Introdução : ArcGraph é um banco de dados gráfico distribuído com arquitetura nativa da nuvem e inventário e análise integrados. Este artigo explicará em detalhes como o ArcGraph pode lidar de maneira flexível com a análise de gráficos com memória limitada.
01 Introdução
Agora que a tecnologia de análise gráfica é amplamente utilizada, os círculos acadêmicos e os principais fabricantes de bancos de dados gráficos estão ansiosos para melhorar os indicadores de alto desempenho da tecnologia de análise gráfica. No entanto, no processo de busca da computação de alto desempenho, o método de “trocar espaço por tempo” é frequentemente adotado, ou seja, aumentando a quantidade de uso de memória para acelerar os cálculos. No entanto, a computação gráfica com memória externa ainda não está madura neste estágio, e a análise gráfica ainda depende da computação com memória total. Isso faz com que os mecanismos de computação gráfica de alto desempenho tenham uma forte dependência de grande memória. não será executado.
Descobrimos, em muitos casos de clientes no passado, que os recursos de hardware que os clientes investem na análise de gráficos são geralmente fixos e limitados, e os recursos do ambiente de teste são mais limitados do que os do ambiente de produção. Os requisitos de pontualidade dos clientes para análise gráfica são geralmente T+1, que é um requisito típico de análise offline. Portanto, os clientes esperam que o mecanismo de computação gráfica reduza a demanda por recursos como CPU e memória, em vez de buscar alto desempenho de algoritmo, desde que atenda a T+1. Este é um grande desafio para a maioria dos mecanismos de computação gráfica. Os requisitos de CPU são relativamente fáceis de controlar, enquanto os requisitos de memória são difíceis de otimizar significativamente em um curto ciclo de desenvolvimento.
O ArcGraph também enfrenta os desafios acima, mas por meio de resumo e aprimoramento contínuos nas práticas de entrega ao cliente, nosso mecanismo de computação gráfica tem flexibilidade para equilibrar o processamento no tempo e no espaço. Atualmente, o mecanismo de computação gráfica integrado do ArcGraph lidera a indústria em termos de indicadores de desempenho de análise gráfica e ainda está sendo otimizado e aprimorado. A seguir, explicaremos como o ArcGraph troca habilmente tempo por espaço para lidar com a análise de gráficos sob memória limitada de múltiplas perspectivas, incluindo a estrutura de dados subjacente do mecanismo e a invocação de algoritmos de nível superior.
02 Seleção do tipo de ID do ponto
O mecanismo de cálculo gráfico ArcGraph suporta três tipos de ID de ponto: string, int64 e int32. O suporte para o tipo de ponto de string pode melhorar a compatibilidade com os dados de origem, mas comparado ao int64, aumentará o uso de memória porque uma tabela de mapeamento de ID de ponto de string para int64 precisa ser mantida na memória. Se o tipo de ponto especificado for int64, o ArcGraph irá gerar uma tabela de mapeamento int64 a partir do ID do ponto do tipo string nos dados de origem e colocá-la na memória externa. Somente os dados da borda do ponto do tipo int64 mapeados serão retidos na memória. Após a conclusão do cálculo, a tabela de mapeamento é lida na memória e o ID da string é restaurado. Portanto, usar o ID de ponto do tipo int64 aumentará o consumo de tempo extra para trocar a tabela de mapeamento entre a memória externa e a memória, mas também reduzirá significativamente o uso geral da memória. O tamanho da memória economizada depende do comprimento e do ponto do original. ID do volume.
Além disso, o mecanismo de cálculo gráfico ArcGraph também suporta int32. Para cenários onde o número total de pontos de dados de origem é inferior a 40 milhões, o uso de memória pode ser reduzido ainda mais em cerca de 30% em comparação com int64.
A seguir está um exemplo de especificação do tipo de ID do ponto de carregamento do gráfico na API do algoritmo de gráfico de execução do ArcGraph:
curl -X 'POST' 'http://myhost:18000/graph-computing?reload=true&use_cache=true' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"algorithmName": "pagerank",
"graphName": "twitter2010",
"taskId": "pagerank",
"oid_type": "int64",
"subGraph": {
"edgeTypes": [
{
"edgeTypeName": "knows",
"props": [],
"vertexPairs": [
{
"fromName": "person",
"toName": "person"
}
]
}
],
"vertexTypes": [
{
"vertexTypeName": "person",
"props": []
}
]
},
"algorithmParams": {
}
}'
03 Ative a codificação Varint
A codificação Varint é usada para compactar e codificar inteiros e é um método de codificação de comprimento variável. Tomando int32 como exemplo, são necessários 4 bytes para armazenar um valor normalmente. Na codificação Varint convencional, os últimos 7 bits de cada byte são usados para representar dados, e o bit mais alto é o bit de sinalização.


- Se o bit mais alto for 0, significa que os últimos 7 bits do byte atual são todos os dados e os bytes subsequentes não têm nada a ver com os dados. Por exemplo, o número inteiro 1 na figura acima requer apenas um byte para representar: 00000001, e os bytes subsequentes não pertencem aos dados do número inteiro 1.
- Se o bit mais alto for 1, significa que os bytes subsequentes ainda fazem parte dos dados. Por exemplo, o número inteiro 511 na imagem acima requer 2 bytes para representar: 11111111 00000011, e os bytes subsequentes são os dados de 131071.
Usando essa ideia, inteiros de 32 bits podem ser representados por 1 a 5 bytes. Da mesma forma, um número inteiro de 64 bits pode ser representado por 1 a 10 bytes. Em cenários reais de uso, a taxa de uso de números pequenos é muito maior do que a de números grandes, especialmente para números inteiros de 64 bits. Portanto, a codificação Varint geralmente pode obter efeitos de compactação significativos. Existem muitas variantes de codificação Varint e muitas implementações de código aberto.
O mecanismo de cálculo gráfico ArcGraph suporta o uso da codificação Varint para compactar o armazenamento de dados de borda na memória (principalmente CSR/CSC). Quando a codificação Varint está ativada, a memória ocupada pelos dados de borda pode ser significativamente reduzida, até cerca de 50% nas medições reais. Ao mesmo tempo, a perda de desempenho causada pela codificação e decodificação também chegará a cerca de 20%. Portanto, antes de ligá-lo, você precisa entender claramente os cenários de uso e as necessidades do cliente para garantir que a perda de desempenho causada pela economia de memória esteja dentro de uma faixa aceitável.
A seguir está um exemplo de codificação Varint para permitir o cálculo de gráfico na API de carregamento de gráfico do ArcGraph:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true"
}'
04 Ative o HashMap Perfeito
A diferença entre Perfect HashMap e outros HashMap é que ele usa Perfect Hash Function (PHF). A função H mapeia N valores de chave para M inteiros, onde M>=N, e satisfaz H(key1)≠H(key2)∀key1, key2, então a função é uma função hash perfeita. Se M = N, então H é a Função Hash Mínima Perfeita (abreviadamente MPHF). Neste momento, N valores-chave serão mapeados para N inteiros consecutivos.
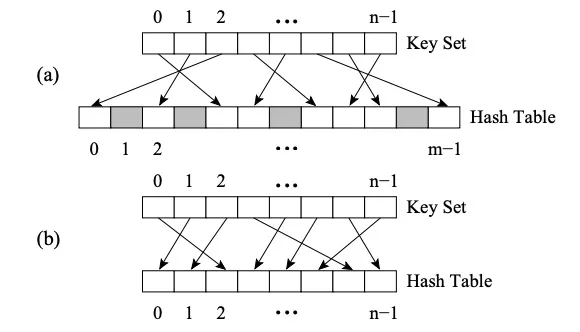 A imagem (a) é PHF, a imagem (b) é MPHF
A imagem (a) é PHF, a imagem (b) é MPHF
A imagem acima é a estratégia FKS de hashing de dois níveis. Primeiro, os dados são mapeados no espaço T por meio do hash de primeiro nível e, em seguida, os dados conflitantes são selecionados aleatoriamente e mapeados para o espaço S usando uma nova função hash, e o tamanho m do espaço S é o quadrado do conflito. dados (por exemplo, há três em T2. Se os números entrarem em conflito, eles serão mapeados para o espaço S2 onde m é 9). Neste momento, é fácil encontrar uma função hash que evite colisões. A seleção apropriada da função hash reduz as colisões durante o hash de um nível, de modo que o espaço de armazenamento esperado pode ser O(n).
O mecanismo de cálculo gráfico ArcGraph manterá um mapeamento do ID do ponto original para o ID do ponto interno na memória. O ponto interno é um tipo inteiro longo e contínuo, que é conveniente para compactação de dados e otimização de vetorização. O mapeamento é essencialmente um hashmap, mas o ArcGraph fornece dois métodos em termos de implementação subjacente:
- Flat HashMap - A vantagem é que a velocidade de construção é rápida, mas a desvantagem é que geralmente requer maior espaço de memória para reduzir colisões de hash frequentes.
- HashMap Perfeito - A vantagem é que menos memória pode ser usada para garantir uma consulta com eficiência O(1) no pior caso, mas a desvantagem é que todas as chaves precisam ser conhecidas com antecedência e o tempo de construção é longo.
Portanto, ativar o Perfect HashMap também pode atingir o objetivo de trocar tempo por espaço. De acordo com o teste, para o mapeamento definido do ponto original para o ID do ponto interno, o uso de memória do Perfect HashMap é geralmente apenas cerca de 1/5 do Flat HashMap, mas correspondentemente, seu tempo de construção é de 2 a 3 vezes.
A seguir está um exemplo de Perfect HashMap que permite o cálculo de gráfico na API de carregamento de gráfico do ArcGraph:
curl -X 'POST' 'http://localhost:18000/graph-computing/datasets/twitter2010/load' -H 'accept: application/json' -H 'Content-Type: application/json' -d '{
"oid_type": "int64",
"delimeter": ",",
"with_header": "true",
"compact_edge": "true",
"use_perfect_hash": "true"
}'
05 Implementação de algoritmo de otimização e processamento de resultados
O uso de memória no nível de implementação do algoritmo depende da lógica específica do algoritmo. Resumimos os seguintes pontos da prática, que podem atingir o objetivo de trocar tempo por espaço:
Reduza adequadamente o multithreading e o uso de objetos ThreadLocal no algoritmo. Os algoritmos geralmente envolvem o armazenamento de coleções temporárias de ponta. Se esses armazenamentos aparecerem na lógica multithread, a memória geral aumentará à medida que o número de threads aumentar. Reduzir adequadamente o número de threads simultâneos ou reduzir o uso de objetos grandes ThreadLocal ajudará a reduzir a memória. Aumente adequadamente a troca de dados entre a memória interna e externa. De acordo com a lógica específica do algoritmo, objetos grandes temporariamente não utilizados são serializados na memória externa e, quando o objeto é usado, ele é lido na memória em fluxo para evitar que vários objetos grandes ocupem uma grande quantidade de memória ao mesmo tempo. tempo.
A seguir está um exemplo de implementação de algoritmo que incorpora os dois pontos acima:
void IncEval(const fragment_t& frag, context_t& ctx,
message_manager_t& messages) {
...
...
if (ctx.stage == "Compute_Path"){
auto vertex_group = divide_vertex_by_type(frag);
//此处采用单线程for循环而非多线程并行处理,意在防止多个path_vector同时占内存导致OOM。
for(int i=0; i < vertex_group.size(); i++){
//此处path_vector是每个group中任意两点间的全路径,可理解为一个超大对象
auto path_vector = compute_all_paths(vertex_group[i]);
//拿到该对象后不会在当前stage使用,所以先序列化到外存中。
serialize_path_vector(path_vector, SERIALIZE_FOLDER);
}
...
...
}
...
...
if (ctx.stage == "Result_Collection"){
//在当前stage中,将之前stage生成的多个序列化文件合并为一个文件,并把文件路径返回。
auto result_file_path = merge_path_files(SERIALIZE_FOLDER);
ctx.set_result(result_file_path);
...
...
}
...
...
}
Após a conclusão do cálculo, os resultados são gravados na memória externa e a memória relevante do mecanismo de cálculo gráfico é liberada. Em alguns cenários, o programa de processamento de resultados será executado no servidor de cluster de computação gráfica para ler os resultados da computação gráfica e processá-los posteriormente. Se a memória do mecanismo de cálculo gráfico não tiver liberado os resultados do cálculo, na pior das hipóteses, haverá duas cópias dos dados do resultado na memória atual do servidor. Em cenários com grandes quantidades de dados, uma cópia dos dados resultantes ocupará uma quantidade muito elevada de memória. Portanto, neste tipo de cenário, deve-se dar prioridade à gravação dos resultados dos cálculos na memória externa e à liberação oportuna da memória do mecanismo de computação gráfica.
Ao mesmo tempo, a equipe ArcGraph continuará a desafiar a "necessidade e necessidade" de alto desempenho e baixo uso de recursos, e trabalhará com parceiros acadêmicos e industriais para aperfeiçoar ainda mais a memória de transporte de gráficos e a eficiência computacional para alcançar novos avanços tecnológicos.
Google: A transição para Rust reduziu significativamente as vulnerabilidades do Android. PostgreSQL 17 é lançado. Huawei anuncia UBMC aberto, o antigo reprodutor de música clássico Winamp, é oficialmente de código aberto. tornou-se uma marca registrada da Oracle? Open Source Daily | PostgreSQL 17; Como as empresas chinesas de IA contornam a proibição de chips dos EUA; A empresa iniciante "Zhihuijun" abriu o código-fonte AimRT, uma estrutura de desenvolvimento de tempo de execução para o campo da robótica moderna, Tcl/Tk 9.0, lançou o Meta e lançou o modelo de IA multimodal Llama 3.2