1、Git概念及使用
1.1Git是一种分布式版本控制系统。
版本控制就是对文件变更过程的管理,即版本控制就是要把一个文件或一些文件的各个版本按一定的方式管理起来,目的是需要用到某个版本的时候可以随时拿出来。
这里的“分布式”是相对于“集中式”来说的。把数据集中保存在服务器节点,所有的客户节点都从服务节点获取数据的版本控制系统叫做集中式版本控制系统,比如svn就是典型的集中式版本控制系统。与之相对,Git的数据不止保存在服务器上,同时也完整的保存在本地计算机上,所以我们称Git为分布式版本控制系统。
Git的这种特性带来许多便利,比如你可以在完全离线的情况下使用Git,随时随地提交项目更新,而且你不必为单点故障过分担心,即使服务器宕机或数据损毁,也可以用任何一个节点上的数据恢复项目,因为每一个开发节点都保存着完整的项目文件镜像。
Git能够解决哪些问题?
大多人会通过保存项目或文件的备份来达到版本控制的目的。这是一种简单的办法,但过于简单。这种方式无法详细记录版本附加信息,难以应付复杂项目或长期更新的项目,缺乏版本控制约定,对协作开发无能为力。
Git能够为我们解决版本控制方面的大多数问题,利用Git
- 可以为每一次变更提交版本更新并且备注更新的内容;
- 可以在项目的各个历史版本之间自如切换;
- 可以一目了然的比较出两个版本之间的差异;
- 可以从当前的修改中撤销一些操作;
- 可以自如的创建分支、合并分支;
- 可以和多人协作开发;
- 可以采取自由多样的开发模式。
综上,Git解决了版本控制方面的很多问题,但最核心的是它很好的解决了版本状态存储(即文件变更过程存储)的问题。
Git的实现原理
人们都有版本记录的经验,比如在文档撰写的关键点上保留一个备份,或在需要对文件进行修改的时候“另存”一次。Git采取了差不多的方式。不同之处在于存储方式,在Git系统中一旦一个版本被提交,那么它就会被保存在“Git数据库”中。
1.2 Git基本用法
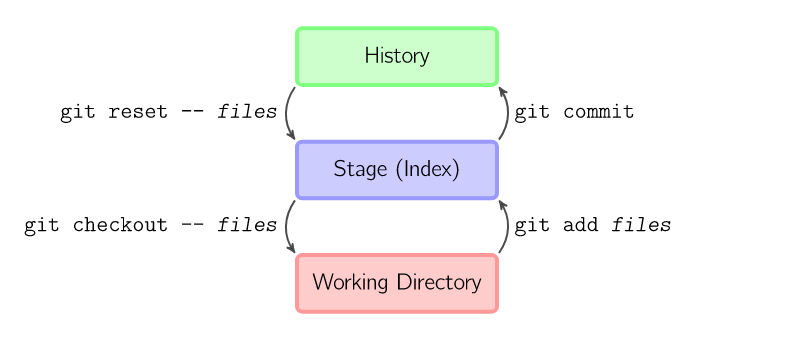
上面的四条命令在工作目录、暂存目录(也叫做索引)和仓库之间复制文件。
git add files把当前文件放入暂存区域。git commit给暂存区域生成快照并提交。git reset -- files用来撤销最后一次git add files,你也可以用git reset撤销所有暂存区域文件。git checkout -- files把文件从暂存区域复制到工作目录,用来丢弃本地修改。
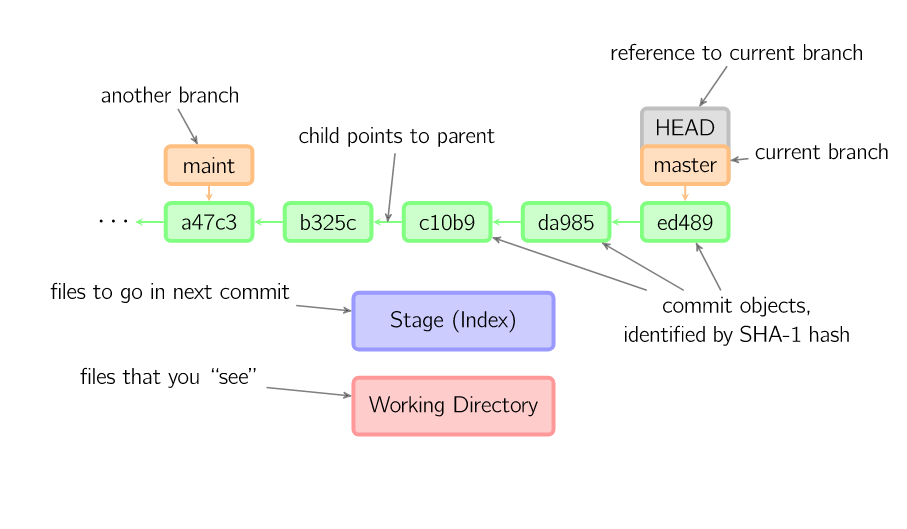
1.3 具体操作演示
在github上创建远程库
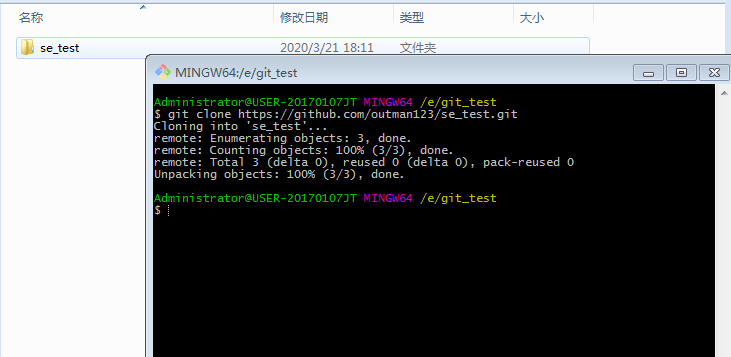
通过git clone https://github.com/outman123/se_test.git拉取远程库到本地
1.3.1分支同步
接下来进入本地仓库并创建自己的分支 ,并在分支上对项目进行操作,完成后在合并到远程的master上去,安全方便。
下面是在本地新建test.txt文件,然后add到缓存中并commit到库中
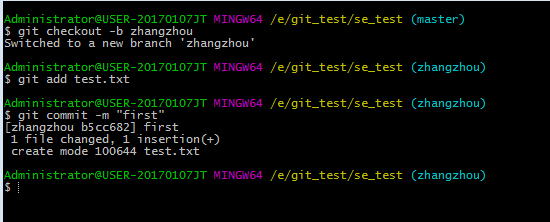
但是上面的提交操作是在分支中完成的,所以远程的master仓库中并没有test.txt,必须切换回master再进行分支合并,这样才能将自己分支的修改同步到master上去。


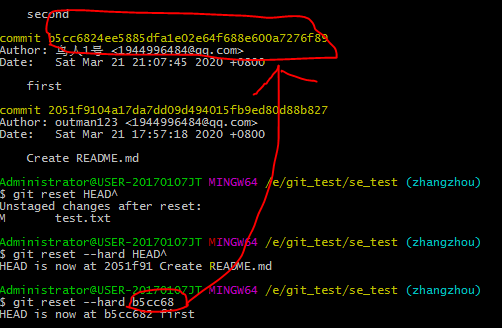
1.3.2版本变更
原来的test.txt文件只有如下信息
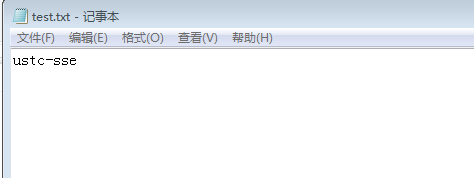
现在往文件中添加信息,然后提交到本地仓库
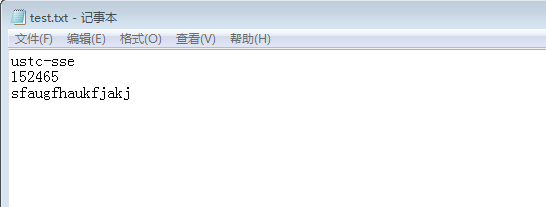
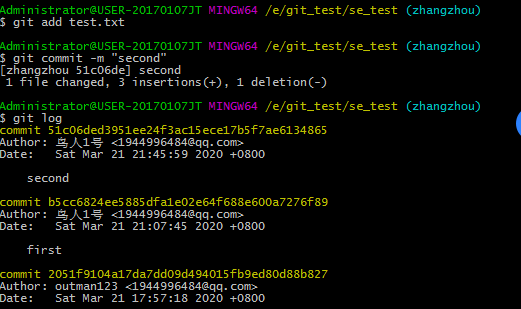
通过git log可以查看到每次操作的版本号,提交信息等,然后我们就可以根据版本号进行变更,例如我们用git reset --hard HEAD^可以回到前一个版本或者根据版本号制定到达某个版本。
2、Vim概念及使用
2.1 简介
Vim(Vi[Improved])编辑器是功能强大的跨平台文本文件编辑工具,继承自Unix系统的Vi编辑器,支持Linux/Mac OS X/Windows系统,利用它可以建立、修改文本文件。进入Vim编辑程序,可以在终端输入下面的命令:vim [filename]
其中filename是要编辑器的文件的路径名。如果文件不存在,它将为你建立一个新文件。Vim编辑程序有三种操作模式,分别称为 编辑模式、插入模式 和 命令模式,当运行Vim时,首先进入编辑模式。
2.2 编辑模式
ZZ命令,连续按两次大写的
Z键。
* 当光标停留在一个单词上,* 键会在文件内搜索该单词,并跳转到下一处;
# 当光标停留在一个单词上,# 在文件内搜索该单词,并跳转到上一处;
(/) 移动到 前/后 句 的开始; {/} 跳转到 当前/下一个 段落 的开始。 g_ 到本行最后一个不是 blank 字符的位置。 fa 到下一个为 a 的字符处,你也可以fs到下一个为s的字符。 t, 到逗号前的第一个字符。逗号可以变成其它字符。 3fa 在当前行查找第三个出现的 a。 F/T 和 f 和 t 一样,只不过是相反方向; gg 将光标定位到文件第一行起始位置; G 将光标定位到文件最后一行起始位置; NG或Ngg 将光标定位到第 N 行的起始位置替换和删除:
rc 用 c 替换光标所指向的当前字符;
nrc 用 c 替换光标所指向的前 n 个字符;
x 删除光标所指向的当前字符;
nx 删除光标所指向的前 n 个字符;
dw 删除光标右侧的字;
ndw 删除光标右侧的 n 个字;
db 删除光标左侧的字;
ndb 删除光标左侧的 n 个字;
dd 删除光标所在行,并去除空隙;
ndd 删除(剪切) n 行内容,并去除空隙;复制粘贴:
yy 复制当前行到内存缓冲区;
nyy 复制 n 行内容到内存缓冲区;
5yy 复制 5 行内容到内存缓冲区;
“+y 复制 1 行到操作系统的粘贴板;
“+nyy 复制 n 行到操作系统的粘贴板。 2.3 插入模式
在编辑模式下正确定位光标之后,可用以下命令切换到插入模式:
i 在光标左侧插入正文
a 在光标右侧插入正文
o 在光标所在行的下一行增添新行
O 在光标所在行的上一行增添新行
I 在光标所在行的开头插入
A 在光标所在行的末尾插入退出插入模式的方法是,按 ESC 键或组合键 Ctrl+[ ,退出插入模式之后,将会进入编辑模式
2.4 命令模式
: ,光标就跳到屏幕最后一行,并在那里显示冒号,此时已进入命令模式。命令模式又称
末行模式 ,用户输入的内容均显示在屏幕的最后一行,按回车键,Vim 执行命令。
:e
保存当前编辑的文件需要用
:w ,保存并退出:wq
^ 放在字符串前面,匹配行首的字;
$ 放在字符串后面,匹配行尾的字;
\< 匹配一个字的字头;
\> 匹配一个字的字尾;
. 匹配任何单个正文字符;
[str] 匹配 str 中的任何单个字符; [^str] 匹配任何不在 str 中的单个字符; [a-b] 匹配 a 到 b 之间的任一字符; * 匹配前一个字符的 0 次或多次出现; \ 转义后面的字符。:d 删除光标所在行
:3d 删除 3 行
:.,$d 删除当前行至正文的末尾 :/str1/,/str2/d 删除从字符串 str1 到 str2 的所有行 :g/^\(.*\)$\n\1$/d 删除连续相同的行,保留最后一行 :g/\%(^\1$\n\)\@<=\(.*\)$/d 删除连续相同的行,保留最开始一行 :g/^\s*$\n\s*$/d 删除连续多个空行,只保留一行空行 :5,20s/^#//g 删除5到20行开头的 # 注释:%s/str1/str2/ 用字符串 str2 替换行中首次出现的字符串 str1
:s/str1/str2/g 用字符串 str2 替换行中所有出现的字符串 str1 :.,$ s/str1/str2/g 用字符串 str2 替换正文当前行到末尾所有出现的字符串 str1 :1,$ s/str1/str2/g 用字符串 str2 替换正文中所有出现的字符串 str1 :g/str1/s//str2/g 功能同上 :m,ns/str1/str2/g 将从m行到n行的str1替换成str2
1.使用底线命令输入%s/xxx/yyy/g
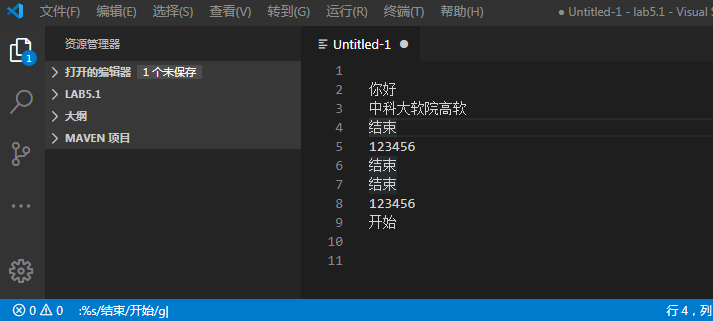
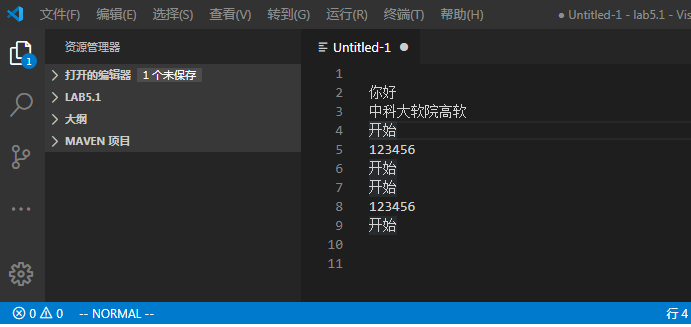
2.5,9s/^/#/g 将当前文件中5-9行的代码注释,添加注释为#,实质为文本替换。


3.使用自动化宏指令多次复制粘贴,在正常模式下输入q[a-z],录入[a-z]宏指令,最后正常模式下在输入n@[a-z]执行n次的[a-z]宏指令
3、正则表达式使用
| \ | 将下一个字符标记为一个特殊字符、或一个原义字符、或一个向后引用、或一个八进制转义符。例如,“n”匹配字符“n”。“\n”匹配一个换行符。串行“\\”匹配“\”而“\(”则匹配“(”。 |
|---|---|
| ^ | 匹配输入字符串的开始位置。如果设置了RegExp对象的Multiline属性,^也匹配“\n”或“\r”之后的位置。 |
| $ | 匹配输入字符串的结束位置。如果设置了RegExp对象的Multiline属性,$也匹配“\n”或“\r”之前的位置。 |
| * | 匹配前面的子表达式零次或多次。例如,zo*能匹配“z”以及“zoo”。*等价于{0,}。 |
| + | 匹配前面的子表达式一次或多次。例如,“zo+”能匹配“zo”以及“zoo”,但不能匹配“z”。+等价于{1,}。 |
| ? | 匹配前面的子表达式零次或一次。例如,“do(es)?”可以匹配“does”或“does”中的“do”。?等价于{0,1}。 |
| {n} | n是一个非负整数。匹配确定的n次。例如,“o{2}”不能匹配“Bob”中的“o”,但是能匹配“food”中的两个o。 |
| {n,} | n是一个非负整数。至少匹配n次。例如,“o{2,}”不能匹配“Bob”中的“o”,但能匹配“foooood”中的所有o。“o{1,}”等价于“o+”。“o{0,}”则等价于“o*”。 |
| {n,m} | m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次。例如,“o{1,3}”将匹配“fooooood”中的前三个o。“o{0,1}”等价于“o?”。请注意在逗号和两个数之间不能有空格。 |
| ? | 当该字符紧跟在任何一个其他限制符(*,+,?,{n},{n,},{n,m})后面时,匹配模式是非贪婪的。非贪婪模式尽可能少的匹配所搜索的字符串,而默认的贪婪模式则尽可能多的匹配所搜索的字符串。例如,对于字符串“oooo”,“o+?”将匹配单个“o”,而“o+”将匹配所有“o”。 |
| . | 匹配除“\n”之外的任何单个字符。要匹配包括“\n”在内的任何字符,请使用像“(.|\n)”的模式。 |
| (pattern) | 匹配pattern并获取这一匹配。所获取的匹配可以从产生的Matches集合得到,在VBScript中使用SubMatches集合,在JScript中则使用$0…$9属性。要匹配圆括号字符,请使用“\(”或“\)”。 |
| (?:pattern) | 匹配pattern但不获取匹配结果,也就是说这是一个非获取匹配,不进行存储供以后使用。这在使用或字符“(|)”来组合一个模式的各个部分是很有用。例如“industr(?:y|ies)”就是一个比“industry|industries”更简略的表达式。 |
| (?=pattern) | 正向肯定预查,在任何匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如,“Windows(?=95|98|NT|2000)”能匹配“Windows2000”中的“Windows”,但不能匹配“Windows3.1”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始。 |
| (?!pattern) | 正向否定预查,在任何不匹配pattern的字符串开始处匹配查找字符串。这是一个非获取匹配,也就是说,该匹配不需要获取供以后使用。例如“Windows(?!95|98|NT|2000)”能匹配“Windows3.1”中的“Windows”,但不能匹配“Windows2000”中的“Windows”。预查不消耗字符,也就是说,在一个匹配发生后,在最后一次匹配之后立即开始下一次匹配的搜索,而不是从包含预查的字符之后开始 |
| (?<=pattern) | 反向肯定预查,与正向肯定预查类拟,只是方向相反。例如,“(?<=95|98|NT|2000)Windows”能匹配“2000Windows”中的“Windows”,但不能匹配“3.1Windows”中的“Windows”。 |
| (?<!pattern) | 反向否定预查,与正向否定预查类拟,只是方向相反。例如“(?<!95|98|NT|2000)Windows”能匹配“3.1Windows”中的“Windows”,但不能匹配“2000Windows”中的“Windows”。 |
| x|y | 匹配x或y。例如,“z|food”能匹配“z”或“food”。“(z|f)ood”则匹配“zood”或“food”。 |
| [xyz] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a”。 |
| [^xyz] | 负值字符集合。匹配未包含的任意字符。例如,“[^abc]”可以匹配“plain”中的“p”。 |
| [a-z] | 字符范围。匹配指定范围内的任意字符。例如,“[a-z]”可以匹配“a”到“z”范围内的任意小写字母字符。 |
| [^a-z] | 负值字符范围。匹配任何不在指定范围内的任意字符。例如,“[^a-z]”可以匹配任何不在“a”到“z”范围内的任意字符。 |
| \b | 匹配一个单词边界,也就是指单词和空格间的位置。例如,“er\b”可以匹配“never”中的“er”,但不能匹配“verb”中的“er”。 |
| \B | 匹配非单词边界。“er\B”能匹配“verb”中的“er”,但不能匹配“never”中的“er”。 |
| \cx | 匹配由x指明的控制字符。例如,\cM匹配一个Control-M或回车符。x的值必须为A-Z或a-z之一。否则,将c视为一个原义的“c”字符。 |
| \d | 匹配一个数字字符。等价于[0-9]。 |
| \D | 匹配一个非数字字符。等价于[^0-9]。 |
| \f | 匹配一个换页符。等价于\x0c和\cL。 |
| \n | 匹配一个换行符。等价于\x0a和\cJ。 |
| \r | 匹配一个回车符。等价于\x0d和\cM。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于[ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于[^ \f\n\r\t\v]。 |
| \t | 匹配一个制表符。等价于\x09和\cI。 |
| \v | 匹配一个垂直制表符。等价于\x0b和\cK。 |
| \w | 匹配包括下划线的任何单词字符。等价于“[A-Za-z0-9_]”。 |
| \W | 匹配任何非单词字符。等价于“[^A-Za-z0-9_]”。 |
| \xn | 匹配n,其中n为十六进制转义值。十六进制转义值必须为确定的两个数字长。例如,“\x41”匹配“A”。“\x041”则等价于“\x04&1”。正则表达式中可以使用ASCII编码。. |
| \num | 匹配num,其中num是一个正整数。对所获取的匹配的引用。例如,“(.)\1”匹配两个连续的相同字符。 |
| \n | 标识一个八进制转义值或一个向后引用。如果\n之前至少n个获取的子表达式,则n为向后引用。否则,如果n为八进制数字(0-7),则n为一个八进制转义值。 |
| \nm | 标识一个八进制转义值或一个向后引用。如果\nm之前至少有nm个获得子表达式,则nm为向后引用。如果\nm之前至少有n个获取,则n为一个后跟文字m的向后引用。如果前面的条件都不满足,若n和m均为八进制数字(0-7),则\nm将匹配八进制转义值nm。 |
| \nml | 如果n为八进制数字(0-3),且m和l均为八进制数字(0-7),则匹配八进制转义值nml。 |
| \un | 匹配n,其中n是一个用四个十六进制数字表示的Unicode字符。例如,\u00A9匹配版权符号(©)。 |
详细可见:https://tool.oschina.net/uploads/apidocs/jquery/regexp.html

/^[a-zA-Z][a-zA-Z]+[0-9]*