Автор: Конфуций усилия
https://www.cnblogs.com/yanshw/p/10735079.html
При оценке модели, вы можете выбрать различные индикаторы, но разные индикаторы могут давать разные результаты, как выбрать правильные показатели, в зависимости от требований к необходимости миссии.
Точность и ошибки ставки
Правильная скорость : количество образцов правильно классифицировано / общее количество образцов, точность
Частота повторения ошибок : число выборок неправильно классифицирован / общее число проб, ошибок
коэффициент ошибок Точность = 1 +
Оба показателя простой и наиболее распространенный
недостаток
Обобщение не обязательно модель реакции, такие, как проблема дисбаланса класса.
Мы не можем удовлетворить потребности всех задач
Если автомобиль арбузы, задача: выбрать хороший арбуз, сколько на самом деле хорошо дыня, Вторая задача: Все хорошо дыню, сколько было выделено, по-видимому, правильные и ошибки ставки не могут решить эту проблему.
Точность и отзыв
Во-первых, чтобы получить знать несколько концепций
Положительные образцы / п-кортеж: целевые кортежи, кортежи интереса
Отрицательные образцы / отрицательный кортеж: другие кортежи
Для бинарной классификации, модель прогнозирования можно разделить на: реальные случаи TP, ложноположительные случаи FP, правда отрицательных случаев TN, ложные отрицательные случаи FN,
Реальные дела на самом деле положительные, прогноз является положительным, а другие так же, как
Очевидно, что ТР + ФП + TN + FN = общее количество образцов
Путаница матрица
Разделение четырех видов замешательства матрицы используется для представления
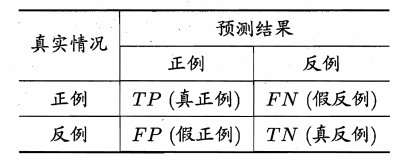
Таким образом, сделать следующие понятия
Точность : насколько актуальный прогноз положителен в положительном, точность, точность, также известный как
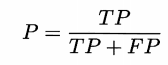
Напомним : во сколько позитивный прогноз положительный, напомним , на самом деле, также известный как отзывом
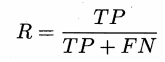
Точность и отзыв является мерой противоречию. Как правило, высокая точность, скорость вспомнить низкий, и наоборот.
Такие, как арбуз или автомобиль, я надеюсь, что все хорошо дыня избран как это возможно, если я надену все бахчевые избраны, естественно все хорошо дыня избраны, все из которых должны быть признаны как хорошие дыни дынь, на этот раз низкая точность и скорость напомним, составляет 100%.
Если я хочу, чтобы выбрать дыни арбузы хороши, то он должен быть осторожным, и не хотел бы голосовать, не может быть неправильный выбор, который требует положительного прогноза должны быть реальные случаи, когда точность 100% ставка отзыв Это может быть низким.
Обратите внимание, что я сказал, вероятно, будет низкой, если образец, как правило, хорошие моменты, такие, как назначаются на весь положительный, отрицательный, отрицательный полный назначенный, и что точность, отношение отозвание 100%, не противоречат друг другу.
кривая PR
Так как противоречие, что отношения между ними должны быть такими, как показано ниже
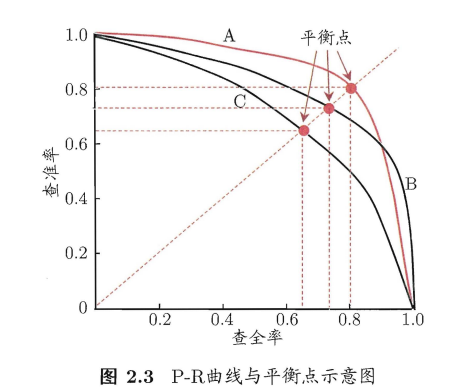
Эта кривая называется кривой PR, точность - кривая отзыва.
Эта кривая, как извлечь из него? Это можно понять, если я получить образец в некотором роде есть вероятность положительных примеров (такие как использование моделей для прогнозирования всех образцов), а затем образец сортируется по вероятности, от высокого к низкому
Если первая модель прогнозирования является положительным, отрицательным прогностическим отдых, в это время была точность, напомним близко к 0,
Если модель предсказала спереди два положительных, отрицательное предсказание остального, на этот раз немного снижаются точность, напомнит несколько увеличились,
Turn ...
Если образец модели, за исключением последнего прогноза является положительным, окончательный прогноз отрицательный, точность очень низкая, проверьте полный курс очень высок.
В этот момент я зашифровать данные, вытянутые карты остается такой же, как на карте.
Так как точность и припоминания конфликтующих, который был использован в качестве индекса оценки это? Или одновременно с два индекса модели оценки, как это?
В обоих случаях
Если PR обучения кривых А полностью «обертка» обучаемый PR кривой С, производительность лучше, чем C
Если кривая PR PR обучения кривой B является Учащийся пересекаются, то трудно судить, какой из них лучше, это обычная практика в это время, фиксированная точность, напомним сравнение отношения, фиксированный или отзыв, точность компаратор ставка.
Кривая пересекутся в нормальных условиях, но люди все еще хотят поставить два учащихся, чем на один уровень из, разумный подход, чтобы сравнить два область PR под кривой.
Но эта область не является хорошим расчетом, поэтому он разработал ряд другой с учетом точности вспомнить, как, вместо расчета площади.
Остаток: Point Break-события, упоминается как НЭП, дело в том, чтобы выбрать точность = напомним, т.е. фиг, Y = X прямой линии пересечения кривой и PR.
Этот метод жесток
F1 и Fβ мера
Более распространенным способом является измерение F1
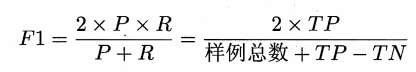
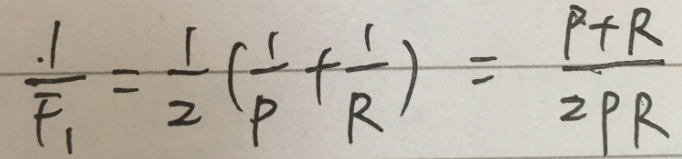
Т.е., F1, является Р и гармонического среднего.
По сравнению с средним арифметическим и геометрическим средним, гармоническим средним большого упором на меньшем значении.
В некоторых приложениях, акцент на точности и вспомнить разные.
Такие, как системы рекомендаций продукта, чтобы избежать преследований клиентов, в надежде, что рекомендуемое содержание представляет интерес для клиентов, точность является более важной в настоящее время,
Другим примером является система запроса данных, для того, чтобы не пропустить полезную информацию, в надежде получить на всю информацию, а затем вызвать более важное значение.
В этом случае необходимость в точности и взвешенной проверки полной скорости
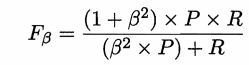

То есть, R и Р взвешенного гармонического среднего.
β> 0, & beta; меры, напомним о важности точности, β = 1, когда F1 является
β> 1, напомним, что более важно, β <, точность является более важным 1
Multi-классификация F1
多分类没有正例负例之说,那么可以转化为多个二分类,即多个混淆矩阵,在这多个混淆矩阵上综合考虑查准率和查全率,即多分类的F1
方法1
直接在每个混淆矩阵上计算出查准率和查全率,再求平均,这样得到“宏查准率”,“宏查全率”和“宏F1”

方法2
把混淆矩阵中对应元素相加求平均,即 TP 的平均,TN 的平均,等,再计算查准率、查全率、F1,这样得到“微查准率”,“微查全率”和“微F1”
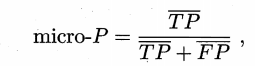
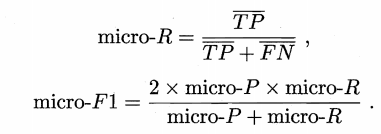
ROC 与 AUC
很多学习器是为样本生成一个概率,然后和设定阈值进行比较,大于阈值为正例,小于为负例,如逻辑回归。
而模型的优劣取决于两点:
这个概率的计算准确与否
阈值的设定
我们把计算出的概率按从大到小排序,然后在某个点划分开,这个点就是阈值,可以根据实际任务需求来确定这个阈值,比如更重视查准率,则阈值设大点,若更重视查全率,则阈值设小点,
这里体现了同一模型的优化,
不同的模型计算出的概率是不一样的,也就是说样本按概率排序时顺序不同,那切分时自然可能分到不同的类,
这里体现了不同模型之间的差异,
所以ROC可以用来模型优化和模型选择,理论上讲 P-R曲线也可以。
ROC曲线的绘制方法与P-R曲线类似,不再赘述,结果如下图

横坐标为假正例率,纵坐标为真正例率,曲线下的面积叫 AUC
如何评价模型呢?
若学习器A的ROC曲线能包住学习器B的ROC曲线,则A优于B
若学习器A的ROC曲线与学习器B的ROC曲线相交,则难以比较孰优孰劣,此时可以比较AUC的大小
总结
模型评估主要考虑两种场景:类别均衡,类别不均衡
模型评估必须考虑实际任务需求
P-R 曲线和 ROC曲线可以用于模型选择
ROC曲线可以用于模型优化
参考资料:
周志华《机器学习》
本文由博客一文多发平台 OpenWrite 发布!