На этой неделе задача:
А, питон на основе препаратов
1) установлена среда разработки Python, PyCharm или так может Anaconda, в зависимости от личных предпочтений привычки.
2) установить базовую библиотеку, такие как Numpy, панда, SciPy, Matplotlib
Во- вторых, на этой неделе, содержание обучения видео: https://www.bilibili.com/video/BV1Tb411H7uC?p=1
1) основа P4 Python
2 P1 Введение в Machine Learning)
Концепция: обучение Машина AI филиал, чтобы создать компьютерную систему, в соответствии с данными , предоставленными определенным способом обучения, с увеличением количества обучения, мы можем продолжать учиться и совершенствоваться в работе, обучение оптимизации параметров модели.
Категория: Машинное обучение включает в себя контролируемое обучение, бесконтрольное обучение и обучение с подкреплением ( 9'38 )
Контролируемое обучение - в рамках существующих данных о (х, у) , чтобы определить новые данные (х) на у значения.
• Пример: После того, как несколько учебных дети изучают концепцию Луны, а затем быть в состоянии судить о чем-то, является ли луна.
Неконтролируемое обучение - Анализ взаимосвязи между данными не являются полностью независимыми, P (X) P (Y) ≠ P (XY) . (Кластеризация)
• Пример: тезаурус сочетание обучено, чтобы получить новые слова, новые слова, получить вероятность словосочетаний.
Действие: 1 ) Данные Очистка / Выбор функции; 2 ) определение арифметической модели / оптимизации параметра; 3 ) , предсказывающий исход ( 21 '00 )
[ ×] большая хранения данных / параллельные вычисления / Робот
[Разница] принять определенные правила при выполнении традиционных методов , использование некоторых правил машинного обучения .
Многомерная модель линейной регрессии: построение множества прогностических факторов, в соответствии со значением бесконечно близко к фактическому значению модели.
Неограниченные итерации, так что функция потерь (целевая функция) минимальная, оптимальная модель.
Общий процесс машинного обучения: сбор данных → стиральная данные → Engineering (функция выбора функции, установки параметров) → данных → модели прогнозирования ( 37 '39 )
[Примечание] Фактический объем работ по чистоте и имеет большую инженерию
Методы машинного обучения:
1 ) с использованием различных алгоритмов для классификации данных
Линейный СВМ / РФБ SVM / Дерево решений / Наивный Байес / Линейная дискриминация / QDA / AdaBoast / Случайный лес 等
2 ) различные модели обучения податливого профиля
3 ) функция потерь , чтобы сделать соответствующие корректировки для достижения оптимальных данных прогнозирования
4 ) размер модели проекта , чтобы адаптироваться к различным устройствам
Тэйлор формула - Прогнозирование Е Х значения / осмотр Джини Коэффициент изображения (метод градиентного спуска)
функция Γ
функция Выпуклые
Soft-макс возвращение
Классическая вероятность - День рождения Paradox / упаковка проблемы → энтропии (хаоса степень отражения - деревья решений, случайные леса)
3. Требования к кандидату:
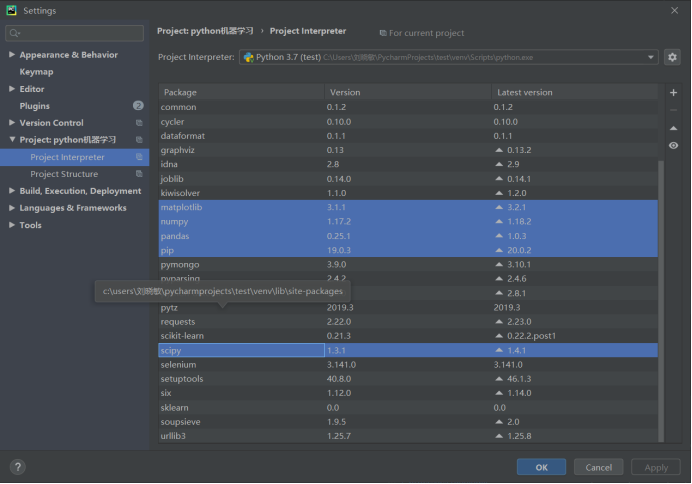
1) Вставить среду Python и пипсов список скриншотов, посмотреть на готовность каждого. Пожалуйста, не будут иметь условия для развития причин и планов.
2) Вставить видео исследования отмечает, требует реального, а не плагиат, почерк может фотографировать.
3) Что такое машинное обучение, какая классификация? С случае, напишите ваше понимание.




Двумерный массив напрямую , используя уникальные дедупликации станет первым двумерный массивом одномерного массива , то предыскажения, не соответствует спросу. Таким образом, способ: дополнительно преобразуется в мнимое число дубликатов.

Способ 2: двумерный массив, а затем преобразуются в набор кортежей
![]()
Укладка np.stack () , в соответствии с осями различных эффектов различного стека.
Умножение матриц![]()
Умножив соответствующий элемент![]()