前言
最近几天,Hadoop官方社区发布了2.9.0版本,这也是第一个2.9开头的小版本。相比较于之前的2.8版本,2.9版本中新增了不少新功能特性。其中关于HDFS模块的一个重要功能是HDFS Router Federation(基于路由的Federation)。有人可能好奇,这个功能与目前HDFS支持的federation功能有什么区别呢?一句话简单的来讲,就是之前federation是通过多namespace的方式,然后通过viewFs的方式在客户端维护一份挂载表,然后在逻辑上是同一个集群地址。这里笔者特意点出了客户端这3个字,因为是在客户端做路由分析,所以对于用户来说很不方便使用和维护,一旦未来映射关系需要做更改的时候。相比于老federation+ViewFS的方式,Router Federation则是在HDFS内部增加了软件层来帮我们做请求路由。本文笔者就来简单聊聊这个软件层的路由是怎么实现的。
Router Federation软件层结构
想较于ViewFs通过在客户端维护挂载表信息,Router Federation是真正做到了对客户端的完全透明。因为这部分映射信息将会被额外的保存下来,还会持久化出去。这个模块我们姑且称之为状态维护(State Maintenance)的模块。另外还有一个重要的部分是请求转发模块,这里我们称之为Request forward。
以上2个模块构成了HDFS新的Federation软件层的设计。在这层软件结构以下,就是各个子集群。每个子集群会与Federation软件层,进行信息交互。结构图如下:
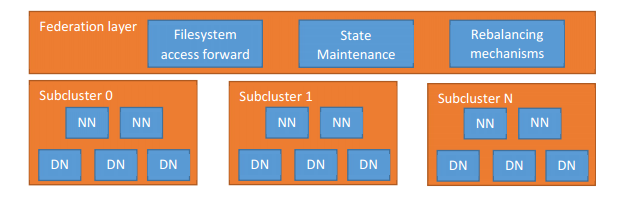
Router Federation角色介绍
针对Router Federation软件层的各个模块,都对应的一个新的服务角色。比如,请求转发模块对应的角色名称就叫Router服务,后面部分描述简写为R。而映射关系存储模块叫做State Store服务。
我们首先来看Router服务,路由器角色,同时与底下的NameNode和上面的State Store服务通信。Router在这里主要有2个作用:
- 第一,提供Federation接口,这个接口是给客户端使用的,它会将客户端请求转发到正确的子集群上。
- 第二,收集NameNode的心跳信息,报告给State Store。这样State Store维护的信息是实时更新的。
Router路由服务并不只是一对一的,它可以是一个Router对应多个NameNode。这样的话,一个NameNode可能会同时被多个Router汇报,这个时候采用的算法是quorum协议。通过这样的设计,来实现Router服务的高可用性。一个Router挂了,不会影响系统的运行,每个Router都是独立运行的。Router汇报结构如下图:
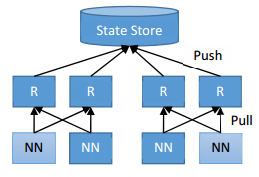
接下来,我们来看另外一个关键的服务State Store服务。因为有了这个状态服务,所以Router路由服务它是无状态的。那么State Store存储的信息主要有哪些呢?答案如下:
- 1.各个NameNode的基础信息,包括地址信息,空间大小信息等基础信息。
- 2.远程挂载表信息,形式为路径–>真实路径信息,这个与之前viewFs基本类似。
- 各个Router的状态信息。
- Federation情况下的balancer状态信息。
在上面4点中,笔者主要来聊聊第2点设计的一些细节。维护在State Store内部的远程挂载表信息,它可能会是很庞大的,因为目标映射的路径可能会很多。如下所示:
hdfs://tmp → hdfs://C0-1/tmp /* Folder tmp is mapped to folder tmp in subcluster C0-1 */
hdfs://share → hdfs://C0-2/share
hdfs://user/user1 → hdfs://C0-3/user/user1
hdfs://user/user2 → hdfs://C0-2/user2所以设计者在这里提供了2类持久化的方案,一种是基于文件的保存,还有一种是保存在额外zookeeper服务上。
在ViewFS中,这些映射关系是用户主动配置在客户端的配置文件中的。而这在Router Federation中是不需要的,State Store服务内部有各个NameNode的信息,它能查询找到正确的NN,然后将映射信息保存下来。当然这些映射信息会被更新一旦被发现是过期或是不正确的时候。
Router Federation路由请求过程
结合上面的角色服务介绍,下面我们来看看一个客户端请求的完整过程,这样我们能直观地理解本文以上所阐述的内容了。
大致过程调用如下图所示,先后顺序已由数字标好(笑脸代表客户端用户)。
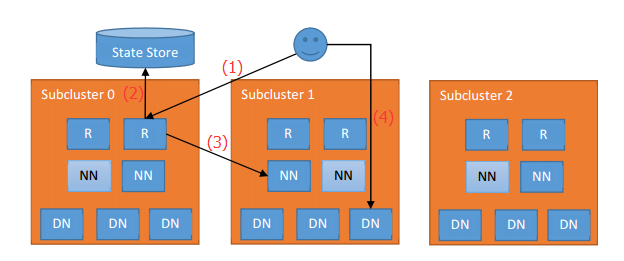
步骤1:客户端调用Router提供的请求接口。
步骤2:该Router向State Store服务查询该请求对应的正确的NN地址。
步骤3:Router得到正确的NN地址后,将请求转发到正确的NN上。
步骤4,然后NN返回文件数据所在的DN地址,客户端与此DN进行消息通信(读/写block文件数据)
以上就是今天笔者所要阐述的内容,为了式文章更加精简易懂一些,笔者省略了其中很多的细节,感兴趣的读者朋友可以阅读社区文档或原始设计文档。链接如下:
[1].http://hadoop.apache.org/docs/r2.9.0/hadoop-project-dist/hadoop-hdfs/HDFSRouterFederation.html
[2].https://issues.apache.org/jira/secure/attachment/12806670/HDFS%20Router%20Federation.pdf