partition 的高可用副本机制
我们已经知道Kafka的每个topic都可以分为多个Partition,并且多个 partition 会均匀分布在集群的各个节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个partition 来说,都是单点的,当其中一个 partition 不可用的时候,那么这部分消息就没办法消费。所以 kafka 为了提高 partition 的可靠性而提供了副本的概念(Replica),通过副本机制来实现冗余备份。
每个分区可以有多个副本,并且在副本集合中会存在一个leader 的副本,所有的读写请求都是由 leader 副本来进行处理。剩余的其他副本都做为 follower 副本,follower 副本 会 从 leader 副 本 同 步 消 息 日 志 。 这 个 有 点 类 似zookeeper 中 leader 和 follower 的概念,但是具体的实现方式还是有比较大的差异。所以我们可以认为,副本集会存在一主多从的关系。
一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同 broker 上,当 leader 副本所在的 broker 出现故障后,可以重新选举新的 leader 副本继续对外提供服务。通过这样的副本机制来提高 kafka 集群的可用性。
副本分配算法
将所有 N Broker 和待分配的 i 个 Partition 排序. 将第 i 个 Partition 分配到第(i mod n)个 Broker 上. 将第 i 个 Partition 的第 j 个副本分配到第((i + j) mod n)个 Broker 上
创建一个带副本机制的 topic
通过下面的命令去创建带 2 个副本的 topi
./kafka-topics.sh --create --zookeeper 192.168.11.156:2181 --replication-factor 2 --partitions 3 --topic secondTopic
然后我们可以在/tmp/kafka-log 路径下看到对应 topic 的副本信息了。我们通过一个图形的方式来表达。
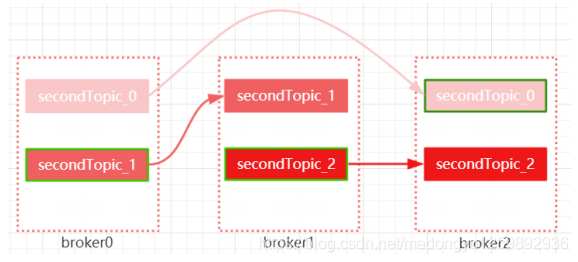
针对 secondTopic 这个 topic 的 3 个分区对应的 3 个副本

如何知道那个各个分区中对应的 leader 是谁呢?在 zookeeper 服务器上,通过如下命令去获取对应分区的 信息, 比如下面这个是获取 secondTopic 第 1 个分区的状态信息。
get /brokers/topics/secondTopic/partitions/1/state
{"controller_epoch":12,"leader":0,"version":1,"leader_epoch":0,"isr":[0,1]}leader 表示当前分区的 leader 是哪个 broker-id,下图中。绿色线条的表示该分区中的 leader 节点。其他节点就为follower
Kafka 提供了数据复制算法保证,如果 leader 发生故障或挂掉,一个新 leader 被选举并被接受客户端的消息成功写入。Kafka 确保从同步副本列表中选举一个副本为 leader;leader 负责维护和跟踪 ISR(in-Sync replicas , 副本同步队列)中所有 follower 滞后的状态。当 producer 发送一条消息到 broker 后,leader 写入消息并复制到所有 follower。消息提交之后才被成功复制到所有的同步副本。
既然有副本机制,就一定涉及到数据同步的概念,那接下来分析下数据是如何同步的?
需要注意的是,大家不要把 zookeeper 的 leader 和follower 的同步机制和 kafka 副本的同步机制搞混了。虽
然从思想层面来说是一样的,但是原理层面的实现是完全不同的。
kafka 副本机制中的几个概念
Kafka 分区下有可能有很多个副本(replica)用于实现冗余,从而进一步实现高可用。
副本根据角色的不同可分为 3 类:
1.leader 副本:响应 clients 端读写请求的副本
2.follower 副本:被动地备份 leader 副本中的数据,不能响应 clients 端读写请求。
3.ISR 副本:包含了 leader 副本和所有与 leader 副本保持同步的 follower 副本——如何判定是否与 leader 同步后面会提到每个 Kafka 副本对象都有两个重要的属性:LEO 和HW。注意是所有的副本,而不只是 leader 副本。
LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果 LEO=10,那么表示该副本保存了 10 条消息,位移值范围是[0, 9]。另外,leader LEO 和 follower LEO 的更新是有区别的。我们后面会详细说。
HW:即上面提到的水位值。对于同一个副本对象而言,其HW 值不会大于 LEO 值。小于等于 HW 值的所有消息都被认为是“已备份”的(replicated)。同理,leader 副本和follower 副本的 HW 更新是有区别的。
副本协同机制
刚刚提到了,消息的读写操作都只会由 leader 节点来接收和处理。follower 副本只负责同步数据以及当 leader 副本所在的 broker 挂了以后,会从 follower 副本中选取新的leader。
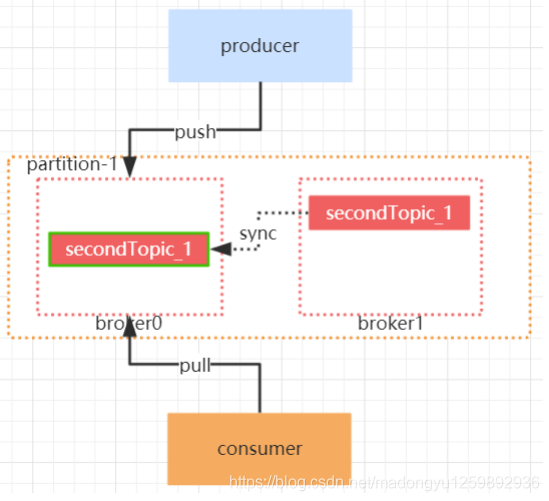
写请求首先由 Leader 副本处理,之后 follower 副本会从leader 上拉取写入的消息,这个过程会有一定的延迟,导致 follower 副本中保存的消息略少于 leader 副本,但是只要没有超出阈值都可以容忍。但是如果一个 follower 副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候,leader 就会把它踢出去。kafka 通过 ISR集合来维护一个分区副本信息
ISR
ISR 表示目前“可用且消息量与 leader 相差不多的副本集合,这是整个副本集合的一个子集”。怎么去理解可用和相差不多这两个词呢?具体来说,ISR 集合中的副本必须满足两个条件
-
副本所在节点必须维持着与 zookeeper 的连接
-
副本最后一条消息的 offset 与 leader 副本的最后一条消息的 offset 之 间 的 差 值 不 能 超 过 指 定 的 阈 值 (replica.lag.time.max.ms)
replica.lag.time.max.ms:如果该 follower 在此时间间隔内一直没有追上过 leader 的所有消息,则该 follower 就会被剔除 ISR 列表(ISR 数 据 保 存 在 Zookeeper 的/brokers/topics//partitions//state 节点中)
HW&LEO
关于 follower 副本同步的过程中,还有两个关键的概念,HW(HighWatermark)和 LEO(Log End Offset). 这两个参数跟 ISR 集合紧密关联。HW 标记了一个特殊的 offset,当消费者处理消息的时候,只能拉去到 HW 之前的消息,HW之后的消息对消费者来说是不可见的。也就是说,取partition 对应 ISR 中最小的 LEO 作为 HW,consumer 最多只能消费到 HW 所在的位置。每个 replica 都有 HW,leader 和 follower 各自维护更新自己的 HW 的状态。一条消息只有被 ISR 里的所有 Follower 都从 Leader 复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何 Follower 复制就宕机了,而造成数据丢失(Consumer 无法消费这些数据)。而对于Producer 而言,它可以选择是否等待消息 commit,这可以通过 acks 来设置。这种机制确保了只要 ISR 有一个或以上的 Follower,一条被 commit 的消息就不会丢失。
