Моделирование вознаграждения (RM) и повторная информация
Теги статьи Модель языка данных Подкрепление Обучение Классификация статей jQuery Front-end Development Чтения 254
Моделирование вознаграждения (RM) и обучение с подкреплением на основе отзывов людей (RLHF) для моделей большого языка (LLM) 技术初探
1. Предыстория технологии RLHF
Модель диалога ChatGPT, запущенная OpenAI, запустила новую волну ИИ.Он сталкивается с множеством вопросов и ответов и, похоже, сломал границу между машинами и людьми. За этой работой стоит новая парадигма обучения в области создания большой языковой модели (LLM): RLHF (Reinforcement Learning from Human Feedback), которая оптимизирует языковую модель на основе обратной связи с человеком посредством обучения с подкреплением.
Различные LLM за последние несколько лет впечатляют своей способностью генерировать разнообразный текст на основе запросов, вводимых человеком. Однако оценка сгенерированных результатов субъективна и зависит от контекста , например,
- Мы хотим, чтобы модель генерировала творческую историю
- Фрагмент фактического информационного текста
- исполняемый фрагмент кода
Эти результаты трудно измерить с помощью существующих показателей генерации текста на основе правил, таких как BLEU и ROUGE .
В дополнение к оценочным метрикам существующие модели обычно моделируются путем предсказания следующего слова и простой функции потерь (такой как кросс-энтропия), без явного введения человеческих предпочтений и субъективных мнений .
Чтобы решить вышеуказанные проблемы, не будет ли лучше , если мы будем использовать отзывы людей о сгенерированном тексте в качестве меры производительности или сделать еще один шаг и использовать эти отзывы как потери для оптимизации модели ? В этом и заключается идея RLHF: использовать обучение с подкреплением для прямой оптимизации языковых моделей с обратной связью с человеком .
RLHF позволяет языковым моделям, обученным на общих корпусах текстовых данных, согласовывать сложные человеческие ценности.
2. Разложение технологии RLHF
RLHF — это сложная концепция, включающая несколько моделей и разные этапы обучения.Согласно идее OpenAI, RLHF делится на три этапа:
- Собирайте отзывы людей и предварительно обучайте/настраивайте языковую модель на основе данных, помеченных людьми (пары подсказок-завершений).
- Используйте несколько моделей (может быть начальная модель, модель тонкой настройки, искусственная и т. д.), чтобы дать несколько ответов на один и тот же вопрос, а затем вручную отсортируйте эти пары вопрос-ответ по некоторым критериям (читабельность, безвредность, корректность, блабла), агрегируйте данные вопросов и ответов и обучить модель вознаграждения (Reward Model, RM) для подсчета очков
- Вопрос 1, почему бы не вручную забить напрямую? Поскольку оценка субъективна и требует нормализации, а сортировка вообще у всех будет общий вывод: какой ответ лучше, A или B, для одного и того же вопроса. То, что люди отвечают, — это не стандартный ответ, а предпочтение лучшего ответа, которое представлено в виде ранжирования. На самом деле, не существует стандартного лучшего ответа на большинство вопросов.
- Вопрос 2, с группой частичных заказов (A>B, A>C, C>B), как получить призовые баллы за каждый ответ? На этом шаге используется рейтинговая система Эло из блога Hug. Любой, кто играет в квалификационные матчи онлайн-игр или смотрит футбольные и баскетбольные матчи. Относитесь к каждой частичной последовательности как к соревнованию, а к награде относитесь как к ранжированию.Здесь мы используем Эло, чтобы получить полную сортировку, а затем получаем награду после нормализации.
- Вопрос 3, какую модель использует этот RM? Просто используйте систему Elo для оценки и нормализации, а затем перейдите непосредственно к LM для регрессии.Вы можете тренироваться с нуля или использовать старую LM для точной настройки. Здесь интересно то, что весь текст необходимо вводить как для вопросов и ответов, так и для подсчета очков.На самом деле емкость (или способность понимания) двух моделей должна быть одинаковой, а существующие модели RLHF используют модели двух разных размеров.
- Вопрос 4. Есть ли другой способ обучить модель подсчета очков? Учитель Чжан Цзюньлинь отметил, что прямое использование парного обучения для ранжирования частичных последовательностей, вероятно, больше соответствует общепринятому мышлению, а конкретный эффект зависит от практики.
- Настройте Pretrain LM с помощью обучения с подкреплением (RL) , чтобы получить SFT-LM
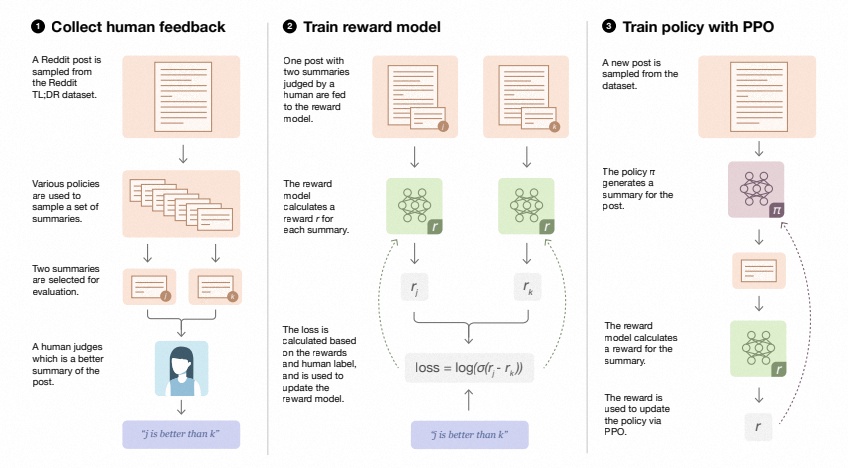
Ссылка на ссылку:
https://zhuanlan.zhihu.com/p/591474085
https://zhuanlan.zhihu.com/p/613315873?utm_id=03. Соберите отзывы людей и предварительно обучите / настройте языковую модель (SFT LLM) на основе данных, помеченных людьми (пары подсказок-завершений по отзывам людей).
Существует две основные категории моделей, которые можно использовать для сбора отзывов людей:
- Pre-training model (Base LLM), то есть модель, только обученная ожидаемой библиотекой без тонкой настройки
- Базовая модель с учителем (SFT LLM), то есть модель, использующая набор тестовых данных, настроенных на основе предварительно обученной модели.
Для результатов, полученных с помощью вышеуказанной модели, специальный исследователь, назначающий ярлыки, проведет относительно хорошую или плохую оценку и, наконец, получит «пары подсказок-завершений по отзывам людей». Затем языковую модель sft можно обучить с помощью классического метода тонкой настройки. Для этого шага модели
- OpenAI использует уменьшенную версию GPT-3 в своей первой популярной модели RLHF, InstructGPT .
- Anthropic использует для обучения модель Transformer с параметрами от 10 до 52 миллиардов.
- DeepMind использует собственную модель с 280 миллиардами параметров Gopher
Этот LM можно настроить здесь с помощью дополнительного текста или условий, например.
- OpenAI точно настраивает «предпочтительный» текст, созданный человеком
- Anthropic выделяет оригинальный LM по контекстуальным подсказкам по критериям «полезный, честный и безвредный».

Обратите внимание, что обучение этому sft-llm — это только отправная точка, затем мы будем обучать модель вознаграждения RM, а затем продолжим обучение этого sft-llm с помощью модели вознаграждения RM.
Когда модель вознаграждения RM участвует в обучении SFT, опыт человеческой тенденции, содержащийся в RM, будет введен в обратную связь SFT , В конечном счете, наша цель - получить высококачественный RLHF-LLM.
4. Модель вознаграждения за обучение (Модель вознаграждения)
Затем мы сгенерируем данные модели вознаграждения за обучение (RM , также называемую моделью предпочтений ) (завершения, соответствующие подсказке) на основе sft-llm, и на этом этапе введем информацию о предпочтениях человека (оценка и ранжирование).
0x1: Зачем нужна модель вознаграждения?
На следующем рисунке показана текущая парадигма разработки технологии GPT для конкретных задач.

В целом, SFT уже может удовлетворить потребности большинства сценариев (что нам нужно сделать, в основном, это очистка данных и дистилляция данных ), но если есть более высокий спрос на качество генерации модели, требуется обучение с подкреплением на основе обратной связи с человеком (RLHF). .
Когда модель SFT уже может генерировать множество ответов в разных стилях, но по таким причинам, как закон, этика, человеческие ценности и требования к задачам в определенных областях, нам нужно направить модель SFT на выбор определенного стиля ответа. Поэтому нам нужен способ предоставить LLM обратную связь, чтобы помочь им понять, что работает, а что нет, чтобы мы могли согласовать их результаты с общепринятыми человеческими ценностями, такими как честность, готовность помочь и безвредность.
Таким образом, нам необходимо обучить модель RM по следующим причинам:
- Хотя базовый SFT-LLM соответствует основным требованиям качества, он все же не полностью соответствует человеческой тенденции ограничивать конкретные задачи, ценности, этику и законы.
- По причинам рабочей нагрузки людям нецелесообразно напрямую предоставлять такую обратную связь во время обучения, поэтому нам нужна модель, которая может имитировать человеческие предпочтения, чтобы обеспечивать вознаграждение при обучении согласованных LLM.
- Будь то настройка модели или ежедневный мониторинг производительности после того, как модель будет подключена к сети, нам нужен автоматизированный стандарт оценки и процесс оценки, чтобы постоянно отслеживать обобщение и снижение модели.
Вышеупомянутое как раз и является целью модели вознаграждения в соответствии с LLM.
0x2: Задача построения модели вознаграждения
- Количество данных обратной связи : создание количества и разнообразия данных обратной связи, необходимых для достаточно точных моделей вознаграждения, является сложной задачей.
- Распределение обратной связи . В идеале мы хотим, чтобы модель вознаграждения точно предсказывала вознаграждение не только для данных, которые видела модель, но и для данных, не входящих в распределение обучающих данных (OOD).
- Игра с вознаграждением : если в функции вознаграждения есть несколько повторяющихся черных дыр, агент может использовать их, чтобы получить больше вознаграждений во время RL, не сходясь к ожидаемому значению.
0x3:Моделирование награды
Тренировка РМ – это начало отличия RLHF от старой парадигмы . Эта модель принимает последовательность текстов (пары подсказок-завершений) и возвращает скалярное вознаграждение (баллы ), численно соответствующее предпочтениям человека.
- Мы можем моделировать с помощью LM сквозным образом.
- Или смоделированная с помощью модульной системы (например, ранжирование вывода, а затем преобразование рейтинга в вознаграждение), это значение вознаграждения будет иметь решающее значение для последующей плавной интеграции в существующие алгоритмы RL.
Что касается выбора модели,
- RM может стать еще одним доработанным LM
- Это также может быть LM, обученный с нуля на данных о предпочтениях.
Например, Anthropic предлагает специальный метод предварительного обучения, который использует предварительное обучение модели предпочтений (PMP) для замены процесса тонкой настройки после общего предварительного обучения . Потому что считается, что первый имеет более высокий коэффициент использования выборочных данных. Но до сих пор не принято решение о том, какой RM лучше.
Что касается обучающего текста, текст пары подсказок (подсказок)-генерации (завершений) RM (пары подсказок-с ) представляет собой расширенный текст, который включает в себя оценку завершений или ранжирование пар завершений после ручной маркировки . Например, как показано на рисунке ниже

Что касается ценности вознаграждения за обучение, необходимо вручную оценивать ответы, сгенерированные SFT-LM.
- Одна из идей — обучать RM непосредственно на оценках текстовых аннотаций , но эти оценки некалиброваны и зашумлены из-за разных значений аннотаторов.
- Другая идея состоит в том, чтобы сравнить выходные данные завершения нескольких моделей для одной и той же подсказки по рейтингу, а затем использовать систему Elo для построения полного рейтинга. Эти разные результаты ранжирования будут нормализованы к скалярному значению вознаграждения за обучение.
Относительно скалярного числа, описывающего качество текста, формула выражается следующим образом:
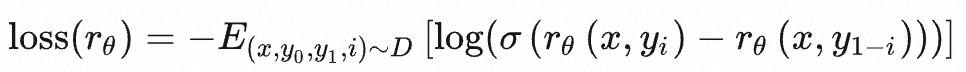
- х означает подсказку
- y означает завершение
- rθ представляет собой балльную оценку модели вознаграждения с параметром θ.
- σ представляет сигмовидную функцию
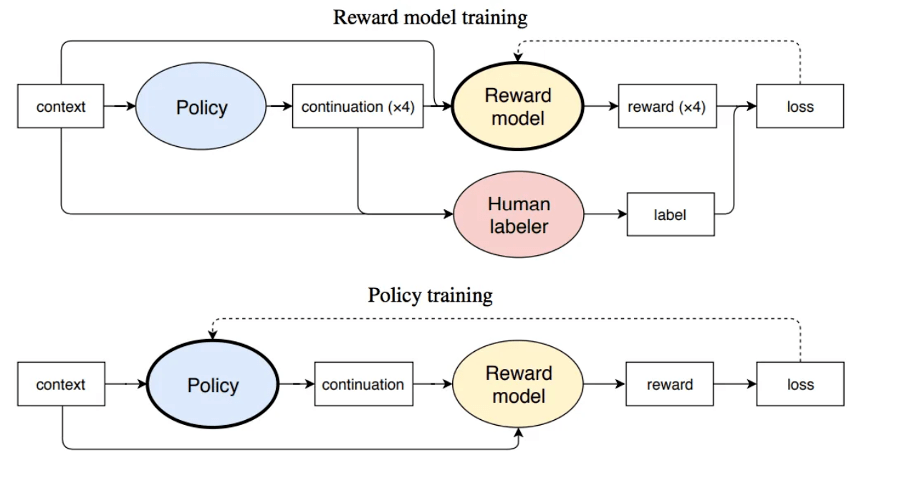
Модель вознаграждения принимает последовательность текста (пара «хорошее или плохое подсказка-выполнение») и возвращает скалярное вознаграждение (баллы), численно соответствующее предпочтениям человека.
Интересным артефактом этого процесса является то, что в настоящее время успешные системы RLHF используют LM разных размеров, чем генеративные модели, например.
- OpenAI использует 175 млрд LM и 6 млрд RM.
- Размер LM и RM, используемых Anthropic, варьируется от 10 до 52 байт.
- DeepMind использует модель 70B Chinchilla как LM и RM соответственно.
Одна интуиция состоит в том, что модели предпочтения и генеративные модели должны иметь одинаковую способность понимать текст, предоставленный им, т. Е. Судьи должны быть такими же способными, как и игроки, чтобы точно оценивать действия игроков.

0x4: Обучение модели политики
Во-первых, задача тонкой настройки исходной языковой модели моделируется как проблема обучения с подкреплением (RL), поэтому необходимо определить основные элементы, такие как политика , пространство действий и функция вознаграждения .
- Стратегия основана на языковой модели, получает на вход подсказку, а затем выводит серию текстов (или вероятностное распределение текстов).
- Пространство действий — это перестановка и комбинация всех токенов в словаре во всех выходных позициях (одна позиция обычно имеет около 50 000 токенов-кандидатов).
- Пространство наблюдения - это возможная последовательность входных токенов (подсказка), которая, очевидно, довольно велика, что представляет собой перестановку и комбинацию всех токенов во всех входных позициях словаря.
- Функция вознаграждения (вознаграждение) рассчитывается на основе модели RM, которую мы обучили ранее, чтобы получить начальное вознаграждение, а затем добавляем элемент ограничения в
Весь процесс выглядит так:
Для алгоритма обучения с подкреплением распространенным возможным решением является использование алгоритма обучения с подкреплением градиента политики (Policy Gradient RL) и проксимальной оптимизации политики (Proximal Policy Optimization, PPO) для точной настройки некоторых или всех параметров исходного LM.
1. Моделирование обучения с подкреплением языковой модели
Установите словарь на
, модель языка , то распределение вероятностей для последовательности длины n может быть выражено как

- поле ввода
- выходное пространство
для ввода
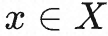
подсказка с возможной длиной 1000 ,

Могут быть пополнения длины 100.
Тогда вероятность завершения y, сгенерированного подсказкой x, может быть выражена как:
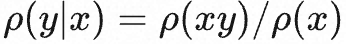
стратегия инициализации
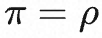
, а затем используйте алгоритм PPO для обновления политики π, функция вознаграждения определяется как r, тогда ожидаемое значение вознаграждения может быть выражено как:

Затем алгоритм PPO оптимизирует этапы расчета функции вознаграждения следующим образом:
- Введите приглашение x в исходный LM и текущий настроенный LM, чтобы получить выходной текст y1, y2 соответственно, и передайте текст из текущей политики в RM, чтобы получить скалярное вознаграждение rθ
- Сравнение сгенерированного текста двух моделей, вычисление штрафного члена за разницу, обычно разработанное как масштабирование расхождения Кульбака-Лейблера (KL) между выходными последовательностями распределения слов, т. Е. Где
- Этот термин используется для наказания политик RL, которые генерируют большие отклонения от исходной модели в каждом обучающем пакете, гарантируя, что модель выводит достаточно связный текст. Если этот штрафной термин будет удален, модель может генерировать искаженный текст во время оптимизации, чтобы обмануть модель вознаграждения, заставив ее предоставлять высокие значения вознаграждения.

Наконец, в соответствии с алгоритмом PPO мы оптимизируем в соответствии с индексом вознаграждения текущего пакета данных (из характеристик алгоритма PPO). Алгоритм PPO представляет собой алгоритм оптимизации области доверия (TRO), который использует ограничения градиента, чтобы гарантировать, что шаг обновления не нарушит стабильность процесса обучения. оптимизировать градиент.
0x5: Общий процесс обучения RM и модели стратегии
- Начиная с Base LLM (например, GTP-3.5, LLaMA, Tongyi Qianwen), собирайте подсказки и ответные ответы (дополнения)
- Посредством ручной обратной связи различные варианты выполнения каждой подсказки сравниваются и ранжируются попарно, что указывает на предпочтения человека в отношении различных ответов (завершений), а попарное ранжирование преобразуется в баллы, соответствующие различным завершениям, с помощью таких алгоритмов, как ELO.
- Обучите модель RM (обычно LLM), введите «пару подсказок-завершений с набором данных меток оценок», чтобы продолжить обучение, и обученная модель RM имеет возможность выводить оценку данной пары подсказок-завершений.
- Обучение модели политики
- Сначала сформулируем задачу тонкой настройки как задачу RL. Во-первых, политика представляет собой LM, который принимает подсказку и возвращает последовательность текстов (или распределение вероятностей текстов). Пространство действия этой стратегии — все токены, соответствующие словарю LM (обычно порядка 50 тыс.), а пространство наблюдения — возможная последовательность входных токенов, которая также относительно велика (словарь ^ количество входных токенов). Функция вознаграждения представляет собой комбинацию модели предпочтений и ограничения изменения политики.
- Функция вознаграждения, определяемая алгоритмом PPO, рассчитывается следующим образом:
- Введите приглашение x в начальный LM и текущий настроенный LM и получите выходной текст y1, yw соответственно.
- Передать текст из текущей политики в RM за скалярное вознаграждение
- Наконец, в соответствии с алгоритмом PPO мы оптимизируем в соответствии с индексом вознаграждения текущего пакета данных (из характеристик алгоритма PPO). Алгоритм PPO — это алгоритм оптимизации доверенной области (TRO), который использует градиентные ограничения, чтобы гарантировать, что шаг обновления не дестабилизирует процесс обучения. DeepMind использует аналогичную настройку вознаграждения для Gopher, но использует алгоритм A2C ( синхронное преимущество актера-критика ) для оптимизации градиента.
- Наконец, получается нейронная сеть RM, которая соответствует человеческим предпочтениям.Далее, награды, выдаваемые RM (баллы за различные завершения), могут использоваться для автоматической фильтрации завершений, которые больше соответствуют человеческим предпочтениям, чтобы постоянно настраивать и оптимизировать SFT-LM
Ссылка на ссылку:
https://karpathy.ai/stateofgpt.pdf
https://zhuanlan.zhihu.com/p/616708590
https://openreview.net/forum?id=10uNUgI5Kl
https://huggingface.co/blog/zh/rlhf
https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons/viewer/CarperAI--openai_summarize_comparisons/train?row=0
https://zhuanlan.zhihu.com/p/450690041
5. Обучите простую модель вознаграждения
Выберите набор данных WebGPT в качестве корпуса модели вознаграждения, как показано ниже, каждое приглашение соответствует списку завершений.
(
'The USA entered World War I because Germany attempted to enlist Mexico as an ally, and for what other reason?',
[
"The United States entered World War I because of Germany's use of submarine warfare against ships in the Atlantic Ocean, which was hurting American exports to Europe. Additionally, Germany tried to enlist Mexico as an ally against the United States, an event which convinced American businessmen and industrialists that the United States should enter the war.",
'The USA entered World War I because Germany attempted to enlist Mexico as an ally and for the Zimmerman Telegram.'
]
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
Набор данных, дополненный отзывами людей, выглядит следующим образом:

Логика обработки для выбора лучшего ответа на отзыв человека из набора данных выглядит следующим образом:
class WebGPT:
name = "openai/webgpt_comparisons"
def __init__(self, split: str = "train"):
super().__init__()
self.split = split
dataset = load_dataset(self.name, split=self.split)
self.dataset_dict = defaultdict(dict)
for item in dataset:
post_id = item["question"]["id"]
if post_id not in self.dataset_dict.keys():
self.dataset_dict[post_id] = {
"full_text": item["question"]["full_text"],
"answers": [],
}
if item["score_0"] > 0:
answers = [item["answer_0"], item["answer_1"]]
elif item["score_0"] < 0:
answers = [item["answer_1"], item["answer_0"]]
else:
answers = []
answers = [re.sub(r"\[\d+\]", "", answer) for answer in answers]
answers = [
".".join([sent.strip() for sent in answer.split(".")])
for answer in answers
]
if answers:
self.dataset_dict[post_id]["answers"].extend(answers)
else:
_ = self.dataset_dict.pop(post_id)
self.post_ids = list(self.dataset_dict.keys())
def __len__(self):
return len(self.post_ids)
def __getitem__(self, idx):
question, answers = self.dataset_dict[self.post_ids[idx]].values()
return question, answers- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
Затем используйте функции обработки, чтобы выполнить дополнительную подготовку данных, например токенизацию и заполнение, перед подачей данных в модель. В зависимости от набора данных количество завершений для каждой подсказки может варьироваться, поэтому я буду поддерживать дополнительную переменную batch_k_lens, чтобы указать количество завершений, доступных для каждой подсказки в пакете. Это поможет нам рассчитать потери.
@dataclass
class RMDataCollator:
tokenizer: PreTrainedTokenizer
max_length: int = 512
def format_example(self, example, eos, prompt=False):
sp_token = SPECIAL_TOKENS["prompter"] if prompt else SPECIAL_TOKENS["assistant"]
return "{}{}{}".format(sp_token, example, eos)
def process_example(self, example):
trunc_len = 0
eos = self.tokenizer.eos_token
prefix, outputs = example
prefix = self.format_example(example, eos, prompt=True)
outputs = [self.format_example(output, eos) for output in outputs]
prefix_tokens = self.tokenizer.encode(prefix)
input_ids, attention_masks = [], []
for output in outputs:
out_tokens = self.tokenizer.encode(
output,
)
if len(prefix_tokens) + len(out_tokens) > self.max_length:
trunc_len = max(
0, len(prefix_tokens) + len(out_tokens) - self.max_length
)
prefix_tokens = prefix_tokens[trunc_len:]
out_tokens = prefix_tokens + out_tokens
out_tokens = out_tokens[: self.max_length]
pad_len = self.max_length - len(out_tokens)
attn_masks = [1] * len(out_tokens) + [0] * pad_len
out_tokens += [self.tokenizer.pad_token_id] * pad_len
input_ids.append(out_tokens)
attention_masks.append(attn_masks)
return input_ids, attention_masks
def __call__(self, examples):
batch_k_lens = [0]
input_ids, attention_masks = [], []
for i, example in enumerate(examples):
inp_ids, attn_masks = self.process_example(example)
input_ids.extend(inp_ids)
attention_masks.extend(attn_masks)
batch_k_lens.append(batch_k_lens[i] + len(inp_ids))
return {
"input_ids": torch.tensor(input_ids),
"attention_mask": torch.tensor(attention_masks),
"k_lens": batch_k_lens,
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
Для архитектуры модели модели вознаграждения есть два варианта:
- Используйте чистую модель кодировщика, такую как BERT, Roberta, и добавьте сверху линейный слой. Подойдет любая модель, поддерживающая AutoModelForSequenceClassification.
- Используйте чистую архитектуру декодера, такую как GPT, и добавьте пользовательский линейный слой поверх. Модель только с декодером более масштабируема. Подойдет любая модель, поддерживающая AutoModelForCausalLM.
На данный момент я выбираю GPTNeoXModel, и я усредняю последний скрытый слой и добавляю пользовательскую головку поверх, чтобы сгенерировать скалярный вывод.
@dataclass
class GPTNeoxRMOuptput(ModelOutput):
"""
Reward Model Output
"""
logits: torch.FloatTensor = None
class GPTNeoXRM(GPTNeoXPreTrainedModel):
""" """
def __init__(
self,
config,
):
super().__init__(config)
self.gpt_neox = GPTNeoXModel(config)
self.out_layer = nn.Linear(config.hidden_size, 1)
def forward(
self,
input_ids,
attention_mask,
**kwargs,
):
return_dict = (
kwargs.get("return_dict")
if kwargs.get("return_dict") is not None
else self.config.use_return_dict
)
outputs = self.gpt_neox(
input_ids,
attention_mask,
return_dict=return_dict,
**kwargs,
)
hidden_states = outputs[0]
if attention_mask is None:
hidden_states = hidden_states.mean(dim=1)
else:
hidden_states = (hidden_states * attention_mask.unsqueeze(-1)).sum(
dim=1
) / attention_mask.sum(dim=1).unsqueeze(-1)
lm_logits = self.out_layer(hidden_states)
if not return_dict:
return (lm_logits,) + outputs[1:]
return GPTNeoxRMOuptput(logits=lm_logits)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
Для функции потерь я буду использовать дополнительный коэффициент нормализации L2, чтобы предотвратить переоснащение. Для k ответов на каждое приглашение ответить на завершение существует

Попарное сравнение.
Потери вычисляются индивидуально для каждой подсказки и усредняются, чтобы получить среднюю потерю партии.
class RMLoss(nn.Module):
""" """
def __init__(
self,
reduction=None,
beta=0.001,
):
super().__init__()
self.reduction = reduction
self.beta = beta
def forward(
self,
logits,
k_lens=None,
):
total_loss = []
indices = list(zip(k_lens[:-1], k_lens[1:]))
for start, end in indices:
combinations = torch.combinations(
torch.arange(start, end, device=logits.device), 2
)
positive = logits[combinations[:, 0]]
negative = logits[combinations[:, 1]]
l2 = 0.5 * (positive**2 + negative**2)
loss = (
-1 * nn.functional.logsigmoid(positive - negative) + self.beta * l2
).mean()
total_loss.append(loss)
total_loss = torch.stack(total_loss)
if self.reduction == "mean":
total_loss = total_loss.mean()
return total_loss
view raw- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
Наконец, мы передадим все это вместе с параметрами обучения специальному тренеру для обучения и оценки нашей модели.
помнить! Наша конечная цель — обучить «арбитра», который представляет тенденцию человеческой обратной связи и может подсчитывать и сортировать быстрые завершения (по сути, осуществлять дистилляцию тренировочного набора).
Как только хороший «арбитр» обучен, развитие LLM SFT может войти в положительный цикл Общий процесс развития выглядит следующим образом:
- Механизм подсказок на основе Base LLM для создания пакета начального набора данных data_v1
- SFT Base LLM на основе исходного набора данных для получения sft-llm_v1
- Пригласите бизнес-экспертов предметной области для маркировки и сортировки исходного набора данных и получения расширенного набора данных data_v2
- На основе расширенного набора данных data_v2 обучите модель вознаграждения, reward_v1
- Механизм подсказок на основе sft-llm_v1, получение нового набора данных для завершения подсказок data_v3
- Отметьте и отсортируйте data_v3 на основе вознаграждения_v1, чтобы получить data_v4
- Пригласите бизнес-экспертов предметной области для маркировки и сортировки data_v4 и получите расширенный набор данных data_v5
- На основе расширенного набора данных data_v5 обучите модель вознаграждения, reward_v2
- Выполните SFT для sft-llm_v1 на основе data_v5, чтобы получить sft-llm_v2.
- .....
- Повторяйте описанные выше шаги и постоянно оптимизируйте модель вознаграждения и sft llm, используя отзывы бизнес-экспертов в данной области.
- Когда производительность модели вознаграждения в основном сравняется с производительностью экспертов-людей, последующее обучение больше не потребует ручного вмешательства, а модель вознаграждения может автоматически подсчитывать и сортировать завершение sft llm, и весь процесс оптимизации обучения будет полностью автоматизированный
Ссылка на ссылку:
https://explodinggradients.com/reward-modeling-for-large-language-models-with-code
https://huggingface.co/datasets/openai/summarize_from_feedback/viewer/axis/test?row=0- 1.
- 2.
6. Изучите полный процесс разработки RLHF на примере rlhf trlx.
Возьмите случай rlhf с trlx в качестве примера, чтобы глубже понять весь процесс.
0x1: холодный запуск с нулевой выборкой
Для разработки большинства LLM для конкретных предметных областей начальный этап проекта в основном начинается с холодного запуска с нулевой выборкой. Поэтому первым шагом задачи-LLM является подготовка данных.
Мы обсудим процесс запуска с нулевой выборкой в двух случаях.
1. Способность базовой большой модели имеет плохую способность к обобщению по отношению к целевой предметной области.
- У вас уже есть хотя бы одна базовая большая модель, вы можете ввести приглашение для создания дополнений
- Обобщающая способность базовой большой модели для целевой предметной области относительно слаба, и сгенерированные дополнения не соответствуют потребностям целевой предметной области.
В этой ситуации нам необходимо использовать такие процессы, как оперативное проектирование, очистка и дистилляция образцов и т. д., и постоянно расширять наши базовые образцы в циклической итерации.
- Шаг 1: быстрое проектирование (быстрое проектирование):
- Используйте Base LLM, чтобы запрашивать образцы семян, а также вручную выбирать и изменять результаты маркировки.
- Перейдите к подэтапу а и постоянно отсеивайте наборы подсказок высокого качества.
- Используйте оптимальный набор команд подсказки для ввода обобщенной базовой модели из тысячи вопросов, чтобы получить «базовый набор данных для завершения подсказки».
- Этап 2: дистилляция пробы (перегонка/очистка пробы)
- Вручную отобрать пробы хорошего качества, отвечающие минимальным требованиям к качеству, из базового набора данных быстрого завершения для очистки проб.
- Вручную корректируйте заполнение образцов с плохим случаем, которые не соответствуют требованиям, чтобы они соответствовали минимальным требованиям к качеству, чтобы гарантировать, что общий размер выборки останется в основном неизменным.
- Процесс дистилляции/очистки пробы можно группировать и постепенно расширять, чтобы постоянно добавлять в модель возможности обобщения. Каждый раунд итераций непрерывно накапливается для получения пакета «очищенных наборов данных о выполнении подсказок» с увеличивающимся числом.
- Шаг 3: sft train (тонкая настройка обучения с самоконтролем)
- На основе «очищенного набора данных о выполнении подсказок» выполняется тонкая настройка на основе Base-LLM и получается доработанная модель sft-llm.
- Шаг 4: разработка модели вознаграждения rm и ручное обучение обратной связи RLHF
- Разработайте и оцените веб-версию, люди могут оценить модель, посмотрев результат модели,
- Отмечайте новые образцы на основе модели тонкой настройки sft-llm, генерируйте более двух завершений для одного и того же приглашения и генерируйте «набор данных sft-prompt-completions».
- Вручную выберите хороший случай и плохой случай, ранжируйте «набор данных sft-prompt-completions», преобразуйте баллы различных завершений через elo, передайте их в модель rm для обучения и получите модель вознаграждения.
- Через ppo train тонко настроить sft-llm и наконец получить RLHF-llm
- Шаг 5: Циклически задействуйте механизм подсказок и процесс RLHF.
- На основе RLHF-llm в качестве базовой модели шага 1
- Переработка для нового раунда быстрой разработки (быстрая разработка)
- Рециркуляция для нового раунда дистилляции пробы (дистилляция/очистка пробы)
- Переработка для нового раунда sft train (тонкая настройка обучения с самоконтролем)
- Переработка для нового раунда разработки модели вознаграждения rm и ручного обучения обратной связи RLHF
- Шаг 6: автоматический RLHF
- Модель вознаграждения можно использовать в качестве механизма автоматической оценки и механизма обратной связи после выхода модели в онлайн.
- Когда производительность rm достаточно хороша (она полностью соответствует опыту искусственной тенденции), степень ручного вмешательства может быть уменьшена, а модель вознаграждения rm может использоваться для помощи sft-модели в постоянной точной настройке цикла. и, наконец, получить модель SOTA-RLHF
2. Способность базовой большой модели может генерировать выборки, которые в основном соответствуют относительной целевой предметной области.
- У вас уже есть хотя бы одна базовая большая модель, вы можете ввести приглашение для создания дополнений
- Базовая большая модель обладает отличной способностью к обобщению для целевой предметной области, а сгенерированные завершения имеют высокое качество для целевой предметной области.
В этом случае стадию перегонки пробы (перегонки/очистки пробы) можно в принципе исключить, а остальные стадии оставить без изменений.
Завершения, созданные базовой большой моделью, в основном соответствуют минимальным требованиям к качеству целевой области задач, и основная работа будет заключаться в разработке расширенной модели вознаграждения и обучении тонкой настройке RLHF.
0x2: Обучение базовой модели SFT
Мы используем " CarperAI/openai_summarize_tldr ", основанный на " EleutherAI/gpt-j-6B " для SFT,

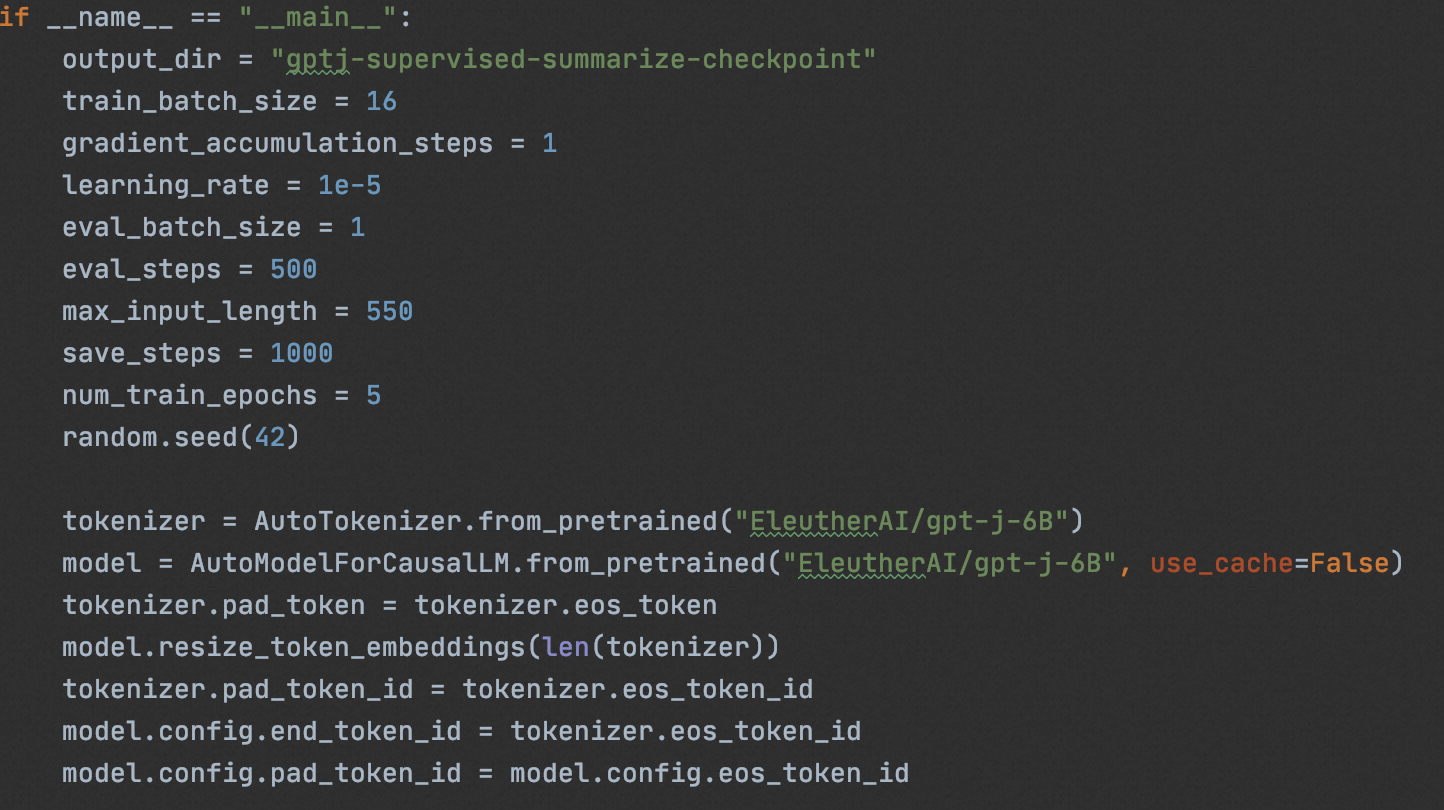

# 单GPU
cd sft/ && CUDA_VISIBLE_DEVICES=0 python3 train_gptj_summarize.py
# 多GPU
cd sft/ && deepspeed train_gptj_summarize.py- 1.
- 2.
- 3.
- 4.
Через sft получается sft-llm, согласованный с задачей суммирования.
0x3: обучение модели вознаграждения (Reward Model)
1. Подготовка набора данных (оценка завершений, ранжирование)
При разработке общего проекта нам необходимо нанять подрядчиков данных или аутсорсеров для сортировки (ранжирования) завершений, созданных методами base-llm, sft-llm и ручными методами. Этот шаг занимает очень много времени, но он очень важен для эффекта конечной модели.

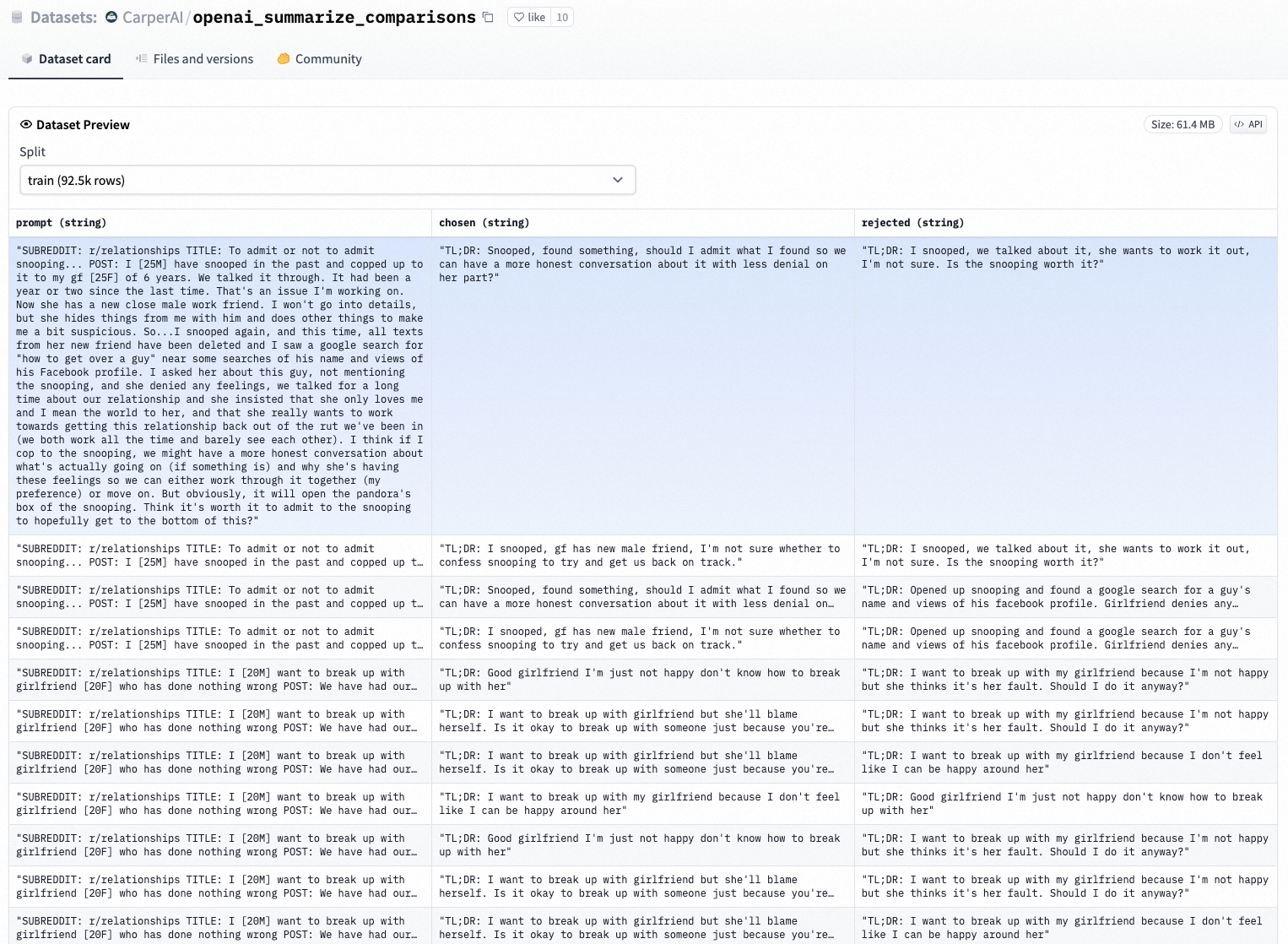
Здесь мы используем файл с открытым исходным кодом « CarperAI/openai_summarize_comparisons » на hugeface для демонстрации.
2. Загрузка и предварительная обработка набора данных Hugface (набор данных о завершении, который завершил ранговую сортировку).
Используя набор данных с открытым исходным кодом , создайте список словарей, каждый с 3 ключами,
- подсказка: оригинальная подсказка
- выбрано: сводка, соответствующая подсказке, помечается вручную как «принятая», что означает, что ранг выше
- отклонено: сводка, соответствующая подсказке, помечается вручную как «отклоненная», что означает более низкий рейтинг.
def create_comparison_dataset(path="CarperAI/openai_summarize_comparisons", split="train"):
dataset = load_dataset(path, split=split)
pairs = []
for sample in tqdm(dataset):
pair = {}
prompt = sample["prompt"]
chosen_summary = sample["chosen"]
rejected_summary = sample["rejected"]
if chosen_summary == rejected_summary:
continue
if len(chosen_summary.split()) < 5 or len(rejected_summary.split()) < 5:
continue
pair["chosen"] = prompt + "\n" + chosen_summary
pair["rejected"] = prompt + "\n" + rejected_summary
pairs.append(pair)
return pairs- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
Сращивание пары приглашение-завершение,
- подсказка+выбрано
- приглашение+отклонено
Для обработанной пары выполните обработку сегментации слов и создайте форму набора обучающих данных.
class PairwiseDataset(Dataset):
def __init__(self, pairs, tokenizer, max_length):
self.chosen_input_ids = []
self.chosen_attn_masks = []
self.rejected_input_ids = []
self.rejected_attn_masks = []
for pair in tqdm(pairs):
chosen, rejected = pair["chosen"], pair["rejected"]
chosen_encodings_dict = tokenizer(
"<|startoftext|>" + chosen + "<|endoftext|>",
truncation=True,
max_length=max_length,
padding="max_length",
return_tensors="pt",
)
rejected_encodings_dict = tokenizer(
"<|startoftext|>" + rejected + "<|endoftext|>",
truncation=True,
max_length=max_length,
padding="max_length",
return_tensors="pt",
)
self.chosen_input_ids.append(chosen_encodings_dict["input_ids"])
self.chosen_attn_masks.append(chosen_encodings_dict["attention_mask"])
self.rejected_input_ids.append(rejected_encodings_dict["input_ids"])
self.rejected_attn_masks.append(rejected_encodings_dict["attention_mask"])
def __len__(self):
return len(self.chosen_input_ids)
def __getitem__(self, idx):
return (
self.chosen_input_ids[idx],
self.chosen_attn_masks[idx],
self.rejected_input_ids[idx],
self.rejected_attn_masks[idx],
)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
Приведенные выше данные неудобно одновременно вводить в модель для обучения, необходимо дополнительно систематизировать данные и построить их в следующем виде:
- input_ids: объедините выбранные и отклоненные input_ids в измерении 0
- Attention_mask: Объедините выбранные и отклоненные из Attention_mask в измерении 0.
- метки: установите для выбранной части значение 0, для отклоненной части значение 1 и объедините размерность 0. Этот шаг завершает цифровую векторизацию метки перемешивания.
Следует отметить, что после вышеуказанной обработки размер партии становится в два раза больше исходного
class DataCollatorReward:
def __call__(self, data):
batch = {}
batch["input_ids"] = torch.cat([f[0] for f in data] + [f[2] for f in data])
batch["attention_mask"] = torch.cat([f[1] for f in data] + [f[3] for f in data])
batch["labels"] = torch.tensor([0] * len(data) + [1] * len(data))
return batch- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
3. Создайте модель вознаграждения
Структура РМ относительно проста, то есть структура трансформатора + головка линейной классификации.
- Преобразователь использует " CarperAI/openai_summarize_tldr_sft " для предварительной подготовки модели llm и замораживает 70% нейронов без тонкой настройки параметров, то есть сохраняет способность оригинального sft-llm понимать текст
- Линейный линейный классификатор, используемый для вывода оценки dim=1, используемый для оценки завершений.
Определите формулу потерь,

- Если модель RM предсказывает, что пара приглашение-завершение выбрано как выбранное, она возвращает 0; если модель RM предсказывает отклонение пары приглашение-завершение, она возвращает 1.
- Цель функции оптимизации потерь состоит в том, чтобы сделать вывод 0/1 RM как можно ближе к 0/1 обучающих данных Чем больше совпадений, тем меньше потеря
class GPTRewardModel(nn.Module):
def __init__(self, model_path):
super().__init__()
model = AutoModelForCausalLM.from_pretrained(model_path)
self.config = model.config
# `gpt-neo(x)` models use `hidden_size` attribute names instead of `n_embd``
self.config.n_embd = self.config.hidden_size if hasattr(self.config, "hidden_size") else self.config.n_embd
self.transformer = model.transformer
self.v_head = nn.Linear(self.config.n_embd, 1, bias=False)
self.tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-j-6B")
self.tokenizer.pad_token = self.tokenizer.eos_token
self.PAD_ID = self.tokenizer(self.tokenizer.pad_token)["input_ids"][0]
def forward(
self,
input_ids=None,
past_key_values=None,
attention_mask=None,
token_type_ids=None,
position_ids=None,
head_mask=None,
inputs_embeds=None,
mc_token_ids=None,
labels=None,
return_dict=False,
output_attentions=False,
output_hidden_states=False,
):
loss = None
transformer_outputs = self.transformer(
input_ids,
past_key_values=past_key_values,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_states = transformer_outputs[0]
rewards = self.v_head(hidden_states).squeeze(-1)
chosen_end_scores = []
rejected_end_scores = []
# Split the inputs and rewards into two parts, chosen and rejected
assert len(input_ids.shape) == 2
bs = input_ids.shape[0] // 2
chosen = input_ids[:bs]
rejected = input_ids[bs:]
chosen_rewards = rewards[:bs]
rejected_rewards = rewards[bs:]
loss = 0
inference = False
for i in range(bs):
if torch.all(torch.eq(chosen[i], rejected[i])).item():
c_inds = (chosen[i] == self.PAD_ID).nonzero()
c_ind = c_inds[0].item() if len(c_inds) > 0 else chosen.shape[1]
chosen_end_scores.append(chosen_rewards[i, c_ind - 1])
inference = True
continue
# Check if there is any padding otherwise take length of sequence
c_inds = (chosen[i] == self.PAD_ID).nonzero()
c_ind = c_inds[0].item() if len(c_inds) > 0 else chosen.shape[1]
r_inds = (rejected[i] == self.PAD_ID).nonzero()
r_ind = r_inds[0].item() if len(r_inds) > 0 else rejected.shape[1]
end_ind = max(c_ind, r_ind)
# Retrieve first index where trajectories diverge
divergence_ind = (chosen[i] != rejected[i]).nonzero()[0]
assert divergence_ind > 0
# Index into the correct rewards
c_truncated_reward = chosen_rewards[i][divergence_ind:end_ind]
r_truncated_reward = rejected_rewards[i][divergence_ind:end_ind]
# Append the last rewards to the list of end scores
chosen_end_scores.append(c_truncated_reward[-1])
rejected_end_scores.append(r_truncated_reward[-1])
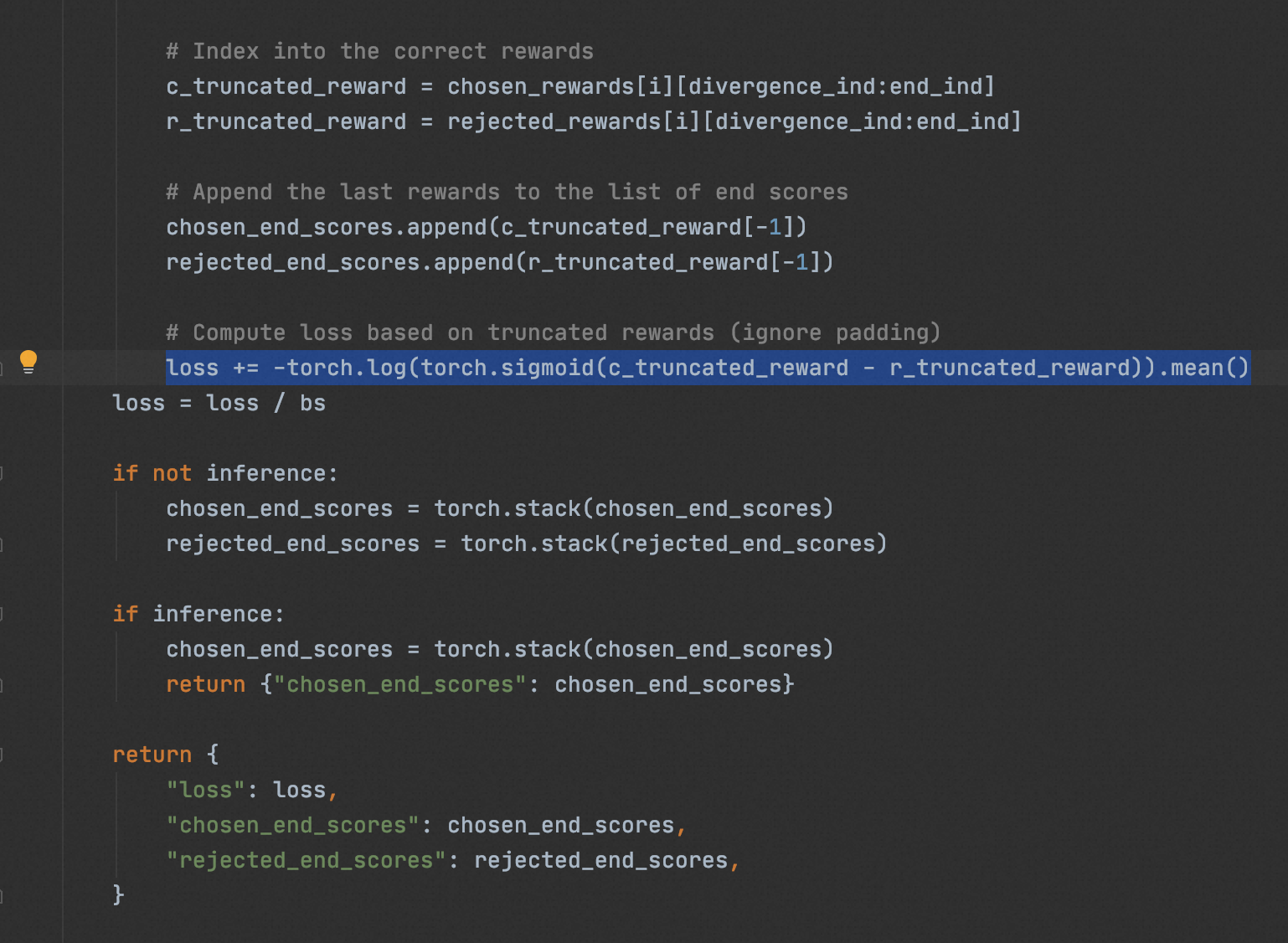
# Compute loss based on truncated rewards (ignore padding)
loss += -torch.log(torch.sigmoid(c_truncated_reward - r_truncated_reward)).mean()
loss = loss / bs
if not inference:
chosen_end_scores = torch.stack(chosen_end_scores)
rejected_end_scores = torch.stack(rejected_end_scores)
if inference:
chosen_end_scores = torch.stack(chosen_end_scores)
return {"chosen_end_scores": chosen_end_scores}
return {
"loss": loss,
"chosen_end_scores": chosen_end_scores,
"rejected_end_scores": rejected_end_scores,
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
- 66.
- 67.
- 68.
- 69.
- 70.
- 71.
- 72.
- 73.
- 74.
- 75.
- 76.
- 77.
- 78.
- 79.
- 80.
- 81.
- 82.
- 83.
- 84.
- 85.
- 86.
- 87.
- 88.
- 89.
- 90.
- 91.
- 92.
- 93.
- 94.
- 95.
- 96.
- 97.
- 98.
- 99.
Комбинируя вышеперечисленные части, вы можете тренировать РМ
# Initialize the reward model from the (supervised) fine-tuned GPT-J
model = GPTRewardModel("CarperAI/openai_summarize_tldr_sft")
# Freeze the first 70% of the hidden layers of the reward model backbone
layers = model.transformer.h
num_layers = len(layers)
num_unfrozen = int(0.3 * num_layers)
for layer in layers[:-num_unfrozen]:
layer.requires_grad_(False)
# Create the comparisons datasets
data_path = "CarperAI/openai_summarize_comparisons"
train_pairs = create_comparison_dataset(data_path, "train")
val_pairs = create_comparison_dataset(data_path, "test")
# Make pairwise datasets for training
max_length = 550
train_dataset = PairwiseDataset(train_pairs, tokenizer, max_length=max_length)
val_dataset = PairwiseDataset(val_pairs, tokenizer, max_length=max_length)
# Create the collator to gather batches of pairwise comparisons
data_collator = DataCollatorReward()
Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
compute_metrics=compute_metrics,
eval_dataset=val_dataset,
data_collator=data_collator,
).train()- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
4. Начните тренировку АД
cd reward_model/ && deepspeed train_reward_model_gptj.py- 1.
Если вы хотите ускорить время, вы также можете напрямую загрузить обученную модель вознаграждения с открытым исходным кодом на огромном лице,
mkdir reward_model/rm_checkpoint
wget https://huggingface.co/CarperAI/openai_summarize_tldr_rm_checkpoint/resolve/main/pytorch_model.bin -O reward_model/rm_checkpoint/pytorch_model.bin- 1.
- 2.


0x4: обучение модели политики (PPO)
Поскольку функция ценности алгоритма PPO может быть моделью глубокого обучения, в данном случае это модель преобразователя, основная идея метода градиента политики состоит в том, чтобы выразить функцию ценности как функцию параметров политики, а затем его можно обновить в соответствии со значением обратной связи RM.
1. Нормализация
Из-за большой дисперсии оценок вознаграждения необходимо сделать разницу на основе искусственных результатов для достижения стандартизации, то есть
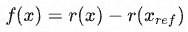
в

обозначают оценку модели и оценку человека соответственно. Код реализован следующим образом:
def reward_fn(samples: List[str]):
# get humans summarizes
posts = [sample.split('TL;DR')] for sample in samples]
ref_samples = [post + 'TL;DR' + post_summ_dict[post] for post in post]
samples_encodings = reward_tokenizer(samples)
samples_scores = reward_model(**samples_encodings) # get scores from reward model for samples
ref_samples_encodings = reward_tokenizer(ref_samples) # get scores from reward model corresponding references samples
ref_samples_scores = reward_model(**ref_samples_encodings)
norms_rewards = samples_scores - ref_samples_scores
return norms_rewards2. Дивергенция КЛ
При использовании PPO для тонкой настройки сводка создается стратегией (LLM). Сгенерированная сводка передается в модель вознаграждения для создания призовых баллов, а затем обновляется стратегия. Поскольку описанные выше операции являются пакетными, а обучение RL очень шумное, особенно на начальном этапе, это может привести к чрезмерному отклонению от политики. Чтобы предотвратить эту проблему, отклонение KL вводится в качестве штрафного условия, чтобы избежать чрезмерного отклонения от модели политики.

в
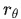
представляет выходной балл модели вознаграждения,
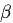
представляет коэффициент,

представляет модель политики,
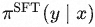
Представляет контролируемую модель.

3. Начните обучение PPO
accelerate launch --config_file configs/default_accelerate_config.yaml trlx_gptj_text_summarization.py- 1.
0x5:Результаты
SFT против PPO
| Модель |
Руж-1 |
Руж-2 |
Красный-L |
Средний |
| СФТ |
0,334 |
0,125 |
0,261 |
0,240 |
| ППО |
0,323 |
0,109 |
0,238 |
0,223 |
РУЖ забивает
| Модель |
Средняя награда |
Награда Δ |
| СФТ |
2,729 |
-0,181 |
| ППО |
3.291 |
+0,411 |
Наградные баллы
Ссылка на ссылку:
https://huggingface.co/datasets/CarperAI/openai_summarize_comparisons/viewer/CarperAI--openai_summarize_comparisons/train?row=0
https://link.zhihu.com/?target=https%3A//github.com/CarperAI/trlx/tree/main/examples/summarize_rlhf
https://github.com/CarperAI/trlx
https://github.com/CarperAI/trlx/tree/main/examples/summarize_rlhf七、RL4LMs — модульная библиотека RL для точной настройки языковых моделей в соответствии с человеческими предпочтениями.
Использованная литература:
https://github.com/allenai/RL4LMs8. Ограничения RLHF и дальнейшая работа
- Эти модели, обученные парадигме RLHF, работают лучше, но все же могут выводить вредный или фактически неточный текст. Это несовершенство является долгосрочной задачей и целью оптимизации RLHF.
- При обучении модели, основанной на парадигме RLHF, стоимость ручной аннотации очень высока , и производительность RLHF может в конечном итоге достичь только уровня знаний аннотатора. Кроме того, ручная маркировка здесь в основном предназначена для маркировки результатов сортировки выходного текста для модели RM, и если вы хотите обучить модель, записывая ответы вручную, стоимость невообразима.На самом деле, для SFT-LLM или For RLHF-LLM, по-настоящему ценная и важная информация — это результат написанных человеком дополнений.
- В процессе RLHF есть еще много областей для улучшения, среди которых особенно важным является улучшение оптимизатора RL . PPO — относительно старый алгоритм RL, основанный на оптимизации области доверия , но другого лучшего алгоритма для оптимизации RLHF не существует.
9. Еще одна парадигма разработки модели вознаграждения
Всего у RM есть два сценария:
- Получает пару подсказок-завершений , дающую числовую оценку (или многомерный числовой вектор , определенный экспертами-людьми)
- Вспомогательный SFT-LLM для обучения с подкреплением
В сценарии 1 на самом деле существует другая парадигма, то есть реализация «цепочки рассуждений о качестве текста в паре подсказка-завершение» путем создания шаблона подсказки. Шаблон подсказки включает следующие элементы:
- ввод пары приглашение-завершение
- определение проблемы
- Критерии оценки Определение
- Вывод результатов оценки (может быть разработан для форматирования)
Пример выглядит следующим образом:
войдите, чтобы скопировать
You are a fair AI assistant for checking the quality of the answers of other two AI assistants.
[Question]
{data['query']}
[The Start of Assistant 1's Answer]
llama chains: {data['llama_chains']}
llama answer: {data['llama_answer']}
[The End of Assistant 1's Answer]
[The Start of Assistant 2's Answer]
chatgpt chains: {data['chatgpt_chains']}
chatgpt answer: {data['chatgpt_answer']}
[The End of Assistant 2's Answer]
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please first judge if the answer is correct based on the question, if an assistant gives a wrong answer, the score should be low.
Please rate the quality, correctness, helpfulness of their responses based on the question.
Each assistant receives an overall score on a scale of 1 to 10, where a higher score indicates better overall performance, your scores should be supported by reasonable reasons.
Please first output a single line containing only two values indicating the scores for Assistant 1 and 2, respectively.
The two scores are separated by a space. In the subsequent line, please provide a comprehensive explanation of your evaluation, avoiding any potential bias, and the order in which the responses were presented does not affect your judgement.
If the two assistants perform equally well, please output the same score for both of them.Воспроизведение 丨 Пекинская конференция Чжиюань 2023 г.
https://2023.baai.ac.cn/schedule
Вышла серия масштабных моделей Zhiyuan «Просвещение 3.0»
https://baai.org/l/27398
Хинтон: отказ от смертных вычислений бессмертия (с видео)
https://baai.org/l/27397
Янн ЛеКун: LLM имеет ограниченные способности к рассуждению и нуждается в переподготовке
https://baai.org/l/27396
Сэм Альтман: Безопасность ИИ начинается с одного шага
https://baai.org/l/27385
Дэвид Хольц: ИИ произведет революцию в обучении, творчестве и организации
https://baai.org/l/27399