在了解了hfds的底层执行之后,也知道它存在的一些问题,mapreduce下的资源管理1.x
简单回顾一下
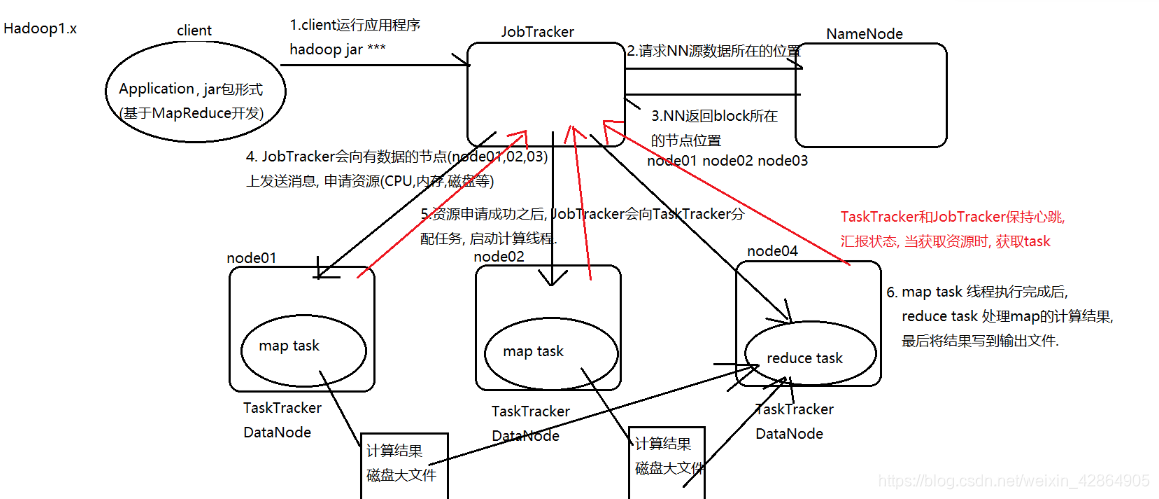
第一单点故障,第二内存的硬件限制,最后就是mapreduce 的计算机制造成了资源的空闲浪费。,对于以上存在的问题,虽然mapreduce是一个很好的大数据处理的计算框架,但是,为了追求最好的运行效率,当遇到特别巨大的运算等特殊情况时所可以得到的最好的处理结果,Hadoop在MapReduce的基础上加以改进提出了yarn集群的管理概念
Yarn的核心思想就是将MR中的jobtracker进行分离,分为ResourceManager(进行集群的资源管理和调度)和ApplicationMaster(负责应用程序的相关事务),分担了jobtracker的任务,大大的减缓了单点问题,同事也提升了集群的扩展性和可用性
优点:
Yarn集群的优点除了在之上说的减缓了jobtracker的工作,提升了集群的扩展性和可用性之外,还有以下的优点:
(1)Federation机制:多个NameNode分管不同的目录进而实现了访问隔离和横向扩展
另外它也可以通过NameNode HA对于运行中的NameNode的单点故障进行处理
(2)yarn具有向后兼容,可以兼容所有在MR上运行的作业,不需要进行修改
(3)支持多个矿建,yarn不再是一个单纯的计算框架,而是一个管理器,对传到yarn上的框架进行统一的管理和资源分配
(4)在yarn中,框架不在分散到各个节点上,而是统一的的存放在客户端,当需要进行修改等操作时,只需要在客户端上进行操作就好
架构:
YARN共有ResourceManager、NodeManager、JobHistoryServer、Containers、Application Master、job、Task、Client组成
(1)ResourceManager(总裁):
控制整个集群的应用程序的分发,分发到集群中的计算资源上,于NodeManager管理每一个节点上的基础应用程序的启动和监控,于applicationMaster进行资源的分发(相当于之前的jobtracker的工作
1.1、处理客户端的qingqiu
1.2、启动或监控applicationMaster
1.3、监控nodeManager
1.4、资源的分配和管理
(2)NodeManager(员工);
集群中节点的管理服务,管理集群中每一个节点的终生管理,把偶哦资源的见识和节点是否正常启动,同时处理来自ResourceManager和applicationMaster的命令
(3)applicationMaster(经理):管理在集群中运行的应用程序的每个实例,协调来自RM 的资源,并通过NM监视容器的致性和资源的使用
(4) JobHistory Server: 负责查询job运行进度及元数据管理。
(5) Containers: Container通过ResourceManager分配。包括容器的cpu、内存等资源。
(6)job:一个mapper、一个Reducer或一个进程的输入列表。job也可以叫做Application。
(7)task:一个具体做mapper或Reducer的独立的工作单元。task运行在nodemanager 的Container中。
运行流程:
1、作业提交
2、作业初始化
3、任务分配
4、任务运行
5、进度和状态更新
6、作业完成
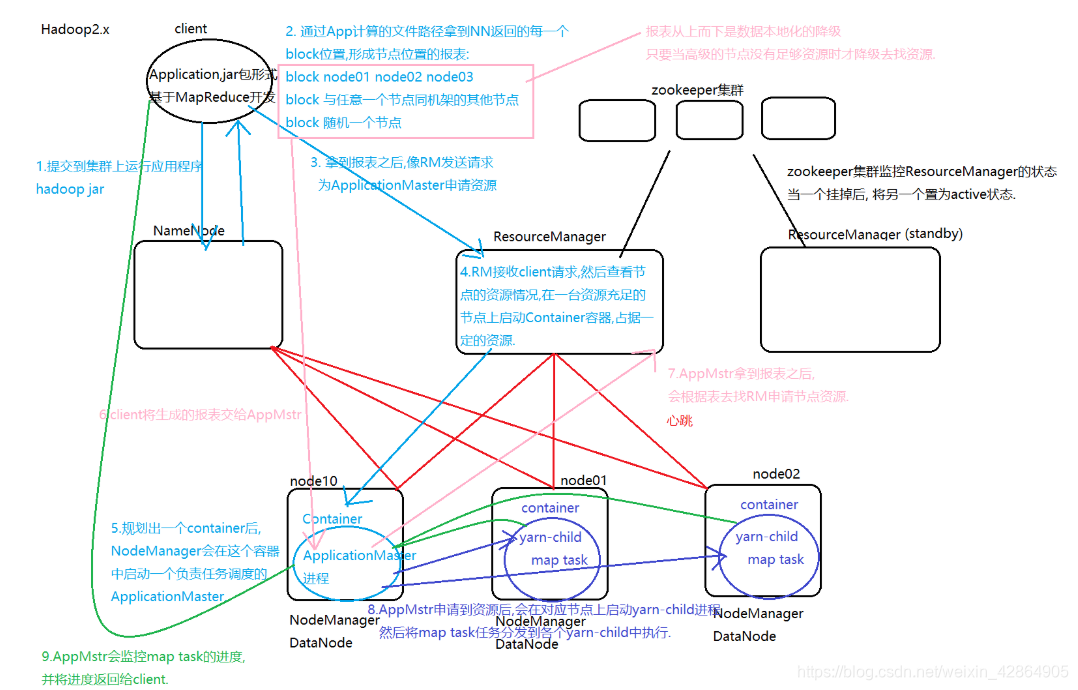
具体流程:
1、用户向yarn集群中提交程序/作业,RM为作业分配第一个container,并于对应的NM进行通信要求启动ApplicationMaster,,
2、applicationMaster向RM进行注册然后application向RM申请资源。
3,applicationmaster在指定的nodemanager上启动任务,
4、启动之后,去拉区RM指定的maptask进行处理。
5、等maptask处理完成之后通知applicationmaster,然后AM会告知RM。RM重新为AM分配资源,去处理maptask的执行结果。开始reducetask任务
6、等所有的reducetaask处理完毕,将运行的NM进行同步,做reduce任务
7、然后将计算结果上传到hdfs中
hadoop--“管家”yarn初步讲解2.x

猜你喜欢
转载自blog.csdn.net/weixin_42864905/article/details/104508206
今日推荐
周排行