非结构化建模的挑战
主要介绍非结构化对内存要求大,速度慢。而结构化相对好很多。主要例子,a影响b ,b影响c,非结构化的处理的话,还需要处理a影响c的情况,结构化不需要。
使用图描述模型结构
主要分为有向图和无向图,有向图又叫信念网络或贝叶斯网络。就像前面介绍的那样可以减少很多参数,适用于因果关系。
无向图又称马尔科夫随机场(MRF)或马尔科夫网络。
这里介绍了配分函数:配置分母的函数,让所有可能性之和为1。后面会有专门的章节介绍。
能量函数:所有概率不为0,通过指数运算可得。
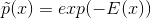
通常基于能量的模型也被称为玻尔兹曼机。rbm
分离和d-分离,分别存在于无向图和有向图。当两个变量集中间存在可观察变量时,并且不存在直连时,两个变量集就是分离的。
无向图和有向图可以相互转换,无向图转换为有向图时,通过一个拓扑排序,而后每个变量集针对后面所有的变量集都有一个指向其的链接。
因子图:无向图中添加一层方块区域,表达函数的作用于,解决无向图中表达的模糊性。如图

从图模型中采样
原始采样:按照拓扑的顺序采样。多个拓扑图时,任意一个顺序都可。但是只适用于有向图。无向图采样较复杂,使用Gibbs采样,下一章有介绍,较复杂。
结构化建模的优势
就是简化流程,将现有知识和知识的学习分开。
学习依赖关系
潜变量:无法被观察到的变量。
推断潜在变量的常用方法:
1、隐马尔可夫模型;
2、因子分析;
3、主成分分析;
4、偏最小二乘回归;
5、潜在语义分析和概率潜在语义分析;
6、EM算法。
就是学习潜变量,以及介绍潜变量的好处,高效表示。
推断和近似推断
具体介绍将在第十九章。就是深度学习可以应用于推断。
结构化概率模型的深度学习方法
深度学习的潜变量主要通过自主学习,而非人工设定。
