文章目录
题目
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
示例1 :
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例2 :
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例3 :
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
想法一:字典
算法实现
def lengthOfLongestSubstring(self, s: str) -> int:
d = {}
res = 0
for i in range(len(s)):
if s[i] not in d:
d.update({s[i]: i})
else:
d = {j: k for j, k in d.items() if k >= d[s[i]]}
d[s[i]] = i
res = max(res, len(d))
return res
执行结果
执行结果 : 通过
执行用时 : 436 ms, 在所有 Python3 提交中击败了14.16%的用户
内存消耗 : 13.5 MB, 在所有 Python3 提交中击败了9.28%的用户

复杂度分析
-
时间复杂度:O(n^2)
-
空间复杂度:O(n)
想法二:双指针
算法实现
def lengthOfLongestSubstring(self, s: str) -> int:
n = len(s)
if n == 0:
return 0
elif n == 1:
return 1
res = 0
perior = 0
for i in range(1, n):
if s[i] in s[perior:i]:
res = max(res, i - perior)
while s[i] != s[perior]:
perior += 1
perior += 1
res = max(res, n - perior - 1)
return res
执行结果
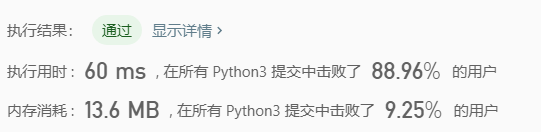
复杂度分析
-
时间复杂度:O(n)
-
空间复杂度:O(1)
滑动窗口:元组实现
算法实现
def lengthOfLongestSubstring(self, s: str) -> int:
if not s: return 0
left = 0
lookup = set()
n = len(s)
max_len = 0
cur_len = 0
for i in range(n):
cur_len += 1
while s[i] in lookup:
lookup.remove(s[left])
left += 1
cur_len -= 1
if cur_len > max_len: max_len = cur_len
lookup.add(s[i])
return max_len
执行结果

复杂度分析
-
时间复杂度:O(n)
-
空间复杂度:O(1)
滑动窗口:字典实现
算法实现
def lengthOfLongestSubstring(self, s: str) -> int:
# 可抛弃字符串的索引尾值 - 字符串索引值,该索引值以及之前的字符都属于重复字符串中的一部分,不再在计算中涉及
ignore_str_index_end = -1
dic = {} # 任意字符最后出现在索引的位置 - {字符: 字符索引值}
max_length = 0 # 最长字符串长度
for i, c in enumerate(s):
# 如果字典中已经存在字符c,则字符c重复
# 如果字符索引值大于ignore_str_index_end,则字符c在需处理的范围内(补充说明请参考备注一)
if c in dic and dic[c] > ignore_str_index_end:
# 先更新可抛弃字符串的索引尾值为字符c上一次的索引值
ignore_str_index_end = dic[c]
# 再更新字符c的索引值
dic[c] = i
# 否则,
else:
# 更新字符最近的索引位置
dic[c] = i
# 更新最大长度
max_length = max(i - ignore_str_index_end, max_length)
return max_length
执行结果
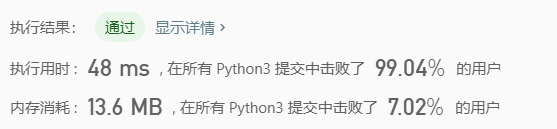
复杂度分析
-
时间复杂度:O(n)
-
空间复杂度:O(1)
小结
先按照自己的想法设计,不重复首先想到字典,键储存字符,值储存索引,但是在去除前面的字符时很费时间。
之后想到了双指针,两指针之间为不重复的字符串,重复后前面向前移动到重复元素前一处。
之后看了官方的滑动窗口,原来正式名字叫这个,和我的想法相同,但是用set和dic来保存不重复字串,查找时更省时间。
