文件系统工作原理
文件系统的工作与操作系统的文件数据有关。现在的操作系统的文件数据除了文件实际内容外,通常含有非常多的属性。例如文件权限(rwx) 与 文件属性(所有者、用户组、时间参数等)。文件系统通常会将这两部分的数据分别存放在不同的区块,权限和属性放到inode中,数据则放到block区块中。另外,还有一个超级块(super block)会记录整个文件系统的整体信息,包括inode与block的总量、使用量、剩余量等等。
每个inode与block都有编号,至于这个三个数据的意义可以简略说明如下:
superblock: 记录此filesystem的整体信息,包括inode/block的总量、使用量、剩余量,以及文件系统的格式与相关信息等。
inode: 记录文件的属性,一个文件占用一个inode,同时记录此文件的数据所在的block号码。
block: 记录文件的内容,若文件太大时,会占用多个block。
由于每个inode与block都有编号,而每个文件都会占用一个inode,inode内则有文件数据放置的block号码。因此,我们可以知道的是,如果能够找到文件的inode的话,那么自然就会知道这个文件说放置数据的block号码,当然也就能够读出该文件的实际数据了。这是个比较有效率的做法,因为如此一来我们的磁盘就能够在短时间内读出全部的数据,读写的性能比较好。
我们将inode与block区块用图解来说明一下,如图所示,文件系统先格式化出inode与block的区块,假设某一个档案的属性与权限数据是放置到inode 4号,而这个inode记录了档案数据的实际放置点位2,7,13,15这四个block号码,此时我们的操作系统就能够据此来排列磁盘的阅读顺序,可以一口气将四个block内容读出来!

这种数据存储的方法我们成为索引式系统。
下面我们来看一下windows系统中的FAT,这种格式的文件系统并没有inode存在,所以FAT没有办法将这个文件的所有block在一开始就读出来。每个block号码都记录在前一个block当中,他的读取方式有点像地下这样
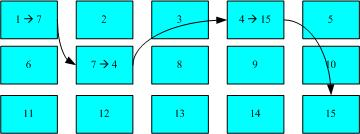
上图中我们假设文件的数据依序写入1->7->4->15号这四个block号码中,但这个文件系统没有办法一口气就知道四个block的号码,他的要一个一个的将block读出后,才会知道下一个block在何处。如果同一个文件数据写入的block分散的太厉害时,则我们的磁盘读取头将无法在磁盘转一圈就读到所有的数据,因此就会多转好几圈才能完整的读取到这个文件的内容。
这就是为什么在windows系统中常常需要碎片整理,需要碎片整理的原因就是文件写入的block太过离散了,此时文件读取的效能将会变的很差。这个时候可以通过碎片整理将同一个文件所属的blocks汇整在一起,这样数据的读取会比较容易。
再来讨论一下inode这个吧!如前所述inode的内容在记录档案的属性以及该档案 实际数据是放置在哪几号block内!基本上,inode记录的文件数据至少有底下这些:
该文件的存取模式(read/write/excute);
该文件的拥有者与群组(owner/group);
该文件的容量;
该文件建立或状态改变的时间(ctime);
最近一次的读取时间(atime);
最近修改的时间(mtime);
定义文件特性的旗标(flag),如setuid...;
该文件真正的内容指向(pointer);
inode的数量与大小也是在格式化的时候就已经固定了,除此之外inode 还有如下特色:
每个inode 大小均固定为128bytes;
每个文件都仅会占用一个inode;
文件系统能共建立的文件数量与inode的数量有关;
系统读取文件时需要先找到inode,并分析inode所记录的权限与用户是否符合,若符合才能够开始实际读取block的内容。
Inode count: Inode的总数量;
Block count: Block的总数量;
Free blocks: 剩余的block数量;
Fre inodes: 剩余的Inode数量;
Filesystem features: has_journal表是为ext3文件系统
superblock(超级块)
superblock是记录整个filesystem相关信息的地方,没有superblock,就没有这个filesystem了。他记录的信息主要有:
在这里插入代码片block与inode的总量
未使用与已使用的inode/block数量;
block与inode 大小(block为1,2,4K,inode为128bytes);
filesystem的挂载时间、最近一次写入数据的时间、最近一侧检验磁盘(fsck)的时间等文件系统的相关信息;
一个valid bit数值,若此文件系统已被挂载,则valid bit为0,若未被挂载,则valid bit为1.
superblock是非常重要的,因为我们这个文件系统的基本信息都写在这里。一般来说,superblock的大小为1025bytes。
硬盘分区的相关事项:
- 当主分区都用完时,可以使用扩展分区来增加额外的分区,这已在前面介绍过了,但是在Linux的kernel里:
(1)IDE的硬盘最多可以支持到16个分区;
(2)SCSI硬盘最多支持15个分区; - 硬盘做多分区的好处:如下:
(1)从控制方面的考虑
将硬盘分成多个分区,就可以把应用程序、使用者的资料、或是一些需要有安全性的资料,分别放入不同分区中方便管理;
(2)从效率方面的考虑
因为硬盘在使用一段时间后,都分有区块不连续的情况,如果一块大容量的硬盘没有划分成多个小分区,那么硬盘在搜索信息时,因为搜索的范围非常大,所以会比较久,如果将大容量的硬盘划分多个小分区,在搜索的时候相对就会快一些;
(3)从使用磁盘配额的功能考虑
因为配额只能对分区做设定,所以我们可以将/home目录单独做一个分区,然后可以对这个分区做配额;
(4)从资料备份和恢复考虑
例如,/home这个目录是专门用于存放用户信息的目录,将这个目录单独设定一个分区,就可以定期就是个分区作备份工作,恢复的时候也比较方便。
文件创建的过程是:
- 先查找一个空的inode
- 写入新的inode table
- 创建Directory,对应文件名,向block中写入文件内容
如何加入一块新硬盘
- 第一步当然是要将硬盘接在电脑上啦;
- 进入系统后,使用fdisk对硬盘进行分区,并设定好分区类型编号;例如:linux 为 83
- 建立好分区后,执行 patrprobe 重新载入分区,使用最新分区表;
- 建立完分区后,格式化分区,如果建立的是SWAP分区,需要为这个SWAP分区写入一个SWAP标志;
- 如果要使用卷标表示法,需要为分区创建卷标名称;
- 建立新的挂载点,并将分区挂载上;
- 在/etc/fstab文件中加入新分区的记录,让电脑以后可以自动挂载这个新建的分区.
