准备知识
1、python读取文件
推荐链接:Python读写txt文本文件
不想细究,直接上手的读取文件参考代码
#默认文件位置为当前python代码的路径(相对路径)
#输出文件应为字符串类型
f = open('读取的文件名.txt',"r")
str1=f.read()
f.close()
fw=open('输出的文件名.txt','w')
fw.write(str(list1))
fw.close()
2、英文分词
英文分词比较容易,依据空格、标点符号什么的很容易就分出来了,具体可以参考我这篇简单的博客:
【Python】英文文本分词与词频统计(split()函数、re库)
3、字典排序
关于字典排序问题,我这里也写了篇简单的归纳博客
【Python】按照字典中值的大小对键进行排序(lambda、sorted()、zip())
代码实现
代码1:读取相关英文文本,将其中的单词划分出来,进行词频统计,并排序,最后将结果写入"result.txt"文件中。
#1 获取文本
f = open('Australia blocks Chinese firms Huawei, ZTE from 5G network.txt',"r")
str1=f.read()
f.close()
#2 划分单词
import re
array=re.split('[ ,.\n]',str1)
print('分词结果',array)
dic={}
for i in array:
if i not in dic:
dic[i] = 1
else:
dic[i] += 1
#3 词频排序
#tuple1=zip(dic.values(),dic.keys())
#print(list(sorted(tuple1)))
list1= sorted(dic.items(),key=lambda x:x[1])
print('\n\n词频统计结果:',list1)
#4 输出结果
fw=open('result.txt','a')
fw.write(str(list1))
fw.close()
部分实验结果:
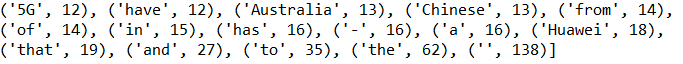
注意这里出现频率最高的是(‘’,138),去掉这个情况的操作见代码2
代码2:输出出现频率最高的n个单词
def order_dict(dicts, n):#网上看的代码,emmmmmm,有点繁琐就是了
result = []
result1 = []
p = sorted([(k, v) for k, v in dicts.items()], reverse=True)
s = set()
for i in p:
s.add(i[1])
for i in sorted(s, reverse=True)[:n]:
for j in p:
if j[1] == i:
result.append(j)
for r in result:
result1.append(r[0])
return result1
def order_dict1(dicts,n):#截取排序结果想要的部分返回就好了
list1= sorted(dicts.items(),key=lambda x:x[1])
return list1[-1:-(n+1):-1]
#return list1[-2:-(n+2):-1] #去除统计结果为""的情况(前面步骤中,字典没有提前""去掉的情况下)
if __name__ == "__main__":
#1 获取文本
f = open('Australia blocks Chinese firms Huawei, ZTE from 5G network.txt',"r")
str1=f.read()
f.close()
#2 划分单词
import re
array=re.split('[ ,.\n]',str1)
#print('分词结果',array)
#3 词频统计
dic={}
for i in array:
if i not in dic:
dic[i] = 1
else:
dic[i] += 1
#4 除统计结果为""的情况
del[dic['']]
#5 输出出现频率最高的5个单词
print(order_dict1(dic,5))
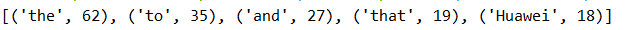
可见,结果中无关紧要的虚词冠词介词什么的占比有点偏多了。(可专门建立一个list为英文中“无关紧要”的词,然后依次排除掉)
扫描二维码关注公众号,回复:
10080913 查看本文章

