论文地址:https://arxiv.org/pdf/1708.02002.pdf
文章内容:
-
论文概述
-
Focal Loss
-
RetinaNet
论文概述:
1、one-stage的检测器方法在识别准确度上往往低于two-stage的检测器,其核心原因在于前景背景类别的极大不平衡
2、论文通过提出Focal Loss来解决类别不平衡的问题,并构建了新的one-stage目标检测网络
Focal Loss:
one-stage识别准确度低于two-stage的原因:
two-stage的检测器很好地处理了类别不平衡问题:1:RPN极大地缩减了候选目标框的数量,过滤了大部分背景样本:2:在分类阶段,通过设置正负样本比例,OHEM等方式,保持了前景背景样本的平衡
one-stage的检测器则会密集地采样,产生~100K的样本,被简单背景样本占据了主导。1、negative example过多造成它的loss太大,以至于把positive的loss都淹没掉了,不利于目标的收敛;2、大多negative example不在前景和背景的过渡区域上,分类很明确(这种易分类的negative称为easy negative),训练时对应的背景类score会很大,换个角度看就是单个example的loss很小,反向计算时梯度小。梯度小造成easy negative example对参数的收敛作用很有限,我们更需要loss大的对参数收敛影响也更大的example,即hard positive/negative example
交叉熵表示:
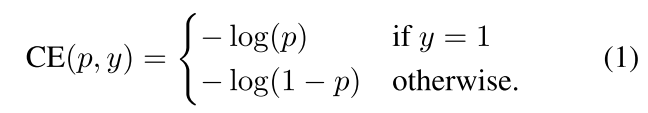
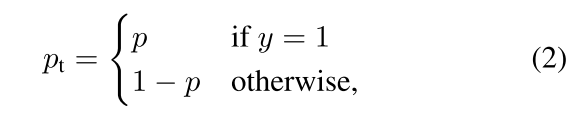
α-balanced CE loss:
解决类别不平衡,可以在CE上加入权重alpha(0~1)

Focal Loss基于CE:
降低容易样本的权重,加大难样本的权重。 pt越大,权重 1-pt就越小。也就是说easy example可以通过权重进行抑制。换言之,当某样本类别比较明确些,它对整体loss的贡献就比较少;而若某样本类别不易区分,则对整体loss的贡献就相对偏大。这样得到的loss最终将集中精力去诱导模型去努力分辨那些难分的目标类别,于是就有效提升了整体的目标检测准度。
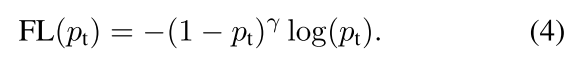
α-balanced variant of the focal loss:
alpha可以平衡正负样本的比例,alpha的选取需要考虑gamma的值,两者最优值是相互影响的,所以在评估准确度时需要把两者组合起来调节

alpha,gamma选值:

RetinaNet:
ResNet+FPN作为backbone,再利用单级的目标识别法+Focal Loss。这个结构在COCO数据集上达到了39.1的mAP

- 训练时FPN每一级的所有example都被用于计算Focal Loss,loss值加到一起用来训练;
- 测试时FPN每一级只选取score最大的1000个example来做nms;
- 整个结构不同层的head部分(图2的c和d部分)共享参数,但分类和回归分支间的参数不共享
- 分类分支的最后一级卷积的bias初始化成前面提到的 -log((1-pi)/pi) ;
