REST 风格的优秀设计应该像下面这些:
如果要设计一个资源拥有另外一个资源的情况的API,例如,设计一个包含用户(users)和用户的评论(comments)的 API 可以采用这样的形式:
- 将这些操作变成一个资源的属性,比如 disable 一个 user,可以在 user 里面加一个 disabled 的属性,可以设计一个 API 使用
PATCH /users/1234将 disabled 设置成 true 即可。 - 将这个操作看成某个资源的附属资源(就像上面例子中的 comments 一样)来设计,比如GitHub的Star a gist API ,就是这样的,它把star操作放在这个资源的后面,看上去好像是一个附属资源:
- PUT /gists/:id/star- DELETE /gists/:id/star 在不得不使用其它例外形式设计 API 时,尽量用文档写清楚输入输出和返回值等其他必要信息,避免让习惯了使用资源名的调用者感到困惑
- 比如你要设计一个API,返回所有已经登录的用户,可以这样做:GET /users?login=true
- 获取所有的用户,返回结果按照create_at降序排序可以这样设计:GET /users?sort=-create_at
- 组合使用过滤条件和排序,GET /users?sort=-create_at,login_at&login=true 表示返回所有已登录用户,结果按照create_at降序, login_at升序
- 单独为 API 设计一个 Query Parameter 专门用于搜索,从 API 中传递过来的 Query Parameter 可以直接设置成这些搜索框架的输入条件GET /users?q=key&&sort=-create_at,login_at&diabled=false
- 映射到一个新的API(相当于快捷方式)比如设计一个用于返回最近登录用户的API:GET /users/recently_login这种设计可以简化客户端的调用,否则调用者每次都要根据时间合成 Query Parameter,增加了客户端使用复杂度
- 查询数据的部分内容GET /user?fields=id,user_name,address&diabled=false&sort=-login_at GET /facebook/v2.8/me?fields=id,name,birthday,cover,devices,email&access_token=xxX
API中都使用了下划线(user_name)的形式来命名这些参数,使用划线(user_name)还是使用驼峰(userName)的形式?下划线分割的形式比使用驼峰的形式更容易阅读(容易20%)
合理设计返回数据的形式,格式和考虑启用压缩(gzip)
假如有个系统提供一个 API 用于上传一张图,这张图上传之后你可以调用另外一个 API 修改这个图片的描述。如果调用上传 API 后,返回数据中没有返回这张图的唯一性 ID,你就无法接着调用其它 API 引用到这个图的资源,从而无法进行修改描述的操作,除非之前额外再次调用查询操作拉取到这张图唯一性 ID。
通常,POST 操作成功以后,我们一般也把新创建的资源的 URL 放在 HTTP header 的 location 字段中,方便客户的拉取。例如上上树图片上传的 API 返回的 header 中可以包含location: http://api.domain.name/photos/1234
RESTful API 一般都是返回文本数据,启用 gzip 通常可以节省60%-80%以上的带宽(这个数据很好证明,随便使用几个个 json 文件 gzip下就可以看出来,我测试几个 json 文件一般300K左右都能被压缩成50K左右),尤其是在返回的数据比较大情况下,压缩比更高。不过启用gzip 不可避免会增加 CPU 的负担,实际工程项目中需要权衡考量。
至于到底用什么用的格式来返回数据?XML?JSON?纯文本?但从统计数据来看 JSON 格式目前是使用做多的 REST API 的输入输出格式。
根据不同的 API 操作,设置合适的 HTTP 状态码和必要的出错信息
- 200 OK 用于返回 GET, PUT, PATCH 或 DELETE 的操作。有使用也用来返回没有创建数据的 POST 操作;
- ** 201 Created** 用来返回 POST 操作并且成功创建了数据的情况。新创建的数据资源的链接应该放在location中返回;
- 204 No Content 用来返回一次成功的请求,但是该请求返回的 body 为空的情况,如 DELETE 请求;
- 304 Not Modified 表示缓存没有失效,和上次的请求相比,没有新的内容;
- 400 Bad Request 用于返回 API 参数不正确的情况,比如传入的 JSON 格式错误无法解析等;
- 401 Unauthorized 用于表示请求等 API 缺少身份验证信息;
- 403 Forbidden 用于表示该资源不允许特定用户访问;
- 404 Not Found 请求一个不存在的资源;
- 429 Too Many Requests 请求过于频繁,可以用在客户端调用过于频繁的情况。
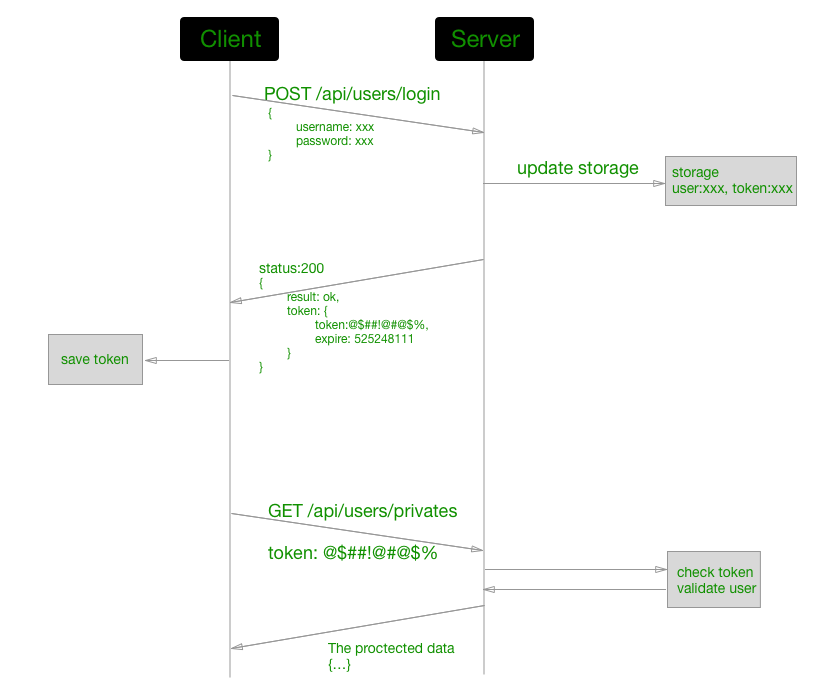
使用 token 机制设计鉴权和验证系统(Authorization and Authentication)
常见的场景就是用户系统-结合 OAuth2,参考腾讯云微视频MVS API,这里给出一个实用的解决方案:
- 用户使用户名密码或者第三方登录,最终请求一个我们设计的登录 API(这个 API 接受用户名密码,或第三方登录验证结果);
- 服务端认证成功以后,生成一个 token,并将这个 token 和用户信息关联在一起,同时返回这个 token 给调用客户端;
- 客户端记录并保存下这个 token;
- 下次客户端发起和用户相关请求 API 都要在 http header 中带上这个 token;
- 服务端通过这个 token 去区分用户是谁,判断这个用户是否已经登录和有什么样的权限;
- 服务端也要考虑 token 的失效时间;
- 客户端在发现 token 失效的时候重新请求新的 token

如何实现数据的分页返回
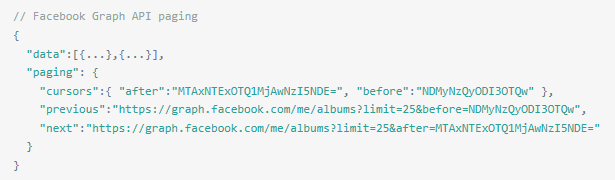
另一种符合WEB标准的做法是使用 link header,简单来说就是在 http header 使用 link字段,提供一个和超链接一样目的 URL 地址,来实现不同资源之间的转跳。如GitHub的Api文档是这样规定分页信息的,这种做法缺点是不太直观,优点是不会干扰数据,返回内容都是数据本身,无需在数据上嵌入额外的属性来说明分页信息,简单干净
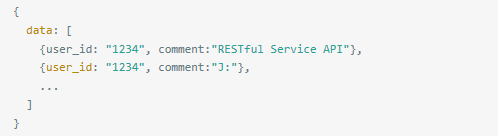
如何处理有关联资源的返回数据
对客户端来说,最直观和容易处理的返回形式如下:

返回数据中 avatar 和 name 是每条数据都是重复的,所以你也可以这样设计返回数据:先返回该用户的所有评论 /comments?user=1234
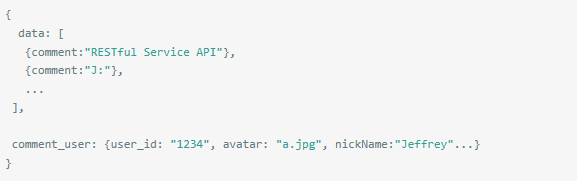
再通过请求该用户 API 的相关内容 /users/1234:{user_id: "1234", avatar: "a.jpg", nickName:"Jeffrey"...}这种情况下其实可以将依赖资源嵌入返回对象中,避免了客户端需要再一次发起请求来获取这个 user 的详细信息/comments?user=1234 直接返回类似这样的信息即可:
考虑启用 HTTP 缓存机制
HTTP协议本身支持两种缓存机制: ETag 和 Last-Modified
- ETag:HTTP 请求中在 header 中包含一个内容的 hash,如果返回结果没有变化,该请求会直接返回304 Not Modified,而不是所有数据内容本身
- Last-Modified: 和 Etag 工作原理差不多,只是使用时间戳作为内容是否过期的标志。
限制 API 调用频次(Rate limiting)
如果一个客户端请求 API 的频率太快,根据HTTP协议,可以返回429 Too Many Requests。
X-Rate-Limit-Limit: 该请求的调用上限
X-Rate-Limit-Remaining: 15分钟内还可以调用多少次
X-Rate-Limit-Reset: 还有多少秒之后访问限制会被重置
- ssl_prefer_server_ciphers: 表示服务端加密算法优先于客户端加密算法,主要是防止降级攻击 (downgrade attack)。
- Strict-Transport-Security(HSTS):告诉浏览器这个域名在指定的时间(max-age)内应该强制使用 HTTPS 访问。