

Autor deste artigo:
Tarik Bennett, Beinan Wang, Hope Wang
Este artigo discutirá os desafios de acesso a dados em inteligência artificial (IA) e revelará que “NAS/NFS comumente usados podem não ser a melhor escolha ” .
1. Arquitetura inicial de inteligência artificial/aprendizado de máquina
A pesquisa do Gartner mostra que, embora os grandes modelos de linguagem (LLM) tenham atraído muita atenção, a maioria das organizações ainda está nos estágios iniciais de uso de grandes modelos e apenas algumas entraram na fase de produção.
O foco da construção de uma plataforma de IA nos estágios iniciais é colocar o sistema em funcionamento para que os pilotos do projeto e as provas de conceito possam ser conduzidas. Essas arquiteturas iniciais, ou arquiteturas de pré-produção, são projetadas para atender às necessidades básicas de treinamento e implantação de modelos. Atualmente, muitas organizações já estão usando esse tipo de arquitetura inicial de IA para ambientes de produção.
À medida que os dados e os modelos crescem, essas primeiras arquiteturas de IA muitas vezes tornam-se ineficientes. As empresas treinam modelos na nuvem e, à medida que os projetos se expandem, espera-se que o uso de dados e da nuvem aumente significativamente dentro de 12 meses. Muitas organizações começam com volumes de dados que correspondem aos tamanhos atuais de memória, mas estão cientes da necessidade de se prepararem para cargas maiores.
As empresas podem optar por usar uma pilha de tecnologia existente ou uma implantação greenfield. Este artigo se concentrará em como usar sua pilha de tecnologia existente ou adquirir algum hardware adicional para projetar uma pilha de tecnologia mais escalável, ágil e de alto desempenho.
2. Desafios no acesso aos dados
Com a evolução da arquitetura AI/ML, o tamanho dos conjuntos de dados de treinamento de modelos continua a crescer significativamente, e o poder de computação e a escala das GPUs também estão aumentando rapidamente. Além da computação, do armazenamento e da rede, acreditamos que o acesso aos dados é outro elemento-chave na construção de uma plataforma de IA voltada para o futuro .

O acesso a dados refere-se a tecnologias como serviços de dados, armazenamento de backup (NFS, NAS) e cache de alto desempenho (como Alluxio) que ajudam o mecanismo de computação a obter dados para treinamento e implantação de modelos.
O foco do acesso aos dados é o rendimento e a eficiência do carregamento de dados, o que é cada vez mais importante para arquiteturas de IA/ML onde os recursos da GPU são escassos – otimizar o carregamento de dados pode reduzir significativamente o tempo de espera ociosa da GPU e melhorar a utilização da GPU. Portanto, o acesso a dados de alto desempenho deve ser o objetivo principal da implantação da arquitetura.
À medida que as empresas expandem as tarefas de treinamento de modelos nas primeiras arquiteturas de IA, surgiram alguns desafios comuns de acesso a dados:
1
A eficiência do treinamento do modelo é menor do que o esperado: devido a gargalos no acesso aos dados, o tempo de treinamento é maior do que o estimado com base nos recursos computacionais. Fluxos de dados de baixo rendimento não fornecem dados suficientes para a GPU.
2
Gargalos relacionados à sincronização de dados: copiar ou sincronizar manualmente os dados do armazenamento para um servidor GPU local cria atrasos na construção da fila de dados a ser preparada.
3
Problemas de simultaneidade e metadados: quando trabalhos grandes são lançados em paralelo, pode ocorrer contenção no armazenamento compartilhado. A latência aumenta quando as operações de metadados no armazenamento de back-end são lentas.
4
Desempenho lento ou baixa utilização da GPU: a infraestrutura de GPU de alto desempenho requer um grande investimento e, uma vez que o acesso aos dados seja ineficiente, levará a recursos de GPU ociosos e subutilizados.
Além disso, esses desafios são agravados por uma série de outras questões que as equipes de dados precisam gerenciar. Esses problemas incluem velocidades lentas de E/S de armazenamento que não atendem às necessidades de clusters de GPU de alto desempenho. Depender da cópia e sincronização manual de dados aumenta a latência enquanto a equipe de dados espera que os dados sejam entregues ao servidor GPU. O desafio do acesso a dados também é agravado pela complexidade arquitetônica de vários silos de dados em infraestruturas híbridas ou ambientes multinuvem.
Em última análise, esses problemas fazem com que a eficiência ponta a ponta da arquitetura fique aquém das expectativas.
Os desafios relacionados com o acesso a dados têm frequentemente duas soluções comuns.
Adquira armazenamento mais rápido: muitas empresas tentam resolver o problema do acesso lento aos dados implantando opções de armazenamento mais rápidas. Os fornecedores de nuvem fornecem armazenamento de alto desempenho, enquanto os fornecedores de hardware profissionais vendem armazenamento HPC para melhorar o desempenho.
Adicione NAS/NFS ao armazenamento de objetos: adicionar NAS ou NFS centralizados como backup para armazenamento de objetos como S3, MinIO ou Ceph é uma prática comum e ajuda as equipes a consolidar dados em sistemas de arquivos compartilhados, simplificando a colaboração e o compartilhamento de usuários e cargas de trabalho. Além disso, você também pode aproveitar funções de gerenciamento de dados relacionadas, como consistência de dados, disponibilidade, backup e escalabilidade fornecidas por fornecedores de NAS experientes.
No entanto, essas duas soluções comuns acima podem não resolver o seu problema.
Embora o armazenamento mais rápido e o NFS/NAS centralizado possam gradualmente alcançar algumas melhorias de desempenho, também existem desvantagens.
1
Armazenamento mais rápido significa migração de dados, o que pode facilmente levar a problemas de confiabilidade dos dados
Para aproveitar o alto desempenho fornecido pelo armazenamento dedicado, os dados devem ser migrados do armazenamento existente para um novo nível de armazenamento de alto desempenho. Isso faz com que os dados sejam migrados em segundo plano. A migração de grandes conjuntos de dados pode resultar em tempos de transferência prolongados e em problemas de confiabilidade dos dados, como corrupção ou perda de dados durante a migração. Enquanto a equipe aguarda a conclusão da sincronização de dados, pausar as operações pode interromper o serviço e retardar o andamento do projeto.
2
NFS/NAS: Manutenção e gargalos
Como camada de armazenamento adicional, os desafios de manutenção, estabilidade e escalabilidade do NFS/NAS permanecem. Copiar dados manualmente do NFS/NAS para um servidor GPU local aumentará a latência e desperdiçará recursos causados por backups repetidos. Picos na demanda de leitura causados por trabalhos paralelos podem agrupar servidores NFS/NAS e serviços interconectados. Além disso, ainda existem problemas de sincronização de dados em clusters de GPU NFS/NAS remotos.
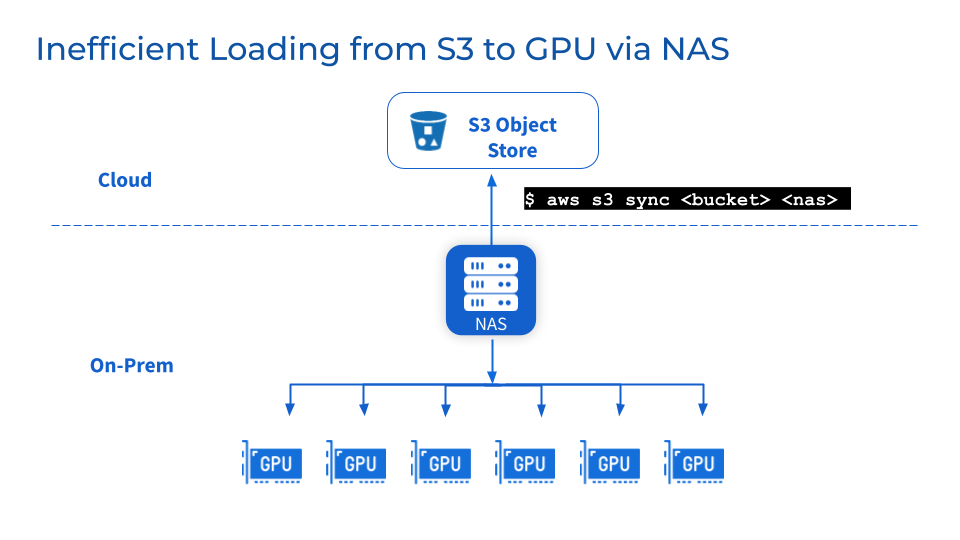
3
E se eu precisar mudar de fornecedor por motivos comerciais?
As empresas podem mudar de fornecedor devido à otimização de custos ou por razões contratuais. A flexibilidade dos ambientes multinuvem exige a capacidade de portar facilmente grandes conjuntos de dados sem dependência de fornecedor. No entanto, mover o armazenamento de dados em escala de petabytes pode causar tempo de inatividade significativo e interrupção no desenvolvimento do modelo.
Em suma, as soluções existentes, embora úteis no curto prazo, não podem fornecer uma arquitetura de acesso a dados escalável e otimizada para atender ao crescimento exponencial das necessidades de dados de IA/ML.
3. Soluções fornecidas pela Alluxio
Alluxio pode ser implantado entre fontes de computação e de dados. Forneça abstração de dados e cache distribuído para melhorar o desempenho e a escalabilidade da arquitetura de IA/ML.
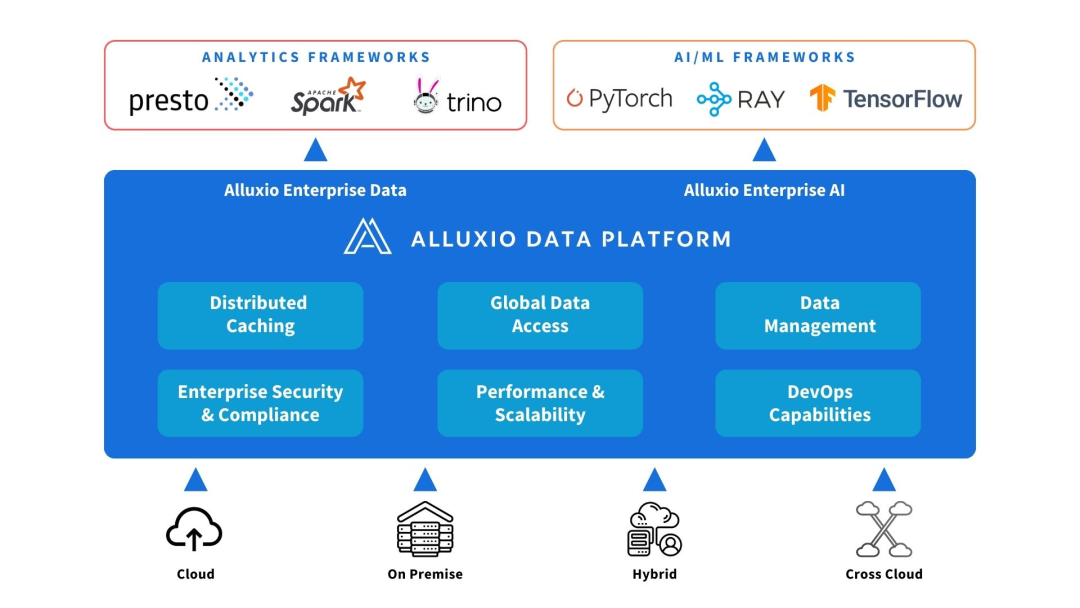
Alluxio ajuda a resolver os desafios enfrentados pelas primeiras arquiteturas de IA em escalabilidade, desempenho e gerenciamento de dados à medida que a quantidade de dados, a complexidade do modelo aumentam e os clusters de GPU se expandem.
1
aumentar a capacidade
O Alluxio pode ser dimensionado além do limite de um único nó para acomodar conjuntos de dados de treinamento maiores do que a memória do cluster ou SSDs locais podem acomodar. Ele conecta diferentes sistemas de armazenamento e fornece uma camada unificada de acesso a dados para montar data lakes em nível de petabyte. O Alluxio armazena em cache de forma inteligente arquivos e metadados usados com frequência em camadas de memória e SSD próximas à computação, eliminando a necessidade de copiar todo o conjunto de dados.
2
Reduza o gerenciamento de dados
Alluxio simplifica a movimentação e armazenamento de dados entre clusters GPU por meio de cache distribuído automatizado. As equipes de dados não precisam copiar ou sincronizar manualmente os dados com arquivos de teste locais. O cluster Alluxio pode capturar automaticamente arquivos ou objetos importantes para um local próximo ao nó de computação sem passar por operações complexas de fluxo de trabalho. Alluxio simplifica fluxos de trabalho mesmo com 50 milhões ou mais objetos por nó.
3
Melhorar o desempenho
O Alluxio foi desenvolvido para acelerar cargas de trabalho, eliminando gargalos de E/S no armazenamento tradicional que limitam o rendimento da GPU. O cache distribuído aumenta a velocidade de acesso aos dados em ordens de magnitude. Comparado ao acesso ao armazenamento remoto através da rede, o Alluxio fornece acesso local aos dados nos níveis de memória e SSD, melhorando assim a utilização da GPU.
Resumindo, o Alluxio fornece uma camada de acesso a dados escalonável e de alto desempenho que pode maximizar o uso de recursos de GPU em cenários de expansão de dados de IA/ML.
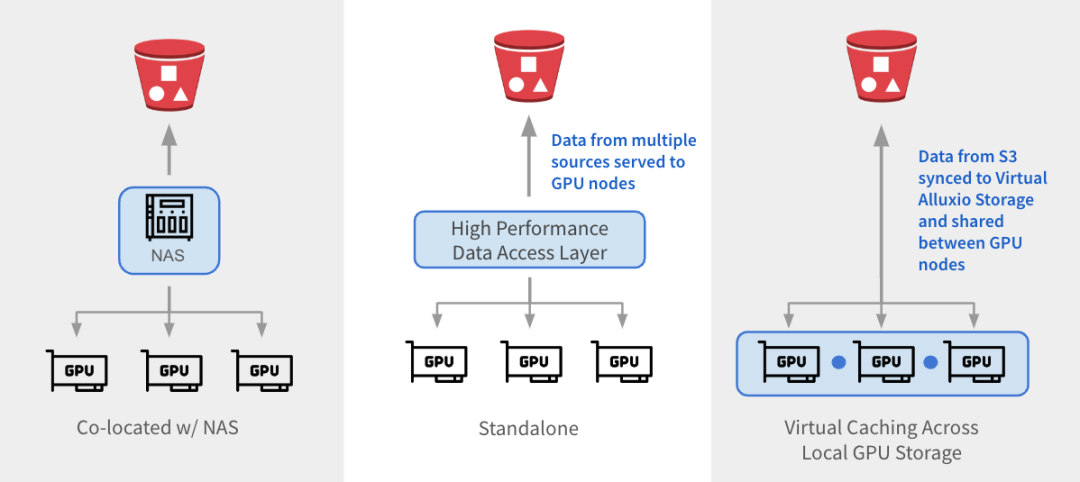
O Alluxio pode ser integrado com arquiteturas existentes de três maneiras.
1
与 NAS 并置:Alluxio 作为透明缓存层与现有 NAS并置部署,增强 I/O 性能。Alluxio将NAS中的活跃数据缓存在跨GPU节点的本地 SSD 中。作业将读取请求重新定向到Alluxio上的SSD缓存,绕过NAS,从而消除NAS瓶颈。写入操作通过 Alluxio 对 SSD 进行低延迟写入,然后异步持久化保存到 NAS中。
2
独立数据访问层:Alluxio 作为专用的高性能数据访问层,整合来自 S3、HDFS、NFS 或本地数据湖等多个数据源的数据,为GPU节点提供数据访问服务。Alluxio 将不同的数据孤岛统一在一个命名空间下,并将存储后端挂载为底层存储。经常访问的数据会被缓存在 Alluxio Worker节点的SSD中,从而加速GPU对数据的本地访问。
3
跨GPU存储的虚拟缓存:Alluxio充当跨本地GPU存储的虚拟缓存。S3中的数据会被同步到虚拟 Alluxio存储并在GPU节点之间共享,无需在节点之间手动拷贝数据。
1
参考架构
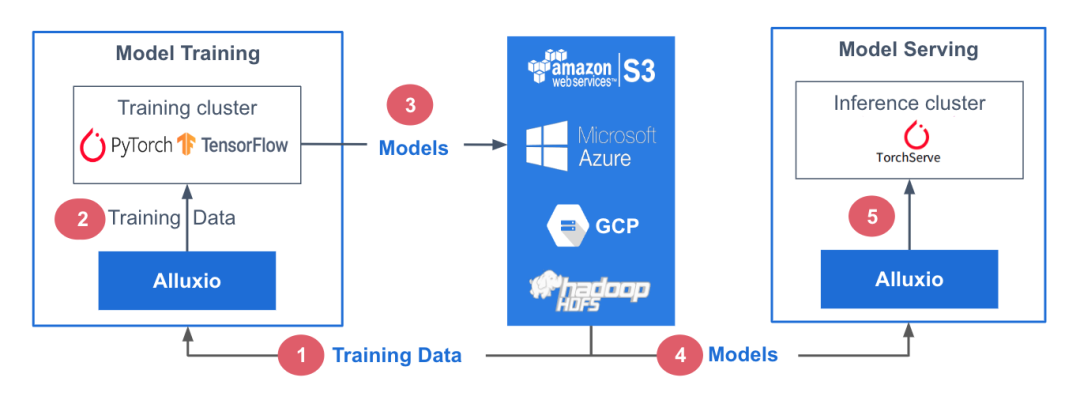
在此参考架构中,训练数据存储在中心化数据存储平台AWS S3中。Alluxio可帮助实现模型训练集群对训练数据的无缝访问。PyTorch、TensorFlow、scikit-learn和XGBoost等ML训练框架都在CPU/GPU/TPU集群上层执行。这些框架利用训练数据生成机器学习模型,模型生成后被存储在中心化模型库中。
在模型服务阶段,使用专用服务/推理集群,并采用TorchServe、TensorFlow Serving、Triton 和 KFServing等框架。这些服务集群利用Alluxio从模型存储库中获取模型。模型加载后,服务集群会处理输入的查询、执行必要的推理作业并返回计算结果。
训练和服务环境都基于Kubernetes,有助于增强基础设施的可扩展性和可重复性。
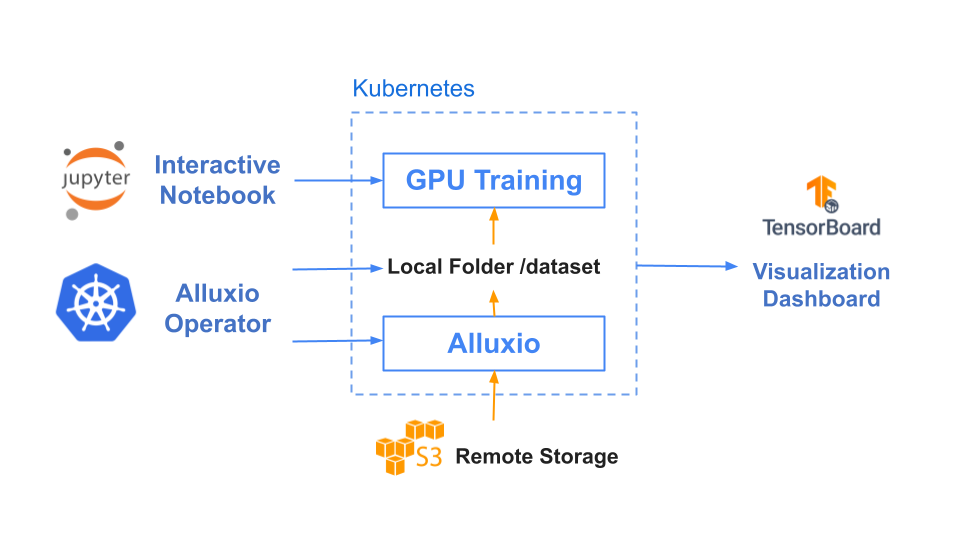
2
基准测试结果
在本基准测试中,我们用计算机视觉领域的典型应用场景之一——图片分类任务作为示例,其中我们以ImageNet的数据集作为训练集,通过ResNet来训练图片分类模型。
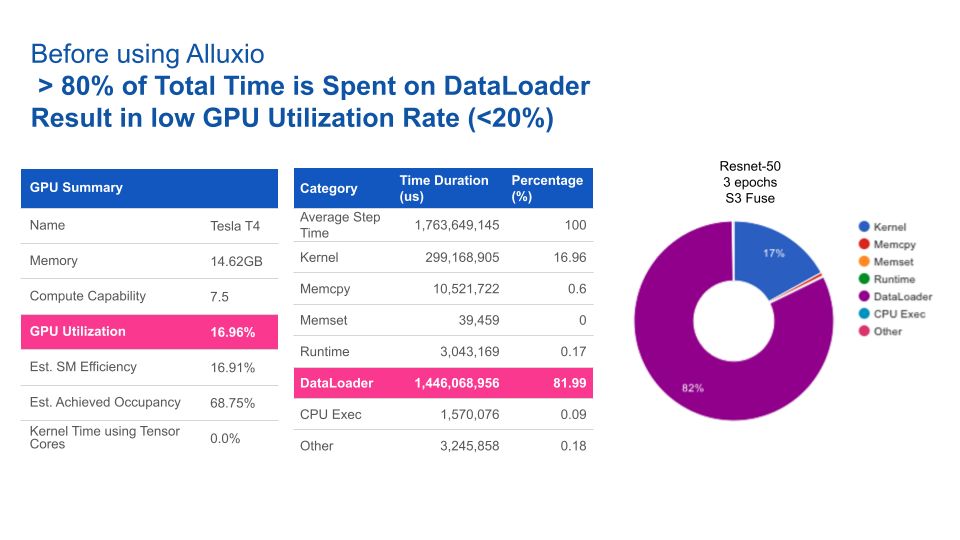
基于Resnet-50上3个epochs性能基准测试的结果,使用Alluxio比使用S3-FUSE的速度快5倍。一般来说,提高数据访问性能可缩短模型训练的总时间。
|
|
Alluxio |
S3 - FUSE |
|
Total training time (3 epochs) |
17 minutes |
85 minutes |
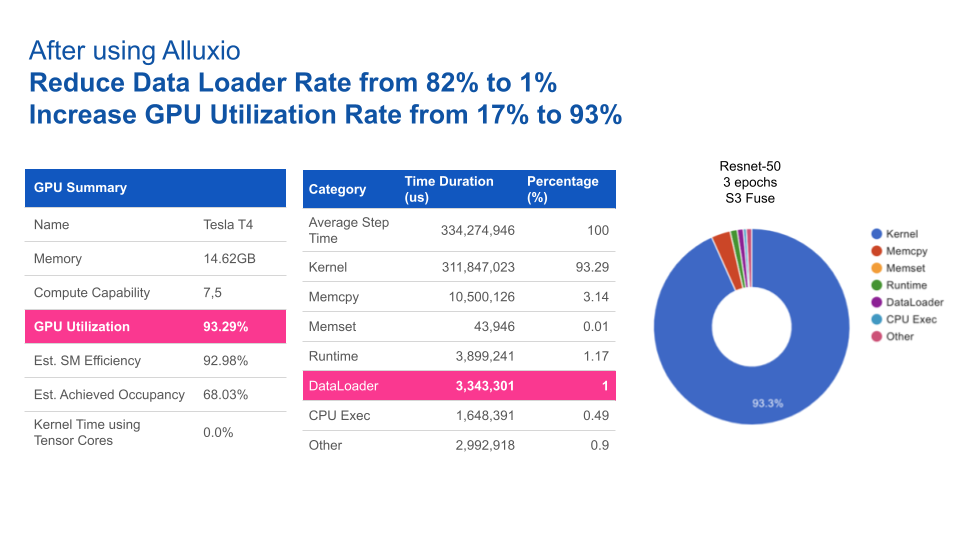
使用Alluxio后,GPU利用率得到大幅提升。Alluxio将数据加载时间由82%缩短至1%,从而将GPU利用率由17%提升至93%。
四、结论
随着AI/ML学习架构从早期的预生产架构向着可扩展架构发展,数据访问始终是瓶颈。仅靠添加更快的存储硬件或中心化NAS/NFS无法完全消除性能不达标以及影响系统操作的管理问题。
Alluxio提供了一种专为优化AI/ML任务数据流而设计的软件解决方案。与传统存储方案相比,其优势包括:
1
优化数据加载:Alluxio智能地加速训练任务和模型服务的数据访问,从而将GPU利用率最大化。
2
维护需求低:无需在节点或集群之间手动拷贝数据。Alluxio通过其分布式缓存层处理热文件传输。
3
支持扩展:当数据量大到需要扩展更多节点的情况下,Alluxio也能维持性能稳定。Alluxio通过使用SSD扩展内存,可缓存任何大小的文件,避免拷贝全部文件。
4
更快的切换:Alluxio将底层存储抽象化,使得数据团队能够轻松地在云厂商、本地或多云环境中迁移数据。数据迁移无需替换硬件,也不会导致停机。
部署Alluxio后,企业通过针对数据访问进行优化的数据架构,可以构建出性能卓越、可扩展的数据平台,从而加速模型开发,满足不断增长的数据需求。
✦
【近期热门】
✦

✦
【宝典集市】
✦






本文分享自微信公众号 - Alluxio(Alluxio_China)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。