高并发内存池-TCMalloc
1.引言:
在生活中,住在山上的人需要下山挑水,如果每次需要用水的时候再下来担水使用的话非常的浪费时间,那么换角度思考,如果在家中建造固定大小水池,一次性存满,那么既可以节约时间,还可以随用随取,相当方便。在计算机内存使用领域,TCMalloc 是 Google 开发的内存分配器,因其高效、实用的特点,在不少项目中都有使用,例如在 Golang 中就使用了类似的算法进行内存分配。它具有现代化内存分配器的基本特征:对抗内存碎片、在多核处理器能够解决锁竞争问题和性能问题,优秀的东西大家总是会去想法设法搞懂它,实现它!!!。
2.简介
项目环境:Wondows10 VS2013 C/C++
什么是内存池?
内存池(Memory Pool) 是一种动态内存分配与管理技术。 通常情况下,程序员习惯直接使用 new、delete、malloc、free 等API申请分配和释放内存,这样导致的后果是:当程序长时间运行时,由于所申请内存块的大小不定,频繁使用时会造成大量的内存碎片从而降低程序和操作系统的性能。内存池则是在真正使用内存之前,先申请分配一大块内存(内存池)留作备用,当程序员申请内存时,从池中取出一块动态分配,当程序员释放内存时,将释放的内存再放入池内,再次申请池可以 再取出来使用,并尽量与周边的空闲内存块合并。若内存池不够时,则自动扩大内存池,从操作系统中申请更大的内存池
3.如何实现高并发内存池?
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。所以这次我们实现的内存池需要考虑以下几方面的问题。
- 1. 内存碎片问题。
- 2. 性能问题。
- 3. 多核多线程环境下,锁竞争问题
就上诉三个问题而言,要解决锁的竞争,我们就不能在用户申请轻量级内存(<=64k)时对其加锁,另外要解决内存碎片问题,在用户用完内存后,要对内存解释回收,按需调度,此时设计三个模块解决上述问题。
- ThreadCache:线程缓存是每个线程独有的,用于<=64k的内存分配,线程从这里申请时,不需要加锁,且每个线程独享一个Cache,这就是这个并发线程池高效的地方。
- CentralCache:中心缓存时所有线程所共享的,ThreadCache是按需从CentraCache索取内存对象,而CentralCache周期性的回收来自ThreadCache中的内存对象,避免一个线程长期占用太多的内存,而其他内存非常吃紧,达到了内存分配在多个线程中更加均衡的按需调度的目的,CentralCache是存在竞争的,所以这里有必要加锁,因为每次都给ThreadCache足够用的内存大小,所以并不会经常性向CentralCache索取内存,所以锁的竞争不会太激烈。
- PageCache:页缓存是在CentrCache上面的一层缓存着,存储的内存是以页为单位进行存储以及分配,CentralCache没有内存对象时,就申请从PageCache分配一定数量的Page,并切割成定长大小的小块内存,分配给CentralCache。PageCache会回收CentralCache满足条件的span对象,并且合并相邻的页,组成更大的页,进而实现解决内存碎片的问题。
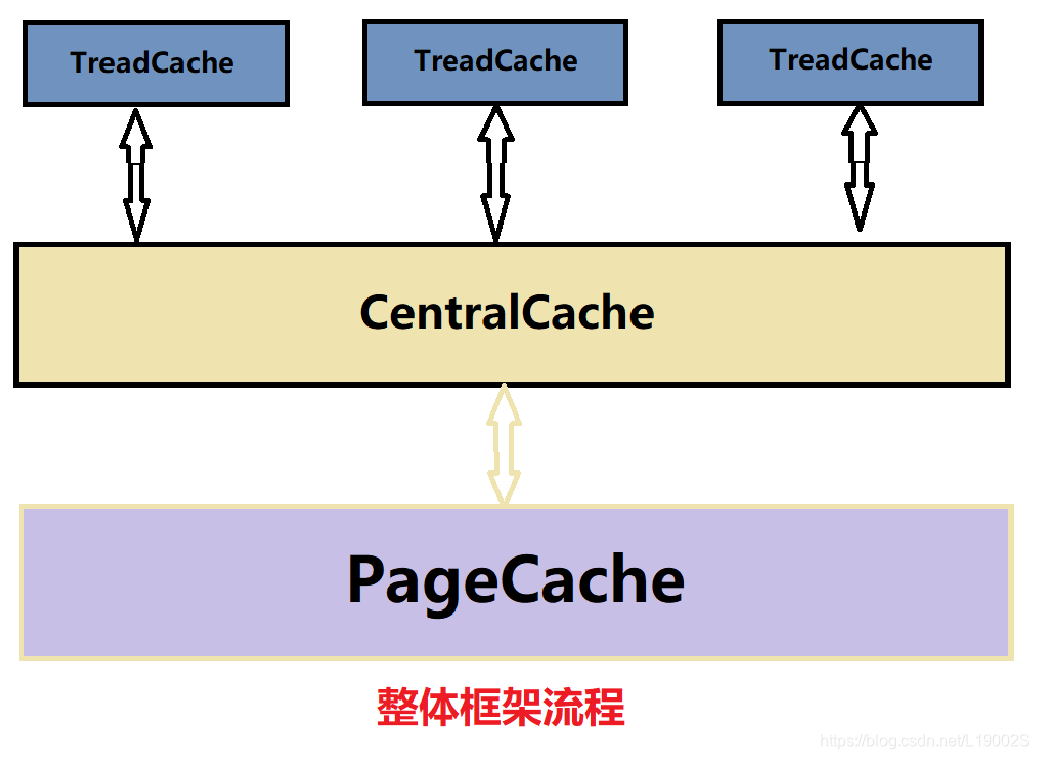
4.如何计算一次申请多少个节点?
用设置的最大除以申请的内存,如果申请的内存越大,就给的越少,相反,申请的越少,就一次性给你512份让你足够用,这样很大程度能够缓解锁的竞争问题!!!
//计算一次申请多少个节点
static size_t NumMoveSize(size_t size)
{
if (size == 0)
return 0;
int num = MAX_SIZE / size;
if (num < 2)
num = 2;
if (num > 512)
num = 512;
return num;
}
5.计算一次向系统申请多少页?
//计算一次向系统获取几个页
static size_t NumMovePage(size_t size)
{
size_t num = NumMoveSize(size);
size_t npage = num*size;
npage >>= 12;
if (npage == 0)
npage = 1;
return npage;
}
6.如何分配定长记录?
出于最大化内存利用率的目的,我们使用另一种经典的方式,freelist。将 4KB 的内存划分为 16 字节的单元,每个单元的前8个字节或者前4个字节作为节点指针,指向下一个单元。初始化的时候把所有指针指向下一个单元;分配时,从链表头分配一个对象出去;释放时,插入到链表。由于链表指针直接分配在待分配内存中,因此不需要额外的内存开销,而且分配速度也是相当快。
7.如何分配变长记录?
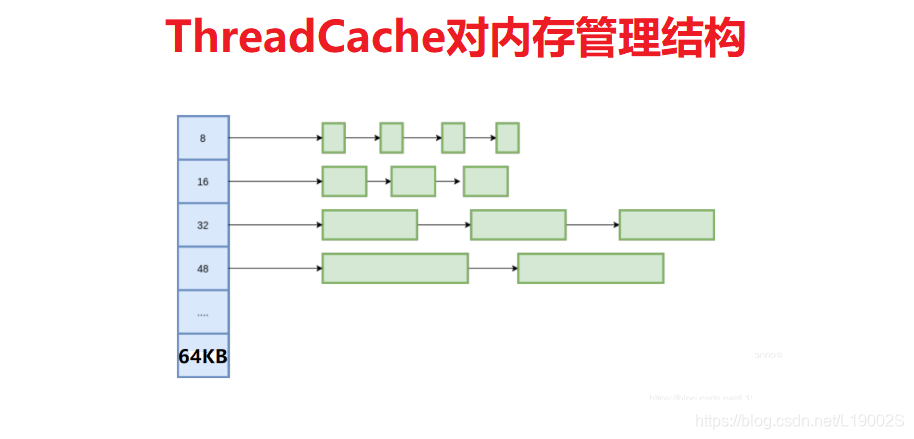
在这里把所有的变长记录进行“取整”,例如分配7字节,就分配8字节,20字节分配32字节,得到多种规格的定长记录。这里带来了内部内存碎片的问题,即分配出去的空间不会被完全利用,有一定浪费。为了减少内部碎片,分配规则按照 8, 16, 32, 48, 64这样子来。注意到,这里并不是简单地使用2的幂级数,因为按照2的幂级数,内存碎片会相当严重,分配65字节,实际会分配128字节,接近50%的内存碎片。而按照这里的分配规格,只会分配80字节,一定程度上减轻了问题。
8.TLS(线程局部存储技术)
概念:线程局部存储(Thread Local Storage,TLS)用来将数据与一个正在执行的指定线程关联起来。
进程中的全局变量与函数内定义的静态(static)变量,是各个线程都可以访问的共享变量。在一个线程修改的内存内容,对所有线程都生效。这是一个优点也是一个缺点。说它是优点,线程的数据交换变得非常快捷。说它是缺点,一个线程死掉了,其它线程也性命不保; 多个线程访问共享数据,需要昂贵的同步开销,也容易造成同步相关的BUG。
如果需要在一个线程内部的各个函数调用都能访问、但其它线程不能访问的变量(被称为static memory local to a thread 线程局部静态变量),就需要新的机制来实现。这就是TLS。
功能:它主要是为了避免多个线程同时访存同一全局变量或者静态变量时所导致的冲突,尤其是多个线程同时需要修改这一变量时。为了解决这个问题,我们可以通过TLS机制,为每一个使用该全局变量的线程都提供一个变量值的副本,每一个线程均可以独立地改变自己的副本,而不会和其它线程的副本冲突。从线程的角度看,就好像每一个线程都完全拥有该变量。而从全局变量的角度上来看,就好像一个全局变量被克隆成了多份副本,而每一份副本都可以被一个线程独立地改变。
_declspec(thread) static ThreadCache* pThreadCache = nullptr;
9.Span及其管理
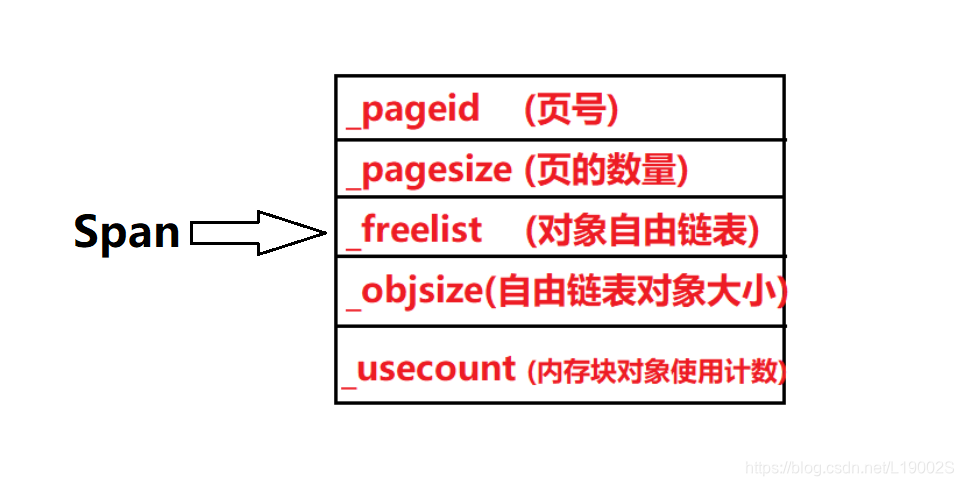
span的本意为跨度,在这里应用也就是CentralCache的一个内存管理的"代表",管理着CentralCache和PageCache里面的以页为单位的内存对象,它里面记录有页号、页的数量、对象自由链表、自由链表对象大小、内存块对象使用计数这五个非常重要的信息,有了这些信息就可以实现对自由链表对象的管理,以及再给ThreadCache都回来之后,usecount为0时,就可以把span还给PageCache用来对span进行合并,那么页号的作用此时也就凸显了出来,它在PageCache中,如果相邻的span都回来挂在了相对应的位置,那么我们就可以对相对小的span进行合并成大的span,假如此时来申请大的span时,就可以轻松的给CentralCache使用,从根源上解决了后置内存碎片的问题!!!
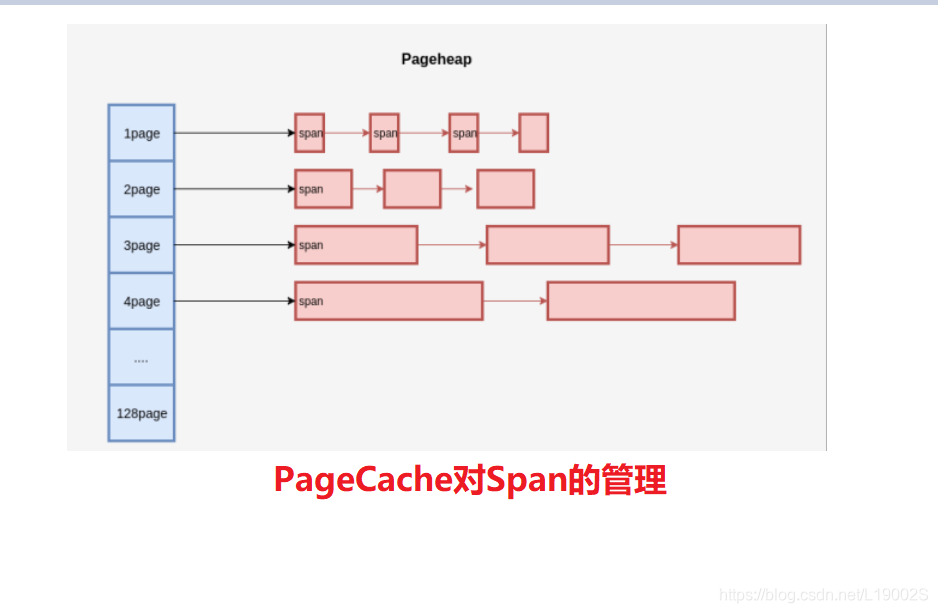
内存申请:切割span
内存释放:合并span
当初始时只有 128 Page 的 Span,如果要分配 1 个 Page 的 Span,就把这个 Span 分裂成两个,1 + 127,把127再记录下来。对于 Span 的回收,需要考虑Span的合并问题,否则在分配回收多次之后,就只剩下很小的 Span 了,也就是带来了外部碎片 问题。为此,释放 Span 时,需要将前后的空闲 Span 进行合并,当然,前提是它们的 Page 要连续。
10.页和Span的映射关系
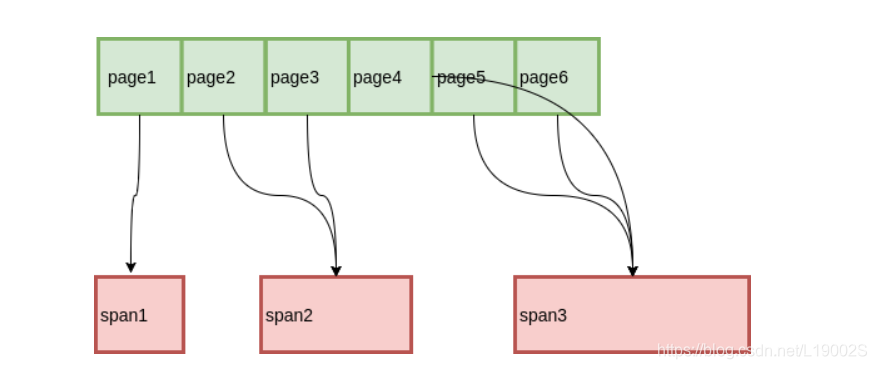
CentralCache中没有非空的span时,则将空的span链在一起,向Page Cache申请一个Span对象,span对象中是一些以页为单位的内存,切成需要的内存大小,并链接起来,挂到span中Span 中记录了起始 Page,也就是知道了从 Span 到 Page 的映射,那么我们只要知道从 Page 到 Span 的映射,就可以知道前后的Span 是什么了。在这里我每没有沿袭TCmalloc里面用的基数树原理,而是采用了较为简便的unordered_map来实现页号和页的映射关系,从来快速找到页并判断它的状态,从而实现页的合并。
11.全局内存管理

每个线程都一个线程局部的 ThreadCache,按照不同的规格,维护了对象的链表;如果ThreadCache 的对象不够了,就从 CentralCache 进行批量分配;如果 CentralCache 依然没有,就从PageCache申请Span;如果 PageCache没有合适的 Page,就只能从操作系统申请了。在释放内存的时候,ThreadCache依然遵循批量释放的策略,对象积累到一定程度就释放给 CentralCache;CentralCache发现一个 Span的内存完全释放了,就可以把这个 Span 归还给PageCache;PageCache发现一批连续的Page都释放了,就可以归还给操作系统。
12.拓展和不足
不足:项目中并没有完全脱离malloc,比如在内存池自身数据结构的管理中,如SpanList中的span等结构,我们还是使用的new Span这样的操作,new的底层使用的是malloc,所以还不足以替换malloc,因为们本身没有完全脱离它。
拓展:
①项目中增加一个定长的ObjectPool的对象池,对象池的内存直接使用brk、VirarulAlloc等向系统申请,new Span替换成对象池申请内存。这样就完全脱离的malloc,就可以替换掉malloc。
②在项目中使用了unordered_map来映射页id和span的关系,进而实现页的查找,而unordered_map的效率并非最优,我们可以使用基数树技术来改进!!!
