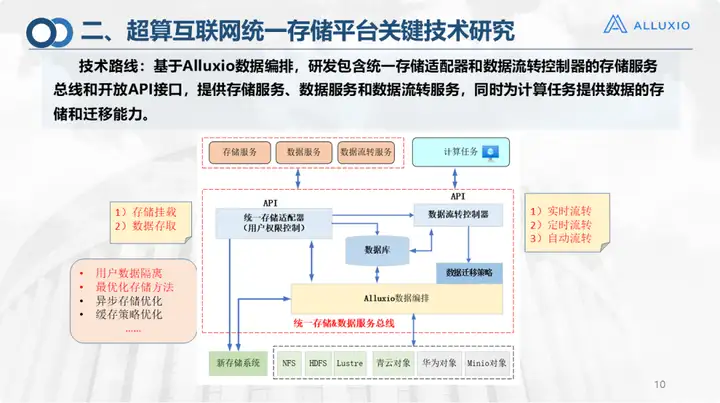
Esta imagem mostra que a tecnologia central da plataforma de armazenamento unificado é o design do barramento de serviço. Retirei-o separadamente porque desenvolvemos um adaptador de armazenamento unificado e um controlador de fluxo de dados na camada superior baseado no Alluxio e incorporamos três estratégias de circulação: circulação em tempo real, circulação programada e circulação automática. Ele também fornece serviços de armazenamento, dados e transferência de dados para este portal de cálculo de código (o portal principal acima) e pode fornecer funções de interface e montagem. Assim como o adaptador de armazenamento unificado, atualmente podemos fazer:
1. Montagem automática de armazenamento;
2. Múltiplas formas de acessar dados, incluindo interface, cliente e linha de comando, são todas suportadas.
É claro que também fizemos pesquisas sobre isolamento de dados de usuários e métodos de armazenamento ideais, que já foram incorporados. O controlador de fluxo de dados realiza muito trabalho e possui três estratégias de fluxo:
1. A transferência em tempo real é principalmente para usuários, porque os usuários solicitam um armazenamento em Jinan e um armazenamento em Qingdao em nossa plataforma. Se desejarem migrar os dados em tempo real, o usuário especifica o endereço original. e destino da migração, selecione a velocidade de transferência e corresponda automaticamente à estratégia de migração. Também fizemos algumas pesquisas sobre modelos inteligentes para calcular o tempo de execução de tarefas em diferentes estados e selecionar a estratégia ideal.
2. Transferência programada A transferência programada é atualmente direcionada para cenários oceânicos e de campus. Por exemplo, os dados locais nas escolas ou no oceano estão no limite, porque alguns deles são dados de vídeo e a escala de dados é particularmente grande. Se você quiser fazer pesquisas e precisar economizar, na verdade não existe tal dispositivo de armazenamento na borda. Sem uma quantidade tão grande de dispositivos de armazenamento, pode ser necessário fazer a migração programada de dados todas as semanas. Configure o endereço de origem e o endereço de destino da migração especificados dentro de um tempo definido. Também usamos o modelo inteligente para selecionar a estratégia ideal com base no tempo e prazo da tarefa. Você pode optar por fazer isso à noite ou quando o tráfego da rede estiver relativamente baixo.
3. A transferência automática também é um recurso, que consiste em selecionar de forma inteligente os dados e o local a serem migrados com base no mecanismo de regras. Pode haver muitos desses cenários. Personalizamos vários desses cenários e há uma introdução aos cenários de fluxo automático posteriormente. É julgado com base se os dados são armazenados e calculados separadamente. Por exemplo, se estiverem armazenados no Zibo e eu quiser calculá-los em Jinan, se as condições da rede não permitirem que o usuário concorde, podemos migrá-los automaticamente para. ele. Obviamente, você pode determinar se os dados são pré-buscados combinando o modo de acesso do banco de dados de metadados e a frequência de acesso dos dados do ponto de acesso.
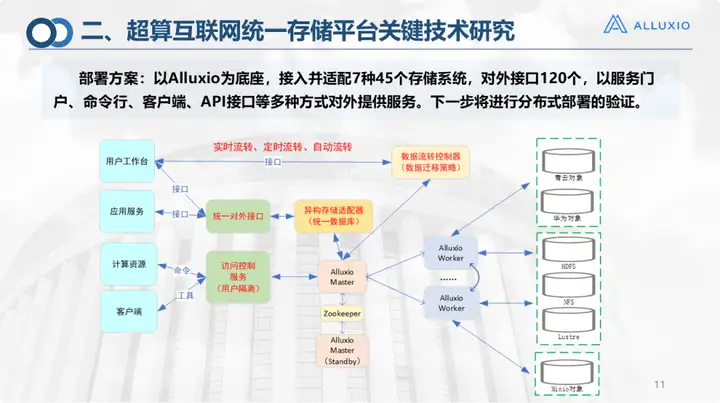
Este é o nosso plano de implantação, que atualmente está conectado aos sistemas de armazenamento listados na figura, incluindo o Alibaba Cloud. São cerca de 130 interfaces externas, que podem fornecer serviços externos através de linha de comando do portal de serviços, cliente, API, etc. Ainda seguimos a implantação clássica do Alluxio para a implantação atual. Numa fase posterior, esperamos conseguir uma implantação distribuída: actualmente, devido a restrições de rede, todas as exportações estão concentradas em Jinan. Embora 16 cidades já tenham estabelecido a China Unicom, as exportações ainda não foram liberalizadas. Por exemplo, a ligação entre Qingdao e Zibo não foi totalmente testada. Sob tais circunstâncias, não há problema com este layout. Todo o armazenamento deve ser implantado e chamado pela plataforma geral Alluxio Master Jinan quando usado. Se outras redes forem liberalizadas, espero que se a computação estiver em Qingdao, o armazenamento também será. em Qingdao, pode realizar a montagem local sem ter que notificar o Mestre em Jinan para deixá-lo fazer a alocação. Na verdade, isso adiciona mais uma etapa, então agora também estamos fazendo testes e verificação de implantação distribuída.
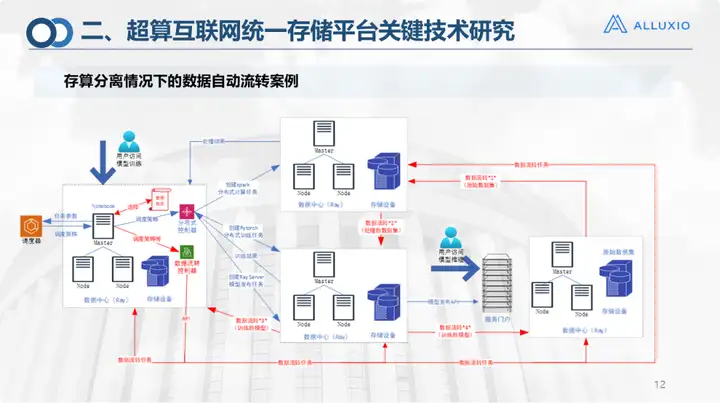
Este é um caso de transferência automática de armazenamento e separação de cálculos. Claro, este também é o cenário real do atual campus inteligente.
Nossos dispositivos de armazenamento e recursos de computação foram todos gerenciados em uma plataforma de armazenamento unificada e em uma plataforma de nuvem, chamada plataforma de gerenciamento multinuvem. Neste caso, nosso sistema operacional de rede de computação terá uma programação geral. Neste ambiente, todos os dados existem atualmente no data center mais à direita. Suponha que este data center esteja em Zibo e o usuário esteja em Jinan ou envie tarefas de treinamento. a plataforma principal, após o envio, haverá um cronograma geral para determinar onde estão os recursos computacionais, o ambiente de pré-treinamento e o ambiente de treinamento para delinear locais e gerar recursos, pois esse contêiner precisa ser gerado automaticamente com base na demanda, e será gerado com base na visualização dos dados (o nosso no Alluxio. Uma camada de visualização dos dados é feita acima). De acordo com a visualização de dados e o controlador de fluxo de dados, os dados são migrados do endereço original para o endereço de destino para treinamento. Para este cenário, quatro fluxos são realmente necessários:
√ Fluxo do conjunto de dados original para treinamento no ambiente de pré-processamento pré-treinamento;
√ Após o processamento, você precisa ir ao ambiente de treinamento para treinamento;
√ Finalmente, o modelo precisa ser retornado ao usuário;
√ Se o usuário configurar, ele deverá retornar à cena final (como um campus) antes de realizar operações de inferência.
Portanto, especificamos o processo de circulação em vários cenários específicos da indústria.
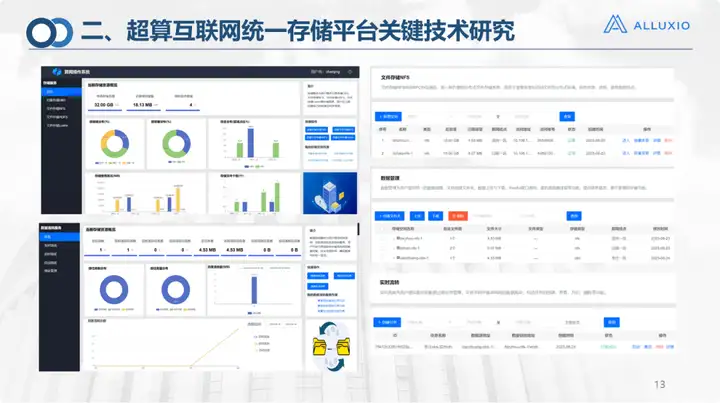
Esta é a interface atual da nossa plataforma de armazenamento unificado V1.0. Foi divulgado no portal principal, incluindo o portal de serviços e o portal de gerenciamento. O portal de serviços possui um total de 6 módulos e mais de 20 submódulos.
Para a plataforma de armazenamento unificado, ainda temos trabalho de acompanhamento para continuar: incluindo implantação distribuída de nós Alluxio Master e gerenciamento unificado de agendamento em sua camada superior. Depois, há a pré-busca de dados, que é a otimização do mecanismo de cache de dados, incluindo o design da pré-busca, regras de associação e, mais importante, queremos fazer armazenamento em camadas, que é o que precisamos fazer mais tarde.
3. Aplicação e desenvolvimento futuro da Internet de supercomputação

A seguir apresentamos as aplicações atuais da Internet de supercomputação em vários setores:
Vamos nos concentrar no desenvolvimento da Internet de supercomputação no segundo semestre de 2022, mas na verdade estamos traçando o layout desde 2016, então já temos algumas aplicações em muitos setores: incluindo oceanos, materiais, meteorologia e proteção ambiental,. ecologia, simulação industrial, educação e outros aspectos.
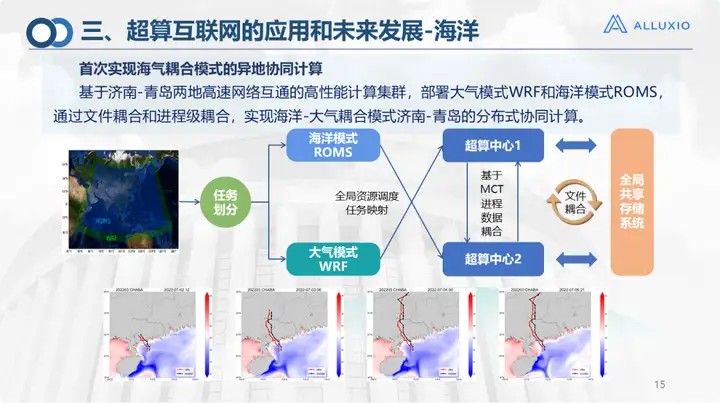
Este é o modelo de acoplamento oceânico, que é uma rede interconectada que construímos em conjunto com o Laboratório Laoshan. Como você pode ver, os cálculos no oceano podem ser relativamente complicados. Cálculos de modelos oceânicos e cálculos de modelos atmosféricos são necessários. O modelo atmosférico atual é executado no supercomputador Qingdao, e o modelo oceânico é executado no supercomputador Jinan, e então o acoplamento de arquivos é realizado. Esta é a primeira vez que implementamos computação colaborativa remota em 2023 e alcançamos bons resultados.

No campo do sensoriamento remoto, também temos um cenário de fluxo de dados relativamente completo. São os dados do Centro Nacional de Dados Científicos de Observação da Terra: primeiro são transmitidos ao Supercomputador Jinan por meio de uma linha dedicada e depois são armazenados em arquivos de bloco. por meio de algumas operações de classificação e armazenamento. No armazenamento, como objetos, os produtos de dados são produzidos e compartilhados após o processamento. Este também é nosso primeiro sistema de coleta e processamento de dados que separa armazenamento e cálculo entre domínios. Também solicitamos a criação do Centro Nacional de Depósito e Computação de Observação da Terra.
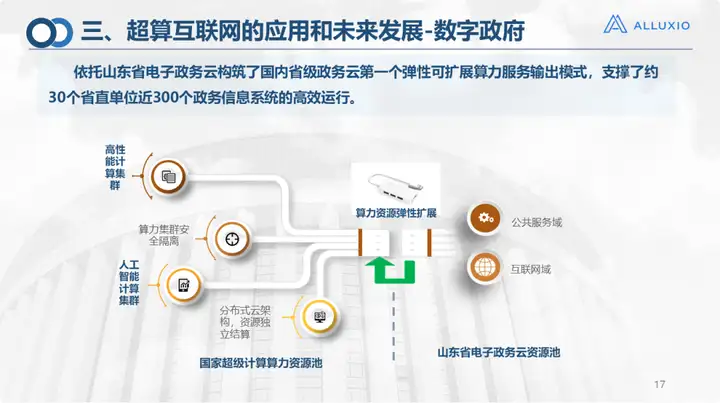
No domínio do governo digital, porque o próprio governo eletrónico está na nossa unidade, atualmente apoiamos a operação eficiente de 30 unidades provinciais e 300 sistemas governamentais na província de Shandong. recursos Expansão elástica.
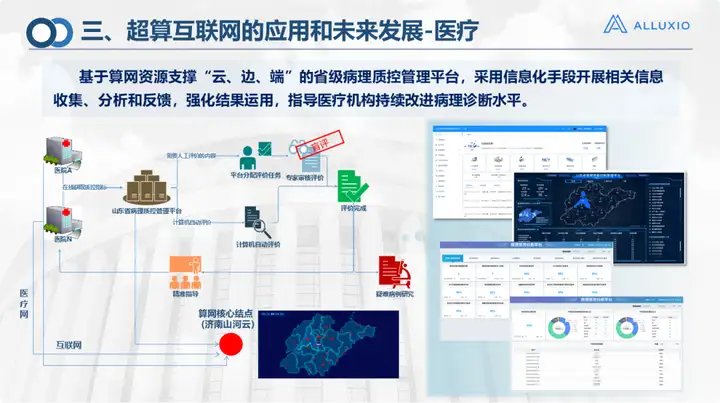
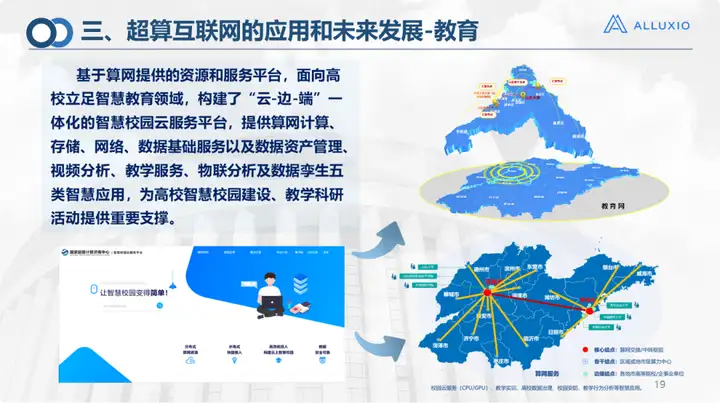
Em áreas como assistência médica e educação, o trabalho na nuvem e na borda é realizado principalmente. É a rede de computação e armazenamento fornecida por Suanwang, incluindo a transferência programada mencionada acima. No cenário de campus inteligente, realizamos o projeto da Universidade de Tecnologia de Qilu e fizemos mais em cenários de aplicação de campus.
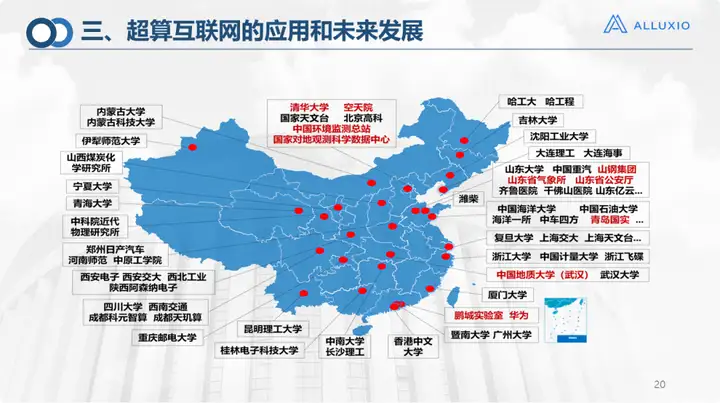
Finalmente, deixe-me apresentar a empresa. Nossas aplicações abrangem mais de 2.000 empresas/universidades/instituições em todo o país e também receberam amplo reconhecimento no país e no exterior. Penso que é realmente necessário construir uma rede de poder computacional, que ajudará a revitalizar o nosso actual stock de recursos de poder computacional. Se tivermos uma Internet de supercomputação, devemos melhorar a utilização dos recursos computacionais, permitir que o poder computacional seja monetizado e permitir que centros de poder computacional, centros de supercomputação e outros centros de dados operem de forma sustentável e saudável, e em alguns ecossistemas de supercomputação, tem melhor aplicações nas áreas de proteção ambiental, oceanos e sensoriamento remoto, e acredito que haverá cenários de aplicação mais amplos no futuro.
