数据挖掘流程:
(一)数据读取:
- 读取数据,并进行展示
- 统计数据各项指标
- 明确数据规模与要完成任务
(二)特征理解分析
- 单特征分析,逐个变量分析其对结果的影响
- 多变量统计分析,综合考虑多种情况影响
- 统计绘图得出结论
(三)数据清洗与预处理
- 对缺失值进行填充
- 特征标准化/归一化
- 筛选有价值的特征
- 分析特征之间的相关性
(四)建立模型
- 特征数据与标签准备
- 数据集切分
- 多种建模算法对比
- 集成策略等方案改进
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
plt.style.use('fivethirtyeight')
import warnings
warnings.filterwarnings('ignore')
%matplotlib inline
data=pd.read_csv('train.csv')
data.head()

查看是否有缺失值
data.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
data.describe()

查看整体的获救比例
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Survived'].value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True,colors=sns.color_palette(palette='cool'))
ax[0].set_title('Survived')
ax[0].set_ylabel('')
sns.countplot('Survived',data=data,ax=ax[1])
ax[1].set_title('Survived')
plt.show()
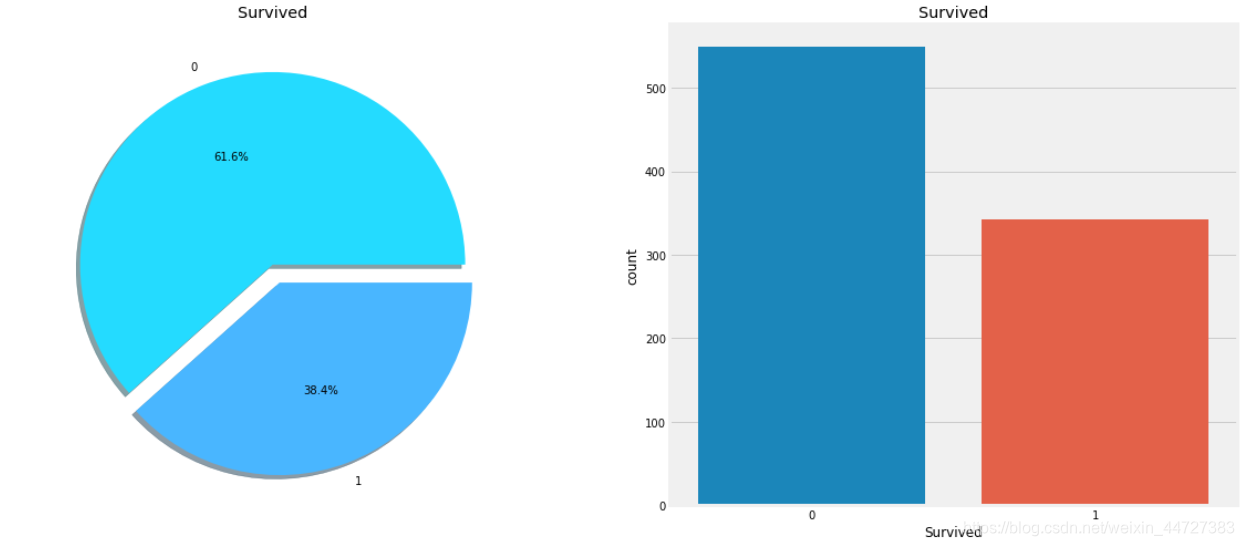
在训练集的891名乘客中,只有大约350人幸存下来,只有38.4%的机组人员在空难中幸存下来。我们需要从数据中挖掘出更多的信息,看看哪些类别的乘客幸存下来,哪些没有。
我们将尝试使用数据集的不同特性来检查生存率。比如性别,年龄,登船地点等
数据特征分为:连续值和离散值
-
离散值:性别(男,女) 登船地点(S,Q,C)
-
连续值:年龄,船票价格
data.groupby(['Sex','Survived'])['Survived'].count()
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
f,ax=plt.subplots(1,2,figsize=(18,8))
data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0],colors='c')
ax[0].set_title('Survived vs Sex')
sns.countplot('Sex',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead')
plt.show()
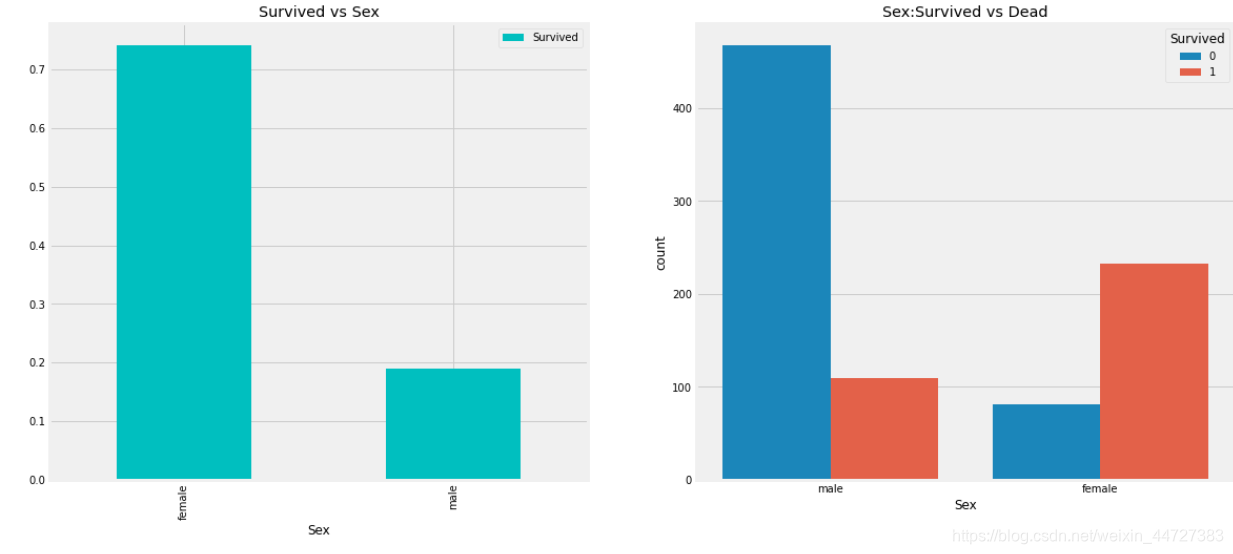
船上的男人比女人多得多。不过,挽救的女性人数几乎是男性的两倍。生存率为一个女人在船上是75%左右,而男性在18-19%左右。
- Pclass --> 船舱等级跟获救情况的关系
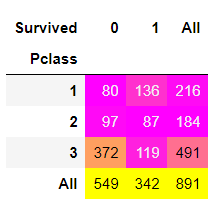
pd.crosstab(data.Pclass,data.Survived,margins=True).style.background_gradient(cmap='spring')
f,ax=plt.subplots(1,2,figsize=(18,8))
data['Pclass'].value_counts().sort_index().plot.bar(colors=sns.color_palette(palette='hls'),ax=ax[0])
ax[0].set_title('Number Of Passengers By Pclass')
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=data,ax=ax[1])
ax[1].set_title('Pclass:Survived vs Dead')
plt.show()
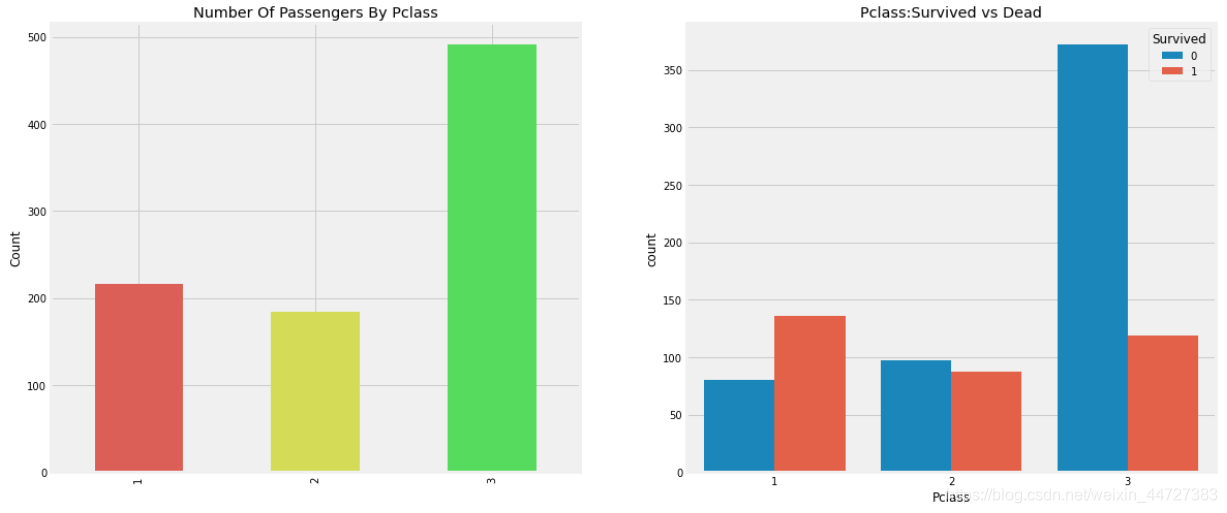
data['Pclass'].value_counts()
3 491
1 216
2 184
Name: Pclass, dtype: int64
船舱等级为1的被给予很高的优先级而救援。尽管数量在pClass 3乘客高了很多,仍然存活数从他们是非常低的,大约25%。
对于pClass1来说存活是63%左右,而pclass2大约是48%。
- 船舱等级和性别对结果的影响
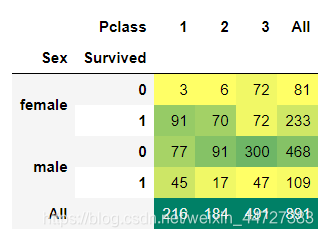
pd.crosstab([data.Sex,data.Survived],data.Pclass,margins=True).style.background_gradient(cmap='summer_r')
sns.factorplot('Pclass','Survived',hue='Sex',data=data)
plt.show()
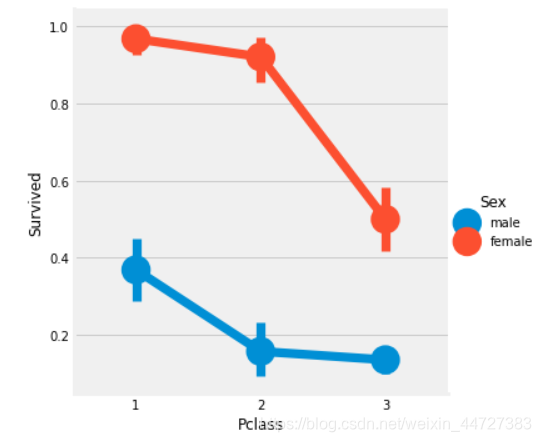
我们用factorplot这个图,看起来更直观一些。
我们可以很容易地推断,从pclass1女性生存是95-96%,如94人中只有3的女性从pclass1没获救。
显而易见的是,不论pClass,女性优先考虑。
看来Pclass也是一个重要的特征。让我们分析其他特征
