作为快速入门Kafka系列的第七篇博客,本篇为大家带来的是kafka的log存储机制和kafka消息不丢失机制~
码字不易,先赞后看!

文章目录
1. kafka的log-存储机制
1.1 kafka中log日志目录及组成
kafka在我们指定的log.dir目录下,会创建一些文件夹;名字是【主题名字-分区名】所组成的文件夹。 在【主题名字-分区名】的目录下,会有两个文件存在,如下所示:
#索引文件
00000000000000000000.index
#日志内容
00000000000000000000.log
在目录下的文件,会根据log日志的大小进行切分,.log文件的大小为1G的时候,就会进行切分文件;

在kafka的设计中,将offset值作为了文件名的一部分
比如:topic的名字为:test,有三个分区,生成的目录如下如下所示:
test-0
test-1
test-2
kafka日志的组成
segment file组成:由两个部分组成,分别为index file和data file,此两个文件一一对应且成对出现; 后缀.index和.log分别表示为segment的索引文件、数据文件。
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个全局 partion的最大offset(偏移message数)。数值最大为64位long大小,19位数字字符长度,没有数字就用0 填充。
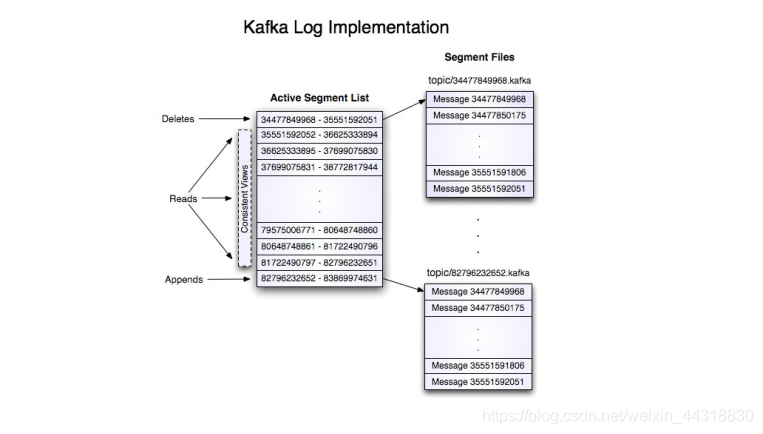
通过索引信息可以快速定位到message。通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作;
通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。 稀疏索引:为了数据创建索引,但范围并不是为每一条创建,而是为某一个区间创建;
好处:就是可以减少索引值的数量。
不好的地方:找到索引区间之后,要得进行第二次处理。
1.2 Kafka的offset查找过程

比如:要查找绝对offset为7的Message:
上图的左半部分是索引文件,里面存储的是一对一对的key-value,其中key是消息在数据文件(对应的log文件)中的编号,比如“1,3,6,8……”,分别表示在log文件中的第1条消息、第3条消息、第6条消息、第8条消息……,那么为什么在index文件中这些编号不是连续的呢?
这是因为index文件中并没有为数据文件中的每条消息都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据建立一条索引。这样避免了索引文件占用过多的空间,从而可以将索引文件保留在内存中。但缺点是没有建立索引的Message也不能一次定位到其在数据文件的位置,从而需要做一次顺序扫描,但是这次顺序扫描的范围就很小了。
其中以索引文件中元数据3,4597为例,其中3代表在右边log数据文件中从上到下第3个消息(在全局partiton表示第4597个消息),其中4597表示该消息的物理偏移地址(位置)为4597。
1.3 kafka Message的物理结构及介绍
kafka Message的物理结构,如下图所示:

1.4 kafka中log CleanUp
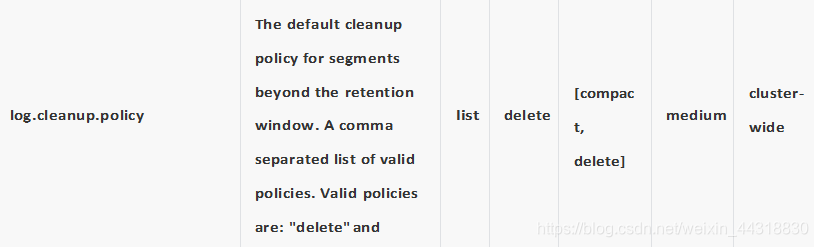
kafka中清理日志的方式有两种:delete和compact。
删除的阈值有两种:过期的时间和分区内总日志大小。
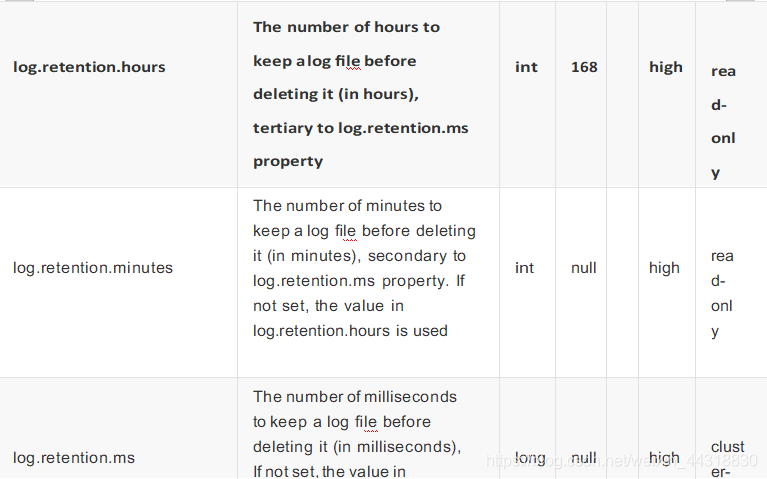
在kafka中,因为数据是存储在本地磁盘中,并没有像hdfs的那样的分布式存储,就会产生磁盘空间不足的情 况,可以采用删除或者合并的方式来进行处理,也可以通过时间来删除、合并:默认7天 还可以通过字节大小、合并。
在kafka中,因为数据是存储在本地磁盘中,并没有像hdfs的那样的分布式存储,就会产生磁盘空间不足的情 况,可以采用删除或者合并的方式来进行处理。
可以通过时间来删除、合并:默认7天 可以通过字节大小、合并。
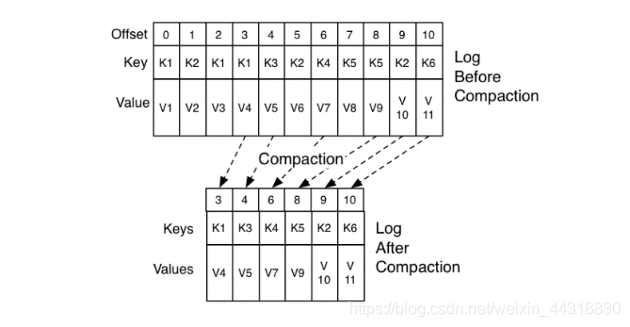
相同的key,保存offset值大的(最新的消息记录)
2. kafka消息不丢失制
从Kafka的大体角度上可以分为数据生产者,Kafka集群,还有就是消费者,而要保证数据的不丢失也要从这三个角度去考虑。
2.1 生产者生成数据不丢失
2.1.1 生产者数据不丢失过程图
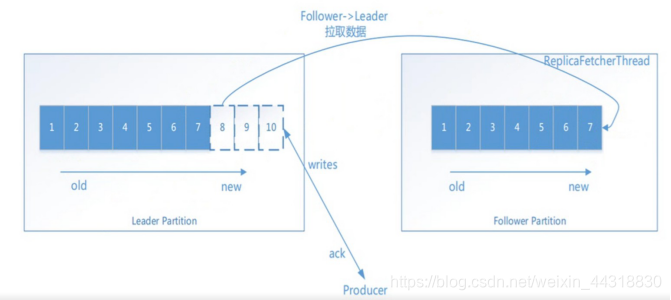
说明:有多少个分区,就启动多少个线程来进行同步数据
2.1.2 发送数据方式
可以采用同步或者异步的方式-过程图
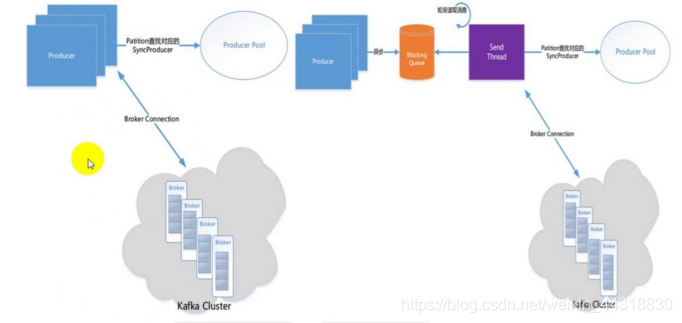
同步:发送一批数据给kafka后,等待kafka返回结果
1、生产者等待10s,如果broker没有给出ack相应,就认为失败。
2、生产者重试3次,如果还没有相应,就报错
异步:发送一批数据给kafka,只是提供一个回调函数。
1、先将数据保存在生产者端的buffer中。buffer大小是2万条
2、满足数据阈值或者数量阈值其中的一个条件就可以发送数据。
3、发送一批数据的大小是500条
说明:如果broker迟迟不给ack,而buffer又满了,开发者可以设置是否直接清空buffer中的数据。
2.1.3 ack机制(确认机制)
生产者数据不抵事,需要服务端返回一个确认码,即ack响应码;ack的响应有三个状态值
0:生产者只负责发送数据,不关心数据是否丢失,响应的状态码为0(丢失的数据,需要再次发送 )
1:partition的leader收到数据,响应的状态码为1
-1:所有的从节点都收到数据,响应的状态码为-1
说明:如果broker端一直不给ack状态,producer永远不知道是否成功;producer可以设置一个超时时间10s,超 过时间认为失败。
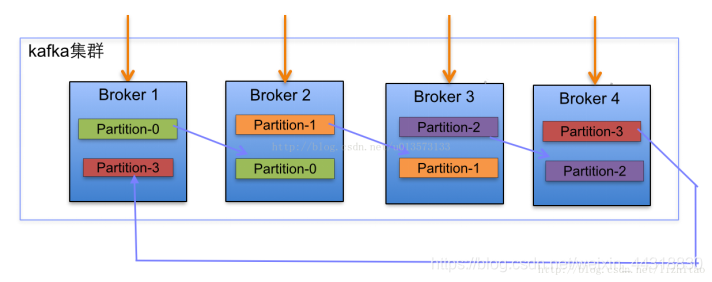
2.2 kafka的broker中数据不丢失
在broker中,保证数据不丢失主要是通过副本因子(冗余),防止数据丢失
2.3 消费者消费数据不丢失
在消费者消费数据的时候,只要每个消费者记录好offset值即可,就能保证数据不丢失。
本篇博客的内容到这里就结束了,受益或对大数据技术感兴趣的朋友们记得点赞关注一下博主,下一篇博客将为大家带来kafka监控及运维,敬请期待|ू・ω・` )

