1. Как создать индекс
- Способ 1: укажите столбец индекса при создании таблицы
- Способ 2. Создайте индекс с помощью инструкции ALTER TABLE.
- Способ 3: используйте CREATE TABLE для создания индекса
2. Способ просмотра индекса в таблице
- Способ 1: Используйте оператор SHOW INDEX FROM имя таблицы; оператор для просмотра индекса в таблице
нравиться:
- Способ 2: Используйте оператор SHOW CREATE TABLE STUDENT01; для просмотра оператора DDL таблицы, вы можете явно увидеть оператор создания индекса
нравиться:
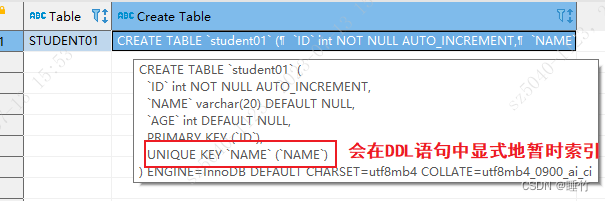
3. Укажите столбец индекса при создании таблицы
3.1 Неявное создание индекса
- К полям, объявленным с ограничениями первичного ключа, уникальными ограничениями и ограничениями внешнего ключа, будут автоматически добавлены связанные индексы.
--创建学生表01,指定ID为主键,此时会自动添加主键索引
CREATE TABLE STUDENT01(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
,AGE INT
)
- Посмотрите на метод индекса 1 в таблице:
--查看当前表的索引
SHOW INDEX FROM STUDENT01;Результаты индекса следующие:
- Посмотрите на метод индекса 2 в таблице:
SHOW CREATE TABLE STUDENT01;Результат выглядит следующим образом:
Примечание. Ограничение внешнего ключа — это ограничение между таблицами, а не индекс.
Случай внешнего ключа:
--案例:
--创建TEACHER01表
CREATE TABLE TEACHER01(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
)
--创建STUDENT18表,ID与TEACHER01表中的ID关联
CREATE TABLE STUDENT18(
ID INT PRIMARY KEY AUTO_INCREMENT
,NAME VARCHAR(20) UNIQUE
,AGE INT
,CONSTRAINT STUDENT18_ID_FK FOREIGN KEY(ID) REFERENCES TEACHER01(ID) --创建外键
)
--查看索引
SHOW INDEX FROM STUDENT18;Результаты индекса в таблице STUDENT18:

3.2 Явное создание индексов
Формат грамматики:
CREATE TABLE имя таблицы (
имя столбца 1 тип столбца 1 ,
имя столбца 2 тип столбца 2 ,
...
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] Имя индекса (имя столбца [длина индекса]) [DESC | AESC]
)
- UNIQUE, FULLTEXT, SPATIAL: необязательные параметры, представляющие уникальный индекс, полнотекстовый индекс и пространственный индекс соответственно.
- ИНДЕКС и КЛЮЧ являются синонимами: оба имеют одну и ту же функцию и используются для указания создания индекса.
- Имя индекса: необязательный параметр, если он опущен, MySQL по умолчанию использует имя столбца в качестве имени индекса.
- Длина индекса: необязательный параметр, длину индекса можно указать только в полях строкового типа.
- ASC/DESC: укажите, хранит ли значение индекса значения в порядке убывания или возрастания.
создать нормальный индекс
--创建学生表02,指定NAME为普通索引
CREATE TABLE STUDENT02(
ID INT
,NAME VARCHAR(20)
,AGE INT
,INDEX idx_name(name)
)
--查看索引
SHOW INDEX FROM STUDENT02;Результаты индексного запроса следующие:

Создайте уникальный индекс (можно добавить несколько нулевых значений)
--创建学生表03,指定ID为唯一索引
CREATE TABLE STUDENT03(
ID INT
,NAME VARCHAR(20)
,AGE INT
,UNIQUE INDEX idx_name(ID)
)Тестовый уникальный индекс:
--给STUDENT03表插入3条数据
INSERT INTO STUDENT03(id,name,age)
VALUES(1,'张三',18);
INSERT INTO STUDENT03(id,name,age)
VALUES(null,'张三',18);
INSERT INTO STUDENT03(id,name,age)
VALUES(null,'张三',18);
--查看所有数据
SELECT * FROM STUDENT03;Результат выглядит следующим образом:

Резюме: уникальный индекс не может повторно вставлять одни и те же данные, но можно добавить несколько нулевых значений.
Создать индекс первичного ключа
- Индекс первичного ключа создается с помощью ограничения первичного ключа, что является способом неявного создания индекса.
Отбросьте индекс первичного ключа:
ALTER TABLE 表名 DROP PRIMARY KEY;Примечание. Если первичный ключ является автоинкрементным, вам необходимо сначала удалить автоинкремент, а затем удалить первичный ключ.
Создать совместный индекс
--创建学生表04,指定NAME、AGE和SCORE为联合索引
CREATE TABLE STUDENT04(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
,INDEX idx_name_age(NAME,AGE,SCORE)
);
--查看索引
SHOW INDEX FROM STUDENT04;Результат выглядит следующим образом:

Уведомление:
- Так как при создании индекса поля располагаются в следующем порядке: ИМЯ, ВОЗРАСТ, БАЛЛ, порядок построения дерева B+ также упорядочивается сначала по ИМЕНИ, затем по ВОЗРАСТУ и, наконец, по БАЛЛУ.
- Принцип крайнего левого префикса: если вы хотите использовать объединенный индекс, если в условии where нет имени крайнего левого поля, то индекс не будет работать.
Мы можем использовать ключевое слово EXPLAIN test:
- Тест 1: все поля в объединенном индексе включены в условие where
--EXPLAIN 测试索引,where条件中使用了NAME,AGE,SCORE
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND AGE = 18
AND SCORE = 85В результате получается следующее: В приведенном выше операторе SQL используется индекс

- Тест 2: промежуточное поле AGE в объединенном индексе не включено в условие where
--EXPLAIN 测试索引,where条件中使用了NAME,SCORE,没有使用中间的字段AGE
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND SCORE = 85В результате получается следующее: В приведенном выше операторе SQL используется индекс

- Тест 3. Условие where не включает имя крайнего левого поля в объединенный индекс
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
AGE = 18
AND SCORE = 85Результат выглядит следующим образом: индекс приведенного выше оператора SQL недействителен.

- Тест 4. Создайте уникальный индекс для самого левого имени поля и проверьте, следует ли использовать индекс с одним столбцом или совместный индекс.
Примечание. Этот тест должен убедиться, что данные существуют в таблице, иначе эффект не будет виден!
--给STUDENT04表插入3条数据
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'张三',18,85);
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'李四',18,85);
INSERT INTO STUDENT04(id,name,age,score)
VALUES(1,'王五',18,85);
--测试索引执行情况
EXPLAIN
SELECT
*
FROM STUDENT04
WHERE
NAME = '张三'
AND AGE = 18
AND SCORE = 85В результате получается следующее: Оператор SQL использует уникальный индекс вместо общего индекса.

Сводка по использованию комбинированного индекса
- Следуйте принципу крайнего левого префикса: когда крайнее левое поле объединенного индекса не используется в условии where, индекс не будет выполнен.
По принципу построения дерева B+: записи данных в узле сортируются сначала по крайнему левому полю, а затем сортируются по порядку других полей в индексе, поэтому, если крайнее левое поле не используется как условие в где, то первоначальная сортировка (запись) записей данных узла дерева B+ не используется, и отсортированные позже поля не будут действовать, что приведет к сбою индекса
- Порядок полей в условии where не влияет на совместный индекс
- В условии where, пока используется крайнее левое поле, совместный индекс вступит в силу
- Когда в таблице есть несколько индексов для перехода, какой индекс будет выбран в соответствии со стоимостью запроса оптимизатора.
4. После создания таблицы используйте команду ALTER TABLE для добавления индексов.
грамматика:
ALTER TABLE имя таблицы ADD [тип индекса] INDEX имя индекса (имя поля);
- Имя индекса можно не указывать
- [Тип индекса]: можно опустить, опущение - это нормальный индекс, если указан тип индекса, то ИНДЕКС тоже можно опустить
нравиться:
CREATE TABLE STUDENT05(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
);
--给STUDENT05表SCORE字段创建普通索引
ALTER TABLE STUDENT05 ADD INDEX (score);
--给STUDENT05表NAME字段创建唯一索引
ALTER TABLE STUDENT05 ADD UNIQUE IDX_NAME(NAME);
--给STUDENT05表NAME,AGE,SCORE字段创建联合索引
ALTER TABLE STUDENT05 ADD INDEX IDX_NAME_AGE_SCORE(NAME,AGE,SCORE);5. После создания таблицы используйте CREATE INDEX, чтобы добавить индекс
грамматика:
CREATE [тип индекса] INDEX имя индекса ON имя таблицы (имя поля);
- Тип индекса можно не указывать
- Имя индекса нельзя опустить
- Ключевое слово INDEX нельзя опускать.
нравиться:
CREATE TABLE STUDENT06(
ID INT
,NAME VARCHAR(20)
,AGE INT
,SCORE decimal
);
--给STUDENT06表SCORE字段创建普通索引
CREATE INDEX idx_score ON STUDENT06(SCORE);
--给STUDENT06表NAME字段创建唯一索引
CREATE UNIQUE INDEX idx_name ON STUDENT06(NAME);
--给STUDENT05表NAME,AGE,SCORE字段创建联合索引
CREATE UNIQUE INDEX IDX_NAME_AGE_SCORE ON STUDENT06(NAME,AGE,SCORE);6. Разница между методом ALTER TABLE и методом CREATE INDEX
- При создании неординарного индекса в режиме ALTER ключевое слово INDEX можно опустить, но в режиме CREATE INDEX опустить нельзя.
- Метод ALTER не требует указания имени индекса, а имя поля используется в качестве имени индекса по умолчанию, а метод C REATE не может опускать имя индекса.
7. Удалить индекс
Сценарий удаления индекса:
- Количество табличных индексов велико, когда требуется большое количество добавлений, удалений и изменений, можно сначала удалить индексы, а потом уже данные.
Способ 1:
ALTER TABLE имя таблицы DROP имя индекса;
Способ 2:
DROP INDEX имя индекса ON имя таблицы;
Уведомление:
- Когда поле одностолбцового индекса удаляется, индекс будет автоматически удален
- Когда поле совместного индекса удаляется, совместный индекс автоматически удалит поле
8. Убывающий индекс
- Индексы хранят значения ключей в порядке возрастания по умолчанию
- О синтаксисе MySQL. Синтаксис нисходящего индекса поддерживается с версии 4.0, но фактически определение DESC игнорируется.
- Версия MySQL8.0 стала действительно поддерживать нисходящий индекс (поддерживается только InnoDB)
Восходящий индекс, созданный MySQL до версии 8.0, по-прежнему используется для обратного сканирования, что значительно снижает эффективность базы данных.
В некоторых сценариях нисходящие индексы имеют большое значение. Например:
Если запросу необходимо отсортировать несколько столбцов, а требования к порядку несовместимы, то использование нисходящего индекса позволит базе данных не использовать дополнительные операции сортировки файлов , тем самым повысив производительность.
случай:
1> В MySQL8 при создании таблицы создайте совместный индекс и укажите a в порядке возрастания и b в порядке убывания в индексе
CREATE TABLE STUDENT07(
a INT
,b INT
,INDEX IDX_A_B(a ASC,b DESC)
);2> Вставьте 799 фрагментов смоделированных данных, используя хранимые процедуры.
-- 创建存储过程
DELIMITER //
CREATE PROCEDURE STUDENT07_insert()
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i<800
DO
insert into STUDENT07 select rand()*80000,rand()*80000;
SET i=i+1;
END WHILE;
commit;
END //
DELIMITER ;
-- 调用存储过程
CALL STUDENT07_insert();3> Тест с использованием нисходящего индекса
EXPLAIN SELECT * FROM STUDENT07 ORDER BY a,b DESC LIMIT 5;Результат: это доказывает, что сортировка использует индекс, и производительность хорошая.

4> Удалите указанный выше совместный индекс, создайте новый совместный индекс, a по возрастанию, b также по возрастанию (имитируя версии ниже MySQL8)
-- 删除原来的索引
DROP INDEX IDX_A_B ON STUDENT07;
-- 创建新的联合索引,a升序,b也升序(模拟MySQL8以下的版本)
CREATE INDEX IDX_A_B ON STUDENT07(a,b); --默认就是升序的5> тест не использует нисходящий индекс
EXPLAIN SELECT * FROM STUDENT07 ORDER BY a,b DESC LIMIT 5;Результат: использованная файловая сортировка (файловая сортировка, плохая производительность)
