Unit1_task1
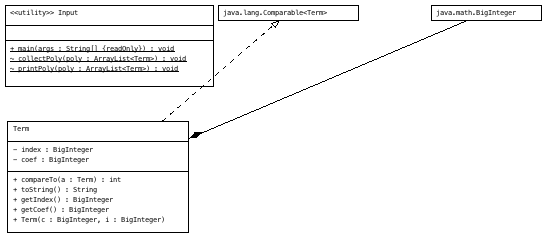
这次作业较为简单,我直接使用正则表达式对项进行分割,再依次提取每个项的系数与次数,用一个二元组来存储数据,最后将二元组按
次数高低排序,最后将相邻的项合并(这里我没有使用HashMap,是因为对HashMap的操作还不熟悉)。其中collectpoly方法是用于化
简最终表达式,printPoly方法用于Term的输出,CompareTo方法则是为了实现Term类的Comparable接口,以便于使用Collections.sort
进行排序,toString方法则是printPoly方法的主要部分,用于单项向字符串的转换。
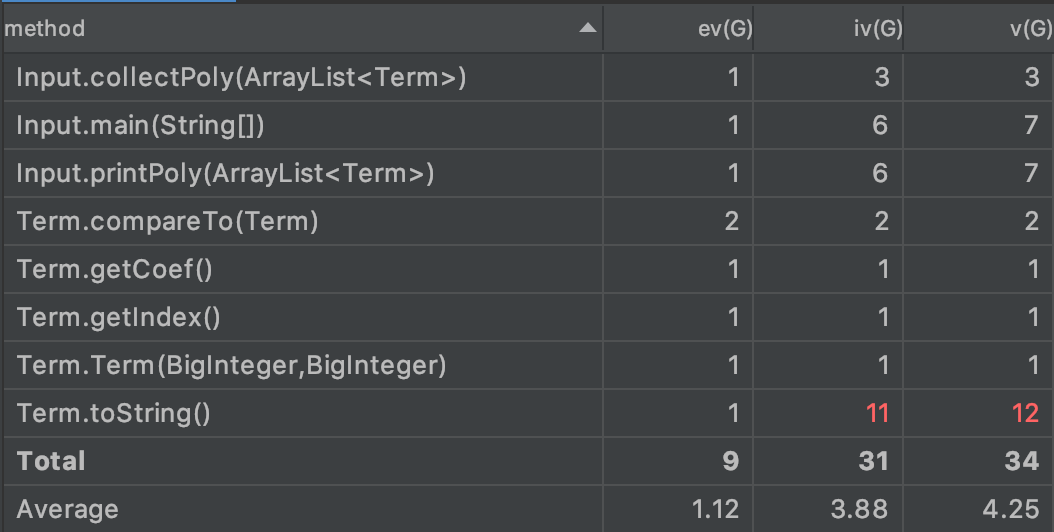
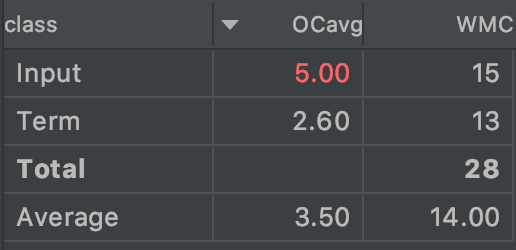
但是Input类的operation complexity还是偏高,主要是由于将太多的功能和表达式处理写在了Input里面,思维仍旧没能脱离面向过程编程
,导致我在处理具体情境时,不是靠创建相应的类来处理,而是靠创建相应的Method和function来处理,也导致类的复杂度较高。
Unit1_task2
f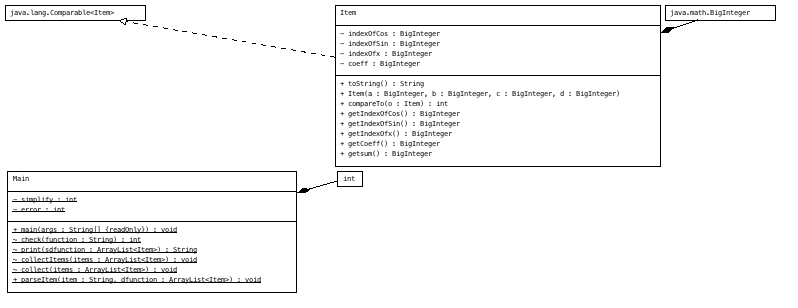

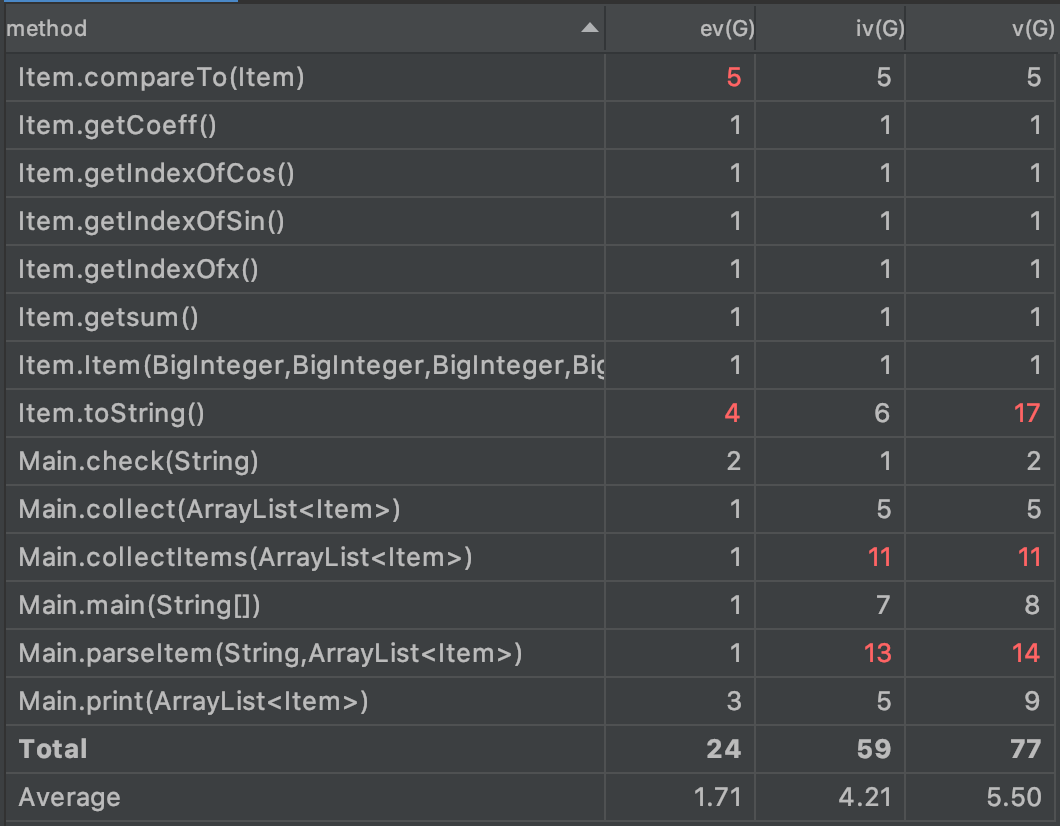
第二次作业在求导表达式中增加了三角函数,但和第一次作业没有本质区别,我直接在第一次的代码基础上,将存储数据的Term类从二元
组改成了四元组,仍旧使用Arraylist来存储多个四元组,这一次不使用HashMap则是由于这里的value是三元数,不像task1直接是一个整数,
这就导致需要二级HashMap,较为不方便。这一次的时间主要花在了Format的识别上,经过考虑,我直接使用了一个大正则和捕获组,来
直接获取所需要的每一项次数和系数。
其中相较于task1所新增的方法有check方法和parseItem方法,check方法用于检查是否格式正确,parseItem方法的新增则是由于这一次使
用的是大正则来解析,采用了指导书的形式化表述,代码更加复杂,所以将这个功能从main方法中单独抽出。
这里看到我的collectItems和parseItem方法的设计复杂度和圈复杂度都较高,这是因为我将求导和化简均放在了collectItems中实现,没有
做到一个方法对应一个功能。
考虑到第三次作业涉及到递归求导,并且不能再取巧使用多元组来存储数据,我私下又重写了一遍task2,这一次的求导采用的是递归函数的
方法(仍旧没有摆脱面向过程的思维方式),实现起来出奇的简单,于是对第三次作业便有了些底气(然并卵)。
Unit1_task3


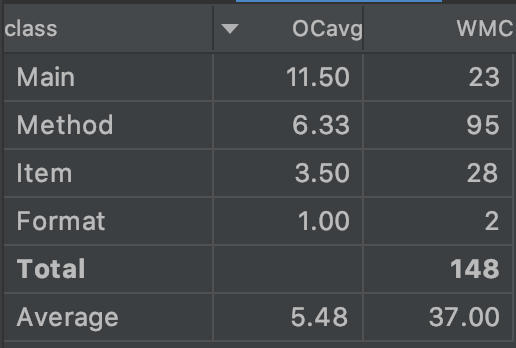
第三次作业允许表达式因子的嵌套,这导致大正则不能再使用,于是第一个摆在面前的就是格式问题,而格式问题也是我在此次作业中遇到
最棘手的问题。由于允许表达式嵌套括号,无法再使用大正则来解析格式,我只能采用最原始的方法,边读边判断。add方法用于实现两个
表达式的“+”连接,mult方法则是用于实现两个表达式之间的“*”连接,用以综合有一个表达式为0或1或null的情况,check方法是针对于简
单表达式化简时,先检查其是否符合某个较为简单的格式,如果符合则进行化简(是的,这里我只对形似taks2的表达式进行了部分的化简),
checkbrackets方法是用于检查表达式中的括号逻辑是否合法,以防止在判断表达式因子的时候出现误判,其他的函数都同task2中的作用。
这次的复杂度主要出现在diffsin和diffcos这两个函数上,因为我无法单独将格式判断问题解耦合出来,所以只能将格式判断糅合在求导之中,
将表达式层层剥开,到最后再判断是否属于基本项,否,则return null。
由于在task2中我便考虑到了task3的扩展,所以在求导规则上并没有太大的问题,但谁又能想到task3最麻烦的不是求导,而是一层又一层的
括号嵌套导致的格式解析难题呢?我果然还是太年轻了。
这次最大的失误在于判断格式的方法,我应该从正反两个方面来综合判断,而不是光想着如何构造正确格式来进行筛选,而忽略了利用错误格
式来进行排除,这导致我在格式的判断上出现了巨大失误,导致重复编写代码,代码复用率低,Method的复杂度也较高。
S2:自我bug分析与bug发掘方法
在task1和task2阶段,在中强测和互测中都未出现什么bug,bug集中爆发在task3,上面在分析程序结构的时候也提到了,在task3中导致我的
代码复杂度直线上升的便是格式的判断,并且由于格式判断的复杂性以及与其他方法的高耦合,导致我在这上面出了较大的问题,一些应当判定
为WRONG FORMAT的我没有识别出来,而一些应当正确解析的,我又认定为WRONG FORMAT,于是在中强测和互测中都被找出了bug。总结
一下,原因有二,一是没有将格式判断模块单独提取出来,导致代码复用率低,修改也较为的麻烦;二是格式识别与其他功能的耦合度太高,导
导各个格式识别的应用场景都出现了问题。
再一个则是bug的发掘。我一般是先根据我自己在处理时遇到的较为棘手的问题,看看他人的解决手段,如果他人在解决这个问题时,采用了很
优秀的处理手法,那我自然可以从中吸取经验,弥补自身思维短板;反之,如果他人也采取了冗长复杂的处理手法,那么在涉及到这部分的代码
就很有可能出现问题。
在检查完这一部分的代码后,便采用MetricsReloaded插件,对其代码进行依赖性和复杂度分析,对于出现了循环依赖以及复杂度较高的情况,就
着重看这部分代码,对于cyclomatic complexity较高的方法,就着重看它的分支语句,看是否有遗漏的情况。这些都是bug出现的重灾区。
S3:应用对象创建模式
从task2开始接触到了工厂模式,但是并没有在我的程序中进行实践,现在看来,使用工厂模式的确能简化一些代码。如果使用这种方式进行重构,
可以考虑创建一个diffFactor(),创建diffAdd(),diffmult(),diffsin(),diffcos(),diffpow()这几个求导类,这样既方便修改,又增加了代码的复用率,还
使得程序的可读性更强,封装性也更好。
S4:与优秀代码的对比和心得
与一些优秀代码进行之后,我最大的感觉就是我和他们的代码风格差距却是很大,在编写程序时,我的思维仍旧是偏向于面向过程而非面向对象,这
导致我的处理手段与常规有很大差别,也导致我经常出现一“main”到底的情况,代码耦合度居高不下,总是方法行数超出限制,甚至类行数行出限制,
这是我需要好好反省的,多读读大佬的代码,尽快从面向过程的思路中转变过来。
其次是个人的心得体会,面向对象这门课确实有难度,十分考验我们的编程水平,也更加贴近我们将来的实际工作,我应当在这门课上多花一些时间。
另外,在写OO代码的时候,一定要一开始就想好大致的思路,主要创建哪几个类,实现哪几个方法,而不是遇到问题就创建一个新的方法,这样非常
容易导致代码耦合度很高,并且需要不断地由于bug来修改方法,来打补丁,这样非常耗费时间。