0 Внимание резюме фона
кодер-декодер
Эта часть фона от этого: https://blog.csdn.net/u012968002/article/details/78867203 Эта статья объясняет внимание хорошо.
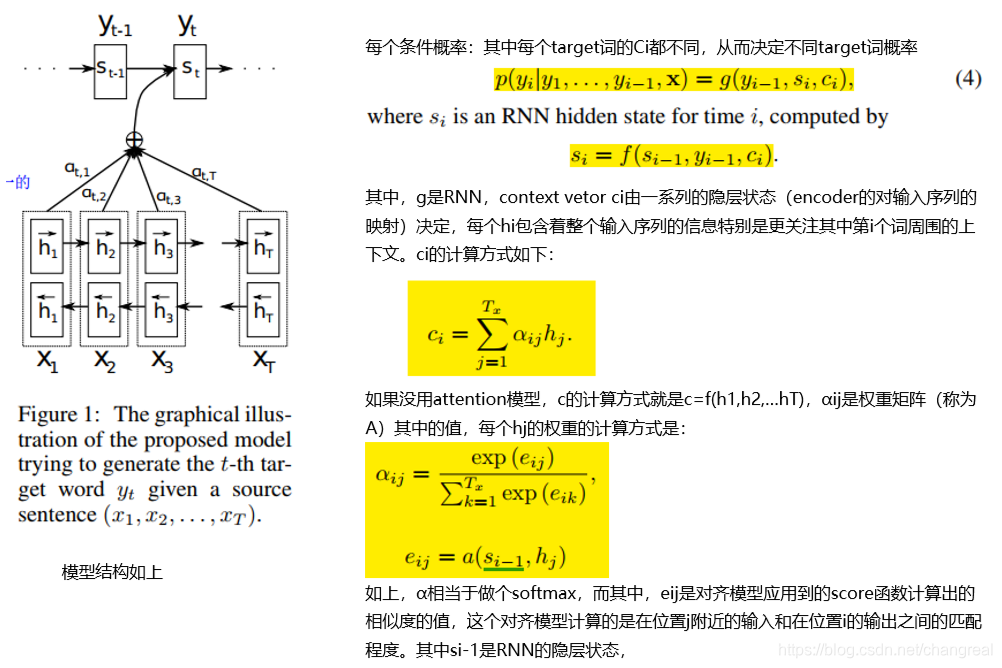
кодер-декодер, вход предложение преобразуется нелинейным преобразованием выражается в виде промежуточных семантики C для декодера Decoder, его задача состоит в том, чтобы представить семантику предложения C Источник и промежуточного ранее генерируемой информации предыстории y1, y2 ...... уг -1 время генерации я хочу , чтобы генерировать слово уга, то yi=g(C, y1, y2,...yi-1)каждый уг генерируется последовательно так, по- видимому, является целью всей системы , генерируемой исходное предложение целевого в соответствии с входным предложением.
如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;
如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;
如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。
В области обработки текста, кодировщик-декодер широкого диапазона применений.
Кодер-декодер кадр широко используется не только в области текста, он часто используется в распознавании речи, обработки изображений и других областях. Как правило, распознавание речи и обработка текста, как правило , используются модель кодировщика РННА, изображение обработки кодировщика CNN обычно используется модель.
0,1 расширить свои собственные
0.1.1 внимание Категория Описание
-
мягкое внимание
软寻址,指的不像一般寻址只从存储内容里面找出一条内容,而是可能从每个Key地址都会取出内容,取出内容的重要性根据Query和Key的相似性来决定。 之后对Value进行加权求和,这样就可以取出最终的Value值,也即Attention值。 本论文用的就是soft-attention -
трудно внимание
(后面看论文了再补过来。好像比较难,因为不能用反向传播) -
самостоятельно внимание
指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。 其具体计算过程是一样的,只是计算对象发生了变化而已。Само внимание может захватить смысловые или синтаксические особенности между объектами в одном слове в предложении. Введение Внимание Само легче охарактеризовать взаимозависимые захвата предложение междугородние .
Однако Само внимание будет направлять любые два слов предложений в процессе вычисления с помощью линии , непосредственно связанного шага вычисления, расстояния в зависимости от расстояния между объектами значительно сокращаются, способствуют эффективному использованию этих возможностей. Кроме того , в дополнении, Self Внимание для увеличенной вычислительной параллелизм имеет прямую помощь. Это основная причина , почему все больше и больше внимания самостоятельной широко используется. -
coattention (позже суммированы дополнение)
-
Все виды внимания трансформатора также дополняют будущее
0.1.2 внимание истории развития
Внимание НЛП:
функция Внимание Сущность может быть описана в виде запроса (запроса) к ряду (значение ключа Key- значения) карты, как показано ниже. Трансформатор является типичным к \ д \ у.
На самом деле, эта цифра ниже , отражает суть идеи Attention механизма ( в основном письменного Внимание это резюме механизм в машинном переводе и отражает основную идею кодера-декодера, характер механизма мышления внимание вырезаны из рамок кодер-декодер и далее абстрагировать, на Рисунок очевидно, особое внимание будет суммировать следующий, а затем заполнить)
в расчете внимания можно разделить на три этапа:
1. 第一步是将query和每个key进行相似度计算得到权重,常用的相似度函数有点积,拼接,感知机等;
2. 然后第二步一般是使用一个softmax函数对这些权重进行归一化;
3. 最后将权重和相应的键值value进行加权求和得到最后的attention。目前在NLP研究中,key和value常常都是同一个,即key=value。
1 обзорные статьи и инновации
Эта статья с механизмом Внимания (мягкое внимание), чтобы завершить задачу машинного перевода, рассматриваемый механизм внимания в первом применении НЛПА в очень поучительно.
Традиционный РНН кодер-декодер недостатки:
1. 对长句子的处理不好(梯度消失)
2. 词对齐问题
НМТ потолок с бумагой нарушил модель Кодер-декодер - РНН генерируется фиксированной длиной вектором предложения C записывается весь информационный режим. Это комбинированное обучение выравнивания и перевода , это просто последовательность ввода в вектор, и адаптивно выбирать подмножество векторов при декодировании перевода. Это позволяет модели лучше работать с длинными предложениями.
В данной работе, когда генерируются модель для генерации слова в переводе , когда он (мягкий) поиском исходного предложения наиболее релевантной информации централизована место, а затем, на основе модели , связанную с расположением контекста фразы исходного вектора и произведенные до Все целевые слова предсказать целевое слово.
внимание и интерес исходного предложения , чтобы быть выходным слово у более соответствующий раздел (вход путем генерации двойного РНН скрытого Н, то хранить эти скрытые вниз состояние, чтобы сосредоточить больше внимания соответствующим взвешивания таким образом , генерируя скрытый слой C).
И механизмы внимания могут выравнивать решить проблему (вопрос документы должны быть приведены в соответствии центровки модели, традиционный статистический машинный перевод , как правило , в процессе выполнения действия будет иметь специальную фразу выровненные, и внимание на то модель является таким же эффектом.).
В целом, бумага не трудно изучить механизмы , внимание стоит начинать.
1.1 Внимание ключ Определение
- В целом применение в естественном языке модели обработки Внимание будет рассматриваться как соответствие выходной модели целевой предложении слова в предложении и каждое слово на входе Source. Это основная идея данной статьи.
- Генерация состояний стороны мишени, все векторы контекста будут использоваться в качестве входных данных.
- Внимание основной точка является переводом каждого целевого слова (или предсказать название товарного текст Категории) используется в контексте отличается, это соображение, очевидно, более разумным.
- Механизм Внимание Источник Значение является взвешенной суммой элементов
- В данной статье внимание наших задач активных требований и целей самой концепции, в то же время применения. Внимание часто определяется как степень корреляции назначения и источника. Но есть много задач, в то же время не имеет понятия источника и цели. Например, классификация документов, только оригинал, а не целевой язык / эссе, а затем, как анализ настроений (также можно рассматривать как простейший вид классификации документа), только оригинал. Так что в этом случае внимание, как запустить его? Это требует разнообразных методов, называемых внутри внимания (или само-внимания), как следует из названия, это сосредоточиться на своем собственном внутреннем механизме оригинала.
- Источник и место назначения
(1) классификация, контекст векторных и исходные предложения определены в модели
(2) имеет два входа, например, QA, как источник и цель
(3) самостоятельно внимание, источник и цель являются их собственные, которые могут быть получены Некоторые данные конфигурации, такие как информация относится к
В большинстве работ, внимание Вектор является весом (обычно SoftMax выход), который размерность равна длине контекста. Чем важнее, тем больше веса соответствующей позиции от имени контекста.
Выше в этой статье, https://blog.csdn.net/fkyyly/article/details/82492433
1,3 Другие
Бумага имеет общую структуру: би-РНН, выравнивание модели. Использование: Метод совместного выравнивания и перевод обучения.
Будущие области для улучшения являются: Для ряда необычных слов или обучения слова корпуса не появляется , как лучшее представление. Это позволяет более механизм внимания в целях улучшения.
2 Совместите обучение и перевод
Общая структура:
- Кодер: быть-РНН
- docoder: эмулирует поиск через исходное предложение при docoding трансляционного (имитируются поиск при декодировании перевода исходного предложения)
2,1 Декодер: Универсальный Описание
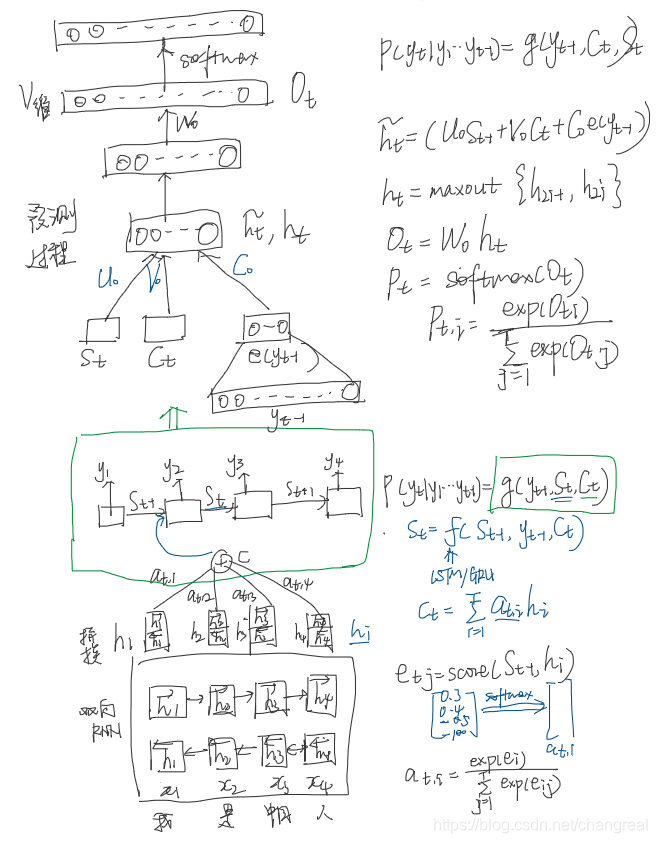
А описание структуры следующим образом:
Ci постоянно меняется в зависимости от текущего слова поколения. Например:
где функция f2 представляет вход кодера английских слов функцию преобразования, если используется модель кодера РНН (например, может google2016年底翻译系统用кодер и декодер используют LSTM 8 слоев), результат этой функции f2 часто время конкретного после состояния входного значения скрытых узлов XI, G представляет собой кодировщик представитель синтетического промежуточной функции преобразования всего предложение семантического представление промежуточных слов, в общей практике, например , является функцией взвешенной суммы составляющих элементов.

Tx是句子source的长度。
αij代表在Target输出第i个单词时Source输入句子中第j个单词的注意力分配系数
hj则是Source输入句子中第j个单词的语义编码
Там также упоминается Alignment модель , я понимаю , что рассчитывает степень соответствия для входных позиций и выходных позиций I J модель, соответствующая информация содержится в функции бальной (е балл вычисляется здесь является функцией модели) являются следующие несколько способов:
1. 点积 dot
2. 双线性函数 general
3. 拼接 concat
3. 隐层的MLP(感知机)(本文用这种) perceptron
Здесь я прикрепил два Боуэн ( https://blog.csdn.net/changdejie/article/details/90782040 , https://www.cnblogs.com/robert-dlut/p/8638283.html см) несколько функции подобия вычисляется:
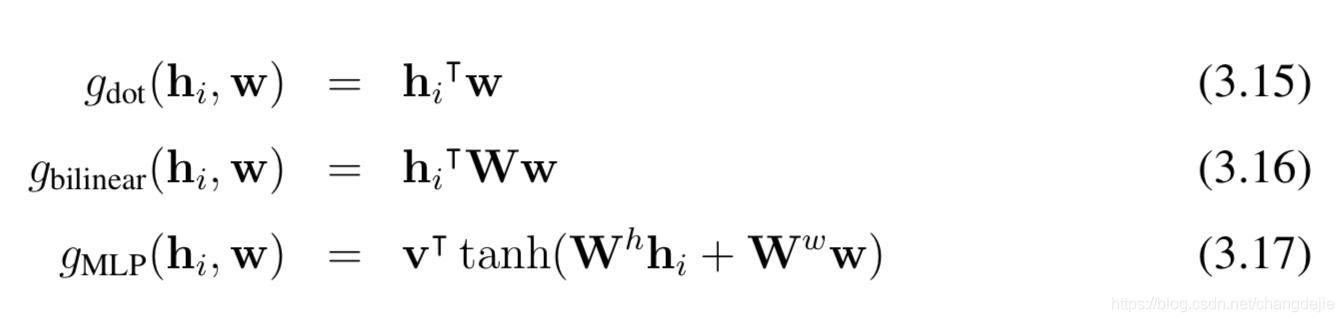
? Как видно из рисунка, запроса ключа, значение в запросе, от имени? Представители ключа? Представители стоимости? См Часть II суммирует внимание
2.1.2 Расчет распределения вероятностей Права весовой матрицы
Декодер для использования РНН есть, во время я, если слово будет генерироваться угом, мы можем знать время перед генерацией мишени уга I-1, в момент времени, выхода я-1 скрытого значение узла слоя Привет-1 (бумага СИ-1).
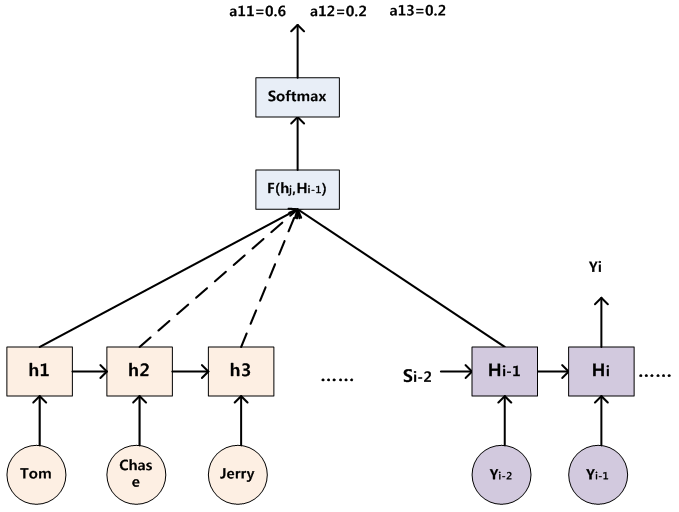
Наша цель состоит в том, чтобы вычислить вход для генерации YI слов в предложении «Томь», «Чейз», «Джерри» распределение внимания для уг является распределение вероятностей, она может быть скрыта выходной слой предложение я-1 раз с Target состояние Привет-1 (Si-1) по сравнению с одиннадцатью Hj (HJ перед каждым накапливается), то есть, с помощью функции F. (HJ и РННЫ скрытых состояний узла каждого слова в предложении ввода соответствующего источника, Hi- 1) - диссертации: Eij = (Si-1, привет) , чтобы получить целевое слово выровнена возможность уг , соответствующий каждое входное слово.
Функция F может принимать различные подходы в разных работах, а затем выводит функцию F Softmax нормированных привлечь внимание распределения вероятностей интервала значений распределения вероятностей в соответствии с распределением значений.
То есть, для каждого уг, можно получить распределение вероятностей на подобии каждого исходного слова! (Потому что это распределение вероятностей, так нормировать)
распределение вероятностей многих! Вероятность каждого слова , соответствующее генерируемое целевое предложение слова в предложении ввода выровненного распределения вероятностей будет иметь в виде , что входное слово генерируется и целевое предложение слова
Модель выравнивания параметрироваться как предуправления нейронной сети, прямое вычислением мягким выровнено, так что она может быть использована для вычисления функции затрат на распространение, в результате чего получает параметры, может быть использован градиент для выравнивания совместной модели обучения и весь перевода.
2.2 кодер: для последовательностей с использованием Bi-РНН
Использование двухсторонняя РНН снова concate прибудет HJ, HJ сосредоточиться на информацию XJ вокруг, так что не только подвести итоги предыдущего HJ слова может подвести слово обратно.
Краткое описание последовательности декодер используется и модель выравнивания, для расчета контекста vecotr.
2.3 Структура Выбор
Выше общая структура, такие, как функция активации F РНН модель, его модель, а, может быть свободно выбран. В этой статье дается конкретный выбор из следующих вариантов:
2.3.1 РНН
РНН: закрытый скрытые блок (сброс ворот + обновление ворот), с логистической сигмовидной функцией активации
На каждом шаге декодера, одного слоя maxout единиц + нормализуют для подсчета выходных вероятностей
2.3.2 Выравнивание Модель
Выравнивание модель, чтобы принять во внимание модель для вычисления длины Tx * Ty Tx и Ty являются необходимость вторичного предложения, с тем чтобы уменьшить объем вычислений, в MLP многослойный перцептрон. MLP веса в процессе обучения, чтобы прийти.
Эксперимент 3
-
数据集: конкатенация Новости-тест-
2012 и новости тест-2013 , чтобы сделать развития (проверки) набор, и оценить модели на тестовом
наборе (Новости-тест-2014) от ВМТ '14, который состоит из 3003 предложений нет присутствует в обучающих
данных.
мы используем список из 30000 наиболее часто встречающихся слов в каждом языке , чтобы
обучать наши модели. Любое слово не входит в шорт - лист отображается в специальный знак ([UNK]). -
Модель: обучение RNNsearch-30 \ RNNsearch-50 производительность модели:
- Передние и обратные RNNsearch РНН 1000 имеет скрытые блоки, многослойная сеть с одним скрытым слоем maxout для вычисления условной вероятности, каждое целевое слово.
- SGD + Adadelta для обучения модели, minibach предложение 80, пять дней обучения
- После хорошей модели обучения с поиском луча, чтобы найти максимально возможный перевод
4 результатов
Результаты Рисунок 4.1
评估: BLEU socre
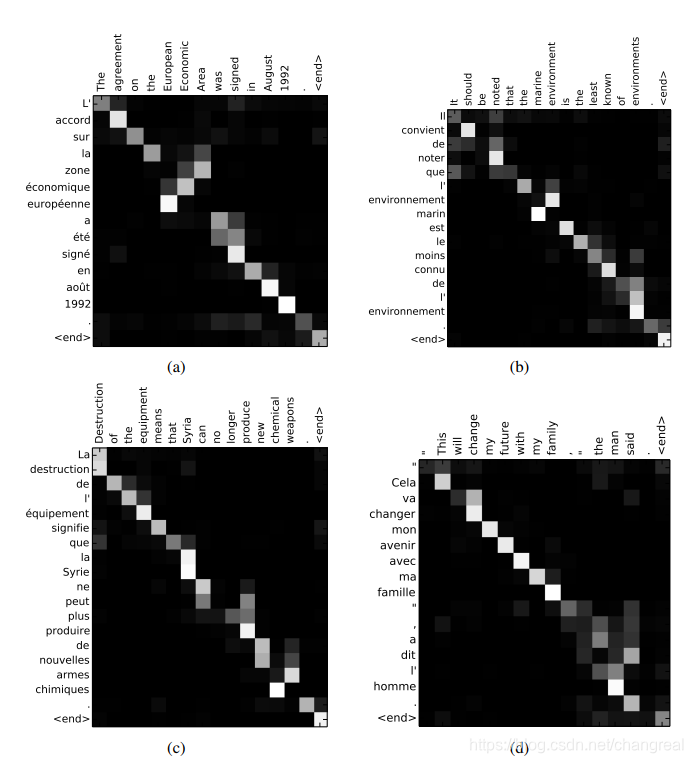
Это делается путем визуализации аннотаций
веса. Из этого мы видим , какие позиции в исходном предложении были более важны при создании целевого слова.
RNNsearch-30 и RNNsearch-50 являются более устойчивыми к длине sentences.RNNsearch-50, в особенности, не показывает ухудшения производительности , даже с предложениями длиной 50 или более.
4.2 Анализ результатов
4.2.1 Выравнивание
По сравнению с жестким выравниванием, мягкое выравнивание перевода будет более полезным. Поскольку Soft-Alignment решает эту Наш выпуск Естественно Позволяя на обоих AT-модели внешний вид [в] и [человек].
Преимуществ Soft-Alignment:
1.关注多个part从而找出正确翻译
2.处理不同长度的句子
5 резюме
拓展了基础的кодер-декодер,让模型(программно) поиск набора входных слов, или их аннотации вычисляются посредством кодера, при генерации целевого слова.
Это позволяет модельное внимание только на информации , относящейся к генерации следующего целевого слова. модель может правильно выравнивать каждое целевое слово с соответствующими словами, или их аннотацией.
Будущие задачи:
- Лучше обработка неизвестных или редких слов
需要 模型 модель будет 更 широко используется, чтобы соответствовать производительности современных систем машинного перевода внедренный во всех контекстах.
