环境:ubuntu64位 + gcc
1. 各数据类型占的字节大小
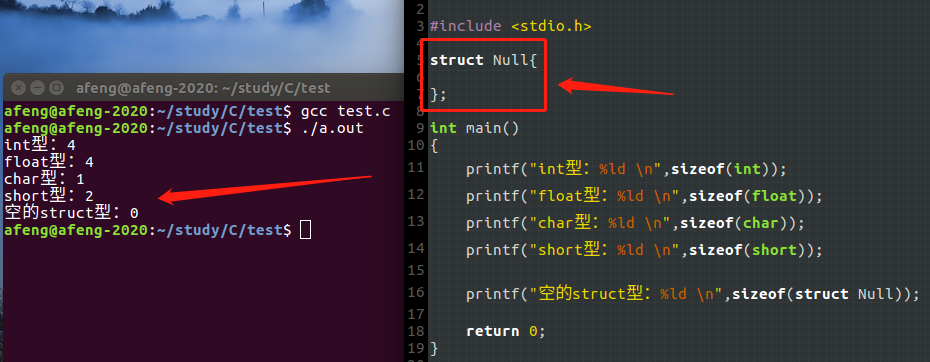
先定义一个空的结构体,通过sizeof查看发现其占用内存字节为0(在vc++6.0中为1),其他类型数据内存字节大小如下图
#include <stdio.h>
struct Null{
};
int main()
{
printf("int型:%ld \n",sizeof(int));
printf("float型:%ld \n",sizeof(float));
printf("char型:%ld \n",sizeof(char));
printf("short型:%ld \n",sizeof(short));
printf("空的struct型:%ld \n",sizeof(struct Null));
return 0;
}
定义一个非空结构体,再观察其内存字节大小,发现一个结构体的大小并非各数据类型大小简单地相加
#include <stdio.h>
struct Student{
int name; //4
float score; //4
char sex; //1
short num; //2
};
int main()
{
printf("struct Student字节数:%ld \n",sizeof(struct Student));
return 0;
}

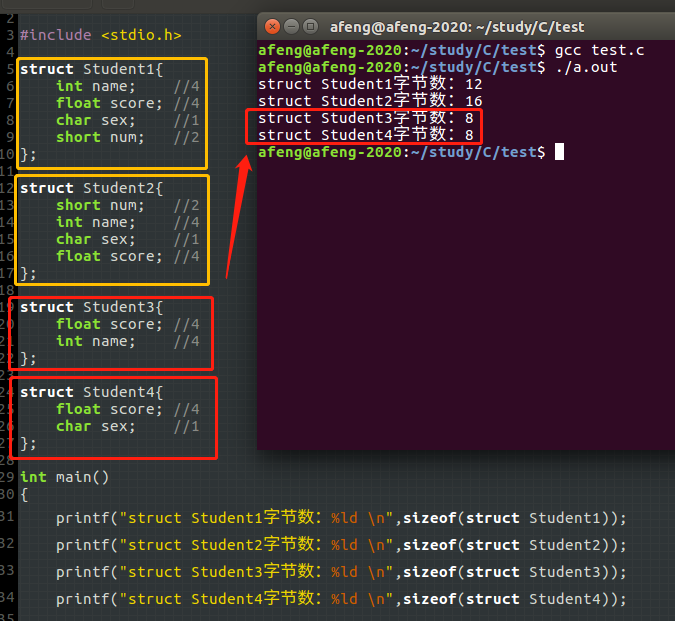
为了体现这谜之乐趣,不妨换一种方式来测一测,观察1和2,发现即使结构体成员都一样,但是换了排序后,所占的字节数就发生改变;观察3和4,float+char和float+int居然一样大
2. 结构体对齐问题
上网查阅可知道,结构体的默认存储方式采用以最大字节元素字节数对其方式进行对齐,所谓的字节对齐,是指数据类型按照固定的字节大小排列,方便计算机cpu、内存等的读取。结构体中的数据类型并不是都相同的,这个时候就需要字节对齐来提高计算机的读取效率
这个固定的字节大小,编译器默认设为结构体内最大元素的字节数,比如上述的float+char和float+int,其实存储的时候,不管是int还是char,都是以4个字节去储存了,简单来说就是,以后索引变量时的步进值均以那个固定字节数访问内存
拿下面的结构体来说明
struct Student1{
int name; //4
float score; //4
char sex; //1
short num; //2
};
| 类型 | 地址1 | 地址2 | 地址3 | 地址4 |
|---|---|---|---|---|
| int | 1字节 | 1字节 | 1字节 | 1字节 |
| float | 1字节 | 1字节 | 1字节 | 1字节 |
| char+short | 1字节 | 1字节 | 1字节 | 填充 |
以最大元素对应的字节数为固定字节,上面的变量中float或int最大,所以是4(每一行存放的字节个数);对于第三行的char+short,是因为在第三行一开始的时候,char一个字节存放完之后,还有三个字节,足够存放接下来的short,故char和short可以存放在同一行。3行4列,一共12个字节。
对于相同元素的结构体2,其内存分布如下
struct Student2{
short num; //2
int name; //4
char sex; //1
float score; //4
};
| 类型 | 地址1 | 地址2 | 地址3 | 地址4 |
|---|---|---|---|---|
| short | 1字节 | 1字节 | 填充 | 填充 |
| int | 1字节 | 1字节 | 1字节 | 1字节 |
| char | 1字节 | 填充 | 填充 | 填充 |
| float | 1字节 | 1字节 | 1字节 | 1字节 |
一开始在第一行先存short型,占2个字节,剩下的2个字节空间并不够接下来的int型4个字节,因此只能另起一行,同理,当char型存在第三行后,剩下的3个字节空间并不够接下来的float型,则另起一行。4行4列,共16个字节。因此可以知道为什么结构体内部元素的排列顺序会对结构体大小产生影响了
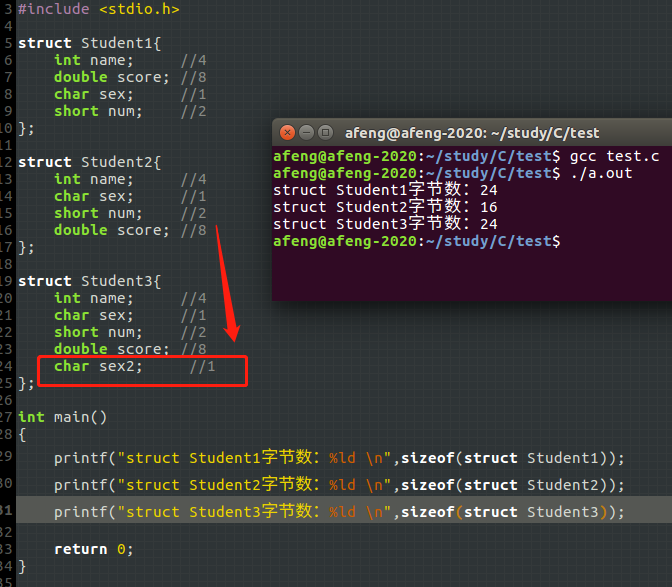
再看一个例子来理解理解,Student1的内存方式是3行8列,Student2的则是2行8列,而Student3仅在Student2基础上增加了一个char,就又变成3行8列了,可知不同的字节对齐方式对内存的影响还是很大的(此处注意,如果最后一行没有满8个,也必须要填充至8个,在本例结构体内存的大小必须要是8的整数倍)
3. 为什么要对齐
(1) 结构体中元素对齐访问主要原因是为了配合硬件,也就是说硬件本身有物理上的限制,如果对齐排布和访问会提高效率,否则会大大降低效率。
(2) 内存本身是一个物理器件(DDR内存芯片,SoC上的DDR控制器),本身有一定的局限性:如果内存每次访问时按照4字节对齐访问,那么效率是最高的;如果你不对齐访问效率要低很多。
(3) 还有很多别的因素和原因,导致我们需要对齐访问。譬如Cache的一些缓存特性,还有其他硬件(譬如MMU、LCD显示器)的一些内存依赖特性,所以会要求内存对齐访问。
(4) 对比对齐访问和不对齐访问:对齐访问牺牲了内存空间,换取了速度性能;而非对齐访问牺牲了访问速度性能,换取了内存空间的完全利用。
小结:说白了,就是为访问结构体成员效率高,也就是读取数据更为高效(但是这里也会牺牲一点点内存)。
值得开心的是,编译器已经帮我们完成了对齐,正如前文所说,编译器是默认以最大字节数为基础进行对齐的,其优点就是提高访问效率,缺点是浪费一定的内存,至于浪费多还是少,是与写代码时对变量的排序有关的
一般的做法就是,字节数少的变量尽量靠在一起,相同类型的变量也要靠在一起,这样子就最大程度上减少内存浪费了
4. 可以自定义其他字节对齐吗
分享一个面试题
怎样使下面的结构体保持一个字节对齐或者说八字节对齐?
struct Test{ int a ; int c ; char d; };
在编译器里,我们可以通过对齐指令来设置结构体的对齐方式,有 #pragma pack() 和 #pragma pack(n) (n=1/2/4/8)
#pragma pack(n)告诉编译器结构体或类内部的成员变量相对于第一个变量的地址的偏移量的对齐方式,缺省情况下,编译器按照自然边界对齐,当变量所需的自然对齐边界比n大 时,按照n对齐,否则按照自然边界对齐;#pragma pack () /取消指定对齐,恢复缺省对齐/
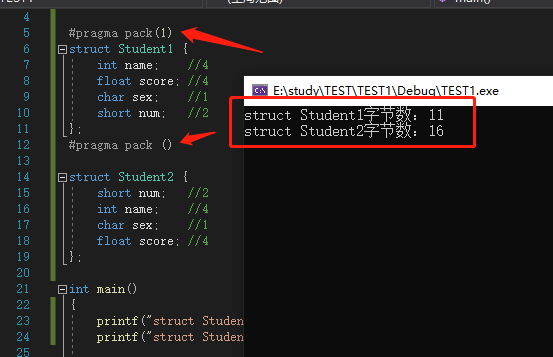
通过上图的测试(在win10+VS2019),发现使用一个字节对齐时,该结构体的内存为11,正好是 4+4+1+2,而没有使用#pragma pack指令的相同结构体,则默认以最大字节(即4字节)进行排序;#prgma pack的方式在很多C环境下都是支持的,但是gcc虽然也可以,不过不建议使用(下图是在gcc环境)
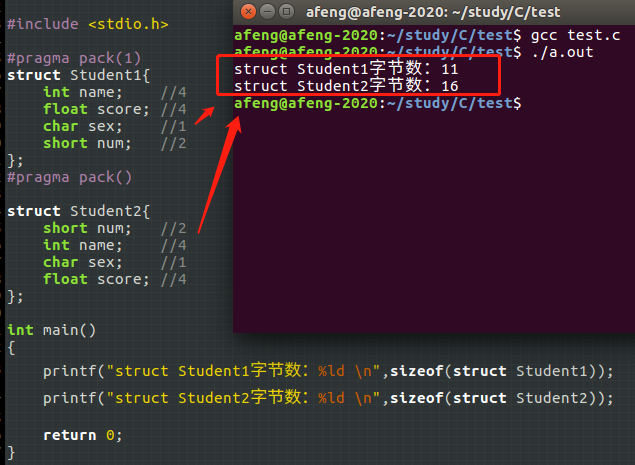
gcc支持但不推荐上述的对齐指令,如下图演示,在gcc环境,对于两个一样的结构体,第一个使用8字节的对齐方式,第二个使用默认的4字节,但是结果却是一样的,按照分析,第一个如果设为8字节对齐,该结构体大小就应该为16才对,因此可以知道编译器还是把该结构体按照4字节对齐处理了
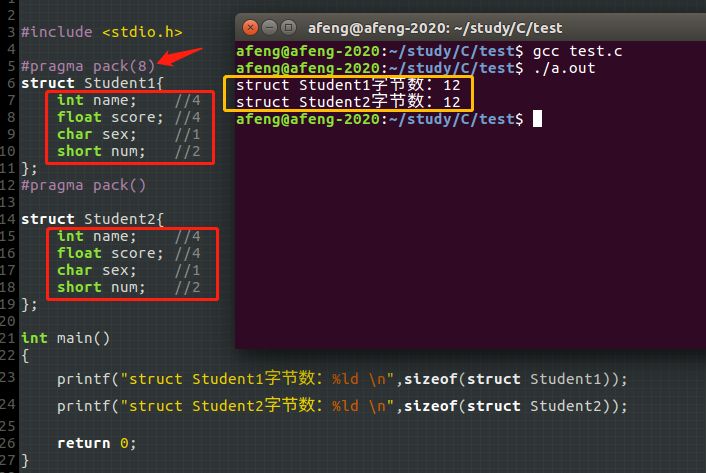
从测试的结果来看是这样:在gcc中,如果指定 #pragma pack(N) 中的 N 的话,N 不能大于默认对齐指定的长度,即如果默认对齐是 4 的话,N的取值可以是 1、2、4,超过 4 之后作为 4 处理。在 Windows 等系统上似乎没有这个限制
gcc推荐的对齐指令__attribute__((packed))和__attribute__((aligned(n)))
上述__attribute__ ((packed)) 的作用就是告诉编译器,取消结构在编译过程中的优化对齐,按照实际占用字节数进行对齐,是GCC特有的语法。
上述__attribute__((aligned(m)))告诉编译器一个结构体或者类或者联合或者一个类型的变量(对象)分配地址空间时的地址对齐方式。也就是所,如果将__attribute__((aligned(m)))作用于一个类型,那么该类型的变量在分配地址空间时,其存放的地址一定按照m字节对齐(m必须是2的幂次方)。并且其占用的空间,即大小,也是m的整数倍,以保证在申请连续存储空间的时候,每一个元素的地址也是按照m字节对齐。
如下图演示,三个结构体均是相同的,取消自动对齐即以1字节方式对齐,此时结构体的大小为元素大小之和;使用__attribute__((aligned(m)))则可以设置其对齐方式,为2行8列

结束
如有错误,还望指正!
