https://mp.weixin.qq.com/s/w1iN4PgA-cp75lAihcr2aw
By 超神经
GPU 和数据库各有所长,GPU 擅长处理机器学习等任务,而数据库擅长有特定要求的计算,比如复杂的连接计算。
目前有一些提供 GPU 加速的数据库解决方案产品,其中有大家熟悉的 MapD、Kinetica,我们今天要介绍是一款年轻的开源产品 BlazingSQL。
BlazingSQL - это инструмент запросов к базе данных с ускорением на GPU, построенный на RAPIDS. BlazingSQL расширяет RAPIDS и позволяет пользователям запускать SQL-запросы непосредственно на Apache Arrow в памяти графического процессора.
В дополнение к степени адаптации и скорости графического процессора, которая намного выше, чем у других аналогичных продуктов, большинство хранилищ данных SQL требуют, чтобы предприятия извлекали и копировали данные самостоятельно, в то время как BlazingDB может напрямую считывать данные из Apache Parquet, что упрощает каналы данных. Архитектура также может поддерживать высокопроизводительные нагрузки.
Что еще более важно, BlazingSQL также получил инвестиции от NVIDIA и Samsung и поддерживает очень хорошие отношения сотрудничества с NVIDIA.
Оценка эффективности
Чтобы сравнить производительность разных инструментов, вам нужно сравнить тест bechmark, сначала запустите рабочую нагрузку сквозного анализа.
-
Шаги: озеро данных> Разработка функций FTL> Обучение XGBoost
- Мы построили два кластера на GCP по сопоставимым ценам, используя соответственно Apache Spark и BlazingSQL.
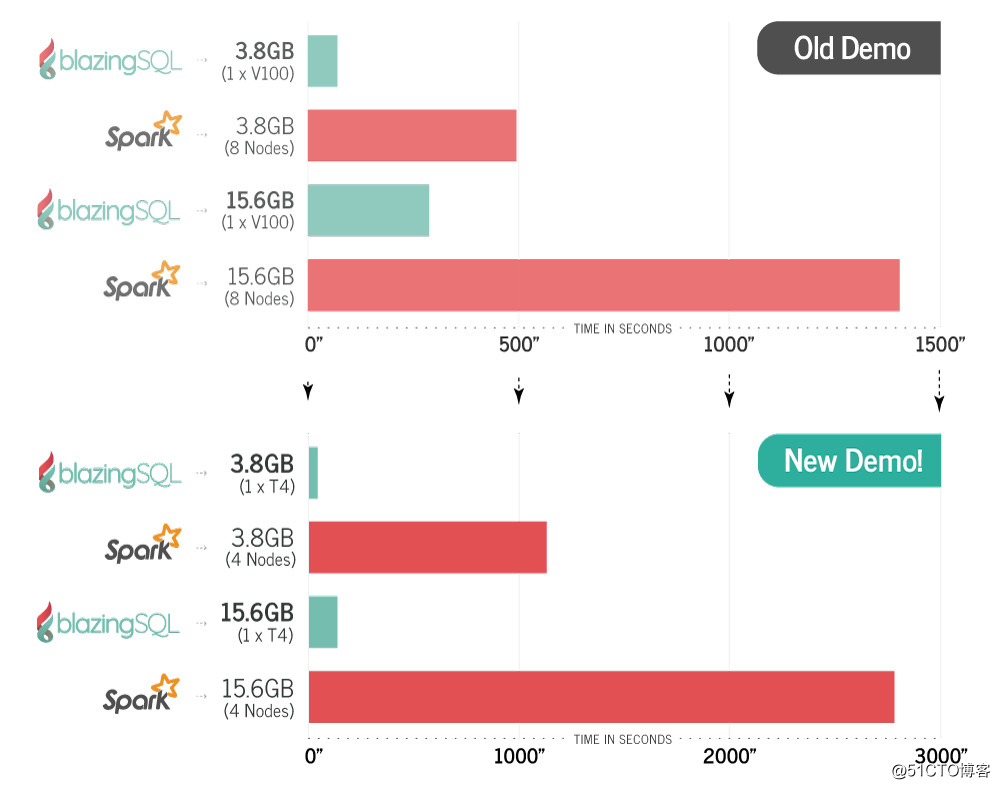
* Конечный результат: BlazingSQL работает в 5 раз быстрее, чем Apache Spark.
* При той же рабочей нагрузке новая версия работает в 20 раз быстрее, чем Apache Spark.
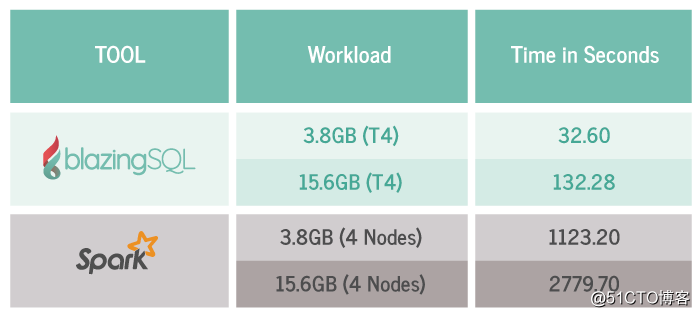
Хорошая лошадь с хорошим седлом
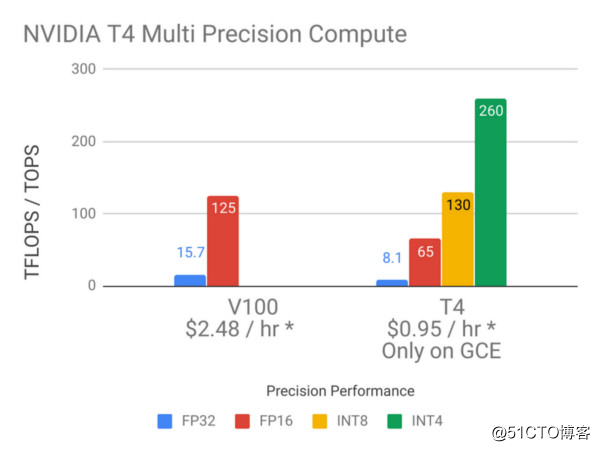
Причина, по которой Blazing SQL может получить эффективные результаты, заключается также в том, что графический процессор GCP T4 используется экстравагантно, это новый графический процессор начального уровня, дешевый, но обладающий высокой производительностью.
Использование нового графического процессора T4 вдвое сократило наши расходы, а для сохранения стабильной цены мы сократили кластер Apache Spark до 4 узлов ЦП.
Но в конечном итоге даже если объем памяти графического процессора будет уменьшен вдвое, общая рабочая нагрузка будет значительно ускорена.
Инженеры Blazing SQL также разработали исполняющее ядро GPU, созданное специально для GPU DataFrames (GDF), которое называется «интерпретатором выражений SIMD».
Для описания интерпретатора выражений SIMD требуется много места.Я просто расскажу здесь некоторые подробности о том, как он работает и почему он дает такое улучшение производительности.
Повышение производительности интерпретатора выражений SIMD в основном происходит за счет следующих ключевых шагов:
-
Машина поддерживает несколько входов. Эти входные данные могут быть столбцами, текстом и функциями GDF.
-
При загрузке этих входов интерпретатор выражений SIMD оптимизирует распределение регистров на графическом процессоре, что увеличивает занятость графического процессора и в конечном итоге улучшает производительность.
- Кроме того, виртуальная машина обрабатывает эти входные данные и одновременно генерирует несколько выходных данных. Например, при выполнении следующего SQL-запроса: SELECT colA + colB * 10, sin (colA) - cos (colD) FROM tableA
Именно благодаря этим усилиям BlazingSQL добился такого большого повышения эффективности.
Бесплатная вычислительная мощность GPU
С праздником фонарей!
Нервная мисс Сестра прислала расчет пособия Фестиваля фонарей!
Наши партнеры-производители проводят внутренние мероприятия по тестированию публичного облака машинного обучения.
В настоящее время открыто 50 мест для внутреннего тестирования, включая время использования CPU и GPU (NVIDIA T4)!
Добавьте WeChat от Miss Nervous Sister (без проверки), чтобы получить код приглашения для регистрации 
Энциклопедия супер нервной системы
Мера сходства
Мера сходства используется для оценки степени сходства между различными выборками и часто используется в качестве критерия для задач классификации.
В машинном обучении и интеллектуальном анализе данных вам нужно знать размер различий между людьми, а затем оценивать сходство и категорию людей.
Наиболее распространенными из них являются корреляционный анализ при анализе данных, алгоритмы классификации и кластеризации при интеллектуальном анализе данных, такие как K ближайших соседей и K средних.
В зависимости от характеристик данных могут использоваться разные методы измерения.
