Предисловие
Текст и изображения в этой статье взяты из Интернета и предназначены только для обучения и общения и не имеют коммерческого использования. Если у вас есть какие-либо вопросы, свяжитесь с нами для обработки.
Содержание преамбулы
Вводное обучение для новичков в Python crawler (2): романы-краулеры
Вводное обучение для начинающих на Python crawler (3): сканирование данных о вторичном жилье Lianjia
Вводное обучение для новичков в Python crawler (4): поиск информации о наборе на 51job.com
Вводное обучение для новичков в Python crawler (5): сканирование заграждения видео станции B
Вводное обучение для новичков в Python crawler (6): создание диаграмм облака слов
Вводное обучение для начинающих Python crawler (7): сканирование видео заграждения Tencent
Вводное обучение для новичков в Python crawler (9): объяснение случая многопоточного краулера
Вводное обучение для начинающих Python crawler (11): недавнее ползание по коже King Glory
Вводное обучение для новичков в Python crawler (12): последнее сканирование кожи League of Legends
Вводное обучение для новичков в Python crawler (16): сканирование красивых видео
Вводное обучение для новичков в Python crawler (17): yy сканирование небольшого видео по всему сайту
Вводное обучение для начинающих искателей Python (19): сканирование IP-прокси, создание пула прокси
Группа по обмену обучением Python: 1039645993
Базовая среда разработки
- Python 3.6
- Pycharm
Использование связанных модулей
import requests
import re
from tqdm import tqdm
import osУстановите Python и добавьте его в переменные среды, pip установит необходимые связанные модули.
Сканер Python, анализ данных, разработка веб-сайтов и другие обучающие видеоролики можно бесплатно смотреть онлайн.
https://space.bilibili.com/523606542 Группа по обмену обучением Python: 1039645993
Определите целевые потребности
Теперь, когда вы выбрали сканирование видео, вы должны отдать приоритет видео с молодой девушкой.

Я все знаю ~
Анализ веб-данных, поиск источников данных
Видео станции A имеет формат m3u8, и все видео разделено на множество небольших сегментов, один сегмент соответствует файлу ts.
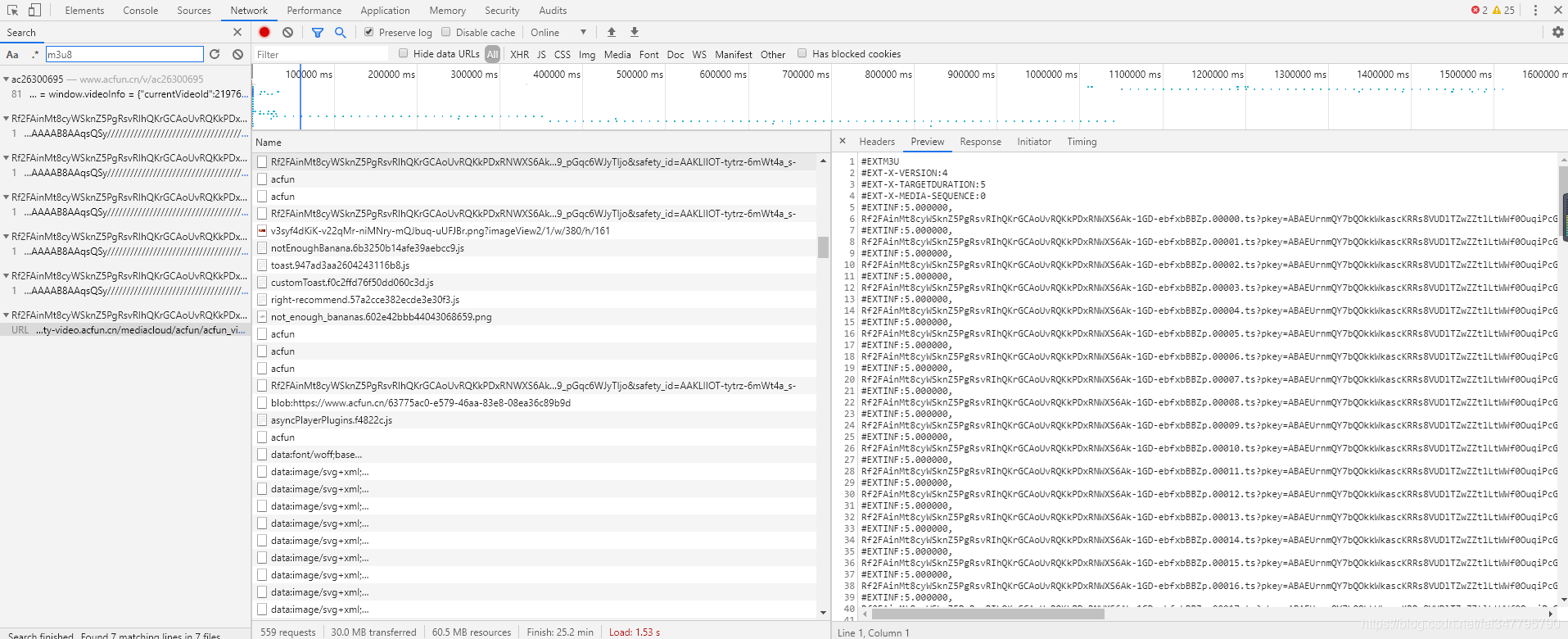
Так что просто найдите источник данных этого m3u8, чтобы получить все файлы ts.

Параметр запроса pkey URL-ссылки изменится. Но этот параметр можно найти в исходном коде веб-страницы. Ссылка для запроса, включающая m3u8, также доступна в исходном коде веб-страницы.

вся идея
1. Запросите адрес видео и получите URL-адрес m3u8 в исходном коде.
2. Запросите адрес m3u8, получите все адреса файлов ts.
3. Сохраните файл ts и объедините файл ts в видеоформат mp4.
Код реализации
import requests
import re
from tqdm import tqdm
import os
def change_title(title):
pattern = re.compile(r"[\/\\\:\*\?\"\<\>\|]") # '/ \ : * ? " < > |'
new_title = re.sub(pattern, "_", title) # 替换为下划线
return new_title
def get_response(html_url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36'
}
response = requests.get(url=html_url, headers=headers)
return response
def save(name, video, title):
path = f'{name}\\'
if not os.path.exists(path):
os.makedirs(path)
with open(path + title + '.ts', mode='wb') as f:
f.write(video)
def get_m3u8_url(html_url):
html_data = get_response(html_url).text
m3u8_url = re.findall('backupUrl(.*?)\"]', html_data)[0].replace('"', '').split('\\')[-2]
title = re.findall('"title":"(.*?)"', html_data)[0]
new_title = change_title(title)
m3u8_data = get_response(m3u8_url).text
m3u8_data = re.sub('#EXTM3U', "", m3u8_data)
m3u8_data = re.sub(r'#EXT-X-VERSION:\d', "", m3u8_data)
m3u8_data = re.sub(r'#EXT-X-TARGETDURATION:\d', "", m3u8_data)
m3u8_data = re.sub(r'#EXT-X-MEDIA-SEQUENCE:\d', "", m3u8_data)
m3u8_data = re.sub(r'#EXT-X-ENDLIST', "", m3u8_data)
m3u8_data = re.sub(r'#EXTINF:\d\.\d,', "", m3u8_data)
m3u8 = m3u8_data.split()
for link in tqdm(m3u8):
ts_url = 'https://tx-safety-video.acfun.cn/mediacloud/acfun/acfun_video/hls/' + link
video = get_response(ts_url).content
ts_title = link.split('?')[0].split('.')[1]
save(new_title, video, ts_title)
print(f'{title}已经下载完成,请验收....')
if __name__ == '__main__':
video_id = input('请输入你要下载的视频ID:')
url = f'https://www.acfun.cn/v/{video_id}'
print('正在下载请稍后.....')
get_m3u8_url(url)
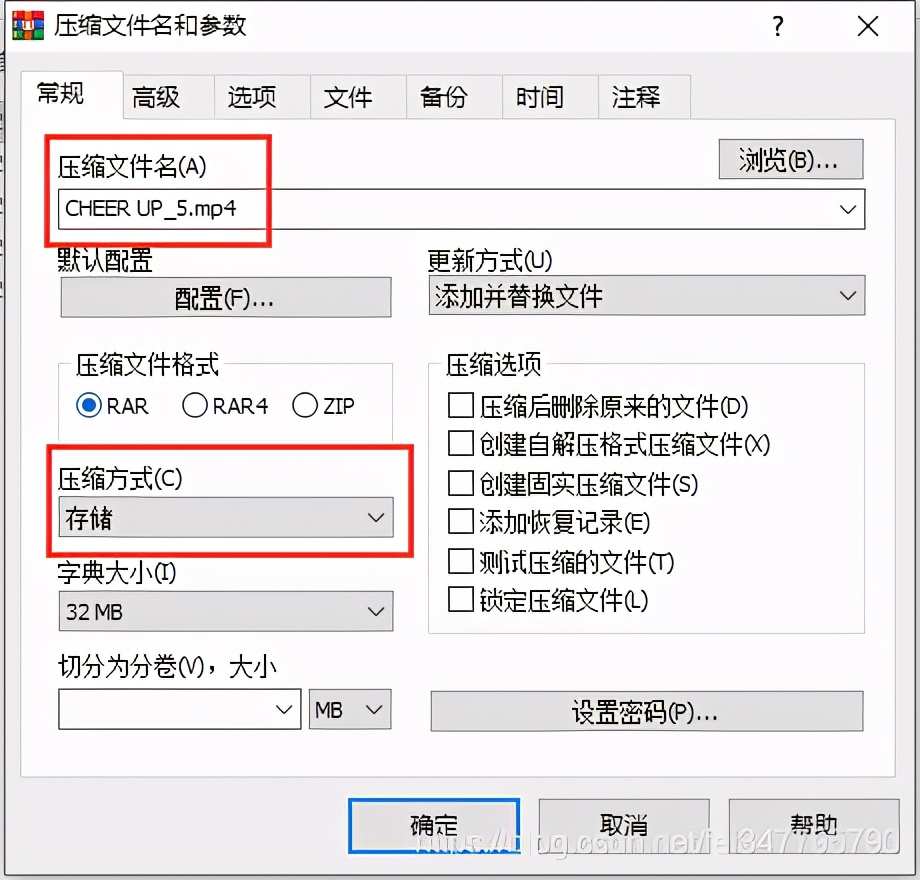
Самый простой способ слиться - руками